



NVIDIA Ampere: Uno sguardo alla nuova architettura
Indice

Sin dall’invenzione della prima GPU (Graphics Processing Unit) al mondo nell’ormai lontano 1999, le soluzioni NVIDIA sono state costantemente in prima linea nella grafica 3D e nell’elaborazione accelerata, con accorgimenti mirati a fornire livelli rivoluzionari di prestazioni ed efficienza. La nuovissima famiglia di processori grafici basati su architettura Ampere non fa ovviamente eccezione, ed è espressamente progettata per accelerare numerose tipologie di applicazioni e carichi di lavoro ad alta intensità.
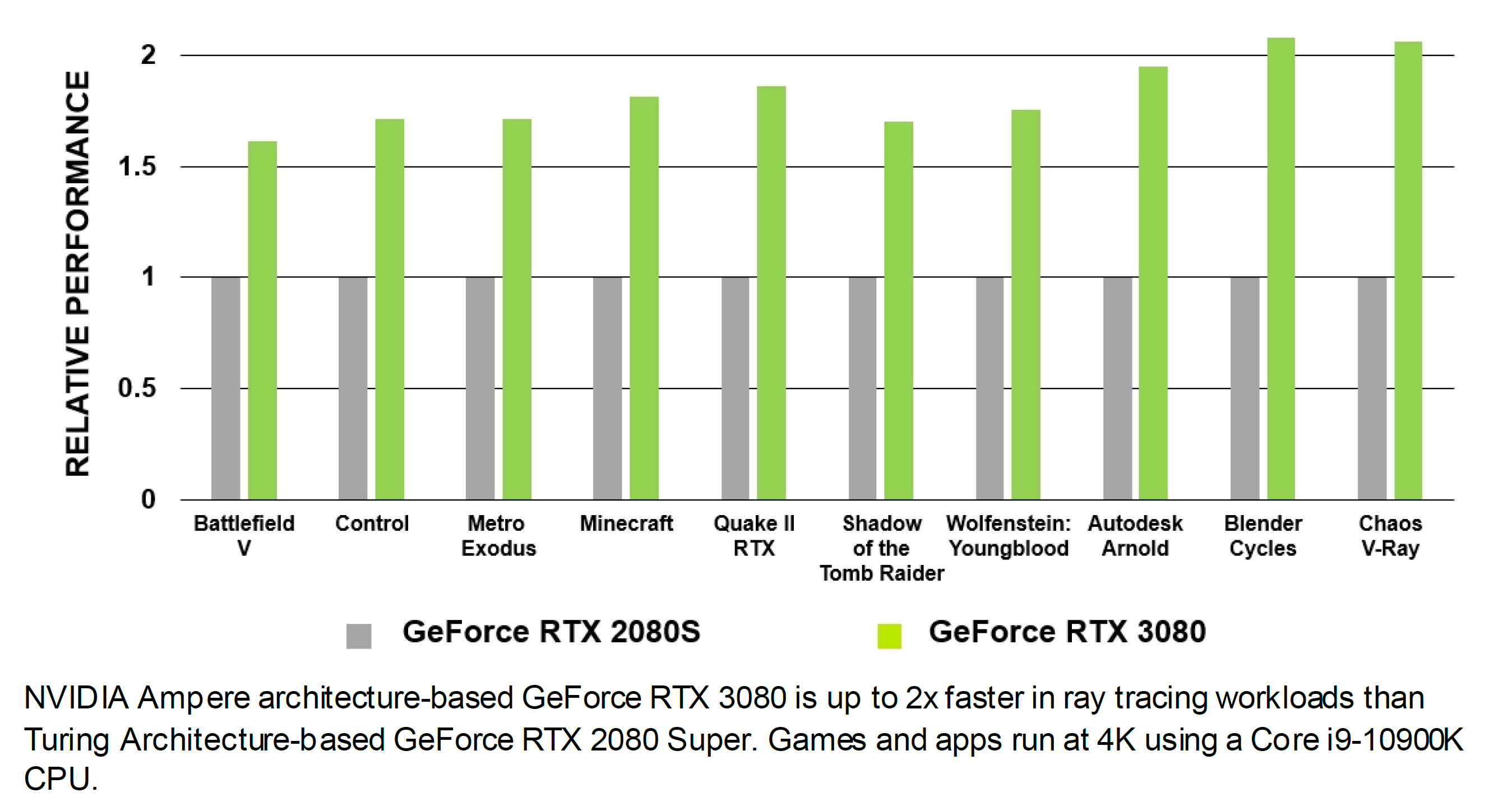
Rilasciata ufficialmente nel corso del mese di maggio dello scorso anno, la prima GPU Ampere, meglio nota con il nome in codice A100, offre incredibili accelerazioni per l’addestramento e l’inferenza AI, i carichi di lavoro HPC e le applicazioni di analisi dei dati. Le declinazioni pensate per il mercato consumer, identificate con i nomi in codice GA10x, riprendono grossomodo quando già osservato in occasione della presentazione delle altrettanto rivoluzionarie soluzioni Turing, introducendo però una serie di nuove funzionalità e ottimizzazioni, mirate ad ottenere un livello di performance significativamente superiore. Il colosso di Santa Clara, infatti, stima come Ampere sia 1,7 volte più veloce nei carichi di lavoro basati sulla tradizionale rasterizzazione e fino a ben 2 volte più veloce nel ray-tracing in tempo reale.

Ancora una volta vengono puntati i riflettori su quello che molti definiscono come il “Santo Graal” nel campo del rendering grafico computerizzato, ovvero il ray-tracing in tempo reale, anche in sistemi a singola GPU. I nuovi processori grafici NVIDIA basati su architettura Ampere, infatti, implementano migliori e ancor più sofisticate unità dedicate all’esecuzione delle operazioni di ray-tracing (denominate per l’appunto “RT Cores”), eliminando così dispendiosi e poco efficienti approcci basati sull’emulazione software.
Queste nuove unità, combinate con la tecnologia software proprietaria NVIDIA RTX e con sofisticati algoritmi di filtraggio, consentono un rendering in ray-tracing in tempo reale, includendo oggetti e ambienti fotorealistici con ombre, riflessi e rifrazioni fisicamente precise.
L’architettura Ampere non solo migliora le già ottime funzionalità di ombreggiatura avanzate introdotte nella passata generazione, atte a migliorare le prestazioni, la qualità dell’immagine ed offrire nuovi livelli di complessità geometrica, ma ne introduce di nuove, tra cui il Ray-Traced Motion Blur accelerato in hardware, che osserveremo con più attenzione più avanti.
Non mancano poi tutti i miglioramenti apportati alla piattaforma CUDA dedicati alla capacità, alla flessibilità, alla produttività e alla portabilità delle applicazioni di elaborazione. Funzioni quali la programmazione indipendente dei Thread, il Multi-Process Service (MPS) accelerato via hardware, e gruppi cooperativi fanno tutti parte di questa nuova architettura NVIDIA.
Ampere è inoltre la prima architettura ad essere sviluppata con la recente ed avanzata tecnologia produttiva a 8 nanometri custom NVIDIA (8N), messa a punto dalla coreana Samsung e capace di garantire non soltanto un deciso incremento dell’efficienza energetica ma soprattutto di offrire la possibilità di integrare un maggior quantitativo di unità di calcolo, grazie ad una densità superiore, e nuove funzionalità all’interno del processore grafico.
NVIDIA ha da tempo dimostrato in modo inequivocabile come una migliore tecnologia produttiva possa incidere in maniera decisa nella fase di progettazione dell’architettura, consentendo agli ingegneri di apportare modifiche e ottimizzazioni particolari, come il perfezionamento delle latenze e la pulizia dei vari segnali, mirate a garantire prestazioni e frequenze operative in precedenza impensabili, pur senza stravolgerne le fondamenta. Nei paragrafi che seguono andremo a descrivere quelle che sono le più significative differenze e novità introdotte con la nuova architettura.
Ampere Streaming Multiprocessor (SM) e nuove unità Tensor Cores
Una delle principali differenze architetturali rispetto alla passata generazione riguarda le unità Streaming Multiprocessor (SM), ancora una volta comprensive di molte delle funzionalità implementate nelle soluzioni professionali, ma ora capaci di un throughput doppio per quanto riguarda le operazioni in virgola mobile (FP32).
Secondo la stessa NVIDIA, questo genere di operazioni rappresenta la maggior parte del carico di lavoro medio in ambito grafico, di conseguenza sono state previste sostanziali differenze in termini di approccio rispetto alla passata generazione al fine di incrementare sia l’efficienza che le prestazioni, introducendo un’elaborazione FP32 a doppia velocità. Nelle precedenti soluzioni Turing ogni partizione SM poteva seguire due datapath principali, uno per l’elaborazione di operazioni su interi (INT32) e uno per l’elaborazione di operazioni virgola mobile (FP32).
Questo consentiva la possibilità di elaborare, per ogni ciclo di clock, un massimo di 16 operazioni INT32 e di 16 operazioni FP32. Con le nuove Ampere ci sono stati dei cambiamenti abbastanza significativi; entrambi i due datapath principali sono ora in grado di elaborare operazioni FP32 (il primo percorso combina INT32 ed FP32, mentre il secondo soltanto FP32), con il risultato che ogni partizione SM può elaborare, per ogni ciclo di clock, o le solite 16 operazioni INT32 + 16 operazioni FP32, oppure un massimo di ben 32 operazioni FP32.

