



NVIDIA Turing - Uno sguardo alla nuova architettura - Parte Prima
Indice

La nuova architettura Turing rappresenta il frutto della grande esperienza maturata in questo settore dal colosso californiano NVIDIA nel corso degli anni. A detta della stessa azienda ci troviamo dinanzi al più significativo passo avanti, a livello architetturale, da oltre un decennio a questa parte, questo sia in termini prettamente prestazionali e sia in quanto ad efficienza e novità tecnologiche introdotte.

Utilizzando nuovi acceleratori hardware e un approccio di rendering di tipo ibrido, infatti, Turing fonde rasterizzazione, ray-tracing in tempo reale, intelligenza artificiale e simulazione per assicurare un incredibile realismo nei giochi, nuovi straordinari effetti alimentati da reti neurali, esperienze interattive di qualità cinematografica e interattività estremamente fluida durante la creazione di modelli 3D complessi.
Le applicazioni di elaborazione e classificazione delle immagini su larga scala, come ad esempio ImageNet Challenge, sono considerate come uno dei più grandi successi del deep-learning, perciò non sorprende che all’intelligenza artificiale venga riconosciuto il potenziale per risolvere molti importanti problemi in ambito grafico.
Allo scopo, Turing implementa delle unità di calcolo espressamente dedicate, denominate Tensor Cores, pensate per potenziare tutta una serie di nuovi servizi neurali basati per l’appunto sul deep-learning, al fine di offrire straordinari effetti grafici per i giochi e la grafica professionale, oltre a fornire inferenze di intelligenza artificiale ancor più efficienti per i sistemi basati sul cloud.
Grazie a questa nuova architettura viene offerto quelli che molti definiscono come il “Santo Graal” nel campo del rendering grafico computerizzato, ovvero il ray-tracing in tempo reale, anche in sistemi a singola GPU. I nuovi processori grafici NVIDIA introducono, infatti, nuove e sofisticate unità espressamente dedicate all’esecuzione delle operazioni di ray-tracing (denominate per l’appunto “RT Cores”), eliminando così dispendiosi e poco efficienti approcci basati sull’emulazione software.
Queste nuove unità, combinate con la tecnologia software proprietaria NVIDIA RTX e con sofisticati algoritmi di filtraggio, consentono un rendering in ray-tracing in tempo reale, includendo oggetti e ambienti fotorealistici con ombre, riflessi e rifrazioni fisicamente precise. Parallelamente allo sviluppo di questa nuova ed interessante architettura, anche Microsoft aveva annunciato, già all’inizio dello scorso anno, lo sviluppo delle nuove API DirectML e DirectX Raytracing (DXR). La combinazione dell’architettura GPU di Turing con queste nuove API assicurerà agli sviluppatori un’implementazione estremamente semplice, di queste interessanti tecnologie, all’interno dei loro titoli.
L’architettura Turing include anche nuove funzionalità di ombreggiatura avanzate atte a migliorare le prestazioni, la qualità dell’immagine ed offrire nuovi livelli di complessità geometrica. Non mancano tutti i miglioramenti apportati alla piattaforma CUDA introdotta nell’architettura Volta, dedicati alla capacità, alla flessibilità, alla produttività e alla portabilità delle applicazioni di elaborazione. Funzioni quali la programmazione indipendente dei Thread, il Multi-Process Service (MPS) accelerato via hardware, e gruppi cooperativi fanno tutti parte di questa nuova architettura NVIDIA.
Questa architettura è inoltre la prima ad essere sviluppata con la recente ed avanzata tecnologia produttiva a 12 nanometri FinFET NVIDIA (FFN), messa a punto dalla taiwanese TSMC e capace di garantire non soltanto un deciso incremento dell’efficienza energetica ma soprattutto di offrire la possibilità di integrare un maggior quantitativo di unità di calcolo, grazie ad una densità superiore, e nuove funzionalità all’interno del processore grafico.
