




Sono trascorsi ormai diversi mesi dal debutto ufficiale della famiglia Core di 13esima generazione, meglio nota con il nome in codice Raptor Lake e con la quale il colosso di Santa Clara ha di fatto tolto i veli sulla seconda generazione della sua architettura di tipo ibrido ad elevate prestazioni, la cui prima apparizione risale alla fine del 2021, in concomitanza con la presentazione delle soluzioni Alder Lake. Indubbiamente una gradita ventata d’aria fresca in ambito desktop di classe mainstream, con tutta una serie di nuove proposte in grado di alzare ulteriormente l’asticella delle pure prestazioni velocistiche, grazie soprattutto ad un maggior quantitativo di core integrati e a frequenze di clock sensibilmente più elevate. Come di consueto l’azienda americana ha proposto, in un primo momento, esclusivamente le soluzioni più complete, contraddistinte da funzionalità specifiche in grado di renderle maggiormente appetibili agli occhi degli appassionati più esigenti ed agli amanti dell’overclocking, per poi ampliare gradualmente la sua offerta con i modelli di fascia inferiore. Nel corso di questa nostra recensione andremo proprio ad osservare una delle ultime soluzioni del marchio dedicate alla fascia media del mercato, svelata ufficialmente lo scorso mese di gennaio, in occasione del CES 2023 tenutosi a Las Vegas. Stiamo parlando del microprocessore Core i5-13400F, una soluzione priva di componente grafica integrata indubbiamente molto interessante e con specifiche tecniche di tutto rispetto; 6 P-Core e 4 E-Core integrati per un totale di ben 16 Thread, un quantitativo capace quindi di assicurare una buona esperienza d’uso in ambito gaming e non solo. Non ci resta che augurarvi una piacevole lettura!
Nel lontano 1968 Robert Noyce e Gordon Moore lasciarono la Fairchild Semiconductor e fondano Intel Corporation. Il terzo dipendente fu Andrew “Andy” Grove, che diresse l’azienda dal suo arrivo negli anni sessanta fino al suo pensionamento, avvenuto negli anni novanta, facendola diventare una tra le più grandi multinazionali del mondo.
![]()
![]()
Inizialmente la produzione si limitava a componenti per memorie e, durante gli anni settanta, l’azienda divenne leader nella produzione di memorie DRAM, SRAM e ROM. Da quando però nel 1971, Marcian Hoff, Federico Faggin, Stanley Mazor e Masatoshi Shima svilupparono il primo microprocessore, l’Intel 4004, gradualmente fino agli anni ottanta la produzione si spostò verso quella dei microprocessori facendo diventare Intel una dei colossi in questo settore.
Nel 1983 toccò al presidente della società, Andy Grove, prendere una delicata decisione, abbandonare la produzione di memorie per focalizzarsi esclusivamente sui microprocessori. Un elemento chiave di questo processo fu sicuramente l’8086 che nel 1982 fu scelto per i PC IBM alla condizione (imposta da IBM) di avere una seconda fonte di produzione. La seconda fonte sarà AMD, che con uno scambio di licenze diviene il secondo fornitore di processori 8088 e 8086 per i PC IBM. Il “problema” dei secondi fornitori sarà sempre presente fino all’avvento del Pentium.
Durante gli anni novanta la Intel Architecture Labs (IAL) fu la maggior responsabile delle innovazioni hardware dei personal computer, fra cui il bus PCI, il bus PCI Express, l’Universal Serial Bus (USB) e le prime architetture per server multiprocessori (SMP).
Il controllo totale del mercato dei processori x86 procurò a Intel negli anni molte cause da parte dell’Antitrust. Attualmente l’azienda controlla l’85% del mercato dei processori 32-bit, unico suo avversario è la Advanced Micro Devices (AMD) con cui Intel ha un accordo dal 1976: ognuna delle due major può usare le tecnologie brevettate dall’avversario senza dover richiederne il consenso.
Intel produce al momento microprocessori, componenti di rete, chipset per schede madri, schede grafiche discrete e molti altri circuiti integrati. Nel settembre del 2007 la società ha acquisito Havok, noto sviluppatore in ambito software per lo sviluppo dell’omonimo motore fisico utilizzato in più di 150 videogiochi.
A oggi Intel Corporation ha il vanto di essere la più grande azienda multinazionale produttrice di semiconduttori, leader indiscusso nel suo segmento di mercato. Maggiori informazioni le trovate sul sito web Intel.
[nextpage title=”Uno sguardo alla nuova architettura ibrida ad elevate prestazioni”]
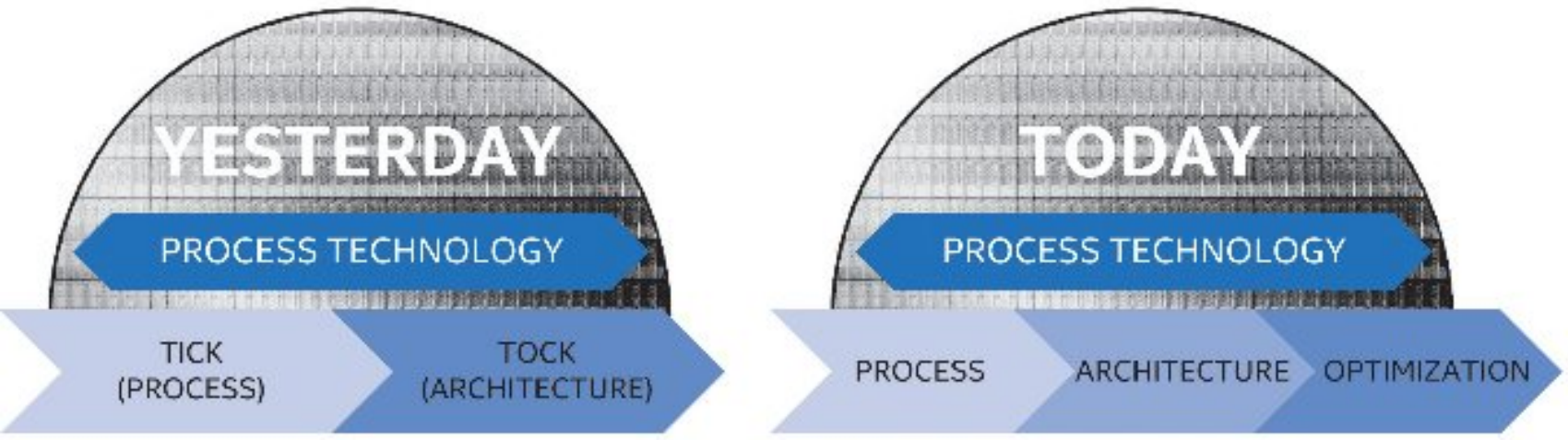
Dopo diverse generazioni nelle quali il colosso di Santa Clara ci ha abituati al tradizionale approccio di sviluppo di tipo Tick-Tock, in cui veniva prevista l’alternanza tra la migrazione di un’architettura già matura su un nuovo processo produttivo (Tick) e la successiva introduzione di una nuova architettura avvalendosi di una tecnologia produttiva ormai affinata (Tock), da qualche tempo a questa parte, e probabilmente a causa delle sempre maggiori difficoltà derivate dall’introduzione di transistor dalle dimensioni sempre più contenute, abbiamo assistito ad un sostanziale cambio di strategia, in cui viene di fatto “rallentato” lo sviluppo introducendo ufficialmente una terza fase, espressamente dedicata al perfezionamento dell’architettura già esistente, al fine di sfruttarne al massimo le potenzialità ed al tempo stesso ottimizzare i sempre maggiori costi di progetto necessari. Questo nuovo approccio di sviluppo viene indicato dall’azienda americana con il termine PAO, acronimo di Process-Architecture-Optimization.
Se con la passata generazione di microprocessori abbiamo infatti assistito ad un cambiamento del tutto radicale, nel quale, per la prima volta in ambito desktop, l’azienda propose un’architettura di tipo ibrido ad elevate prestazioni, con le ultime soluzioni di tredicesima generazione, meglio note con il nome in codice Raptor Lake, osserviamo interventi decisamente più marginali a livello architetturale, uniti a sensibili aumenti delle frequenze di clock resi possibili dal fisiologico affinamento del processo produttivo proprietario a 10 nanometri, denominato Intel 7.