I carichi di lavoro dei moderni videogiochi 3D prevedono un’ampia gamma di esigenze di elaborazione. Molti di questi si basano su un mix di istruzioni aritmetiche FP32, come FFMA, addizioni in virgola mobile (FADD) o moltiplicazioni in virgola mobile (FMUL), insieme a molte istruzioni intere più semplici per indirizzare e recuperare dati, confrontare o elaborare i risultati.
L’aggiunta di funzionalità in virgola mobile al secondo percorso dati è indubbiamente in grado di assicurare un contributo notevole. I miglioramenti delle prestazioni varieranno a livello di shader e applicazione a seconda della combinazione di istruzioni, più vi sarà uno sfruttamento pesante in termini di operazioni in virgola mobile e più la differenza in performance rispetto a Turing sarà marcata. NVIDIA evidenzia come il raddoppio del throughput FP32 incida anche in ambito Ray-Tracing, precisamente per quanto riguarda le operazioni di Denoising, oppure in applicativi professionali quali V-Ray e similari.
Del tutto invariato il quantitativo di unità SM per ogni blocco TPC (Thread/Texture Processing Clusters), sempre pari a due unità, così come in Turing. Ognuna di queste integra al proprio interno 64 core FP32/INT32 e altrettanti core FP32, di tipo concurrent, ovvero in grado di operare in parallelo e contemporaneamente.
Proprio questo aspetto rappresentava una delle differenze più significative, e con il maggior impatto in termini di performance, introdotte con l’architettura Turing. Il colosso californiano, infatti, aveva evidenziato un deciso incremento dell’efficienza, ricordando che per ogni 100 istruzioni in virgola mobile il processore grafico si trova a dover processare almeno 36 istruzioni di tipo integer, e sottolineando così come la possibilità di operare in parallelo e in contemporanea su l’una o l’altra tipologia di istruzione rappresenti un punto chiave delle moderne architetture grafiche.
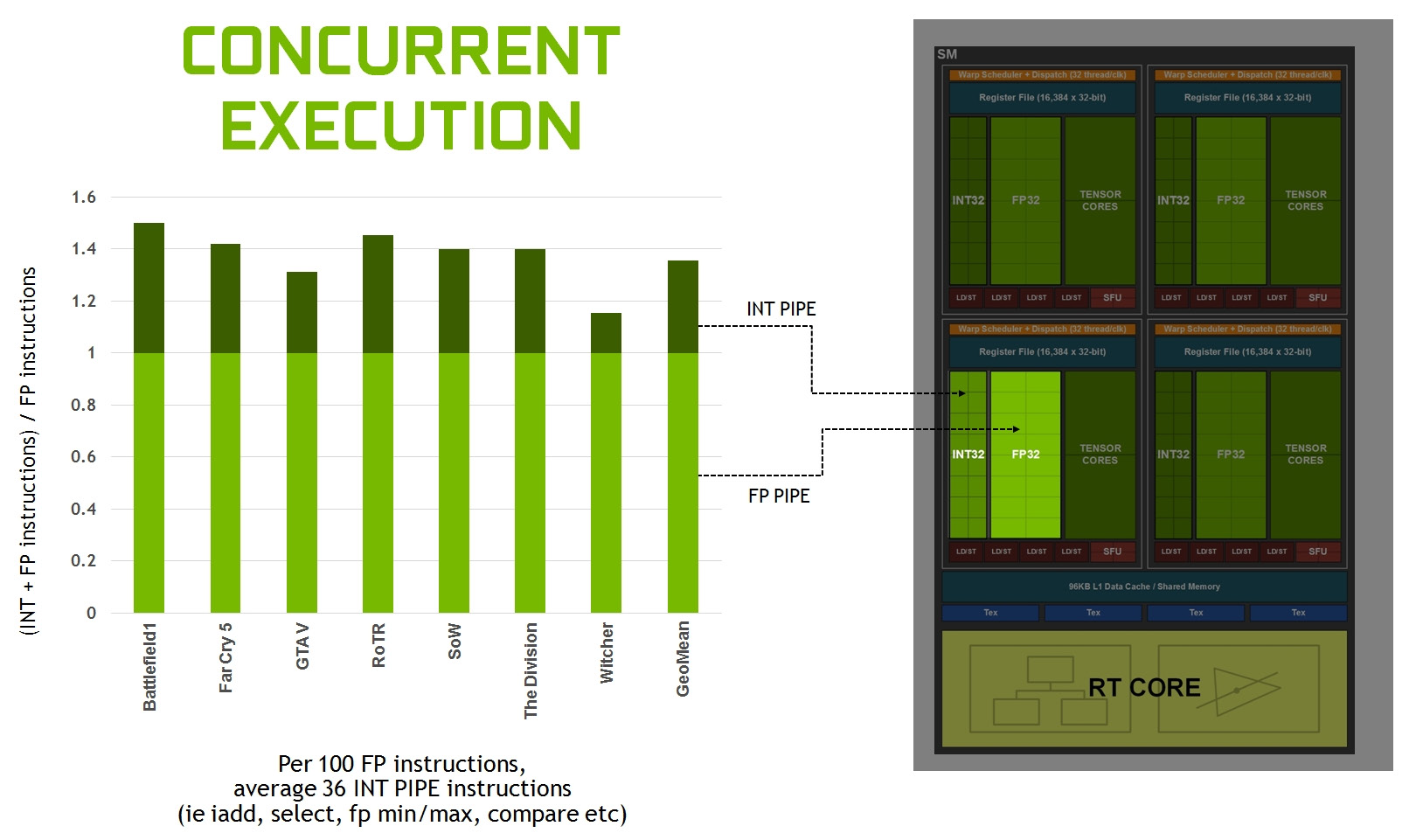
Ad essere radicalmente rivista ed ottimizzata è stata anche l’architettura della Cache e della memoria condivisa (Shared Memory), ora basate su un design di tipo unificato in grado di essere riconfigurato a seconda del carico di lavoro per allocare più memoria per la L1 o per la memoria condivisa a seconda delle necessità. La capacità della cache di dati L1 è aumentata a 128 KB per ogni SM, contro i 96 KB previsti in Turing. In modalità di calcolo sono ora supportate le seguenti configurazioni:
- 128 KB L1 + 0 KB Shared Memory;
- 120 KB L1 + 8 KB Shared Memory;
- 112 KB L1 + 16 KB Shared Memory;
- 96 KB L1 + 32 KB Shared Memory;
- 64 KB L1 + 64 KB Shared Memory;
- 28 KB L1 + 100 KB Shared Memory.
Oltre ad incrementare le dimensioni della memoria cache L1 del 33% (dai 6912KB di TU102 a ben 10752KB di GA102), è stata raddoppiata anche la larghezza di banda della memoria condivisa, con prestazioni che raggiungono i 128 byte/clock per SM contro i 64 byte/clock della soluzione Turing. La larghezza di banda L1 totale della nuova GeForce RTX 3080 raggiunge quota 219 GB/sec contro i 116 GB/sec della precedente soluzione GeForce RTX 2080 SUPER.
L’insieme di questi interventi assicura un significativo impatto sulle prestazioni, semplificando allo stesso tempo la programmazione e l’ottimizzazione necessaria all’ottenimento di prestazioni prossime al picco massimo. Sempre all’interno dello Streaming Multiprocessor (SM), troviamo le unità computazionali specifiche che hanno rappresentato il vero e proprio punto di svolta rispetto alle architetture pre-Turing, ovvero Tensor Cores e RT Cores, giunte rispettivamente alla terza e alla seconda generazione.
In ognuna delle unità SM presenti in Ampere troviamo un quantitativo pari a 4 unità Tensor Cores a precisione mista, ed 1 unità RT Cores che analizzeremo nel dettaglio più avanti. Rispetto a Turing, quindi, troviamo un numero dimezzato di unità Tensor Cores, tuttavia ognuna di quelle ora presenti vanta, come vedremo, potenzialità di gran lunga superiori. Le unità Tensor Cores osservate in occasione della presentazione dell’architettura Turing, introducevano le modalità di precisione INT8 e INT4, capaci di gestire operazioni quantistiche e supportavano appieno, inoltre, la modalità FP16 per carichi di lavoro che richiedono un maggior livello di precisione.
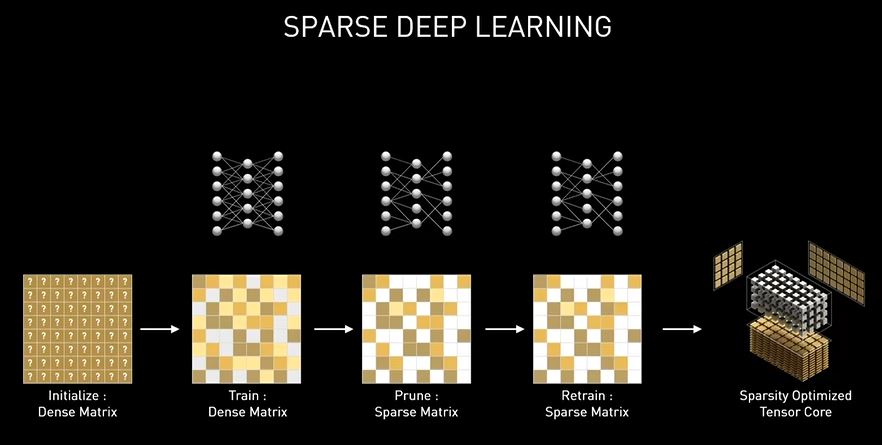
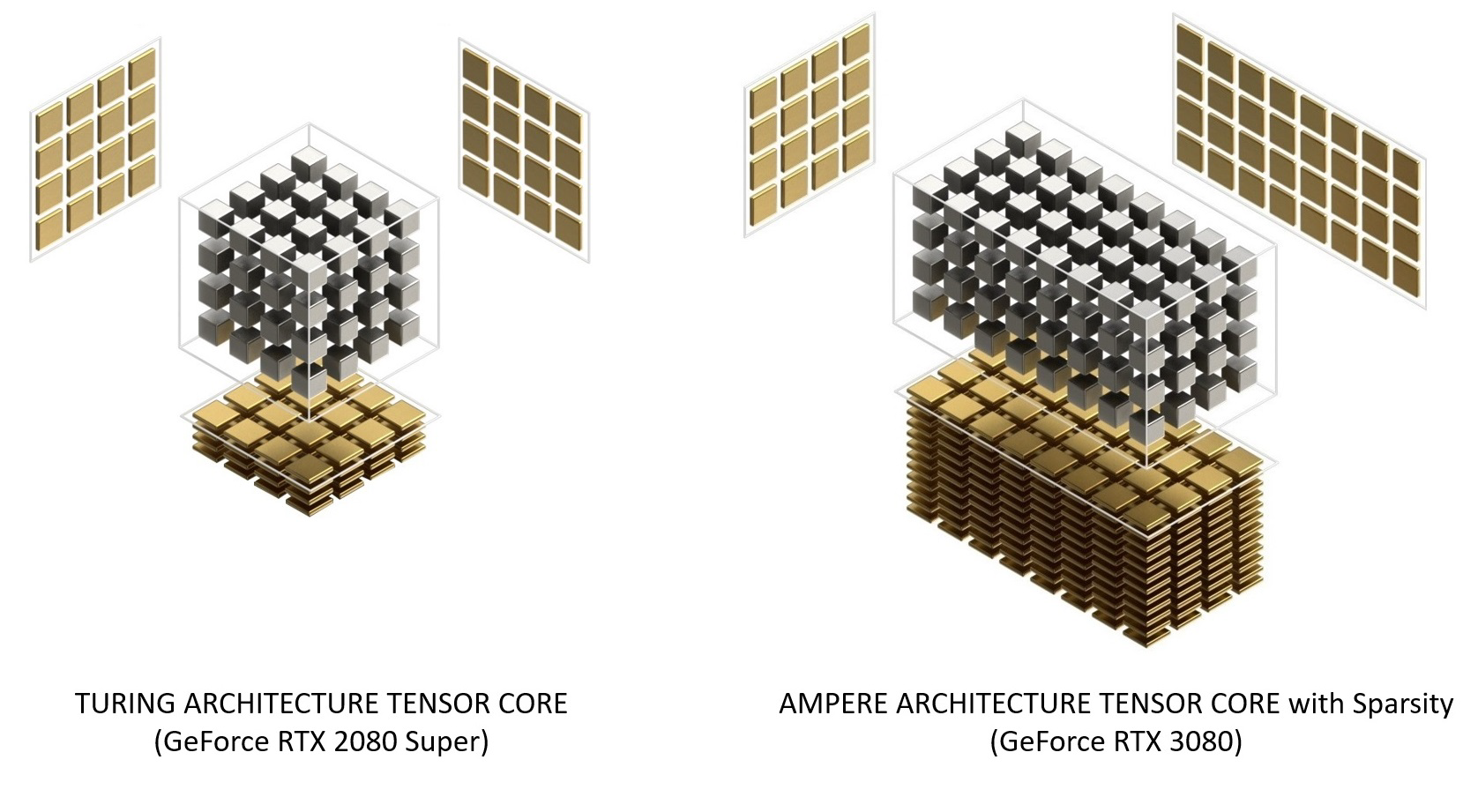
I nuovi Tensor Cores dell’architettura Ampere sono stati riorganizzati per migliorarne l’efficienza e ridurre il consumo energetico. Con la terza generazione di queste unità vengono accelerati ancor più tipi di dati e viene implementato il supporto hardware per l’elaborazione di matrici con pattern sparsi, assicurando un raddoppio del throughput anche grazie alla possibilità di saltare elementi non necessari.
Nella configurazione GA10x ogni SM ha il doppio del throughput di un Turing SM durante l’elaborazione di matrici sparse, pur mantenendo lo stesso throughput totale di un Turing SM per le operazioni ad alta densità. Il supporto Sparsity consente ai processori grafici Ampere di fornire in modo efficiente un enorme aumento del throughput rispetto a Turing; basandosi su stime NVIDIA una GeForce RTX 3080 è in grado di offrire un throughput operativo di ben 2,7 volte superiore rispetto ad una precedente GeForce RTX 2080 SUPER.
Sempre prendendo come esempio la soluzione GeForce RTX 3080 scelta da NVIDIA, basata sulla variante semi-completa del processore grafico di fascia alta GA102, troviamo implementati un totale di 272 Tensor Cores, come anticipato 4 per ognuna delle unità SM presenti, e 1 per ogni blocco di elaborazione previsto all’interno della SM stessa.
Ognuno di essi può eseguire fino a 128 operazioni FMA (Fused Multiply-add) in virgola mobile per ciclo di clock utilizzando input FP16, che salgono a ben 256 con matrice sparsa. Moltiplicando questo dato per il quantitativo di unità previste all’interno di ogni SM otteniamo un totale di 512 operazioni di tipo FP16 oppure 1.024 operazioni con matrice sparsa per ogni ciclo di clock.