NVIDIA ha dimostrato in modo inequivocabile come una migliore tecnologia produttiva possa incidere in maniera decisa nella fase di progettazione dell’architettura, consentendo agli ingegneri di apportare modifiche e ottimizzazioni particolari, come il perfezionamento delle latenze e la pulizia dei vari segnali, mirate a garantire prestazioni e frequenze operative in precedenza impensabili, pur senza stravolgerne le fondamenta. Nei paragrafi che seguono andremo a descrivere quelle che sono le più significative differenze e novità introdotte con la nuova architettura.
Turing Streaming Multiprocessor (SM) e nuove unità Tensor Cores
Una delle principali differenze architetturali rispetto alla passata generazione riguarda le unità Streaming Multiprocessor (SM), ora comprensive di molte delle funzionalità implementate nelle soluzioni professionali basate su architettura Volta.
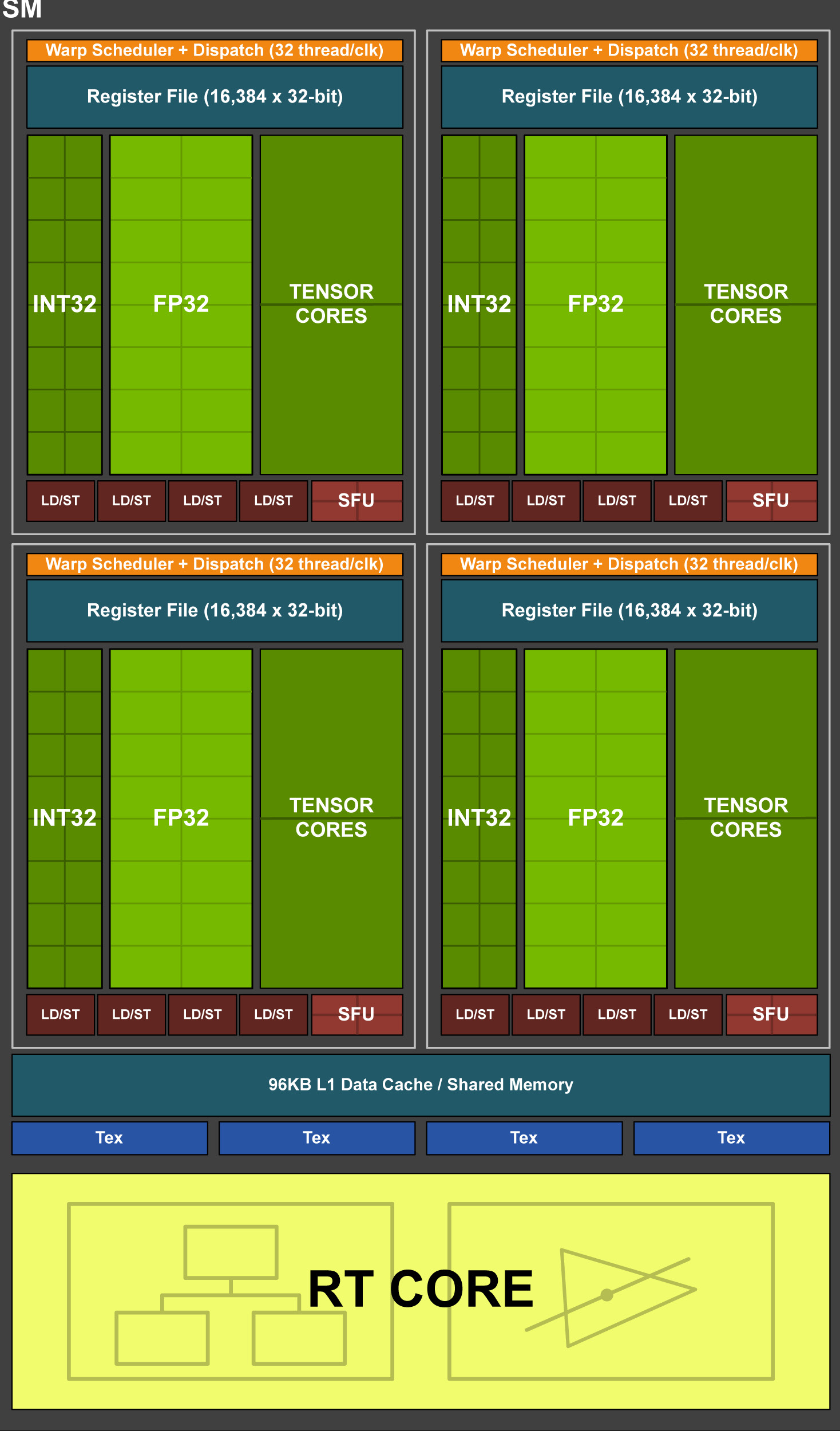
Tra queste evidenziamo un raddoppio delle unità SM per ogni blocco TPC (Thread/Texture Processing Clusters), raggiungendo le due unità. Ognuna di queste integra al proprio interno 64 core FP32 e altrettanti core INT32, di tipo concurrent, ovvero in grado di operare in parallelo e contemporaneamente.