Prima però di addentrarci in un’analisi approfondita di quelle che sono le più significative novità e migliorie introdotte con le ultime soluzioni, riteniamo doveroso soffermarci per un momento proprio sulla particolare architettura ibrida messa a punto dell’azienda, e considerata dalla stessa come una svolta epocale nel mondo dei microprocessori desktop x86.
Innanzitutto, per quale motivo viene indicata proprio con questo termine, ibrida? La risposta è del tutto banale e prevedibile, ed è essenzialmente dovuta alla coesistenza, all’interno di un singolo die, di core basati su architetture differenti tra loro, ma in grado di “unire le forze” al fine di assicurare un livello superiore, in termini di scalabilità ed efficienza, rispetto agli approcci più tradizionali.
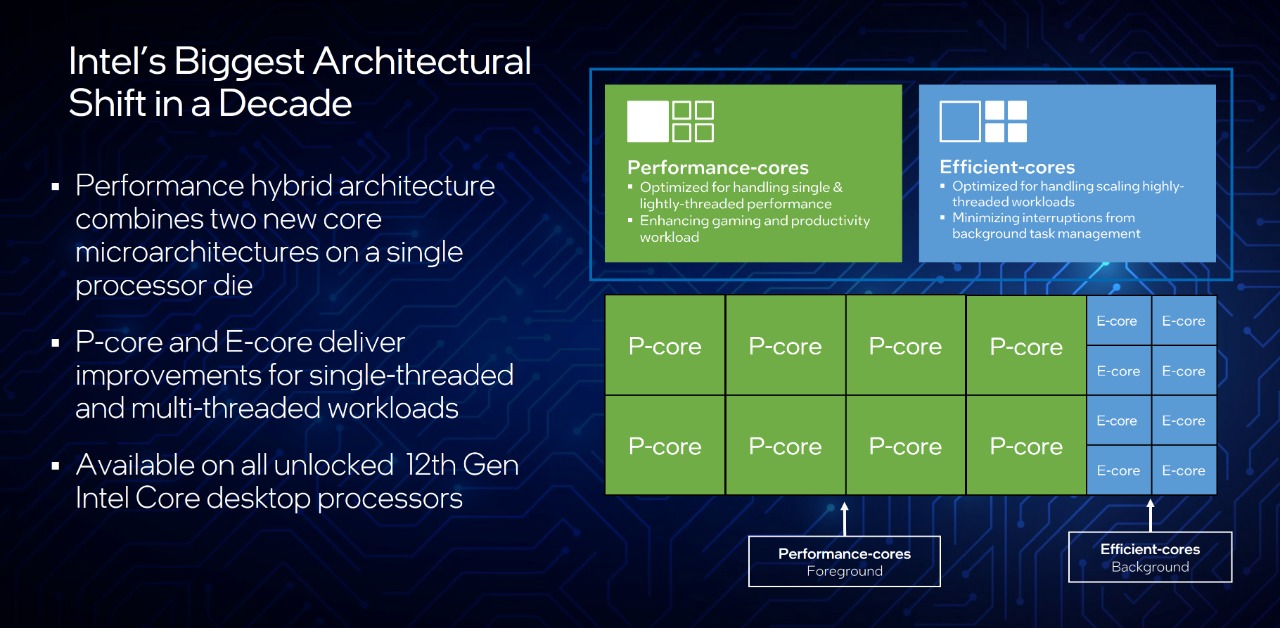
Nello specifico troviamo una serie di core altamente performanti, denominati per l’appunto Performance-Core (o P-Core), espressamente pensati per dare il meglio in ambiti single-thread, per i quali alte frequenze e IPC (Istruzioni per Ciclo) ricoprono un ruolo di fondamentale importanza, basti pensare al gaming o alla produttività; ed altri core più semplici, denominati Efficient-Core (o E-Core), messi a punto allo scopo non solo di massimizzare l’efficienza in tutti quegli scenari che prevedono carichi altamente parallelizzabili, lavorando in concerto con i P-Core, come ad esempio facendo uso di software di rendering, ma anche di farsi carico delle varie operazioni in background meno esigenti, come la sincronizzazione della posta o la gestione del software antivirus, sgravando così i P-Core da una notevole mole di calcoli al fine di poter contare sulle loro piene potenzialità laddove siano veramente capaci di fare la differenza.
In sostanza ci troviamo dinanzi ad una filosofia del tutto analoga a quella che da diversi anni osserviamo nelle soluzioni Arm destinate al mobile, ma che su sistemi desktop tradizionali ha suscitato, almeno in un primo momento, non poche perplessità fra gli addetti ai lavori, soprattutto per quanto riguarda la capacità di gestire i thread in un modo tanto intelligente, dal momento che la maggior parte dei sistemi operativi desktop erano ancorati al presupposto che tutti i core integrati in un microprocessore fossero identici in quanto a caratteristiche e prestazioni.
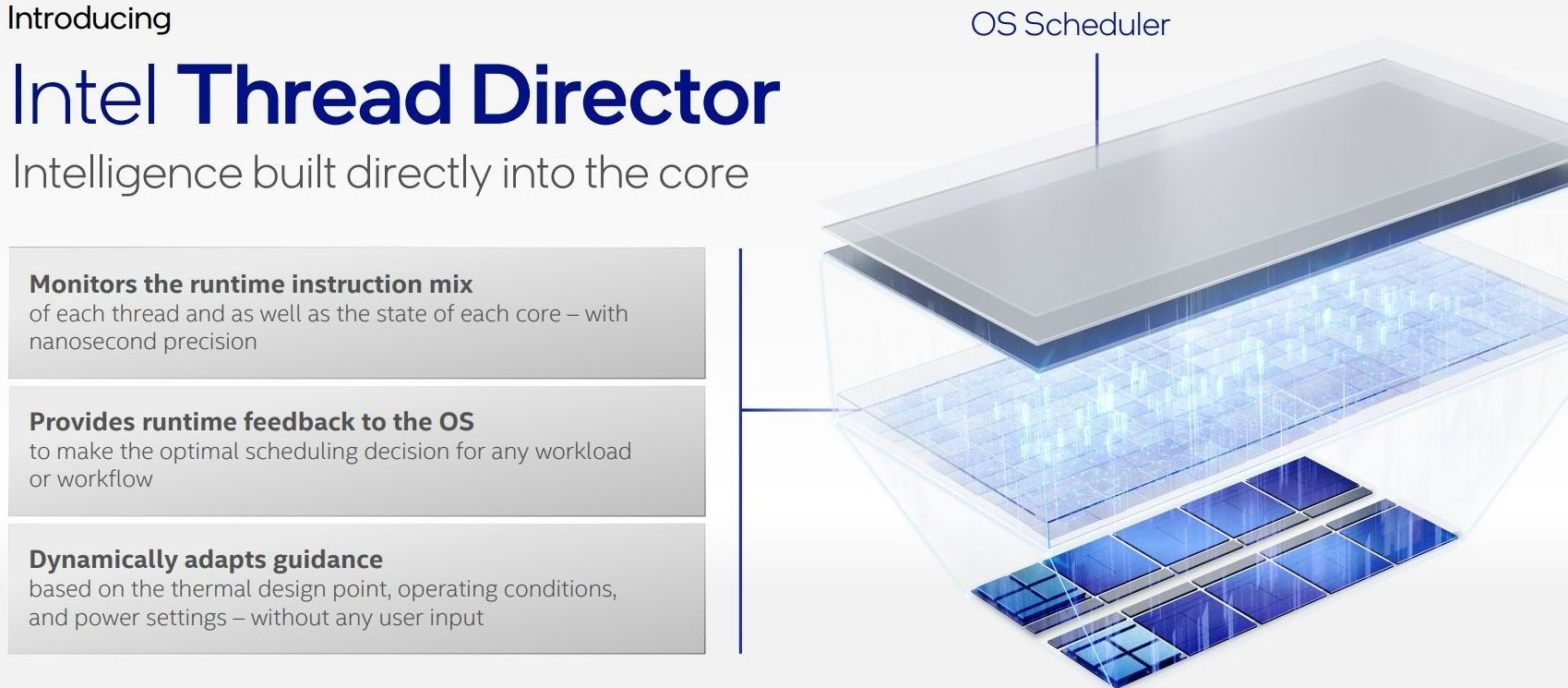
Per far fronte a questo problema, di conseguenza, non solo l’azienda ha lavorato a stretto contatto con Microsoft durante lo sviluppo del sistema operativo Windows 11 e del relativo scheduler, ma ha opportunamente messo a punto un particolare sistema telemetrico direttamente integrato nel microprocessore, denominato Intel Thread Director (ITD), avente lo scopo di monitorare costantemente le istruzioni attive su ogni thread e lo stato di ogni core, in modo tale da fornire al sistema operativo tutta una serie di informazioni utili per l’assegnazione, oppure in caso di necessità la riassegnazione, delle priorità in tempi brevissimi, per intenderci nell’ordine di pochi microsecondi. A titolo di confronto la stessa Intel ha più volte sottolineato che il suo Thread Director è infatti in grado di profilare un thread in appena 30 microsecondi, un nulla rispetto alle centinaia di millisecondi che impiegherebbe un tradizionale scheduler del sistema operativo per giungere alla medesima conclusione.