La funzione Fine-Grained Structured Sparsity può sfruttare le reti di deep learning per raddoppiare il throughput delle operazioni Tensor Core rispetto alla generazione precedente. I Tensor Cores di terza generazione accelerano le funzionalità di intelligenza artificiale come NVIDIA DLSS per la AI Super-Resolution (ora con supporto fino a 8K), l’app NVIDIA Broadcast per comunicazioni video e vocali ottimizzate con AI e l’app NVIDIA Canvas per la pittura basata su AI.
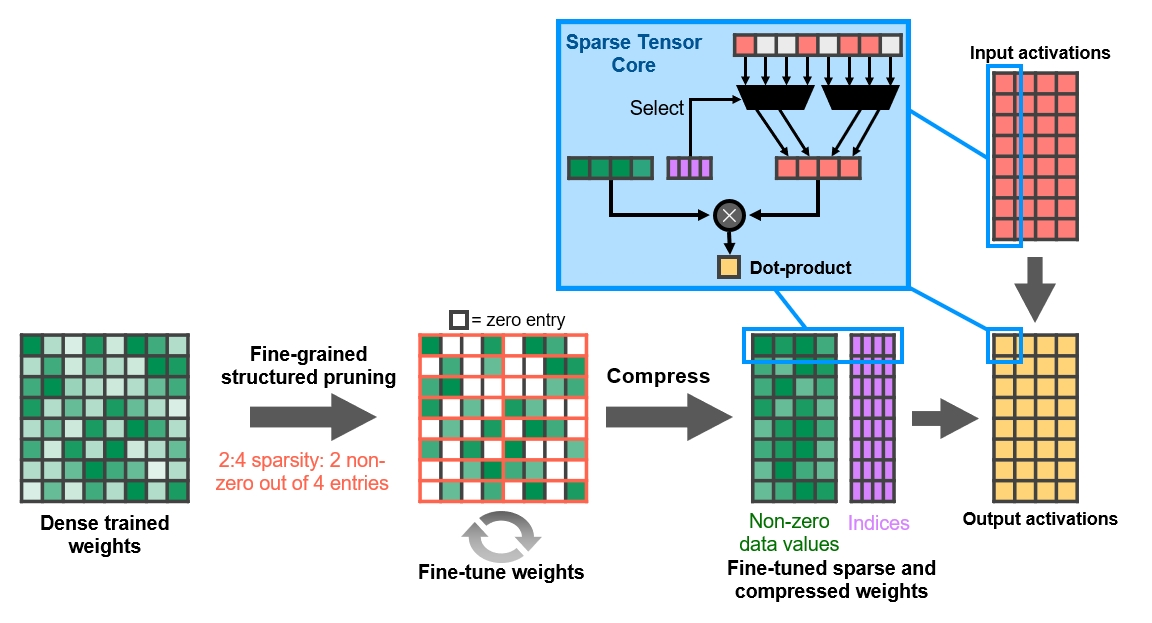
Gli ingegneri NVIDIA hanno scoperto che, poiché le reti di deep learning sono in grado di evolversi durante il processo di formazione in base ai feedback, in generale il vincolo della struttura non influisce sulla precisione della rete addestrata per l’inferenza. Ciò consente di inferire l’accelerazione anche con Sparsity.
Inoltre, il design Tensor Cores di terza generazione aumenta ulteriormente le prestazioni grezze e introduce le nuove modalità di precisione TF32 e BFloat16 dedicate ad alcune funzionalità basate sull’intelligenza artificiale dei servizi neurali NVIDIA NGX. Ad esempio BF16 è un’alternativa a IEEE FP16 e include un esponente a 8 bit, una mantissa a 7 bit e 1 sign-bit. Sia FP16 che BF16 hanno dimostrato di addestrare con successo le reti neurali in modalità a precisione mista, abbinando i risultati dell’addestramento FP32 senza aggiustamento iper-parametrico.
Entrambe le modalità FP16 e BF16 dei Tensor Cores forniscono un throughput matematico 4 volte superiore rispetto allo standard FP32 nelle GPU GA10x. Oggi, la matematica predefinita per l’addestramento AI è FP32, senza l’accelerazione Tensor Core. L’architettura Ampere introduce il pieno supporto per TF32, consentendo di utilizzare i Tensor Core in fase di addestramento AI per impostazione predefinita senza alcuno sforzo da parte dell’utente.
Le operazioni senza unità Tensor dedicate continuano a utilizzare il percorso dati FP32, mentre in modalità TF32 i Tensor Cores leggono i dati FP32 e utilizzano lo stesso intervallo di FP32 con una precisione interna ridotta, prima di produrre un output IEEE FP32 standard. TF32 include un esponente a 8 bit (uguale a FP32), mantissa a 10 bit (stessa precisione di FP16) e 1 sign-bit. La modalità TF32 di una GPU con architettura Ampere offre un throughput doppio rispetto allo standard FP32.
Grazie ai Tensor Cores abbiamo visto sdoganare il deep-learning anche in ambito gaming; nello specifico vengono accelerate alcune funzionalità basate sull’intelligenza artificiale al fine di migliorare la qualità grafica nei titoli di nuova generazione, il rendering ed altre applicazioni lato client. Alcuni esempi di funzionalità NGX AI sono il Deep-Learning Super Sampling (DLSS), l’AI InPainting, l’AI Super Rez e l’AI.
Nuovo sottosistema di Memoria GDDR6X by Micron Technology
Poiché le risoluzioni dello schermo continuano ad aumentare e le funzionalità shader e le tecniche di rendering diventano sempre più complesse, la larghezza di banda e la capacità complessiva della memoria video dedicata giocano un ruolo sempre più rilevante nelle prestazioni dei moderni processori grafici.
Per mantenere un livello di frame rate e una velocità di calcolo più elevati possibili, la GPU non solo ha bisogno di più larghezza di banda di memoria, ma necessita anche di un ampio quantitativo di memoria dedicata da cui attingere per offrire prestazioni costanti e sostenute. Proprio per questi motivi NVIDIA lavora da diverso tempo a stretto contatto con le principali realtà dell’industria DRAM, così da implementare in ogni sua GPU la migliore e più avanzata tecnologia di memoria disponibile.
Se in passato abbiamo assistito a soluzioni grafiche dotate, per la prima volta in assoluto, di prestanti ed innovative HBM2, GDDR5X e GDDR6, con Ampere assistiamo al debutto ufficiale, in ambito consumer, delle nuovissime memorie GDDR6X messe a punto da Micron Technology.
Certamente questa nuova tipologia rappresenta un grande passo avanti nella progettazione della memoria DRAM GDDR ad elevate prestazioni, tuttavia non bisogna pensare che la sua implementazione non abbia richiesto comunque notevoli sforzi. Gli ingegneri NVIDIA, infatti, hanno dovuto ridisegnare completamente il circuito I/O ed il canale di comunicazione tra la GPU e i moduli di memoria stessi, al fine di garantire la massima stabilità ed efficienza a frequenze di funzionamento così elevate.
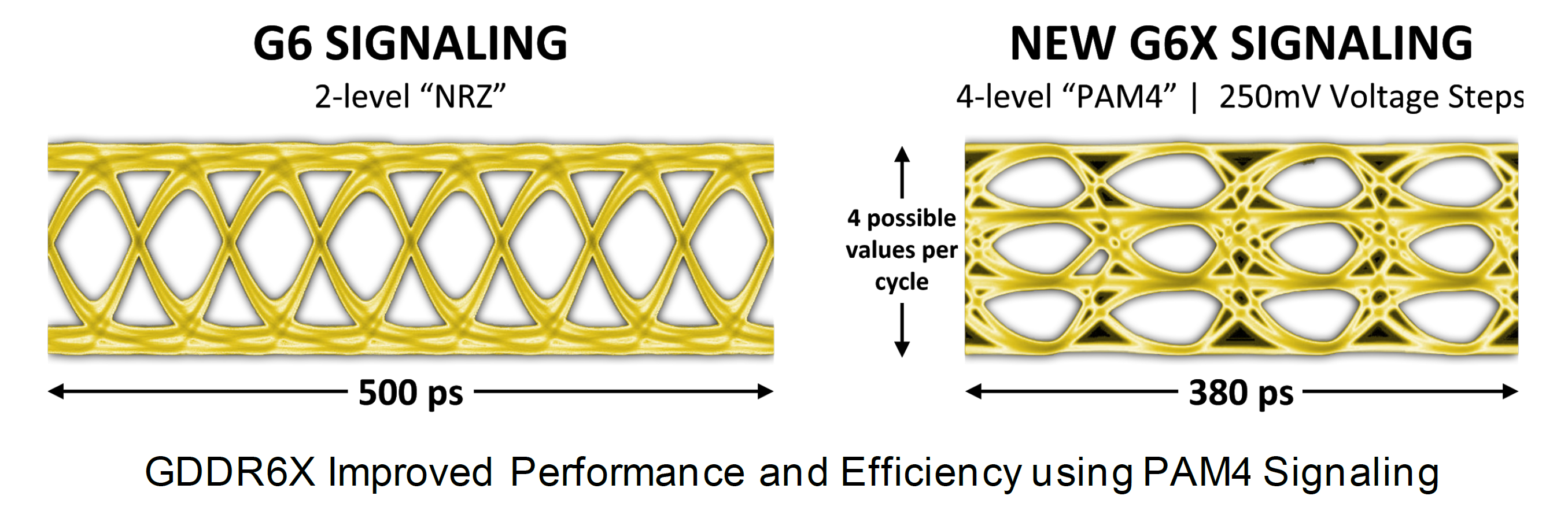
Il sottosistema di memoria di Ampere vanta infatti una frequenza di clock pari a ben 19.5Gbps, aspetto che assicura non soltanto un notevole miglioramento dell’efficienza energetica rispetto alla memoria GDDR6 utilizzata nelle GPU Turing di fascia alta (TU102), ma anche un incremento della larghezza di banda di picco superiore al 50%, raggiungendo per la prima volta su una GPU consumer una bandwith superiore ai 900GB/s. Per ottenere questa svolta, sono state introdotte innovative tecnologie di trasmissione del segnale e di modulazione di ampiezza dell’impulso, così da ridefinire completamente il modo in cui il sottosistema di memoria sposta i dati.
Utilizzando le tecniche di segnale multi-livello PAM4, GDDR6X trasferisce più dati e a una velocità molto più veloce, spostando due bit di informazioni alla volta e raddoppiando la velocità di dati I/O del precedente schema di segnale PAM2/NRZ. I carichi di lavoro affamati di dati, come inferenza AI, Ray-Tracing in tempo reale e rendering video a risoluzione fino ad 8K, possono ora essere alimentati con dati a velocità elevate, aprendo nuove opportunità per il computing e nuove esperienze per l’utente finale.
Nell’immagine riportata poco sopra si nota come la stessa quantità di dati può essere trasferita attraverso l’interfaccia GDDR6X a una frequenza dimezzata rispetto a GDDR6. In alternativa, GDDR6X può raddoppiare la larghezza di banda effettiva rispetto a GDDR6 a una determinata frequenza operativa. Il supporto PAM4 rappresenta un grande aggiornamento rispetto all’NRZ a due livelli previsto nelle memorie GDDR6.
Invece di trasmettere due bit di dati ogni ciclo di clock (un bit sul fronte di salita e un bit sul fronte di discesa del clock), PAM4 invia due bit per fronte di clock, codificati utilizzando quattro diversi livelli di tensione. I livelli di tensione sono divisi in passi di 250mV, con ogni livello che rappresenta due bit di dati – 00, 01, 10 o 11 inviati su ogni fronte di clock (sempre tecnologia DDR).