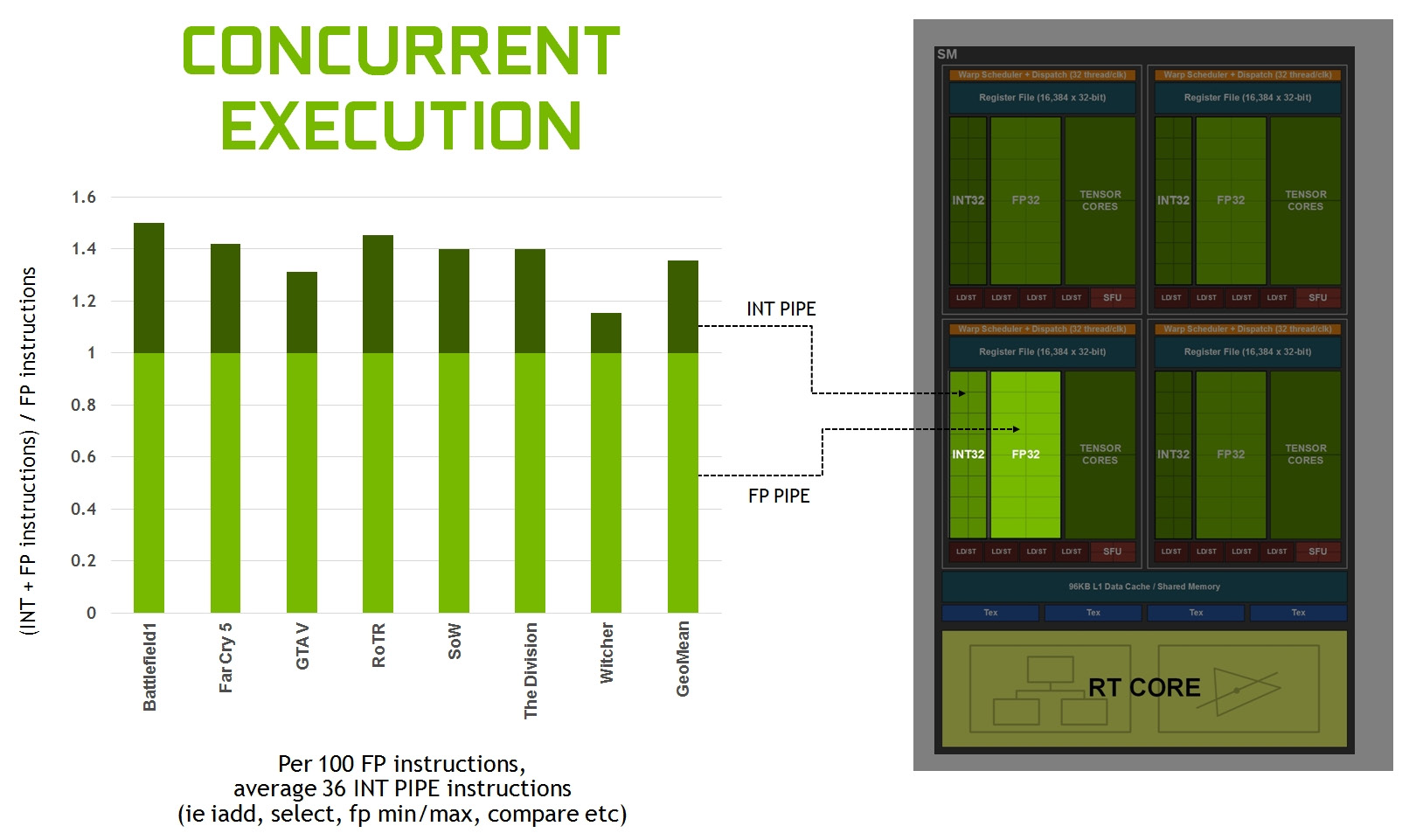
Proprio questo aspetto rappresenta una delle differenze più significative, e con maggior impatto in termini di performance, rispetto alla passata generazione. Il colosso californiano, infatti, assicura un deciso incremento dell’efficienza, ricordando che per ogni 100 istruzioni in virgola mobile il processore grafico si trova a dover processare almeno 36 istruzioni di tipo integer, e sottolineando così come la possibilità di operare in parallelo e in contemporanea su l’una o l’altra tipologia di istruzione rappresenti un punto chiave della nuova architettura.
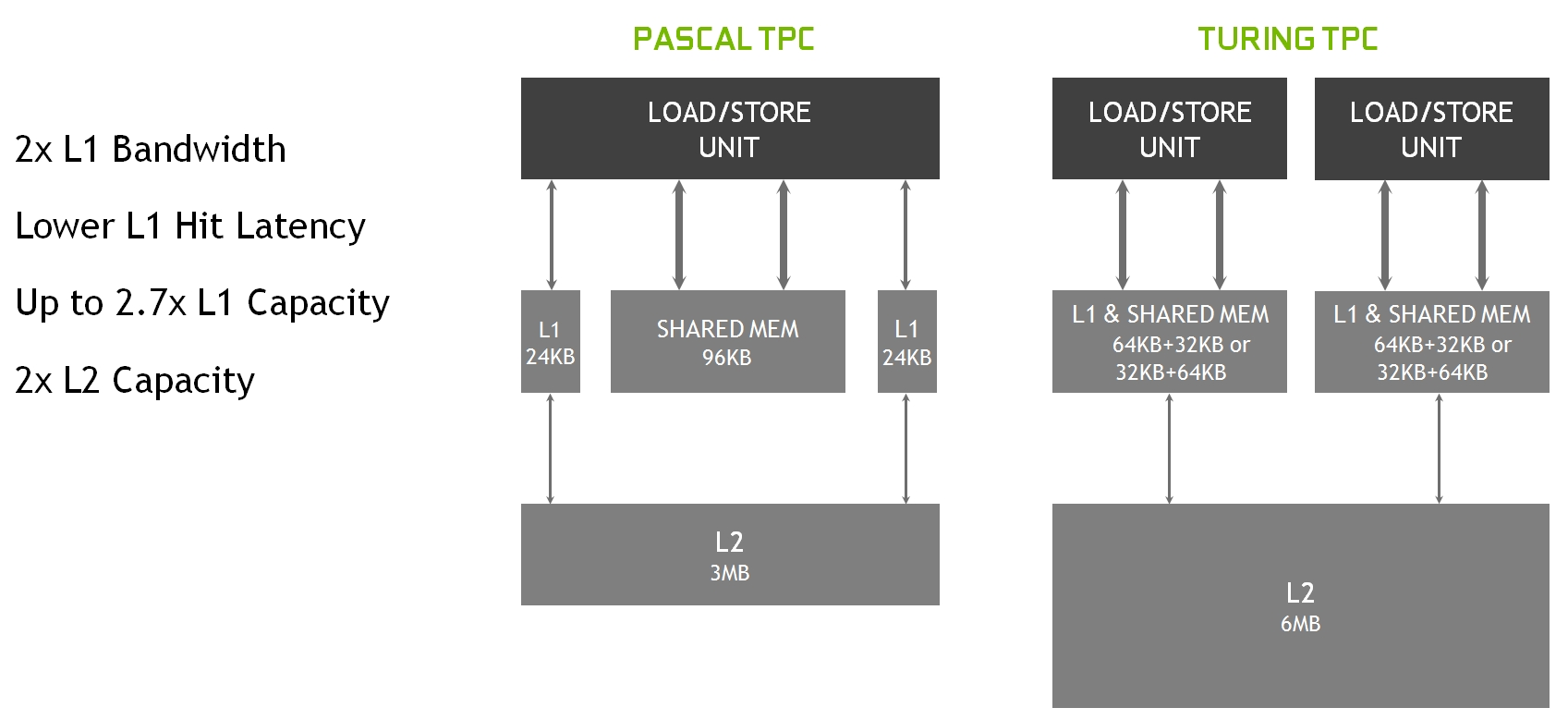
