




I carichi di lavoro dedicati all’addestramento dei modelli di intelligenza artificiale stanno spingendo le GPU moderne ai loro limiti. Con ROCm 7.0 e i nuovi Training Docker v25.9, AMD porta l’addestramento LLM a un livello superiore, offrendo ottimizzazioni avanzate per PyTorch, JAX e i flussi di lavoro multi-nodo.
Il cuore di questa evoluzione è la combinazione tra software ROCm 7.0 e le GPU AMD Instinct MI355X, progettate per massimizzare throughput, efficienza e scalabilità nei modelli di nuova generazione.

Primus: framework unificato per l’addestramento LLM
Con il rilascio v25.9 del Docker PyTorch, AMD integra Primus, un framework modulare pensato per semplificare lo sviluppo di LLM su GPU Instinct. Il sistema ora supporta i backend TorchTitan e Megatron-LM, offrendo configurazioni riproducibili e più efficienti.

La novità più rilevante è Primus-Turbo, una libreria ottimizzata per accelerare i modelli Transformer sulle MI355X, aumentando ulteriormente il throughput nelle fasi più pesanti dell’addestramento.
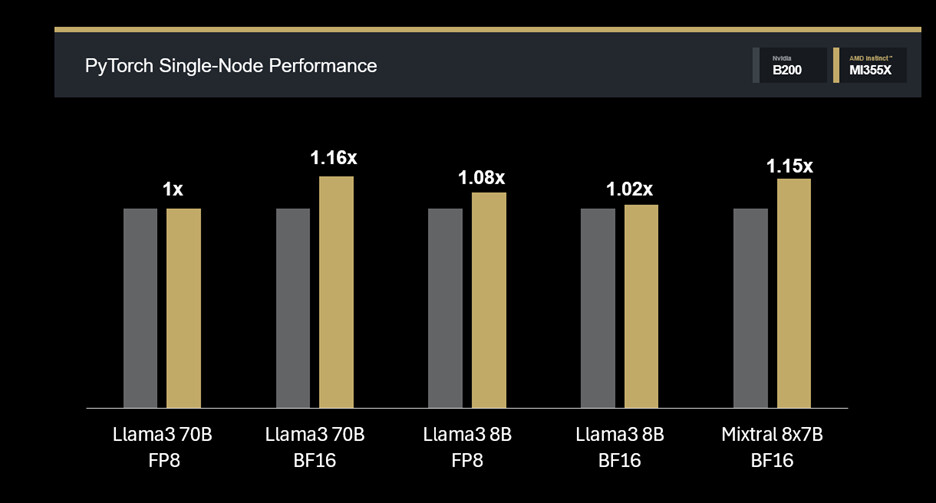
Prestazioni single-node con PyTorch e Primus
Nei test con ROCm 7.0 PyTorch Training Docker v25.9, le MI355X mostrano costantemente prestazioni superiori nei modelli densi e Mixture-of-Experts.
Risultati principali su PyTorch:
Llama3 70B FP8: 1.0× (parità);
Llama3 70B BF16: 1.16×;
Llama3 8B FP8: 1.08×;
Llama3 8B BF16: 1.02×;
Mixtral 8×7B FP16: 1.15×.
Questi valori confermano la capacità delle MI355X di gestire modelli di diversa scala mantenendo un’elevata efficienza in configurazioni single-node.
Prestazioni single-node in JAX MaxText
JAX continua a crescere nella comunità di ricerca grazie alla sua flessibilità e al supporto naturale alla scalabilità su più acceleratori. Il Docker ROCm MaxText include JAX, XLA e tutte le utility necessarie per sfruttare appieno l’hardware AMD.
Anche in questo contesto, le MI355X offrono miglioramenti significativi:
Llama3.1 70B FP8: 1.11×;
Llama3.1 8B FP8: 1.07×;
Mixtral 8×7B FP16: 1.0×.
La GPU mantiene un vantaggio netto nei modelli densi e prestazioni in linea con le alternative su workload MoE.
Scalabilità multi-nodo
Nei contesti di addestramento distribuito, la MI355X conferma un’ottima scalabilità, con risultati competitivi nelle configurazioni a 4 e 8 nodi.
Risultati principali multi-nodo:
Mixtral 8×22B BF16: 1.14× su 4 nodi;
Llama3 70B FP8: 1.01× su 4 nodi;
Llama3.1 405B FP8: 0.96× su 8 nodi.
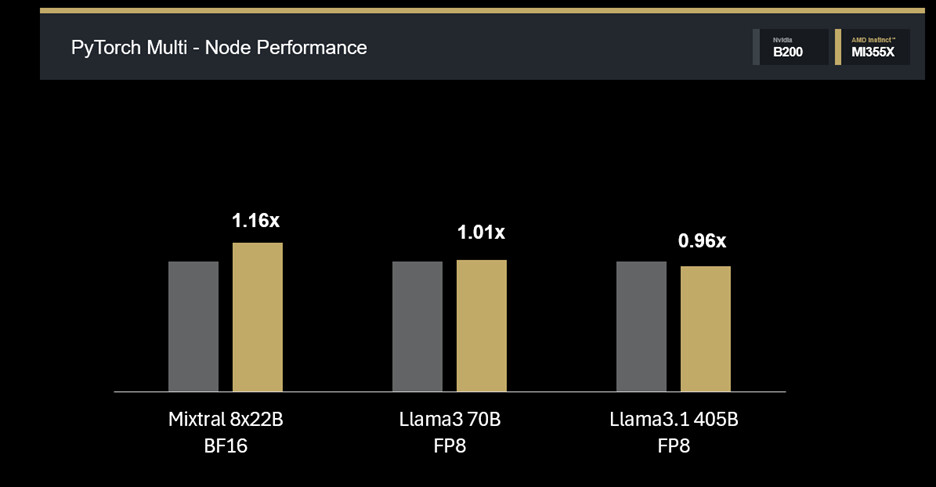
Questi numeri dimostrano una piattaforma matura, capace di supportare modelli estremamente complessi senza perdita di efficienza all’aumentare delle GPU.
Conclusioni
Con ROCm 7.0 e le GPU AMD Instinct MI355X, AMD stabilisce un nuovo standard nelle prestazioni per l’addestramento LLM. Il supporto esteso a PyTorch e JAX, l’integrazione del framework Primus e le ottimizzazioni specifiche per Transformer permettono a sviluppatori e ricercatori di spingersi verso modelli più grandi e complessi con facilità.
L’ecosistema ROCm offre:
Throughput elevato su modelli densi e MoE;
Scalabilità multi-nodo competitiva;
Ambienti di sviluppo completi e preconfigurati;
Framework potenziati per LLM di nuova generazione.
Chi desidera sperimentare direttamente questi miglioramenti può scaricare il Training Docker v25.9 e sfruttare il potenziale delle GPU MI355X nei propri progetti di ricerca avanzata.
HW Legend Staff