Con il nuovo design viene ridotto al minimo il rumore e le variazioni dovute al processo, alla temperatura e alla tensione di alimentazione, inoltre, grazie ad un più ampio clock-gating viene notevolmente ridotto il consumo di energia durante i periodi di minore utilizzo, con conseguente e significativo miglioramento dell’efficienza energetica complessiva.
Tecnologia di Compressione della Memoria
Le GPU NVIDIA utilizzano ormai da tempo diverse tecniche di compressione della memoria al fine di ridurre le esigenze di larghezza di banda grazie all’archiviazione in formato compresso, e senza perdita di qualità, dei dati di colore del frame buffer con possibilità, da parte del processore grafico, sia di lettura che di scrittura degli stessi. La riduzione della larghezza di banda garantita dalla compressione della memoria offre una serie di vantaggi, tra cui:
- Riduzione della quantità di dati scritti verso la memoria;
- Riduzione della quantità di dati trasferiti dalla memoria alla Cache L2 (un blocco di pixel compresso, infatti, produrrà un ingombro sulla memoria inferiore rispetto a un blocco non compresso);
- Riduzione del quantitativo di dati trasferiti tra differenti client (come ad esempio tra le Texture Unit ed il Frame Buffer).
La pipeline di compressione del processore grafico prevede diversi algoritmi pensati per determinare in maniera intelligente il modo più efficace per comprimere i dati. Tra questi, quello indubbiamente più significativo è rappresentato dalla tecnica di compressione del colore di tipo Delta (Delta Color Compression), ossia la capacità della GPU di analizzare le differenze tra il colore dei pixel presenti all’interno di un blocco, che verrà successivamente memorizzato come riferimento, ed i successivi blocchi che compongono il dato completo.
In questa maniera anziché utilizzare un grosso quantitativo di spazio per registrare la mole di dati nella sua interezza, verrà immagazzinato esclusivamente l’insieme di pixel di riferimento con l’aggiunta dei valori differenti (per l’appunto “delta”) rilevati rispetto allo stesso. Di conseguenza, se il delta tra un blocco e l’altro è sufficientemente piccolo saranno necessari solamente pochi bit per identificare il colore dei singoli pixel, riducendo nettamente lo spazio necessario per la memorizzazione dei dati.
Con la nuova architettura sono stati ulteriormente migliorati i già ottimi ed avanzati algoritmi di compressione della memoria implementati nelle soluzioni della passata generazione, offrendo così un ulteriore incremento dell’ampiezza di banda effettiva e contribuendo a ridurre in maniera ancor più marcata la quantità di byte che il processore grafico deve recuperare dalla memoria per singolo frame.
L’insieme di queste migliorie, in abbinamento all’impiego dei nuovi moduli di memorie GDDR6X operanti a ben 19.5Gbps, assicura un notevole aumento dell’ampiezza di banda effettiva, aspetto di fondamentale importanza per mantenere l’architettura bilanciata e sfruttare nel migliore dei modi la architettura delle unità SM.
Nuove unità RT Cores e Ray-Traced Motion Blur
Il ray-tracing è una tecnologia di rendering estremamente impegnativa dal punto di vista computazionale, capace di simulare realisticamente l’illuminazione di una scena e dei suoi oggetti. In ambito professionale e cinematografico, seppur si faccia uso massiccio, ormai da diversi anni, di questa tecnica, sfruttando ad esempio gli strumenti Iray ed OptiX messi a disposizione da NVIDIA, non è mai stato possibile riprodurre tali effetti in alta qualità ed in tempo reale, specialmente affidandosi ad un singolo processore grafico.

Sempre a causa di questa sua natura intensiva in termini di elaborazione, questa tecnica non ha mai trovato impiego in ambito videoludico per attività di rendering significative. Come ben noto, infatti, i giochi che richiedono animazioni fluide ad elevati framerate si basano su ormai rodate tecniche di rasterizzazione, in quanto meno impegnative da gestire. Seppur scene rasterizzate possono vantare tutto sommato un bell’aspetto, non mancano purtroppo limitazioni significative che ne compromettono il realismo.
Ad esempio, il rendering di riflessi e ombre, utilizzando esclusivamente la rasterizzazione, necessita di semplificazioni di presupposti che possono causare diversi tipi di artefatti. Allo stesso modo, le scene statiche possono sembrare corrette fino a quando qualcosa non si muove, le ombre rasterizzate spesso soffrono di aliasing e fughe di luce e le riflessioni nello spazio possono riflettere solo gli oggetti visibili sullo schermo. Questi artefatti, oltre che compromettere il livello di realismo dell’esperienza di gioco, per essere in parte risolti obbligano gli sviluppatori a ricorrere ad effetti e filtri supplementari, con ovvio aumento delle richieste necessarie in termini di potenza elaborativa.
L’implementazione del ray-tracing in tempo reale su singola GPU è stata un’enorme sfida tecnica, che ha richiesto a NVIDIA quasi dieci anni di ricerca, progettazione e stretta collaborazione con i suoi migliori ingegneri in campo software. Tutti questi sforzi hanno portato alla messa a punto della tecnologia software NVIDIA RTX e di unità hardware specifiche espressamente dedicate al ray-tracing, denominate RT Cores e implementate per la prima volta nel 2018, in occasione del debutto di processori grafici basati su architettura Turing.

L’approccio scelto da NVIDIA appare del tutto intelligente, prevedendo una combinazione ibrida tra le due sopracitate tecniche di rendering. In questa maniera la rasterizzazione continuerà ad essere utilizzata laddove è più efficace, allo stesso tempo il ray-tracing verrà previsto esclusivamente negli ambiti nei quali è in grado di assicurare il maggior vantaggio visivo, come nel rendering dei riflessi, delle rifrazioni e delle ombre. A detta del colosso americano questo approccio rappresenta ad oggi il miglior compromesso possibile tra qualità e realismo grafico e onere computazionale. Nell’immagine che segue viene illustrato, in modo schematico, il funzionamento della nuova pipeline di rendering ibrida:
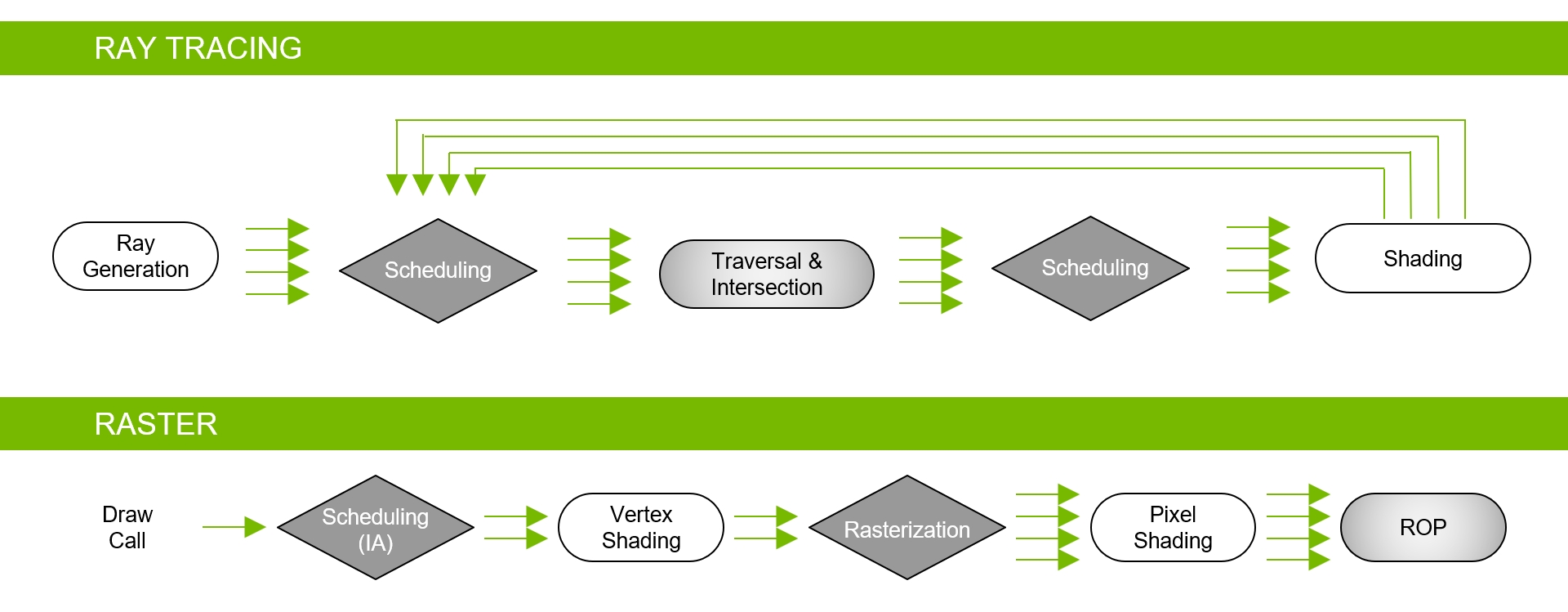
Anche se questi moderni processori grafici consentono un ray-tracing in tempo reale, il numero di raggi primari o secondari espressi per pixel o superficie varia in base a numerosi fattori, tra cui la complessità della scena, la risoluzione, gli ulteriori effetti grafici renderizzati nella scena stessa e, naturalmente, la potenza elaborativa del processore grafico.
Non dobbiamo di conseguenza aspettarci che centinaia di raggi debbano o possano essere rappresentati in tempo reale. Sono, infatti, necessari molti meno raggi per pixel quando si utilizza l’accelerazione tramite RT Cores in combinazione con tecniche di filtraggio di riduzione del rumore avanzate. NVIDIA ha quindi messo a punto degli specifici moduli denominati Denoiser-Tracing, capaci di sfruttare appositi algoritmi basati sull’intelligenza artificiale allo scopo di ridurre in modo significativo il quantitativo di raggi per pixel richiesti pur senza compromettere in maniera marcata la qualità dell’immagine.
Un esempio pratico di questo interessante approccio è stato mostrato nella demo Reflections creata dalla Epic Games in collaborazione con ILMxLAB e NVIDIA. L’implementazione del ray-tracing in tempo reale nel motore grafico Unreal Engine 4 sfrutta le API Microsoft DXR e la tecnologia NVIDIA RTX per portare su schermo illuminazioni, riflessioni, ombre e occlusione ambientale di qualità cinematografica, il tutto eseguito su una singola GPU Quadro RTX 6000 o GeForce RTX 2080 Ti.