Ad essere radicalmente rivista ed ottimizzata è stata anche l’architettura della Cache e della memoria condivisa (Shared Memory), al fine di sfruttare in miglior modo le risorse disponibili rispetto a Pascal. Nello specifico troviamo ora un’architettura di tipo unificato, con Cache dati L1 più capiente (ben 2.7 volte rispetto a Pascal) e memoria condivisa in grado di operare in maniera congiunta in configurazione 64kB + 32kB oppure 32kB + 64kB.
NVIDIA ha ora previsto una coppia di unità Load/Store (il doppio rispetto alla passata generazione) ognuna con accesso diretto al proprio blocco “Cache L1+Shared Memory” dedicato. Entrambi questi blocchi sono a loro volta collegati alla memoria di secondo livello (Cache L2), la cui capienza è stata raddoppiata rispetto a Pascal, raggiungendo i 6MBytes.
L’insieme di questi interventi assicura un significativo impatto sulle prestazioni, semplificando allo stesso tempo la programmazione e l’ottimizzazione necessaria all’ottenimento di prestazioni delle applicazioni prossime al picco massimo. La combinazione della Cache dati L1 con la memoria condivisa riduce la latenza e offre una maggiore larghezza di banda rispetto all’implementazione utilizzata in precedenza nei processori grafici Pascal.
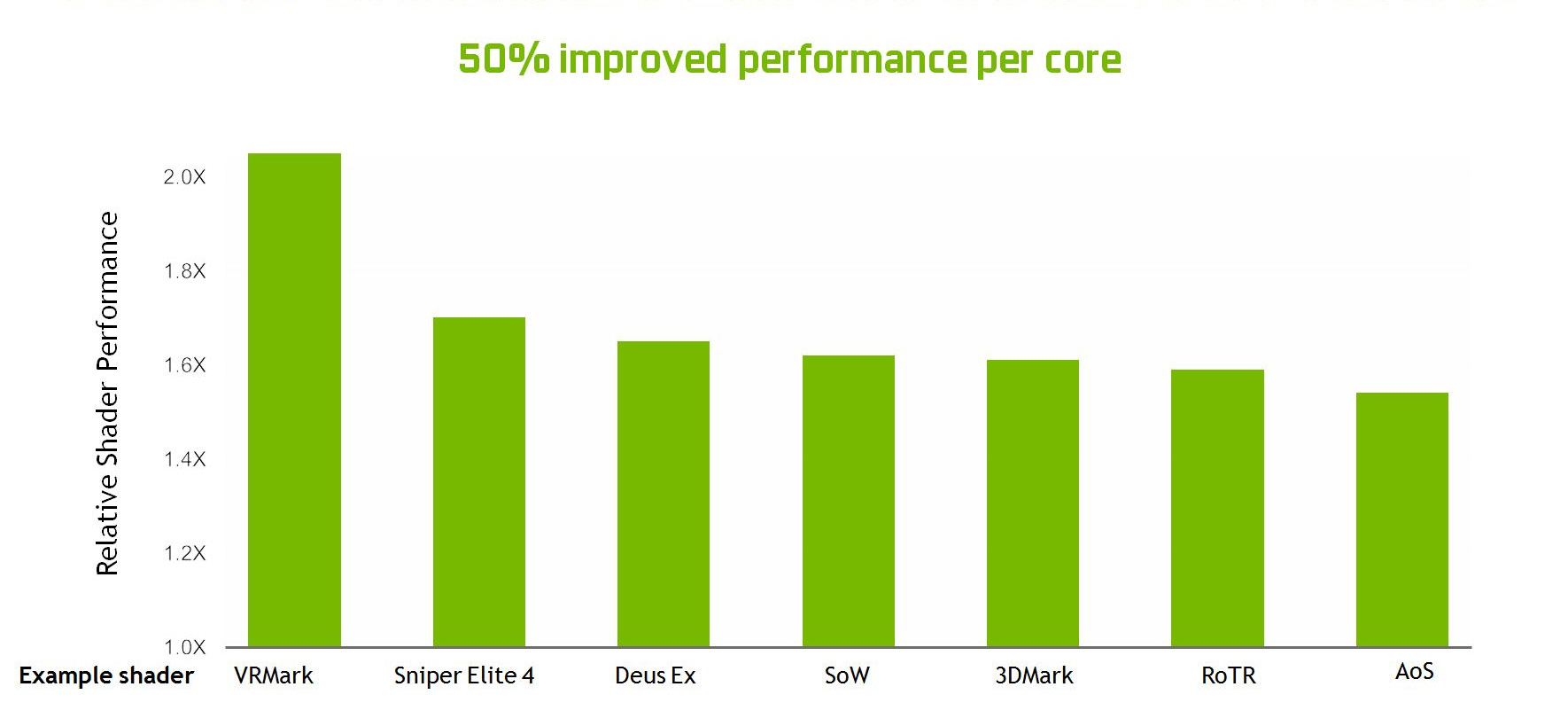
Complessivamente, le modifiche apportate all’unità SM consentono a Turing di ottenere un miglioramento, a seconda del tipo di applicazione che viene eseguita, capace di raggiungere il +50% delle prestazioni erogate per core CUDA.
