



Dalla sua presentazione la scorsa settimana, abbiamo ricevuto un’analisi più approfondita da parte di AMD sui suoi due processori in arrivo. Ora sappiamo che il silicio “Strix Point” alimenta i processori mobili della serie Ryzen AI 300 e il chiplet “Granite Ridge” MCM, invece alimenta i processori desktop Ryzen 9000.
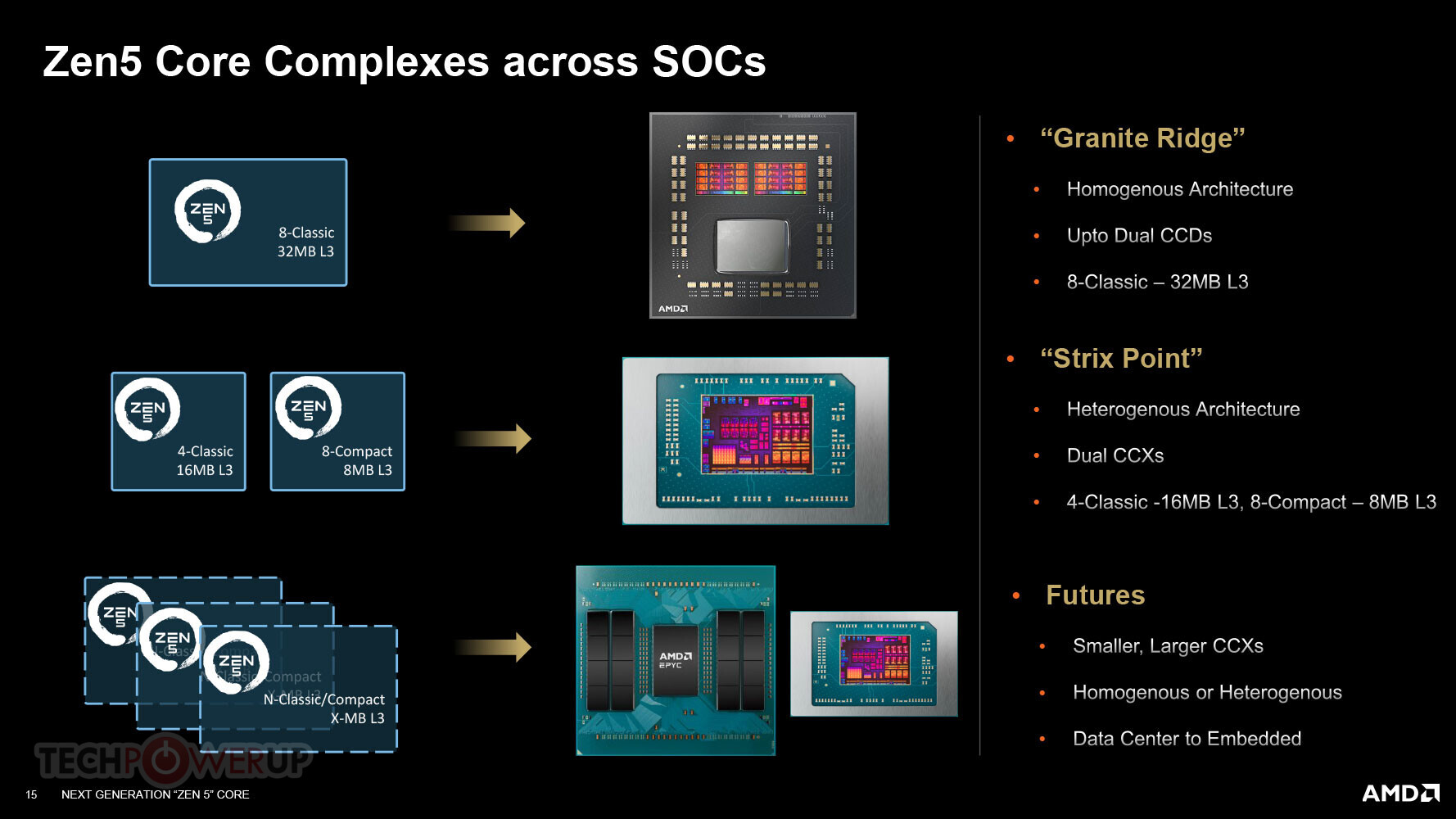
In questo articolo presentiamo uno sguardo più approfondito al SoC “Strix Point”. Si scopre che “Strix Point” adotta un approccio significativamente diverso al multicore eterogeneo rispetto a “Phoenix 2”. AMD ci ha illustrato in maniera approfondita su come funziona. L’azienda ha costruito il silicio monolitico “Strix Point” sul nodo di fonderia TSMC N4P, con un’area del die di circa 232 mm².