Con la nuovissima architettura Ampere debutta anche la seconda generazione di unità RT Cores, unità rese ancor più prestanti ed efficienti rispetto al passato. NVIDIA stima una gestione delle intersezioni raggi-triangoli a velocità doppia rispetto alla scorsa generazione. Le nuove unità RT Cores, inoltre, confermano il pieno supporto verso le tecnologie di ray-tracing NVIDIA RTX e OptiX, le API Microsoft DXR e le più recenti API Vulkan Ray-Tracing, e possono accelerare le tecniche utilizzate in molte delle seguenti operazioni di rendering e non-rendering:
- Riflessioni e Rifrazioni;
- Ombre e Occlusione ambientale;
- Illuminazione Globale;
- Baking istantanea e offline della lightmap;
- Immagini e anteprime in alta qualità;
- Raggi primari nel rendering VR;
- Occlusion Culling;
- Fisica, rilevamento delle collisioni e simulazioni di particelle;
- Simulazioni audio (ad esempio tramite NVIDIA VRWorks Audio basata sull’API OptiX);
- Intelligenza artificiale;
- In-engine Path Tracing (non in tempo reale) per generare immagini di riferimento per la messa a punto di tecniche di rendering in tempo reale di eliminazione del rumore, composizione del materiale e illuminazione della scena.
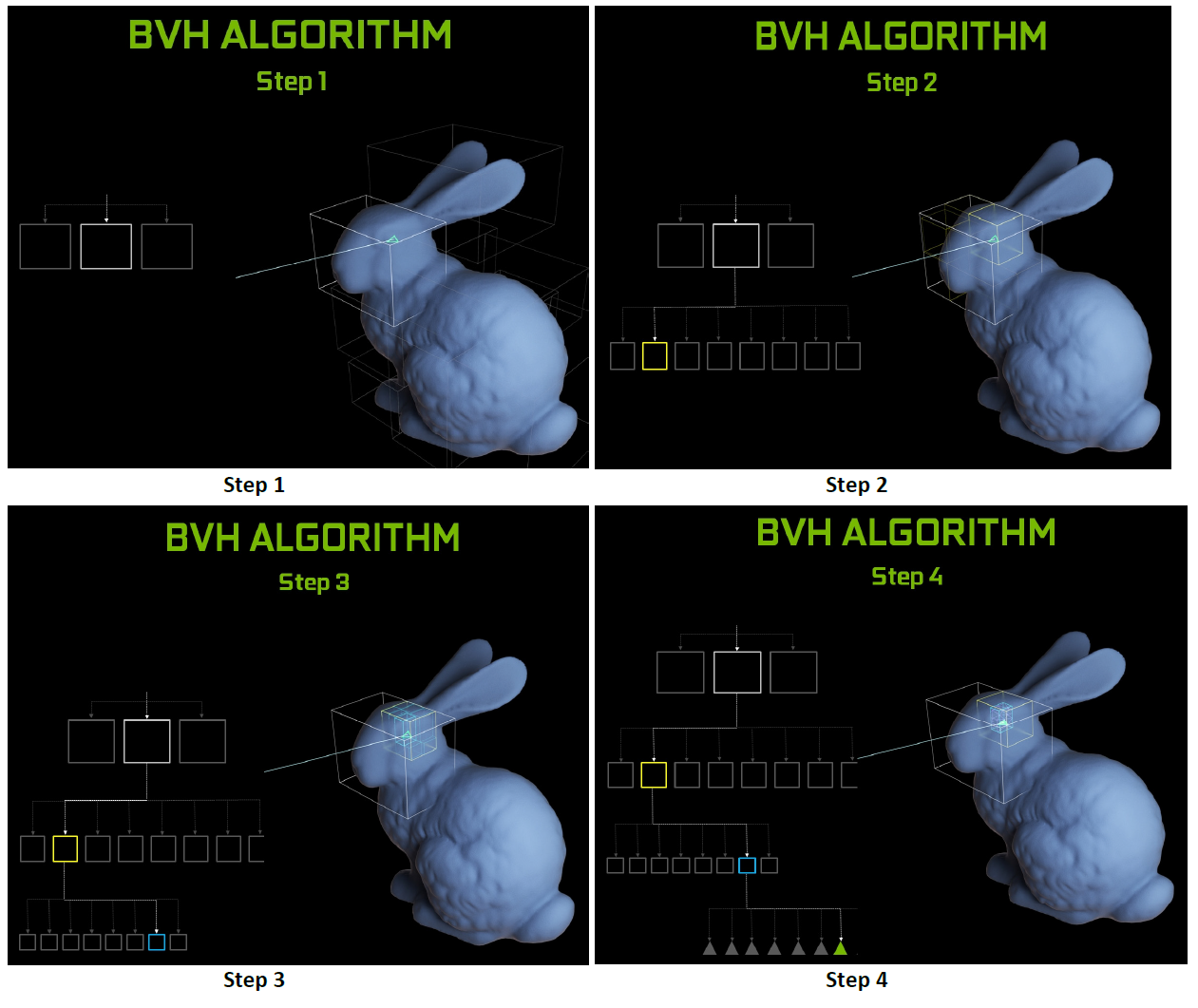
Gli RT Cores, inoltre, sono in grado di gestire in hardware la cosiddetta Bounding Volume Hierarchy (BVH), un particolare algoritmo di scomposizione gerarchica delle superfici tridimensionali che finora richiedeva un’emulazione di tipo software per essere eseguita. Nello specifico l’obiettivo è quello di individuare tutti quei triangoli che incrociano effettivamente uno dei raggi di luce presenti nella scena.
Le unità hardware lavorano insieme ad avanzati filtri di denoising all’interno dell’efficiente struttura di accelerazione della BVH sviluppata dagli ingegneri NVIDIA al fine di ridurre drasticamente la mole di lavoro a carico delle SM, consentendo a queste ultime di dedicarsi ad altre tipologie di operazioni, quali l’ombreggiatura dei pixel e dei vertici e quant’altro. Funzioni come la costruzione e il refitting BVH sono gestite direttamente dai driver, mentre la generazione e l’ombreggiatura dei raggi sono a carico dell’applicazione attraverso nuovi tipi di shader.
Per comprendere meglio la funzione dei nuovi RT Cores e cosa accelerano esattamente, dovremmo prima spiegare come viene eseguito il ray-tracing su GPU o CPU senza un motore hardware dedicato. In questo caso, come descritto da NVIDIA, sono gli shader a lanciare il cosiddetto “raggio sonda” che innesca il processo BVH vero e proprio, comprendente tutti i suddetti test di intersezione raggio/triangolo.
A seconda della complessità della scena da elaborare possono essere necessari migliaia di slot di istruzioni per ogni raggio proiettato fino al momento in cui non verrà effettivamente colpito un triangolo, che sarà successivamente colorato sulla base del punto di intersezione (o se al contrario non ne viene colpito alcuno, il colore di sfondo può essere usato per l’ombreggiatura del pixel stesso). Stiamo parlando di un processo estremamente intensivo dal punto di vista computazionale, al punto da essere considerato impensabile da eseguire in tempo reale facendo uso di una GPU sprovvista di accelerazione ray-tracing in hardware.
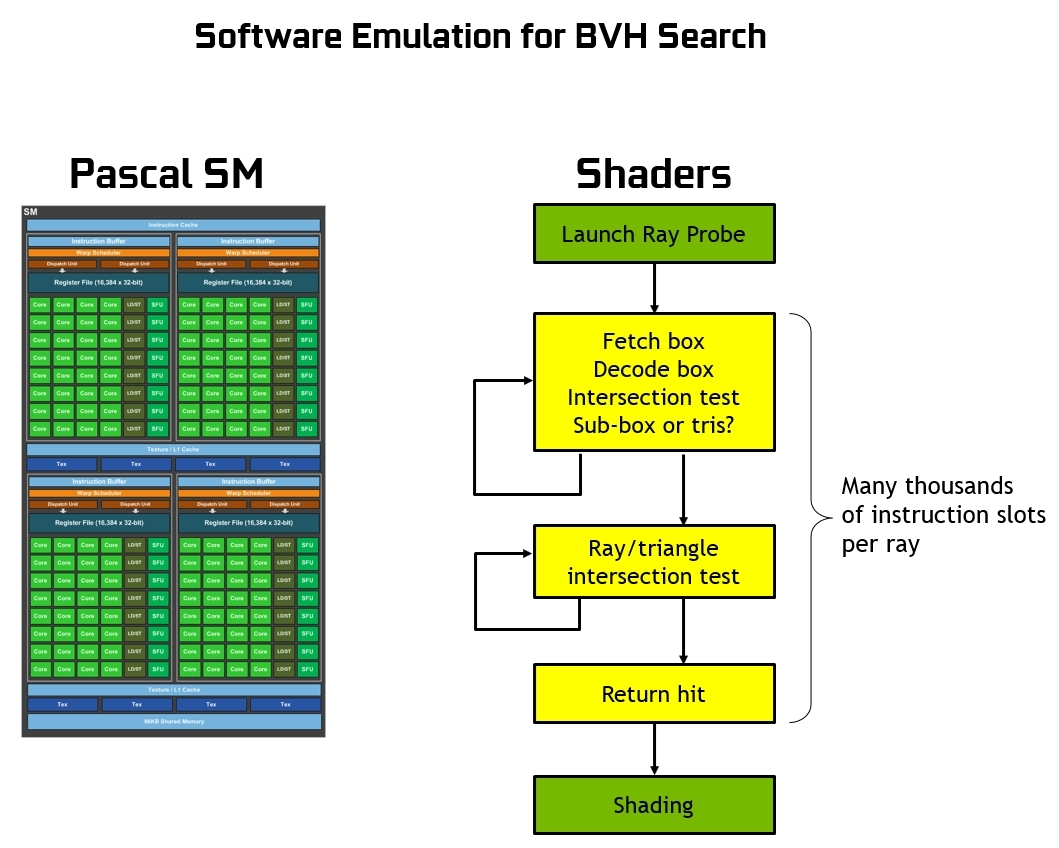
La presenza di questo genere di unità dedicate, al contrario, consente un’elaborazione efficiente di tutti i test di intersezione tra i raggi proiettati e i triangoli, sgravando la SM di migliaia di slot di istruzioni per ogni singolo raggio proiettato. Un vantaggio enorme se pensiamo alla mole di calcoli che sarebbero necessari per un’intera scena.
All’interno di ogni unità RT Cores di Turing vi sono una coppia di sotto-unità specializzate: la prima si occupa dell’elaborazione della scena e della sua suddivisione, dapprima in grandi rettangoli (denominati box) e successivamente in ulteriori rettangoli sempre più piccoli fino ad arrivare ai singoli triangoli; la seconda invece si occupa della gestione dei calcoli di intersezione tra i raggi proiettati e i triangoli, restituendo un risultato in termini di colorazione o meno dei pixel. Alle unità SM, di conseguenza, viene esclusivamente affidato l’onere di lanciare il “raggio sonda”, trovandosi di fatto in gran parte libere di svolgere eventualmente altre operazioni grafiche o computazionali.