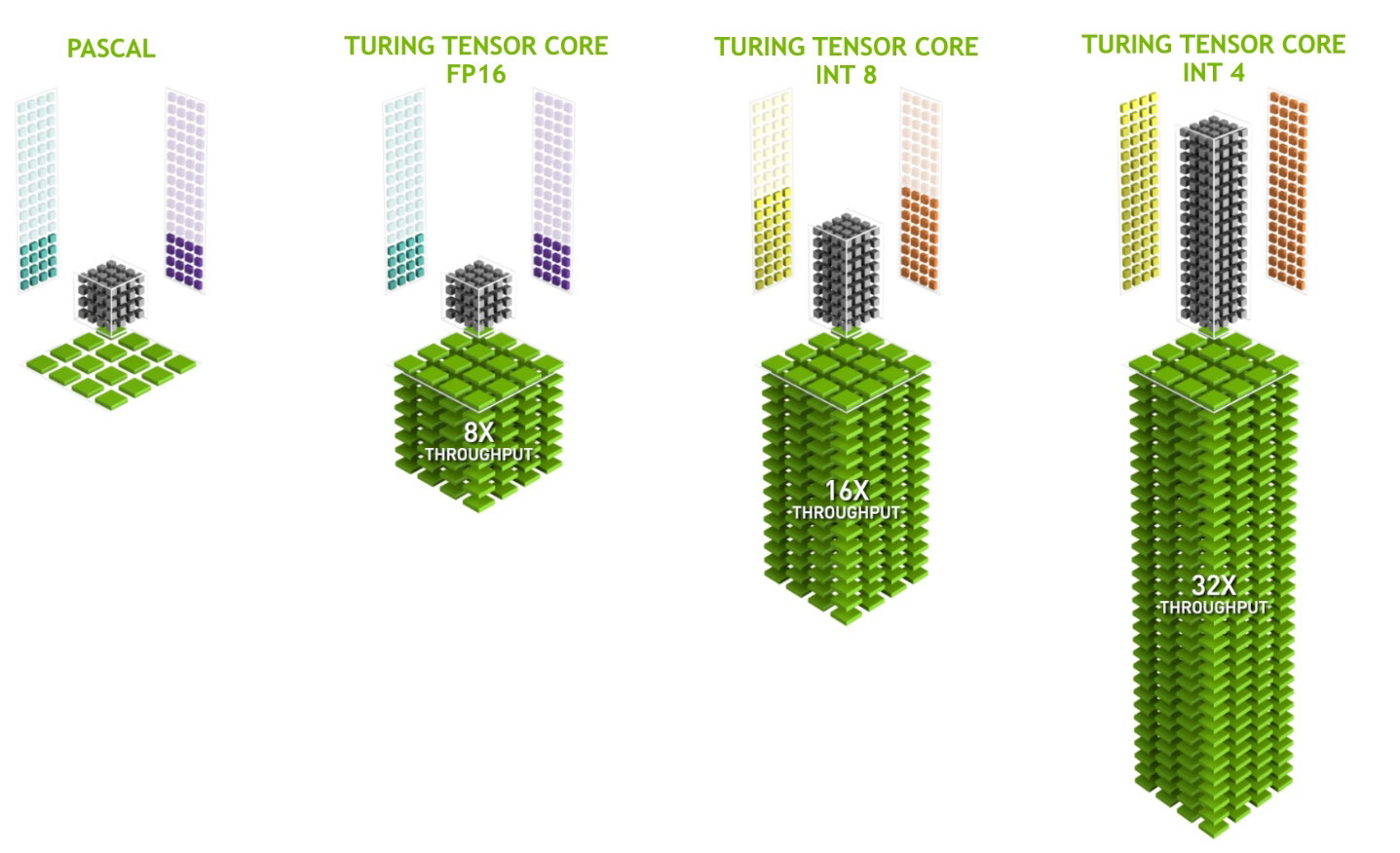
Tuttavia, l’aspetto che più di ogni altro rappresenta il vero e proprio punto di svolta rispetto alle architetture delle passate generazioni, riguarda senz’altro l’implementazione, sempre all’interno dello Streaming Multiprocessor (SM), di nuove e ancor più specifiche unità computazionali, denominate Tensor Cores e RT Cores. In ognuna delle unità SM presenti in Turing troviamo un quantitativo pari ad 8 unità Tensor Cores a precisione mista, ed 1 unità RT Cores (che analizzeremo nel dettaglio più avanti).
Rispetto a Pascal, la presenza delle unità Tensor Cores aggiunge le modalità di precisione INT8 e INT4, capaci di gestire operazioni quantistiche. Inoltre è pienamente supportata la modalità FP16 per carichi di lavoro che richiedono un maggior livello di precisione. NVIDIA dichiara una potenza elaborativa di picco pari a ben 114 TFLOPS in FP16, 228 TOPS in INT8 e ben 455 TOPS in INT4.
Grazie ai Tensor Cores viene sdoganato il deep-learning anche in ambito gaming; nello specifico verranno accelerate alcune funzionalità basate sull’intelligenza artificiale dei servizi neurali NVIDIA NGX al fine di migliorare la qualità grafica nei titoli di nuova generazione, il rendering ed altre applicazioni lato client. Alcuni esempi di funzionalità NGX AI sono il Deep-Learning Super Sampling (DLSS), l’AI InPainting, l’AI Super Rez e l’AI Slow-Mo.