Il silicio “Strix Point” vede l’interconnessione Infinity Fabric dell’azienda. Questa è un’interconnessione punto a punto, a differenza del ringbus su alcuni processori Intel. Il principale macchinario di calcolo sul SoC “Strix Point” sono i suoi CPU (CCX), ciascuno con un percorso dati da 32b (lettura)/16b (scrittura) per ciclo verso il fabric. Il concetto di CCX torna con “Strix Point” dopo quasi due generazioni di “Zen”. Il primo CCX contiene i quattro core CPU “Zen 5” full-size del chip, che condividono una cache L3 da 16 MB tra loro. Il secondo CCX contiene gli otto core “Zen 5c” del chip che condividono una cache L3 più piccola da 8 MB. Ognuno dei 12 core ha una cache L2 dedicata da 1 MB.
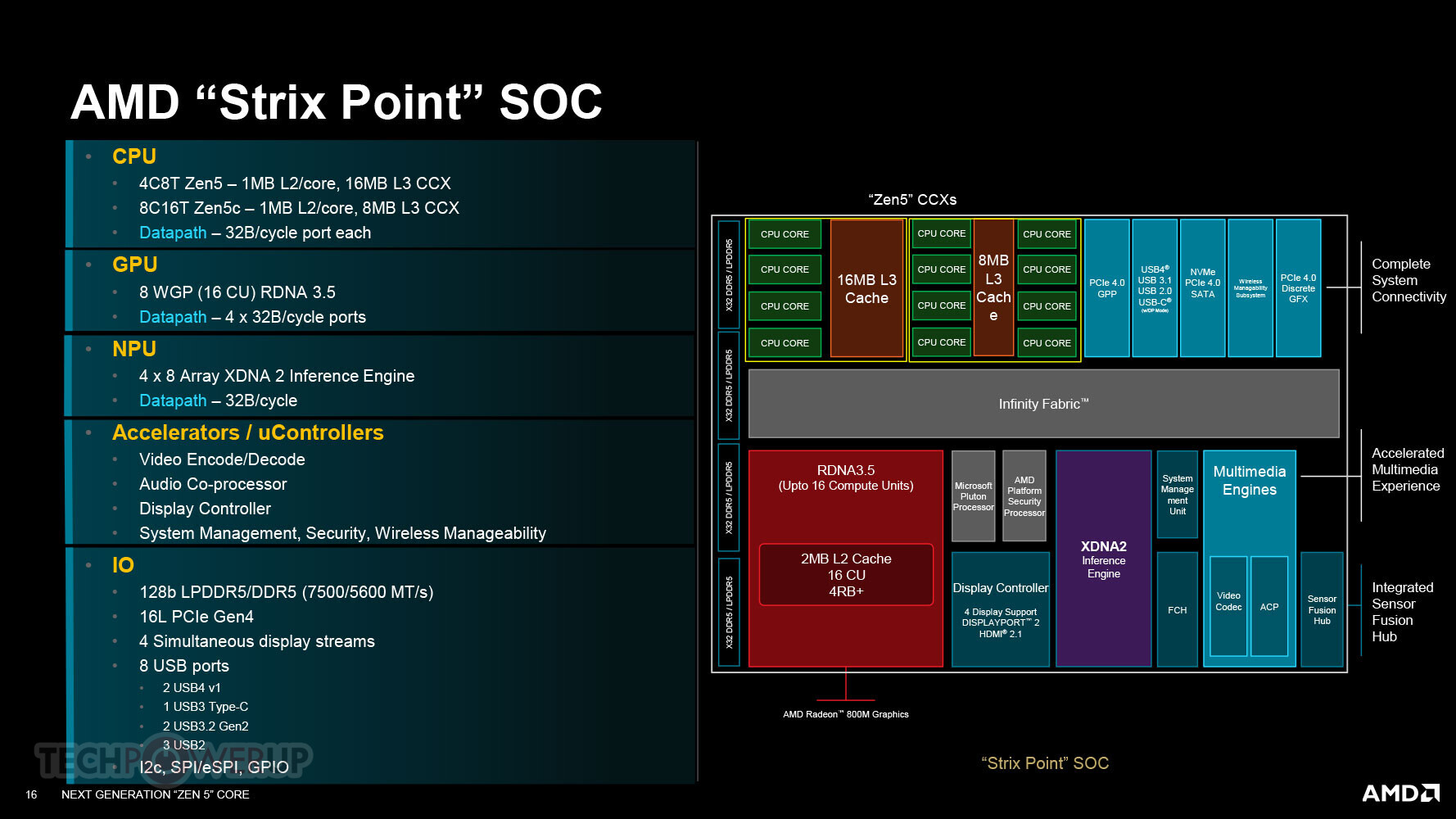
Questo approccio al multicore eterogeneo è significativamente diverso da “Phoenix 2”, dove i due core “Zen 4” e quattro core “Zen 4c” facevano parte di un CCX comune, con una cache L3 comune da 16 MB accessibile a tutti e sei i core. I core “Zen 5” su “Strix Point” saranno in grado di sostenere frequenze di boost elevate, superiori a 5,00 GHz, e dovrebbero trarre vantaggio dalla cache L3 da 16 MB più grande, condivisa tra soli quattro core (cache L3 per core simile a “Granite Ridge”).