Nelle nuove unità RT Cores di seconda generazione, NVIDIA ha apportato diverse ottimizzazioni; dapprima è intervenuta sull’unità “Triangle Intersection”, velocizzandola e dotandola di risorse dedicate al fine di limitare tutti quegli scenari in cui avrebbe potuto rappresentare un collo di bottiglia, in secondo luogo ha aggiunto una nuova sotto-unità, denominata Interpolate Triangle Position, espressamente pensata per l’implementazione del Motion Blur in ambito Ray-Tracing.

Il Motion Blur è un effetto di computer grafica molto popolare e importante utilizzato in film, giochi e molti diversi tipi di applicazioni di rendering professionali per simulare meglio la realtà o semplicemente per creare interessanti effetti artistici. Per comprenderlo al meglio basta pensare a come una telecamera genera l’effetto. Un’immagine fotografica non viene creata istantaneamente, ma al contrario viene creata esponendo la pellicola alla luce per un periodo di tempo finito. Gli oggetti che si muovono abbastanza velocemente rispetto all’apertura dell’otturatore della fotocamera appariranno come strisce o macchie nella foto.
Affinché una GPU crei sfocature di movimento dall’aspetto realistico quando gli oggetti nella scena (geometrie) si muovono rapidamente davanti a una telecamera statica o la telecamera sta scansionando oggetti statici o in movimento, deve simulare il modo in cui una telecamera e un film riprodurrebbero tali scene. Gli effetti di sfocatura ad alta qualità possono essere molto dispendiosi in termini di calcolo, spesso richiedendo il rendering e la fusione di più fotogrammi in un determinato intervallo di tempo.
Potrebbe essere necessaria anche la post-elaborazione per migliorare ulteriormente i risultati. Un certo numero di trucchi e metodi di scelta rapida vengono spesso utilizzati per il Motion Blur in tempo reale, come nei giochi, ma la sfocatura può mancare di realismo. Ad esempio, le immagini potrebbero essere innaturalmente macchiate, rumorose o presentare artefatti di ghosting/strobo, oppure l’effetto potrebbe mancare del tutto nei riflessi e nei materiali traslucidi.
Al contrario, il Motion Blur con Ray-Tracing può essere più accurato, realistico e senza artefatti indesiderati, ma può anche richiedere molto tempo e notevoli risorse per portarne a termine il rendering su una GPU, soprattutto senza l’accelerazione hardware delle operazioni di Ray-Tracing, parte integrante dell’esecuzione di effetti di sfocatura.
Diversi algoritmi o combinazioni di algoritmi possono essere impiegati per eseguire il Motion Blur con Ray-Tracing. Un metodo diffuso spara casualmente nella scena una serie di raggi con time-stamp. Un BVH in grado di sfocare in movimento restituisce le informazioni sui colpi del raggio rispetto alla geometria che si muove nel tempo, campionate al time-stamp associato a ciascun raggio. Questi campioni vengono quindi ombreggiati e combinati per creare l’effetto sfocato finale. È possibile riprendere più raggi in una scena e gli RT Cores accelerano i calcoli eseguendo test di intersezione raggio/triangolo e restituendo risultati per creare effetti di sfocatura. Tuttavia, eseguire il Motion Blur sulla geometria in movimento può essere più impegnativo entro un dato intervallo di tempo poiché le informazioni BVH cambiano mentre gli oggetti si muovono.
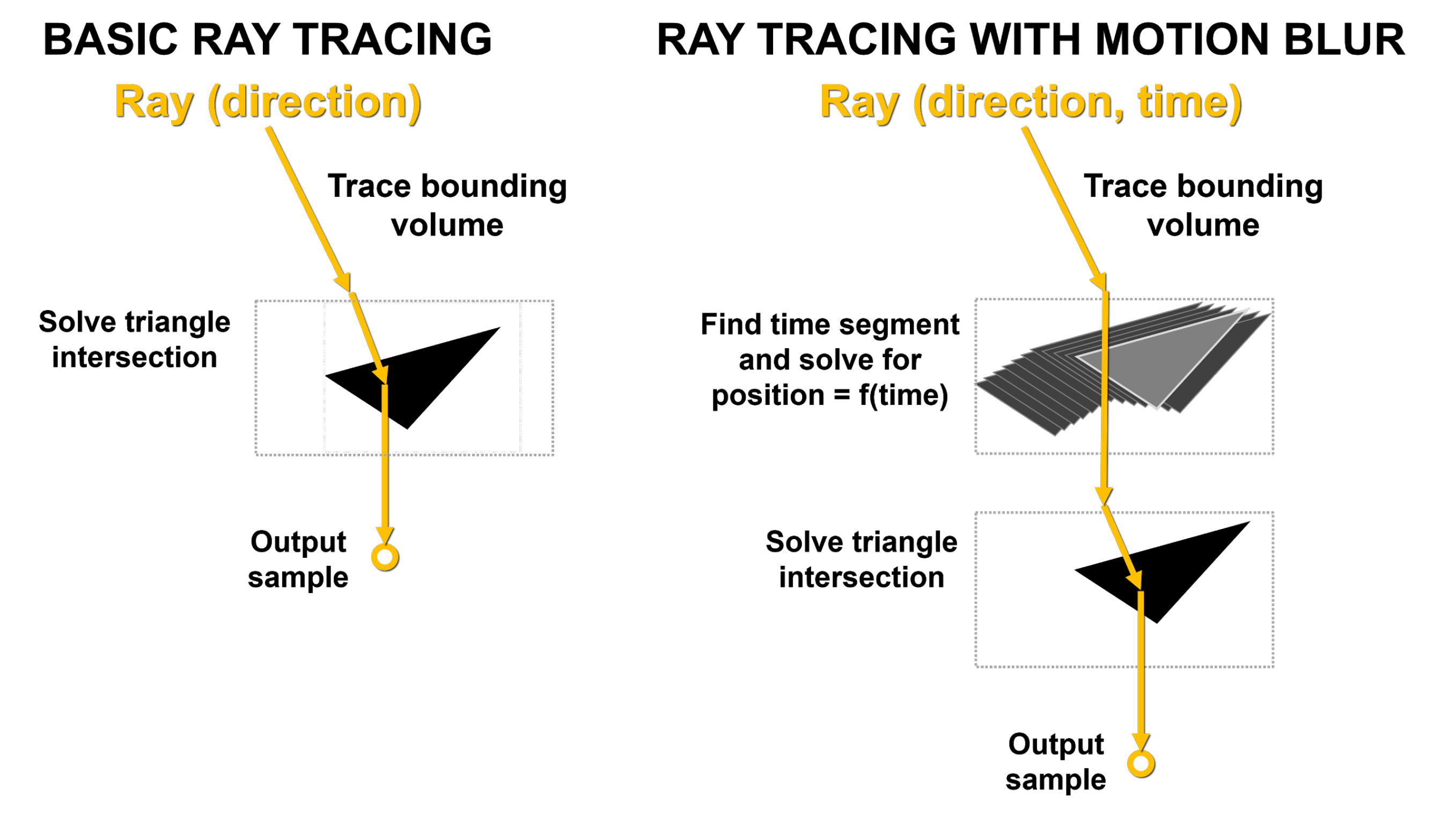
Ed è proprio questo che rappresenta la sfida più grande a cui hanno dovuto far fronte gli ingegneri NVIDIA; con il Motion Blur i triangoli nella scena non sono più fissati nel tempo. Nel Ray-Tracing di base, ogni triangolo è definito all’interno della struttura di accelerazione BVH. Quando viene tracciato un raggio, vengono eseguiti i test raggio/riquadro di delimitazione e intersezione raggio/triangolo e, se viene colpito un triangolo, le informazioni sul risultato vengono campionate e restituite.
Con il Motion Blur nessun triangolo ha una posizione fissa. Fortunatamente il BVH prevede una formula che possiamo riassumere così: “se mi dici che ore sono, posso dirti dove si trova questo triangolo nello spazio”. Ad ogni raggio viene quindi assegnato un time-stamp che indica il tempo da tracciare, alimentando le equazioni BVH per risolvere la posizione del triangolo e l’intersezione raggio/triangolo. Per ovvi motivi, se questo processo non fosse accelerato dall’hardware della GPU, rappresenterebbe un enorme collo di bottiglia data l’ingente mole da calcoli necessari.
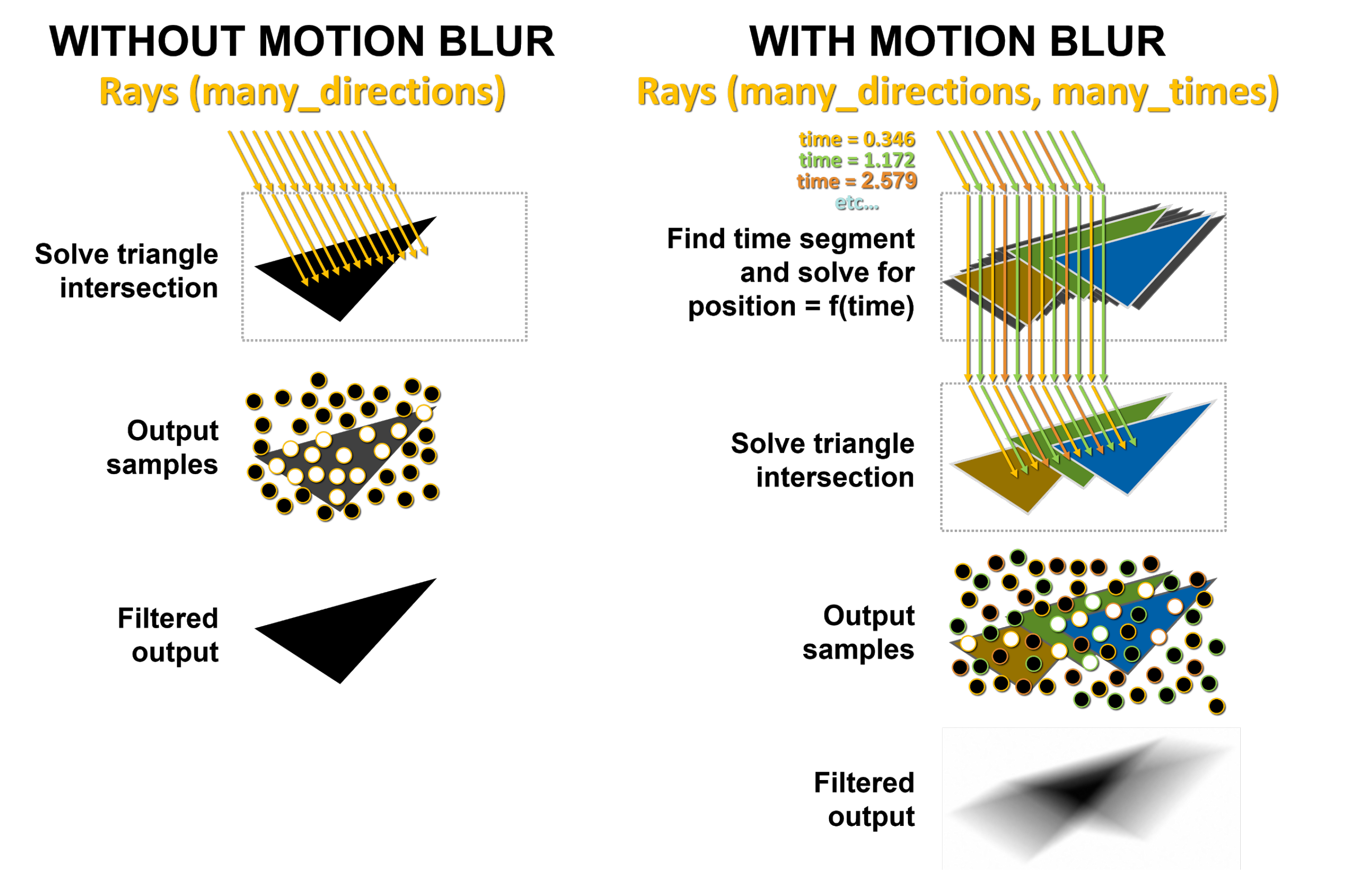
Sul lato sinistro dell’immagine sopra riportata, la ripresa dei raggi nella scena senza movimento potrebbe avere, come mostrato, molti raggi, ma colpiscono tutti lo stesso triangolo nello stesso punto nel tempo. I punti bianchi mostrano dove hanno effettivamente colpito il triangolo e l’output viene prodotto e restituito. Con il Motion Blur, ogni raggio esiste in un momento diverso nel tempo.
Di seguito sono mostrati tre colori dei raggi a scopo illustrativo per differenziarli, ma a ogni raggio viene assegnato in modo casuale un time-stamp diverso. Ad esempio, i raggi arancioni cercano di intersecare triangoli arancioni in punti diversi nel tempo, quindi i raggi verdi e blu cercano di intersecare rispettivamente triangoli verdi e blu. Il risultato è un output filtrato più macchiato e matematicamente corretto come mostrato in basso, derivato da un mix di campioni generati dai raggi che colpiscono i triangoli in diverse posizioni in diversi punti nel tempo.
La nuova unità Interpolate Triangle Position è in grado di generare triangoli nel BVH tra le rappresentazioni triangolari esistenti in base al movimento degli oggetti, in modo che i raggi possano intersecare i triangoli nelle loro posizioni previste nello spazio dell’oggetto ai tempi specificati dai time-stamp dei raggi. Questa nuova unità consente un rendering accurato della sfocatura del movimento con Ray-Tracing fino a otto volte più veloce rispetto all’architettura GPU di Turing.
Il Motion Blur con accelerazione hardware implementato nell’architettura Ampere è pienamente supportato in numerosi software professionali, quali ad esempio Blender 2.90, Chaos V-Ray 5.0, Autodesk Arnold e Redshift Renderer 3.0.X utilizzando l’API NVIDIA OptiX 7.0. L’incremento prestazionale è notevole, una nuova GeForce RTX 3080 è infatti capace di risultare fino a ben cinque volte più veloce di una precedente GeForce 2080 SUPER basata su architettura Turing.