Alla base di questa tecnologia troviamo un sofisticato algoritmo pre-addestrato allo scopo di riconoscere i carichi di lavoro particolarmente assetati di energia e potenza, e quindi capaci di trarre benefici tangibili dall’uso di un P-Core, come ad esempio le operazioni che fanno uso di estensioni AVX/AVX2 o AVX-VNNI (Vector Neural Network Instruction) per l’accelerazione AI/DL. Una volta individuate, queste istruzioni verranno classificate e verrà inviata l’indicazione allo scheduler OS per la loro assegnazione sul core libero più adeguato. Al contrario, tutti gli eventuali thread in background, per i quali l’utilizzo di un P-Core offrirebbe solamente uno scarso o un moderato vantaggio, verranno indirizzati su un E-Core.
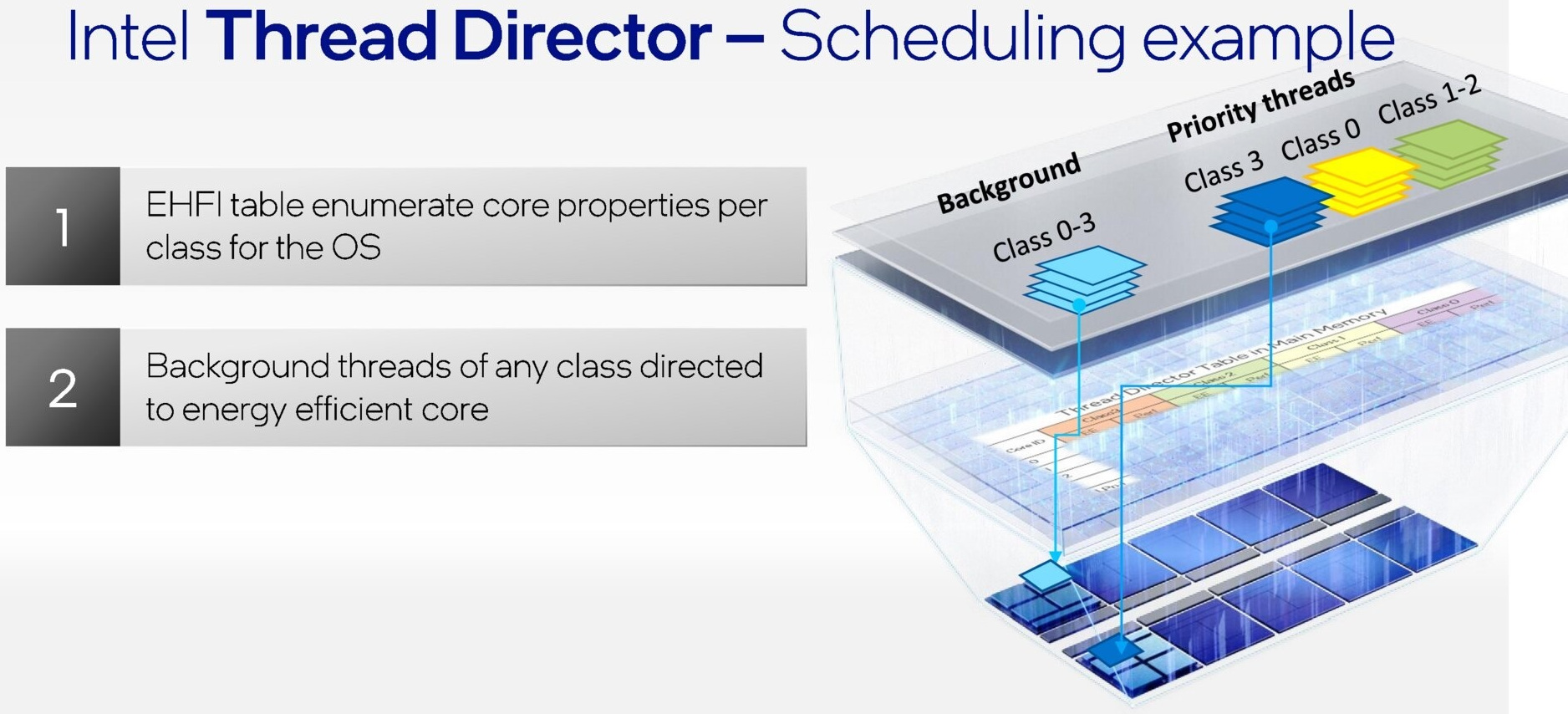
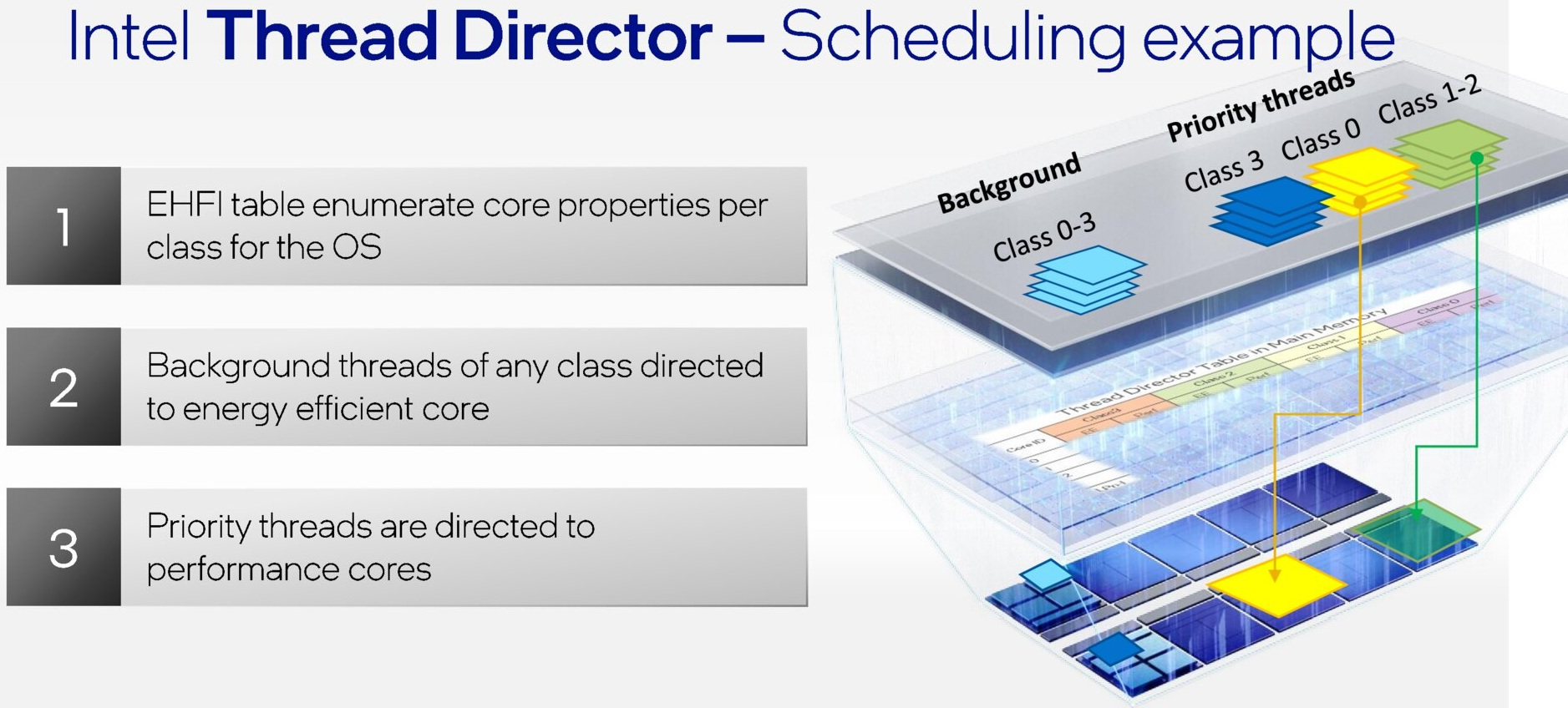