Nella massima espressione di Turing, rappresentata dalla variante completa del processore grafico di fascia alta TU102, sono implementati un totale di ben 576 Tensor Cores, come anticipato 8 per ognuna delle unità SM presenti, e 2 per ogni blocco di elaborazione previsto all’interno della SM stessa.
Ognuno di essi può eseguire fino a 64 operazioni FMA (Fused Multiply-add) in virgola mobile per ciclo di clock utilizzando input FP16. Moltiplicando questo dato per il quantitativo di unità previste all’interno di ogni SM otteniamo un totale di 512 operazioni di tipo FP16 oppure 1.024 operazioni FP per ogni ciclo di clock. La nuova modalità di precisione INT8 è in grado di operare al doppio di questa velocità, arrivando ad eseguire un massimo pari a ben 2.048 operazioni Integer per ciclo di clock.
Sottosistema di Memoria GDDR6
Poiché le risoluzioni dello schermo continuano ad aumentare e le funzionalità shader e le tecniche di rendering diventano sempre più complesse, la larghezza di banda e la capacità complessiva della memoria video dedicata giocano un ruolo sempre più rilevante nelle prestazioni dei moderni processori grafici. Per mantenere un livello di frame rate e una velocità di calcolo più elevati possibili, la GPU non solo ha bisogno di più larghezza di banda di memoria, ma necessita anche di un ampio quantitativo di memoria dedicata da cui attingere per offrire prestazioni costanti e sostenute.
Proprio per questi motivi NVIDIA lavora, da diverso tempo, a stretto contatto con le principali realtà dell’industria DRAM così da implementare in ogni sua GPU la migliore e più avanzata tecnologia di memoria disponibile. Se in passato abbiamo assistito a soluzioni grafiche dotate, per la prima volta in assoluto, di prestanti ed innovative HBM2 e GDDR5X, con Turing assistiamo al debutto ufficiale, in ambito consumer, delle nuovissime memorie GDDR6.
Certamente questa nuova tipologia rappresenta un grande passo avanti nella progettazione della memoria DRAM GDDR ad elevate prestazioni, tuttavia non bisogna pensare che la sua implementazione non abbia richiesto comunque notevoli sforzi. Gli ingegneri NVIDIA, infatti, hanno dovuto ridisegnare completamente il circuito I/O ed il canale di comunicazione tra la GPU e i moduli di memoria stessi, al fine di garantire la massima stabilità ed efficienza a frequenze di funzionamento così elevate.

Il sottosistema di memoria di Turing vanta una frequenza di clock pari a ben 14Gbps, assicurando così un miglioramento dell’efficienza energetica del 20% rispetto alla memoria GDDR5X utilizzata nelle GPU Pascal di fascia alta. Con il nuovo design viene ridotto al minimo il rumore e le variazioni dovute al processo, alla temperatura e alla tensione di alimentazione, inoltre, grazie ad un più ampio clock-gating viene notevolmente ridotto il consumo di energia durante i periodi di minore utilizzo, con conseguente e significativo miglioramento dell’efficienza energetica complessiva.

![Cop – INNO3D GeForce RTX 4060 8GB TWIN X2 [N40602-08D6-173051N]](https://www.hwlegend.tech/wp-content/uploads/2023/12/Cop-INNO3D-GeForce-RTX-4060-8GB-TWIN-X2-N40602-08D6-173051N-150x150.webp "INNO3D GeForce RTX 4060 8GB TWIN X2 [N40602-08D6-173051N]")
![Cop – ASRock Radeon RX 7600 XT 16GB Steel Legend OC [RX7600XT-SL-16GO]](https://www.hwlegend.tech/wp-content/uploads/2024/02/Cop-ASRock-Radeon-RX-7600-XT-16GB-Steel-Legend-OC-RX7600XT-SL-16GO-150x150.webp "ASRock Radeon RX 7600 XT 16GB Steel Legend OC [RX7600XT-SL-16GO]")