I core “Zen 5c”, d’altro canto, operano a frequenze di base e boost inferiori rispetto ai core “Zen 5” e hanno quantità inferiori di cache L3 disponibili. Per migrare tra i due tipi di core, i thread dovranno passare attraverso il fabric e, in alcuni casi, persino subire un round-trip alla memoria principale. Il core Zen 5c è circa il 25% più piccolo nell’area del die rispetto al core Zen 5.
Per riferimento, il core Zen 4c è circa il 35% più piccolo di un normale core Zen 4. AMD ha lavorato per migliorare leggermente le frequenze di boost massime del core Zen 5c rispetto al suo predecessore.
Le tensioni massime inferiori e le frequenze di boost massime dei core Zen 5c li mettono in un significativo vantaggio di efficienza energetica rispetto ai core Zen 5. AMD continua a fare affidamento su una soluzione di pianificazione basata sul software al fine di garantisce che il giusto tipo di carico di lavoro di elaborazione vada al giusto tipo di core.

L’azienda afferma che la soluzione basata su software le consente di correggere “errori di pianificazione” nel tempo. L’iGPU è il dispositivo più affamato di larghezza di banda sul fabric e ottiene il suo percorso dati più ampio: 4x 32B/ciclo.
Basata sull’architettura grafica RDNA 3.5, che mantiene il motore SIMD e l’IPC di RDNA 3, ma con diversi miglioramenti alle prestazioni/Watt, questa iGPU presenta anche 8 processori di gruppo di lavoro (WGP), rispetto ai 6 dell’attuale “Phoenix”.
Ciò equivale a 16 CU, ovvero 1.024 stream processor. L’iGPU presenta anche 4 render backend+, che equivalgono a 16 ROP. Il terzo dispositivo più affamato di larghezza di banda è l’NPU XDNA 2, con un data-path da 32 B/ciclo che ha una larghezza di banda paragonabile a un CCX. L’NPU presenta quattro blocchi di 8 array XDNA 2 e 32 tile del motore AI e può essere overclockato.
Supporta anche il formato dati Block FP16 (da non confondere con bfloat16), che offre la precisione di FP16, con le prestazioni di FP8.
Oltre ai tre componenti ad alta logica, ci sono altri acceleratori che richiedono abbastanza larghezza di banda, come il motore Video CoreNext che accelera la codifica e la decodifica; il coprocessore audio che elabora lo stack audio quando il sistema è “spento”, in modo che possa rispondere ai comandi vocali; il controller del display che gestisce l’I/O del display, inclusa la compressione del flusso del display.
Le interfacce I/O del SoC “Strix Point” includono un controller di memoria che supporta LPDDR5 a 128 bit, LPDDR5x e DDR5 a doppio canale (160 bit). Il PCI-Express è leggermente depotenziato rispetto a quello fornito da “Phoenix”.
Ci sono un totale di 16 corsie PCIe Gen 4. Tutte e 16 dovrebbero essere utilizzabili nei notebook privi di un chipset FCH discreto, ma il numero di corsie utilizzabili dovrebbe scendere a 12 quando AMD adatterà questo silicio al Socket AM5 per le APU desktop.
Sui notebook da gioco che utilizzano processori Ryzen AI HX o serie H 300, le GPU discrete dovrebbero avere una connessione Gen 4 x8. La connettività USB include una USB4 da 40 Gbps, oppure due USB 3.2 Gen 2×2 da 20 Gbps, due USB 3.2 Gen 2 aggiuntive da 10 Gbps e tre classiche USB 2.0.
HW Legend Staff

![Cop - Kingston FURY Renegade G5 NVMe M.2 SSD 2TB [SFYR2S2T0]](https://www.hwlegend.tech/wp-content/uploads/2025/10/Cop-Kingston-FURY-Renegade-G5-NVMe-M.2-SSD-2TB-SFYR2S2T0-150x150.webp "Kingston FURY Renegade G5 NVMe M.2 SSD 2TB [SFYR2S/2T0]")