Tuttavia, potrebbero anche verificarsi situazioni particolari, nelle quali potrebbe comparire un thread ad alta priorità in un momento nel quale non vi sono P-Core liberi sufficienti, in questo caso l’algoritmo fornirà al sistema operativo un’indicazione su quale potrebbe essere un thread candidabile per la retrocessione, ovvero per il suo spostamento da un core ad un altro.
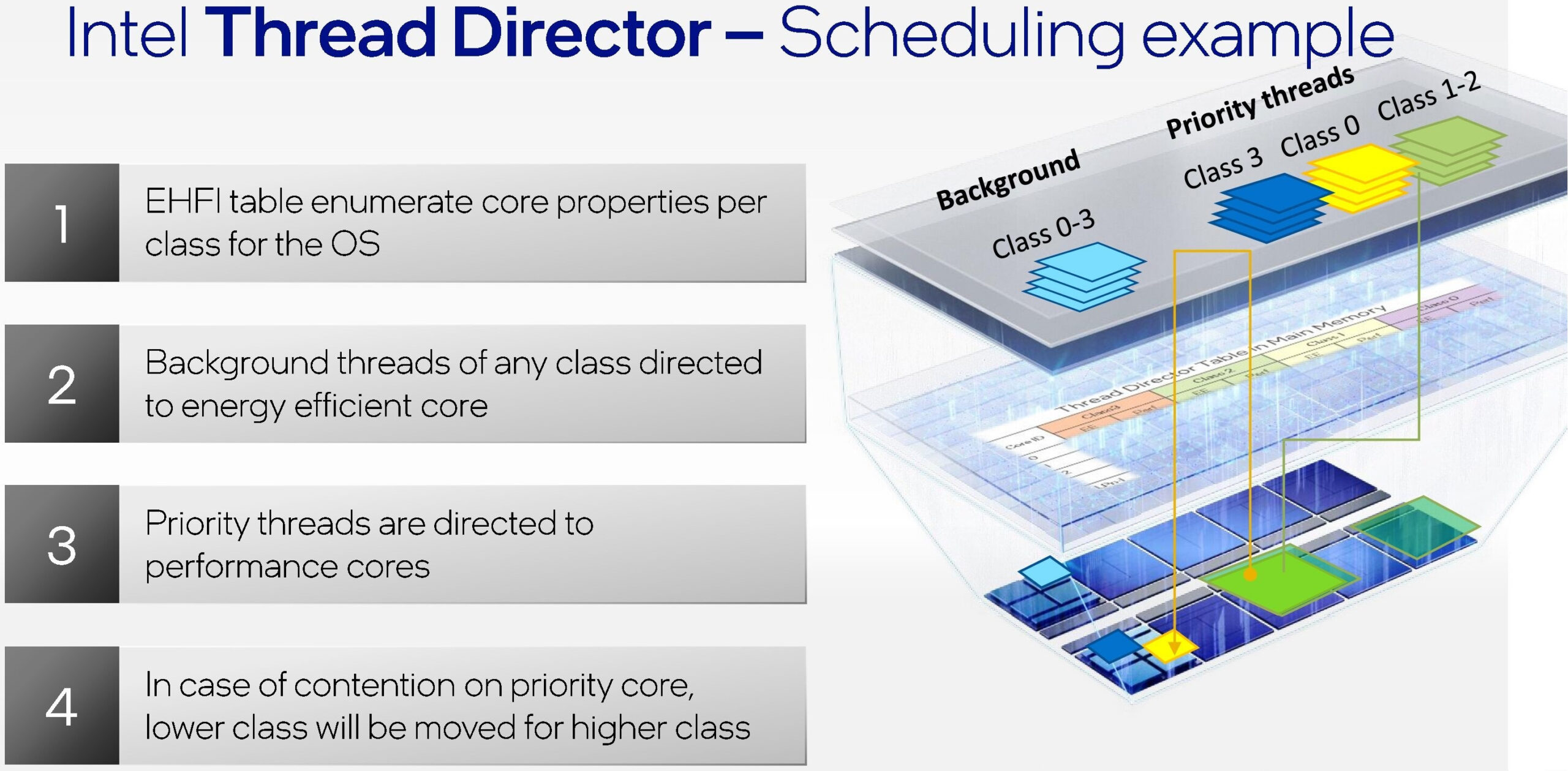
Tutto questo, inoltre, avviene in modo completamente automatico e senza che sia necessario alcun intervento da parte dell’utente. Ma non solo, la tecnologia messa a punto da Intel è anche in grado di adattare dinamicamente il suo comportamento sulla base delle condizioni operative riscontrate, delle impostazioni energetiche e del TDP, in modo da assicurare che in ogni singola “decisione” presa risulti ottimale per qualsiasi carico di lavoro, sfruttando appieno tutte le risorse disponibili.
Performance Core (P-Core): Uno sguardo alla nuova architettura Golden Cove