Oltre alle unità di accelerazione dedicate anche varie tecniche di filtraggio avanzate possono aiutare ad incrementare le prestazioni e la qualità dell’immagine senza richiedere l’aggiunta di ulteriori raggi. Il “Denoising” ad esempio consente di migliorare la qualità visiva di immagini disturbate, ovvero costruite con dati sparsi, presentare artefatti casuali, rumore di quantizzazione o altre tipologie di rumore.
Così come esistono diversi tipi e cause di rumore dell’immagine, allo stesso modo esistono anche svariati metodi per risolvere questo genere di problematica. Il Denoising Filtering, ad esempio, consente di ridurre il tempo impiegato al rendering di immagini ray-traced ad alta fedeltà visivamente prive di rumore, sfruttando specifici algoritmi messi a punto da NVIDIA, basati o meno sull’intelligenza artificiale a seconda del caso di applicazione specifico.
Anche la qualità delle ombre è fondamentale per rendere maggiormente realistica l’atmosfera di una scena. Nella maggior parte dei giochi vengono utilizzate tecniche di Shadow Mapping in quanto veloci, semplici da implementare e non richiedono buffer speciali. L’approccio previsto è del tutto semplice e parte dal presupposto che qualunque oggetto visibile da una fonte di luce dovrà per forza apparire illuminato, al contrario qualunque oggetto non visibile sarà in ombra. Il risultato finale, seppur certamente gradevole a vedersi, non potrà certamente vantare il massimo dell’accuratezza.

Il ray-tracing, combinato con il denoising, consente alle GPU Turing e Ampere di superare i limiti delle Shadow Map, come la mancata corrispondenza della risoluzione, che rende difficile generare bordi accurati in presenza di ombre dure, e l’ìndurimento del contatto. Quest’ultimo può essere approssimato con tecniche quali Percentage Closer Soft Shadows (PCSS) e Distance Field Shadows, la prima (PCSS) particolarmente intensiva dal punto di vista computazionale e non ugualmente in grado di generare ombre completamente corrette in presenza di aree di illuminazione arbitrarie; la seconda (DFS) è fortemente limitata dalla geometria statica nelle attuali implementazioni.
Con l’accelerazione del ray-tracing basata su tecnologia NVIDIA RTX, in aggiunta ai sofisticati algoritmi di denoising veloce, le ombre ray-traced possono facilmente sostituire le obsolete Shadow Map e fornire una tecnica pratica per simulare l’indurimento del contatto fisicamente corretto in presenza di qualsiasi tipologia di illuminazione presente.

Come possiamo osservare in quest’ultima immagine, l’implementazione della Shadow Map seppur riesca ad uniformare i bordi delle ombre non è in grado di rappresentare un corretto indurimento dei contatti. Le ombre ray-traced vengono generate dalla stessa fonte di luce direzionale con angoli di cono variabili. Con questa tecnica si possono ricreare, se lo si desidera, ombre con bordi completamente duri (come mostrato nell’immagine in basso a destra con angolo di cono pari a 0°), oppure ombre morbide con indurimento corretto in relazione all’angolo di cono (figure mostrate sulla destra con angolo di cono pari a 1,5° e 10°).

L’aspetto che più mostra i vantaggi, in termini di qualità visiva, del ray-tracing, riguarda però i riflessi, specialmente se utilizzati in scene ricche di materiali speculari e lucidi. Le tecniche più comuni utilizzate oggi, come la Screen-space Reflections, seppur molto costose in quanto a risorse elaborative, spesso producono buchi e artefatti nell’immagine renderizzata.
Le sonde Cubemap, per lo più statiche e a bassa risoluzione, non rappresentano una soluzione accettabile in presenza di materiali lucidi all’interno di scene con illuminazione prevalentemente statica. Le riflessioni planari sono limitate dal numero che può essere generato facendo uso di tecniche basate sulla rasterizzazione.
I riflessi ray-traced, al contrario, combinati con il denoising, evitano tutti questi problemi e producono riflessi privi di artefatti e fisicamente corretti, assicurando un deciso impatto visivo. Nelle immagini che seguono andremo a mostrare l’implementazione della tecnologia NVIDIA RTX all’interno dell’ultimo capitolo dell’apprezzata serie Battlefield, sviluppato da DICE.


Come possiamo osservare l’attivazione della tecnologia RTX assicura un maggior quantitativo di effetti all’interno della scena di gioco. Ad esempio è possibile osservare la rappresentazione di riflessi realistici sulla macchina provocati da un’esplosione scoppiata al di fuori dello schermo. Questo genere di riflessi sarebbe stato impossibile da riprodurre facendo uso di tecniche Screen-space Reflection, restituendo la scena visibile nell’immagine “RTX Off”.