In seguito al progetto Cypress Cove, alla base come sappiamo delle soluzioni Core di undicesima generazione, l’azienda americana ha optato per un radicale cambio di rotta, focalizzando le proprie risorse sulla messa a punto di una microarchitettura completamente nuova, espressamente pensata non soltanto per far fronte ai sempre più impegnativi carichi di lavoro, ma soprattutto per rappresentare una solida base di partenza per future evoluzioni. Fu così che in occasione del debutto della dodicesima generazione delle soluzioni Core, fu svelata la microarchitettura nota con il nome in codice di Golden Cove, architettura che troviamo alla base dei nuovi Performance-Core (P-Core) e che la stessa Intel definisce come la più innovativa e avanzata degli ultimi anni, facendo confronti con quello che rappresentarono per l’azienda le precedenti Skylake e prima ancora Nehalem.

Rispetto al passato sono stati profondamente rivisti gli elementi fondamentali della CPU, con grande attenzione sul Front-End, enormemente migliorato e potenziato. Il cambiamento più significativo riguarda la capacità di elaborazione in fase di decodifica, ora estesa a ben 6 istruzioni per ciclo rispetto alle 4 fino a quel momento previste in un’architettura x86. L’azienda non è mai entrata nel dettaglio circa un eventuale cambiamento nel layout dei decoder, nello specifico non sappiamo se è ancora previsto almeno un decodificatore complesso (ovvero dedicato all’elaborazione delle istruzioni che richiedono più di una micro-ops) oppure se troviamo solamente decoder semplici.
Al fine di rafforzare la fase di decodifica si è reso necessario un potenziamento della precedente fase di elaborazione fetch, che consiste nella lettura del flusso di istruzioni dalla cache L1-I del processore e del successivo passaggio ai decodificatori, per il quale è stato previsto un raddoppio, da 16 byte a ben 32 byte per ciclo. Questo non avveniva da decenni, sin dai tempi della microarchitettura P6 alla base dei Pentium Pro, introdotti pressappoco a metà degli anni novanta.
Nonostante non sia stato previsto un aumento della dimensione della cache L1-I, sempre ampia 32KB, l’azienda ne ha ottimizzato le latenze ed esteso la capacità della L1-iTLB (Translation Look-Aside Buffer) al fine di assicurare una maggiore copertura di codice. Nello specifico sono state aumentate le pagine 4K da 128 a ben 256 voci, mentre le pagine 2M/4M passano da 16 voci a 32 voci.
In concomitanza con l’aumento dei decoder è stata potenziata ed ampliata anche la cache μOP per le istruzioni già decodificate, ora capace di fornire fino a 8 μOP per ciclo e di ospitare un massimo di ben 4.000 istruzioni, quasi il doppio rispetto alle 2.250 istruzioni previste nella precedente architettura Cypress Cove. Questo aspetto contribuisce ad aumentare la possibilità che il processore trovi direttamente qui le istruzioni già pronte e non debba quindi attivare il decoder (da qui l’aumento dell’hit-rate), risparmiando di conseguenza energia. Secondo Intel questo scenario è quello più probabile, e si verificherebbe nell’80% del tempo di esecuzione.
Anche la coda μOP che segue la cache μOP è stata leggermente aumentata, passando da 70 a 72 voci per ciascuno dei due thread che l’architettura può elaborare, grazie al pieno supporto verso la tecnologia Hyper-Threading. Rispetto al passato, tuttavia, evidenziamo una differenza sostanziale, che consiste nella possibilità di combinare le code separate in una singola coda da ben 144 voci, in tutti quegli scenari nei quali il processore elabora solamente un thread invece che due.
Anche la Branch Prediction è stata resa decisamente più accurata, grazie ad un significativo aumento del Branch Target Buffer (BTB), che passa da 5.000 voci a ben 12.000 voci. L’azienda ha puntualizzato che il BTB può variare dinamicamente la sua dimensione grazie ad all’implementazione di uno speciale algoritmo basato sull’intelligenza artificiale, riducendola qualora non necessaria al fine di risparmiare energia oppure, in alternativa, aumentandola in tutti quei casi in cui vengano richieste maggiori prestazioni.
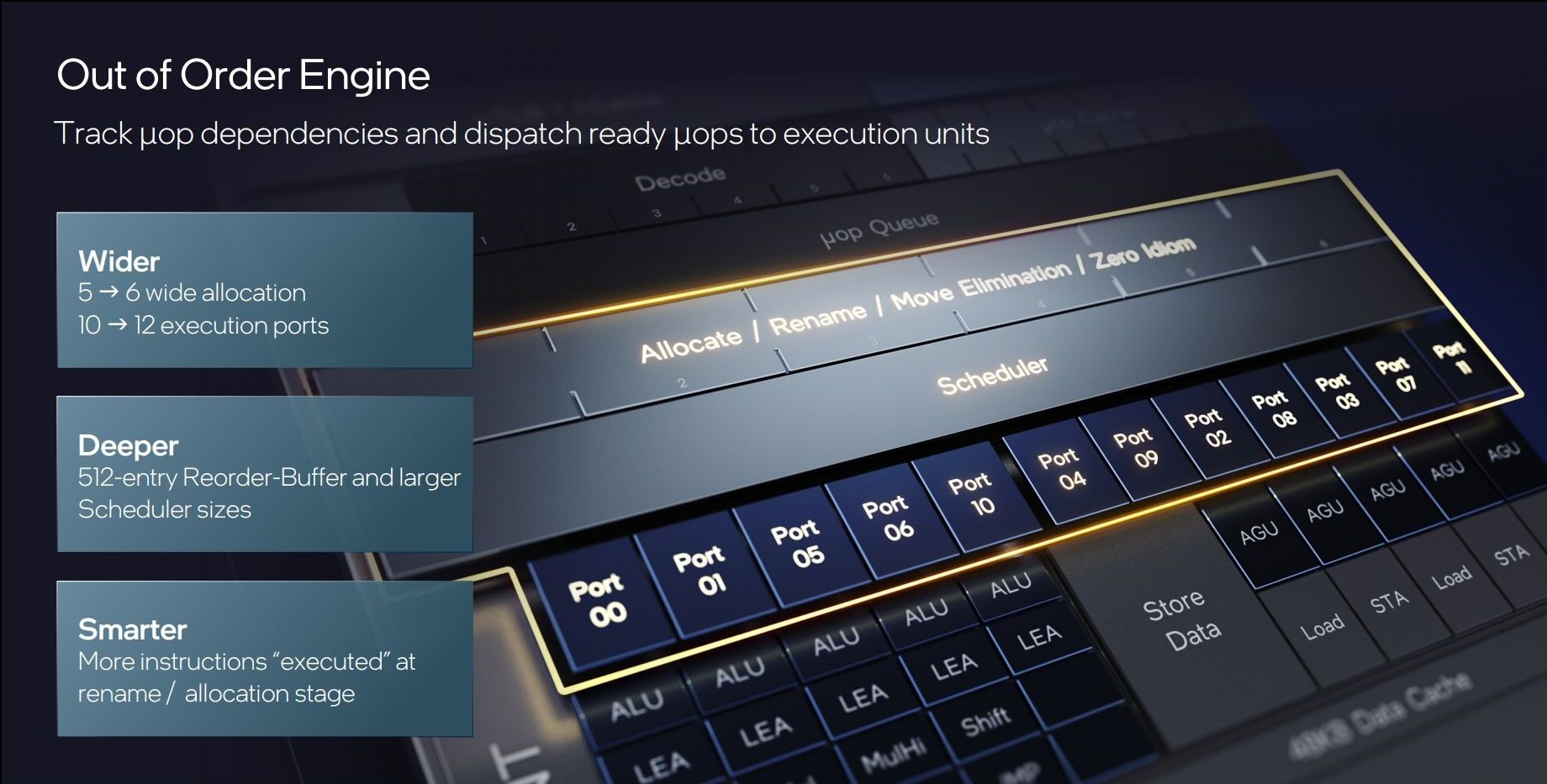
Oltre ai miglioramenti nel Front-End si evidenziano interventi degni di nota anche nel Back-End. Così come sono state rafforzate la fase di elaborazione fetch e la successiva fase di decodifica, anche la fase di allocazione è stata ampliata, passando da 5 a 6 istruzioni. Incrementato anche il numero delle porte di esecuzione parallele allo scheduler, da 10 a 12 porte.
L’Out of Order Engine è stato reso più ampio ed intelligente, allo scopo di incrementare l’IPC grazie alla possibilità di eseguire operazioni in un ordine diverso rispetto a quello previsto dal codice del programma. Per ottenere questo obiettivo alla CPU deve essere però fornita la piena visibilità in una “finestra” di codice sempre più ampia, in modo tale che possa reperire molte più operazioni indipendenti ed eseguirne il riordino. È stata quindi incrementata la dimensione della Re-Order Buffer (ROB) da 352 a ben 512 voci, un aumento tanto significativo quando inaspettato.

Per quanto riguarda il motore di esecuzione evidenziamo l’aggiunta di una quinta pipeline integer, dietro la porta 10. Le ALU o unità logiche aritmetiche (intere) salgono quindi a 5 rispetto alle 4 previste nell’architettura precedente. Tutte le ALU supportano anche l’istruzione LEA (Load Effective Address) a ciclo singolo per calcoli aritmetici generici.

Sul fronte della virgola mobile evidenziamo l’aggiunta di funzionalità Fast Adder (FADD) dedicate dietro le porte 1 e 5, capaci di assicurare una maggiore efficienza e una minore latenza rispetto all’utilizzo delle unità FMA. Queste ultime sono tuttavia state migliorate, aggiungendo loro il supporto verso dati FP16.

Significativi miglioramenti anche per quanto riguarda il sottosistema di memoria, per il quale è stata prevista una nuova porta di esecuzione dedicata con relativa unità load-store o AGU (Address Generation Units), aumentando così da 2 a 3 il numero di caricamenti/memorizzazioni per ciclo possibili. Nelle declinazioni consumer dei core Golden Cove assistiamo quindi ad aumento della larghezza di banda notevole rispetto alla precedente architettura, dal momento che saranno possibili ben tre caricamenti a 256-bit (AVX/AVX2) per ciclo dalla Cache L1, ovvero ben 768-bit/ciclo complessivi. La variante server di Golden Cove, provvista di supporto AVX-512, sarà eventualmente in grado di caricare ben 1Kb di dati per ciclo, suddivisi in due caricamenti a 512-bit per ciclo dalla Cache L1.
Pur mantenendo inalterata la capacità e l’associatività della memoria Cache L1-D, che al pari di Ice Lake/Sunny Cove rimane ampia 48 KB e riconferma le sue 12 vie, allo scopo di far fronte a carichi di lavoro sempre più parallelizzati a livello di memoria, Intel ha previsto diversi interventi alternativi, che spaziano dall’ottimizzazione del precaricamento, all’aumento del buffer di riempimento da 12 a 16, fino ad arrivare ad un incremento del TLB da 64 a 96 voci. Tutto questo assicura un miglioramento delle prestazioni del sotto-sistema di memoria. È stato inoltre aumentato il numero di page walk simultanee, passando da 2 a 4, così da assicurare migliori prestazioni anche nei casi in cui il processore avesse bisogno di recuperare dati da ulteriori livelli del sotto-sistema di memoria.

Anche la memoria Cache L2 è stata enormemente ampliata e ottimizzata. Nello specifico, nella declinazione consumer di Golden Cove troviamo 1.25MB per ciascun core, ovvero il triplo rispetto ai 512KB per core previsti nelle precedenti soluzioni Cypress Cove. Oltre alla capacità è stata prevista la possibilità di gestire un maggior numero di cache-miss, ovvero di richieste di dati da altri livelli del sotto-sistema di memoria quando questi non si trovano nella L2), passando da 32 a ben 48 richieste in sospeso, e contribuendo ad un miglioramento delle capacità di parallelismo a livello di memoria (MLP).
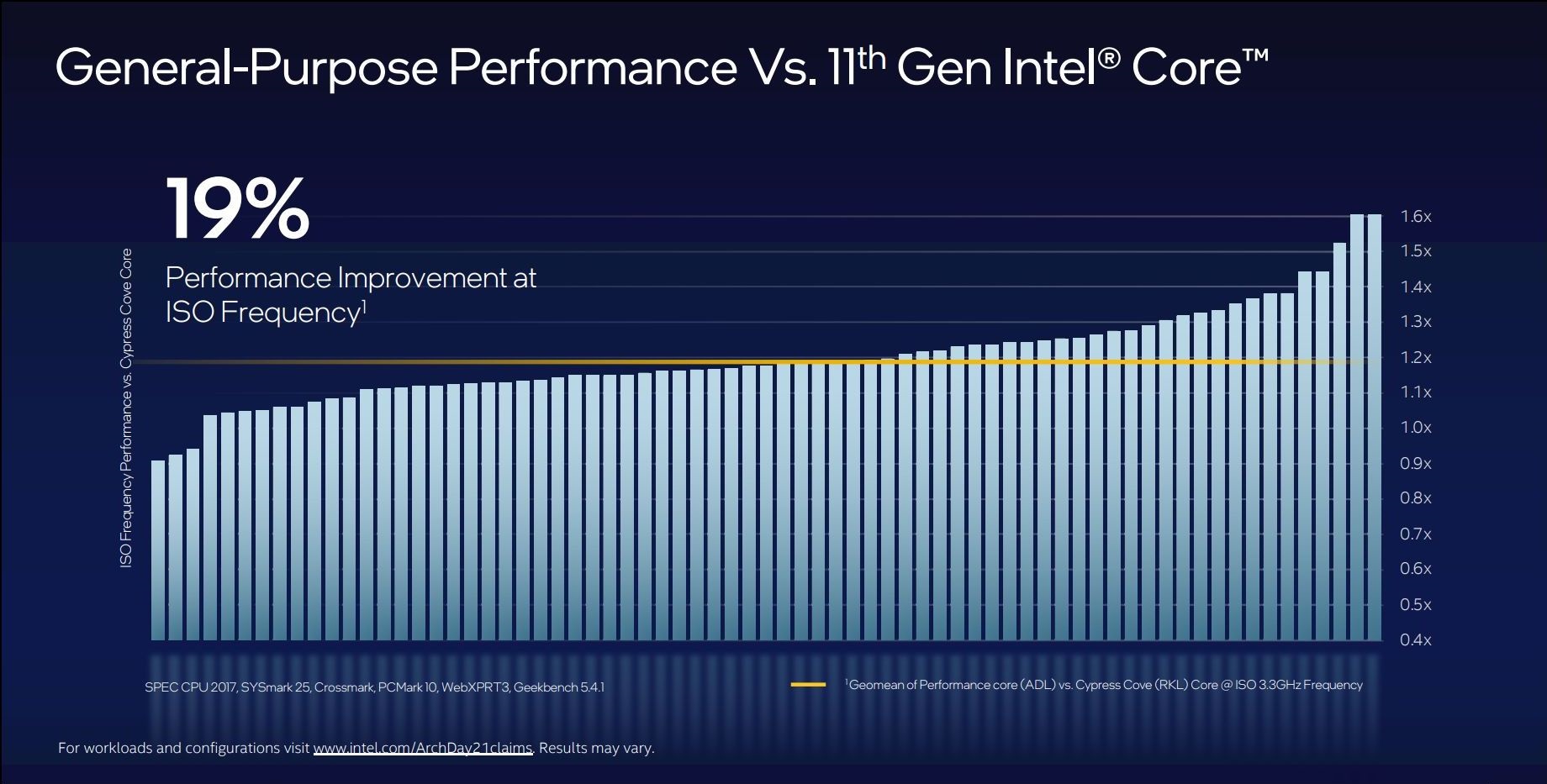
L’insieme di tutti le novità previste nella nuova microarchitettura Golden Cove assicura un aumento dell’IPC (Istruzioni per Ciclo) del tutto consistente, stimato dalla stessa Intel in un +19% medio rispetto ai già prestanti core Cypress Cove, alla base delle soluzioni Core di 11esima generazione.
Efficient Core (E-Core): Uno sguardo alla nuova architettura Gracemont

Come precisato più volte nel corso del nostro articolo, la nuova architettura ibrida ad elevate prestazioni di Intel prevede due diverse tipologie di core al suo interno, ognuna contraddistinta da una differente microarchitettura di base. Dopo aver osservato le caratteristiche dell’innovativa Golden Cove, per la quale l’azienda americana ha impiegato tutta la sua esperienza e risorse allo scopo di ottenere il più grande salto prestazionale degli ultimi anni, è giunto il momento di analizzare più attentamente l’altrettanto interessante Gracemont, che troviamo alla base dei piccoli Efficient Core (E-Core).
Questa nuova microarchitettura ad alta efficienza fa parte della famiglia di processori Atom e trae le sue fondamenta dalla precedente Tremont, il cui debutto risale al 2020, estendendone però in modo significativo caratteristiche e potenzialità. Pur trattandosi di un progetto espressamente pensato per soluzioni a basso consumo, infatti, non bisogna assolutamente pensare che le prestazioni non siano comunque ragguardevoli o che siano state messe in secondo piano durante la fase di progettazione, basti pensare che vengono sostanzialmente raggiunti i livelli in single-thread di un core Comet Lake delle CPU di decima generazione.
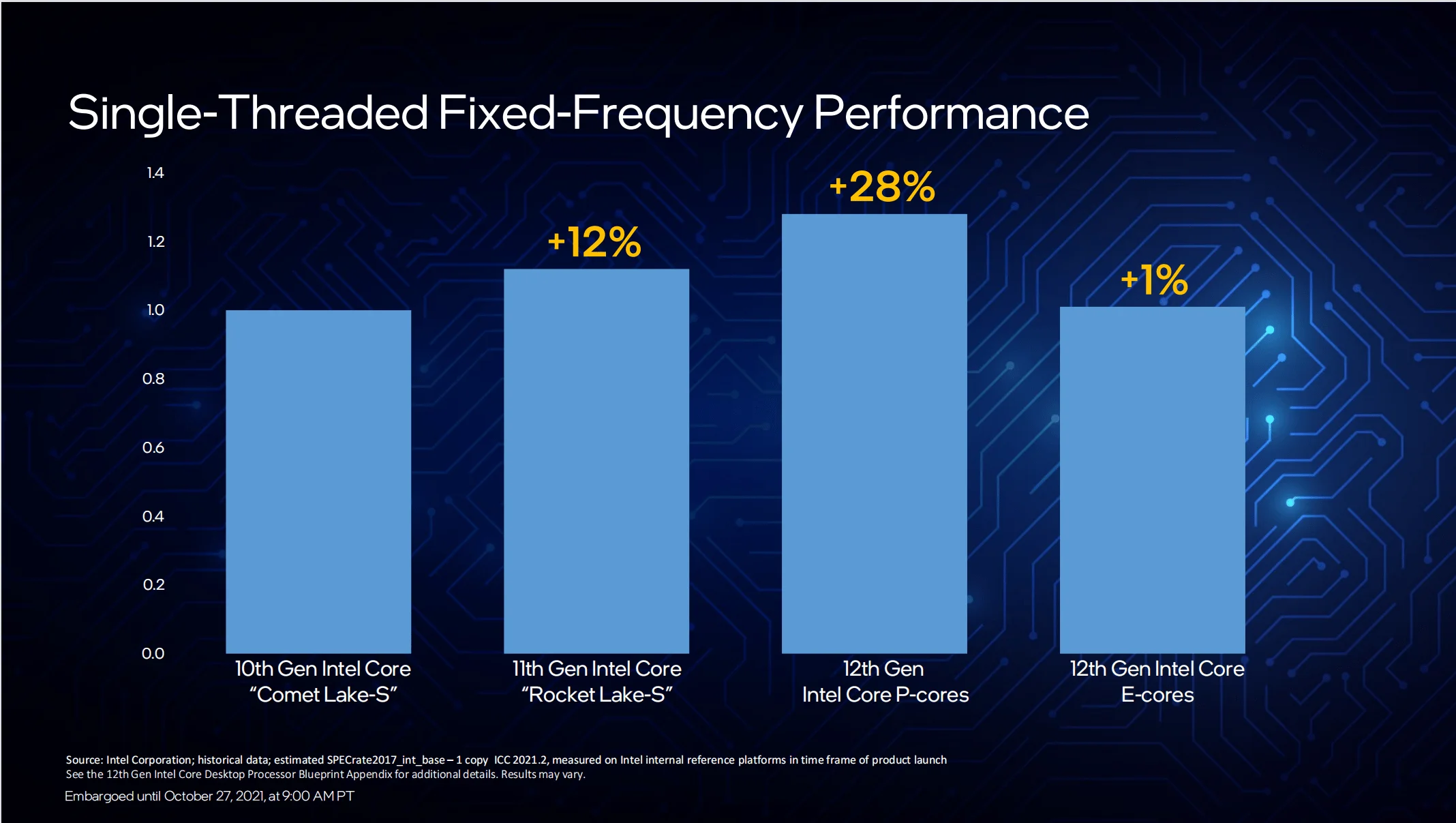
L’azienda americana ha anche divulgato i risultati di un confronto diretto con i core Skylake. Nello specifico viene evidenziato come, in single-thread, un nuovo core Gracemont sia in grado di restituire ben il 40% in più di performance rispetto ad un core Skylake, o dal punto di vista energetico, di assicurare le medesime performance con una riduzione del 40% in termini di consumo.