In questa seconda serie di immagini viene mostrato un altro problema alla base dei riflessi di tipo non ray-traced. Nello specifico, nonostante sia presente un parziale riflesso sul suolo, possiamo osservarne la mancanza all’interno del mirino (correttamente riprodotto nella scena “RTX On”).
Sono varie le tecnologie che unite assieme hanno reso possibile la gestione in tempo reale del ray-tracing da parte dei processori grafici Turing e Ampere. Tra queste, volendo fare una breve sintesi, troviamo:
- Rendering Ibrido: riduce la quantità di ray-tracing necessaria nella scena continuando a utilizzare la rasterizzazione per i passaggi di rendering in cui è considerata efficace, limitando il ray-tracing per i passaggi di rendering in cui la rasterizzazione è in difficoltà non riuscendo ad assicurare un impatto visivo realistico;
- Algoritmi di riduzione del rumore (Denoising) delle immagini;
- Algoritmo BVH: utilizzato per rendere le operazioni di ray-tracing molto più efficienti riducendo il numero di triangoli che devono essere effettivamente testati per trovare quelli effettivamente colpiti dai raggi di luce presenti nella scena;
- RT Cores: tutte le ottimizzazioni precedentemente elencate hanno contribuito a migliorare l’efficienza del ray-tracing, ma non abbastanza da renderlo vicino al tempo reale. Tuttavia, una volta che l’algoritmo di BVH è diventato standard, è emersa l’opportunità di realizzare un acceleratore accuratamente predisposto per rendere le operazioni necessarie estremamente più efficienti. Le unità RT Cores messe a punto da NVIDIA sono proprio quell’acceleratore, capace di rendere le GPU notevolmente più veloci nell’elaborazione ray-tracing. Gli RT Cores di seconda generazione, implementati nell’architettura Ampere raddoppiano il tasso di test di intersezione raggio/triangolo rispetto alle precedenti soluzioni Turing, assicurando un livello prestazionale sensibilmente superiore.
In ambito prettamente videoludico NVIDIA ha mostrato i vantaggi di tutte le migliorie tecnologiche implementate nelle ultime architetture prendendo come esempio l’apprezzato titolo Wolfenstein: Youngblood. Come ormai abbiamo ben compreso, il Ray-Tracing in tempo reale richiede un notevole sforzo computazionale, che sarebbe di gran lunga fuori portata se fosse demandato ai soli shader (CUDA Cores).
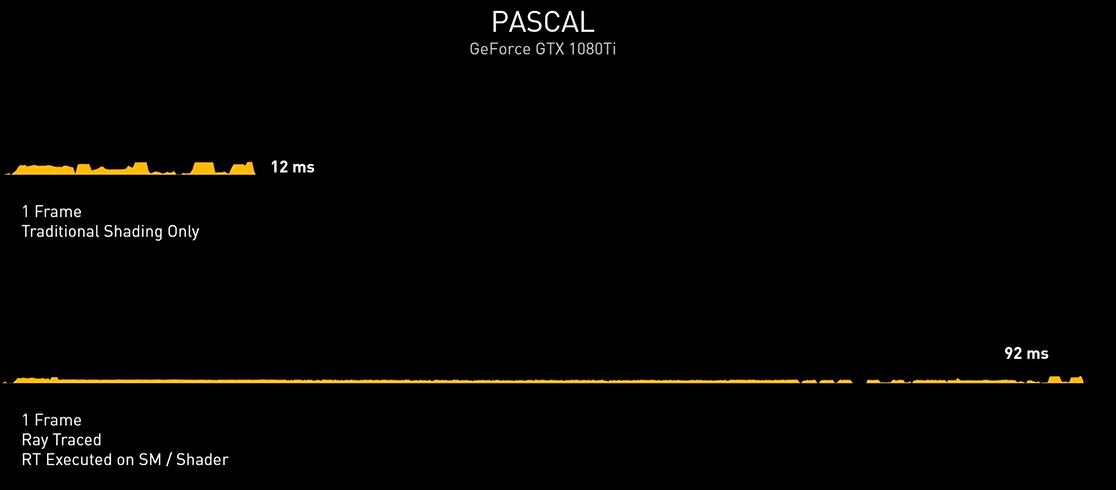
Una soluzione grafica priva di unità dedicate, quale ad esempio una vecchia Pascal (GeForce GTX 1000 Series) non sarebbe in grado di assicurare performance accettabili in presenza di calcoli Ray-Tracing a carico dei soli shader. Nell’esempio proposto da NVIDIA, infatti, una GeForce GTX 1080Ti riesce a calcolare un frame tradizionale in 12ms, che salgono a ben 92ms introducendo anche il Ray-Tracing, rendendo il titolo praticamente ingiocabile.
Con l’architettura Turing sono stati ulteriormente ottimizzati gli shader, rendendoli di gran lunga più performanti, arrivando quasi a dimezzare il tempo di rendering e scendendo dai famosi 92ms necessari alla soluzione Pascal, fino ad appena 51ms.
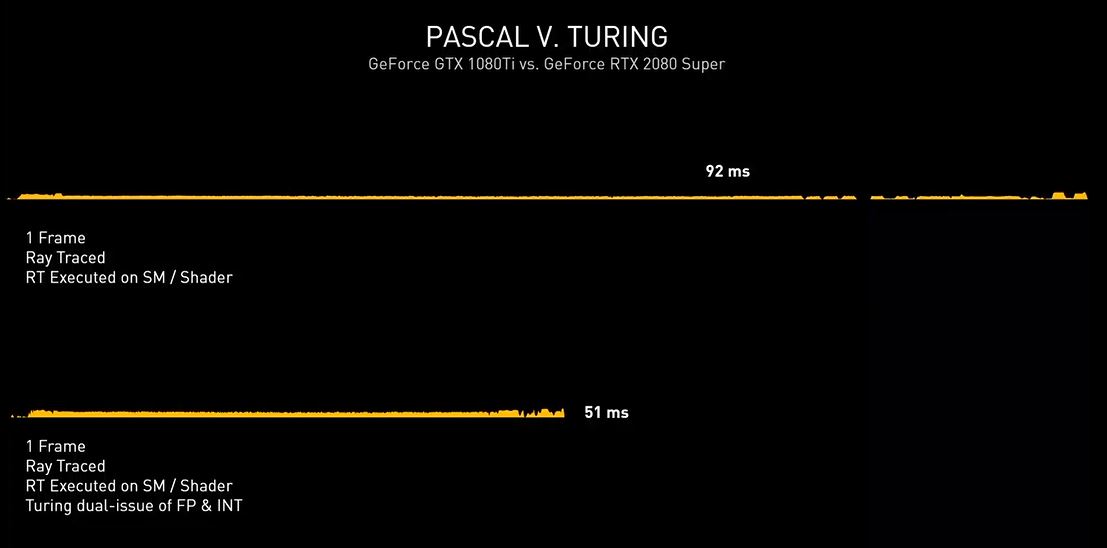
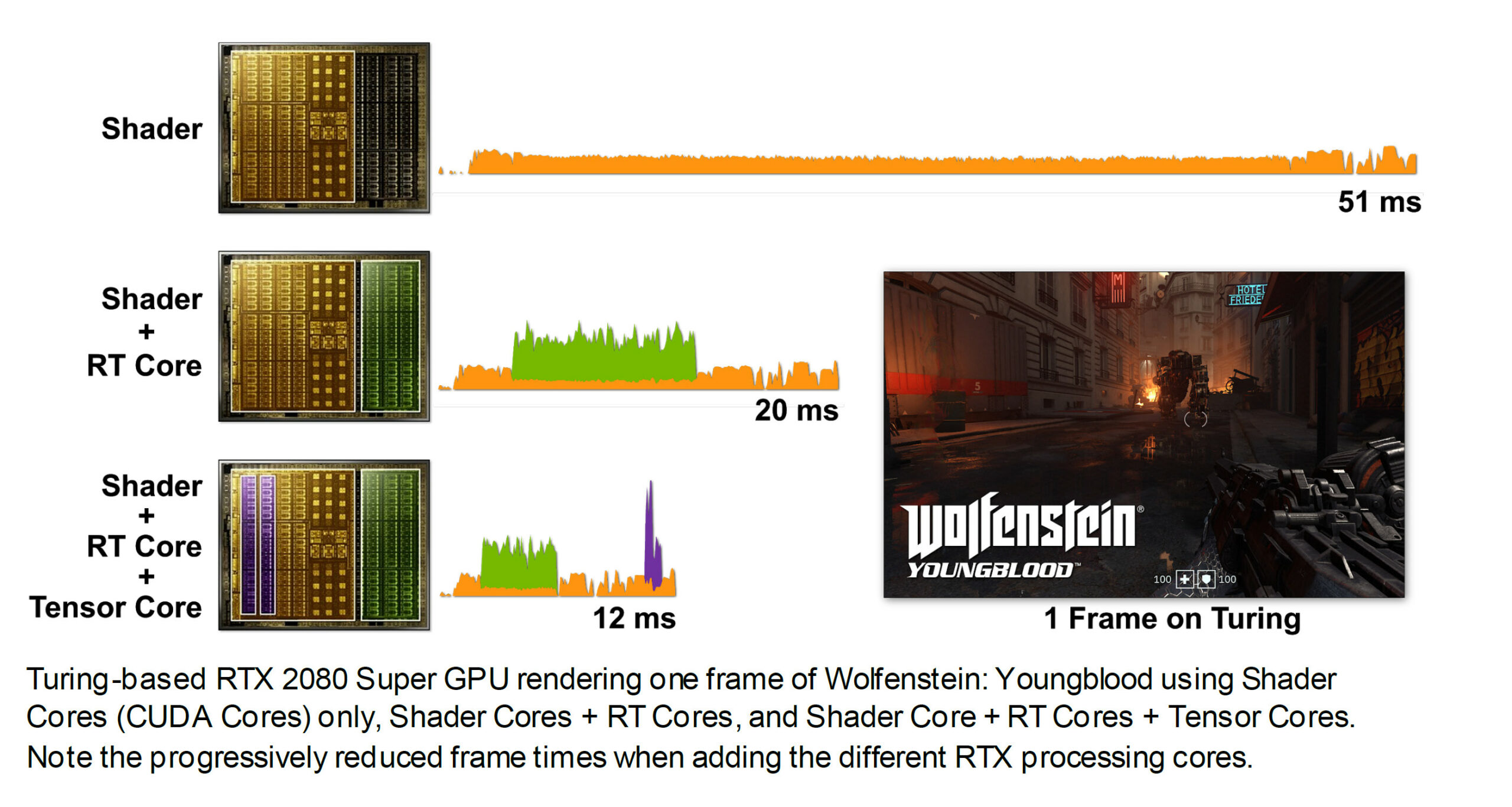
La possibilità da parte di Turing di dirottare parte del lavoro su unità dedicate RT Cores e dei Tensor Cores, però, ha consentito di accelerare ancor più l’elaborazione come possiamo osservare nell’immagine che segue, in cui viene mostrata in azione una GeForce RTX 2080 SUPER. Usando esclusivamente gli shader occorrono 51ms per eseguire questo ipotetico singolo fotogramma (~20FPS). Quando il lavoro di Ray-Tracing viene spostato sugli RT Cores il tempo di rendering si riduce notevolmente, scendendo fino a 20ms (50FPS).
L’utilizzo dei Tensor Cores, per abilitare il DLSS, consente di scendere ulteriormente fino a raggiungere soli 12ms (~83FPS). Tirando semplicemente le somme, nel tempo necessario a Pascal per calcolare un frame tradizionale (12ms), la soluzione Turing è in grado non soltanto di occuparsi dello shading, ma anche del Ray-Tracing tramite RT Cores e di tutti i molteplici calcoli a carico dei Tensor Cores.
La recente architettura Ampere migliora ulteriormente questa situazione, forte di interventi ed ottimizzazioni espressamente mirati ad incrementarne l’efficienza e le prestazioni, quali come abbiamo osservato il raddoppio delle unità in virgola mobile (FP32), il maggior quantitativo e la differente gestione della memoria Cache, oltre che ovviamente la presenza di ancor più veloci unità dedicate RT Cores di seconda generazione.

Il risultato ottenuto è del tutto soddisfacente, basti pensare che viene ancora una volta quasi dimezzato il tempo di rendering necessario, passando dai 19ms della soluzione Turing, ad appena 11ms di Ampere (nel confronto osserviamo una GeForce RTX 2080 SUPER vs GeForce RTX 3080).

Prendendo come riferimento un frame contenente shading, calcoli Ray-Tracing e DLSS, l’architettura Turing impiegherebbe 13ms per portarne a termine l’elaborazione, mentre ad Ampere ne bastano 7,5ms operando nella stessa maniera, che scendono ulteriormente fino ad appena 6,7ms sfruttando l’efficiente esecuzione parallela dei calcoli di cui è capace la nuova architettura messa a punto da NVIDIA.

![Cop – INNO3D GeForce RTX 4060 8GB TWIN X2 [N40602-08D6-173051N]](https://www.hwlegend.tech/wp-content/uploads/2023/12/Cop-INNO3D-GeForce-RTX-4060-8GB-TWIN-X2-N40602-08D6-173051N-150x150.webp "INNO3D GeForce RTX 4060 8GB TWIN X2 [N40602-08D6-173051N]")
![Cop – ASRock Radeon RX 7600 XT 16GB Steel Legend OC [RX7600XT-SL-16GO]](https://www.hwlegend.tech/wp-content/uploads/2024/02/Cop-ASRock-Radeon-RX-7600-XT-16GB-Steel-Legend-OC-RX7600XT-SL-16GO-150x150.webp "ASRock Radeon RX 7600 XT 16GB Steel Legend OC [RX7600XT-SL-16GO]")