Del tutto degno di nota è anche il risultato in termini di througput multi-thread, per il quale viene mostrato un confronto tra un chip Skylake (2C/4T) ed un cluster E-Core Gracemont (4C/4T), da cui si evince come i nuovi core siano in grado di restituire un livello di prestazioni superiore dell’80%, oppure performance equivalenti ma consumando l’80% in meno.

Per ottenere questi livelli di prestazioni ed efficienza si sono resi necessari numerosi interventi a livello architetturale, a cominciare dal Front-End. Al pari di Tremont viene mantenuto il doppio percorso di decodifica simultanea da 3 istruzioni per ciclo, ma viene ora supportato da una memoria Cache L1-I di dimensioni raddoppiate, pari a ben 64KB. Oltre a questo, è stata migliorata e resa più accurata anche la Branch Prediction, grazie a prefetcher ora abilitati in tutti i livelli di cache ed una Branch Target Buffer (BTB), che raggiunge le 5.000 voci.

A differenza di quanto osservato in Golden Cove, i piccoli core Gracemont non prevedono una cache μOP, di conseguenza le istruzioni devono seguire ogni volta il normale percorso di decodifica. Per semplificare le cose è stato previsto un nuovo decodificatore, denominato OD-ILD (On-Demand Instruction Length Decoder), in grado di memorizzare una sorta di cronologia delle decodifiche precedenti direttamente nella memoria Cache L1-I, così che all’occorrenza possano essere da essa prelevate le informazioni necessarie per bypassare la consueta fase di decodifica risparmiando tempo e risorse.
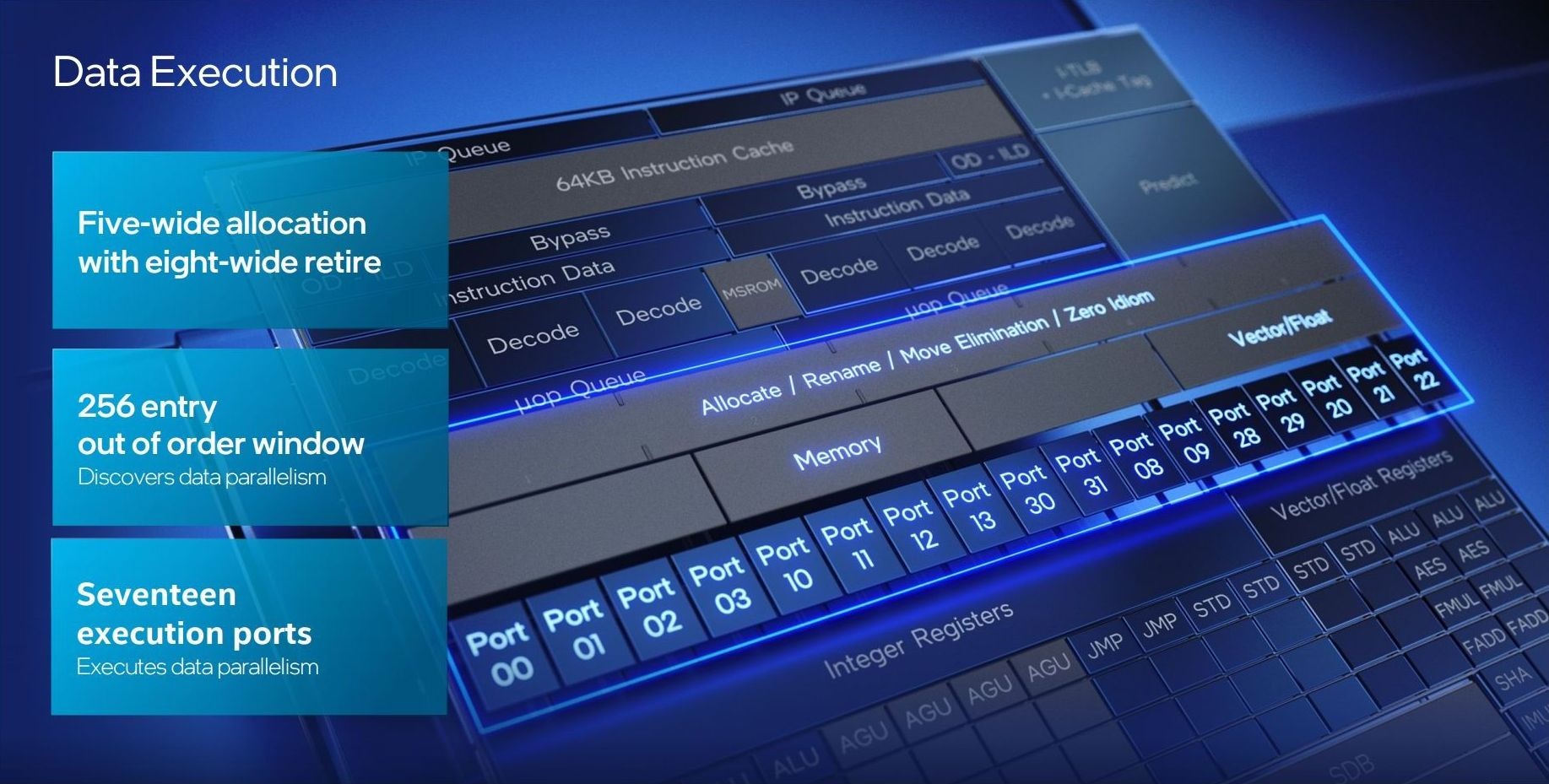
Anche per Gracemont, e al fine di aumentare le potenzialità in termini di parallelismo dei dati, è stato previsto un significativo aumento della dimensione della Re-Order Buffer (ROB), che passa dalle 208 voci massime di Tremont, a ben 256 voci.
Per quanto riguarda l’Execution Engine ci troviamo di fronte ad un Back-End del tutto sovradimensionato, con ben 17 porte di esecuzione parallele, addirittura più di quelle previste nei core Golden Cove. Tuttavia, la fase di allocazione prevede l’elaborazione di un massimo di 5 istruzioni per ciclo. Sul percorso di ritorno, invece, ogni core può ritirare fino a 8 istruzioni per ciclo. È possibile quindi che Intel abbia puntato ancora una volta sul massimo parallelismo, prevedendo un uso ripetuto delle istruzioni.
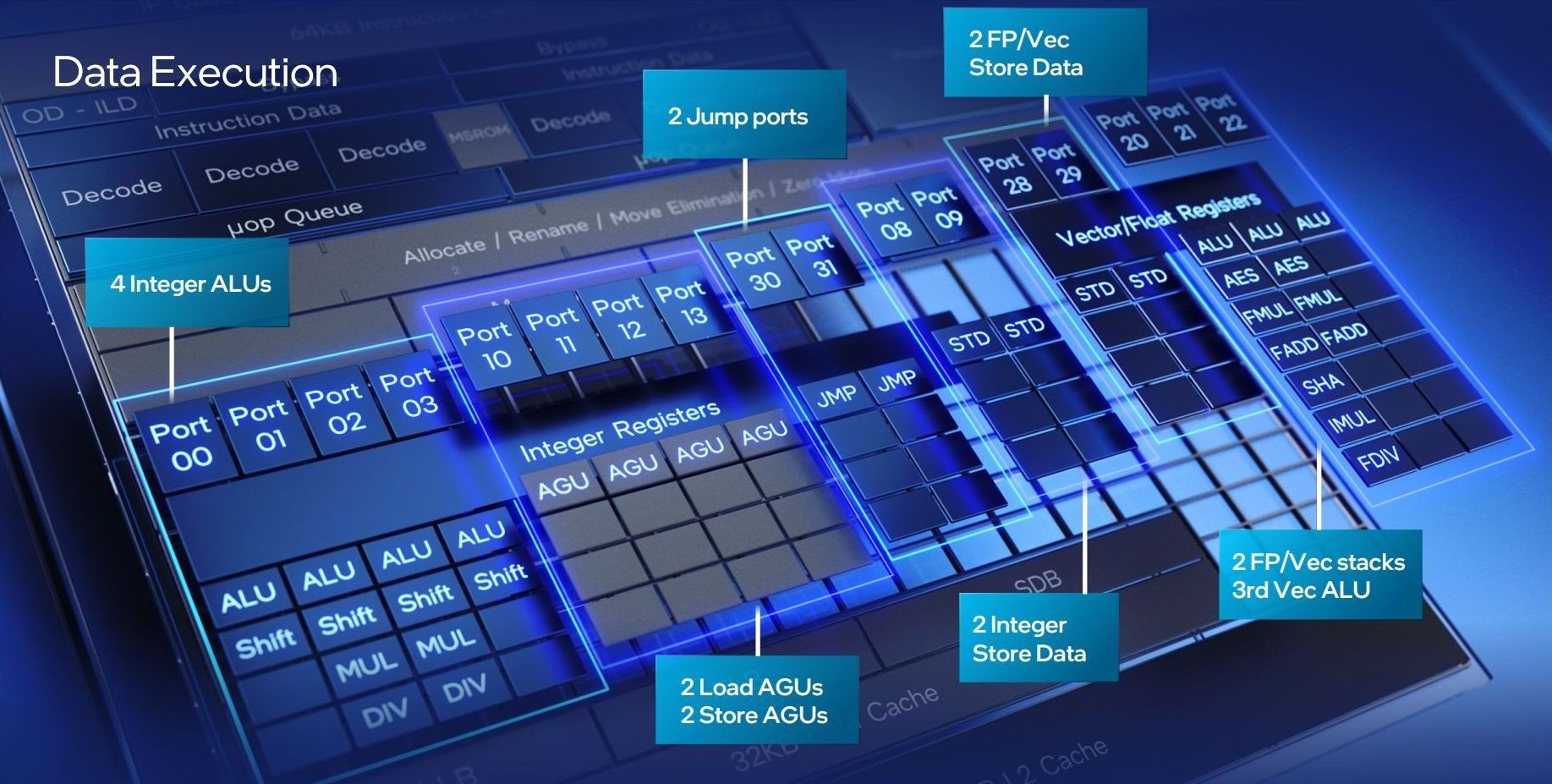
Rispetto a Tremont si evidenzia l’aggiunta di un’ulteriore pipeline integer. Le ALU o unità logiche aritmetiche (intere) salgono quindi a 4 rispetto alle 3 previste nell’architettura precedente. Due di queste ALU possono eseguire operazioni di moltiplicazione/divisione (MUL/DIV). Anche il cluster FP/Vettoriale è stato potenziato, prevedendo l’aggiunta di un’ulteriore ALU, raggiungendo le tre unità.

Sul fronte ISA (Instruction Set Arctitecture) vengono supportate per la prima volta in un core Atom le istruzioni AVX2. Troviamo di conseguenza anche due porte vettoriali (la 20 e la 21) in grado di supportare due operazioni simmetriche di addizione o moltiplicazione (FADD/FMUL) per ciclo. Viene anche previsto il supporto alle più recenti AVX-VNNI (Vector Neural Network Instruction) per l’accelerazione dei carichi di lavoro AI/DL.
Non mancano, inoltre, tutte le più recenti funzionalità di sicurezza dell’azienda, tra cui la tecnologia CET (Control Flow Enhancement Technology), la VT-rp (Virtualization redirect protection) e molto altro.

Novità anche per il sottosistema di memoria, per il quale è stato previsto un significativo miglioramento. Rispetto alla precedente architettura Tremont, sono state previste ben quattro porte di esecuzione con relative unità load-store o AGU (Address Generation Units), aumento così a quattro il numero dei caricamenti/memorizzazioni per ciclo possibili. In considerazione della capacità della memoria Cache L1-D, pari a 32 KB, si evince che sono consentiti due caricamenti da 16 byte e due memorizzazioni da 16 byte per ciclo sulla cache.
I core Gracemont prevedono un raggruppamento in cluster, precisamente composti da quattro core identici, privi di supporto alla tecnologia Hyper-Threading (HT), a loro volta affiancati da una memoria Cache L2 condivisa che può raggiungere un’ampiezza di 2MB o 4MB, unitamente ad una latenza di 17 cicli. Questa memoria condivisa, inoltre, è in grado di supportare fino a 64 byte per ciclo (lettura/scrittura) per core, oltre che di gestire fino a 64 cache-miss, ovvero di richieste di dati da altri livelli del sotto-sistema di memoria quando questi non si trovano nella L2, contribuendo al parallelismo a livello di memoria. Ricordiamo però che questo valore deve essere condiviso tra i quattro core che compongono il cluster. Al fine di assicurare l’equità di accesso alla cache da parte dei core che compongono il cluster, Intel ha messo a punto la tecnologia Resource Director.
In relazione poi al prodotto finale sarà possibile affiancare più cluster in maniera da incrementare il quantitativo di core disponibili, sfruttando le relativamente piccole dimensioni degli stessi. Sulla base degli schemi divulgati dall’azienda, infatti, ognuno di questi cluster, e relativa memoria cache condivisa, parrebbe occupare indicativamente lo spazio di un singolo Performance Core (P-Core), un dato notevole in considerazione delle prestazioni di tutto rispetto offerte.
[nextpage title=”Intel Core 13th Generation (Raptor Lake): Principali Caratteristiche Tecniche e Novità”]
Come abbiamo sottolineato nel capitolo precedente, con le nuove soluzioni Core di 13esima generazione, meglio note con il nome in codice Raptor Lake, l’azienda statunitense non ha previsto grossi stravolgimenti di quelle che sono le fondamenta della sua innovativa architettura ibrida ad elevate prestazioni.
In sostanza l’azienda si è focalizzata su interventi mirati al perfezionamento e al potenziamento di alcuni aspetti ritenuti significativi, al fine di alzare ulteriormente l’asticella delle prestazioni velocistiche e dell’efficienza.

Nello specifico gli sforzi dell’azienda si sono concentrati essenzialmente su tre punti chiave:
- Cercare di aumentare la frequenza di clock massima dei Performance Core (P-Core);
- Migliorare le prestazioni nei carichi di lavoro multi-thread grazie all’aggiunta di Efficient Core (E-Core);
- Potenziare il sottosistema di memoria incrementando la capacità della Cache L2.

Per il primo di questi punti non sono stati richiesti sforzi particolari, al contrario è stato sufficiente sfruttare il fisiologico affinamento del processo produttivo proprietario a 10 nanometri, denominato Intel 7, in grado ora di avvalersi della terza generazione dei transistor SuperFin, capace di assicurare una maggiore mobilità del canale.
Questo ha consentito di incrementare sensibilmente le frequenze di clock massime dei Performance Core (P-Core) su tutta la linea, raggiungendo nel modello di punta, il nuovo Core i9 13900K, quota 5.8GHz, vale a dire ben 600MHz in più rispetto ai 5.2GHz che potevano essere raggiunti dal precedente Core i9 12900K sfruttando i vari algoritmi previsti dalla tecnologia Turbo Boost.
Non solo, la maggiore mobilità del canale dei nuovi transistor ha permesso di apportare una sensibile ottimizzazione alla curva V/F (Tensione/Frequenza), consentendo di ridurre di oltre 50mV la tensione necessaria per una data frequenza (ISO-Frequency) e di aumentare di 200MHz la frequenza ad una data tensione (ISO-Voltage).
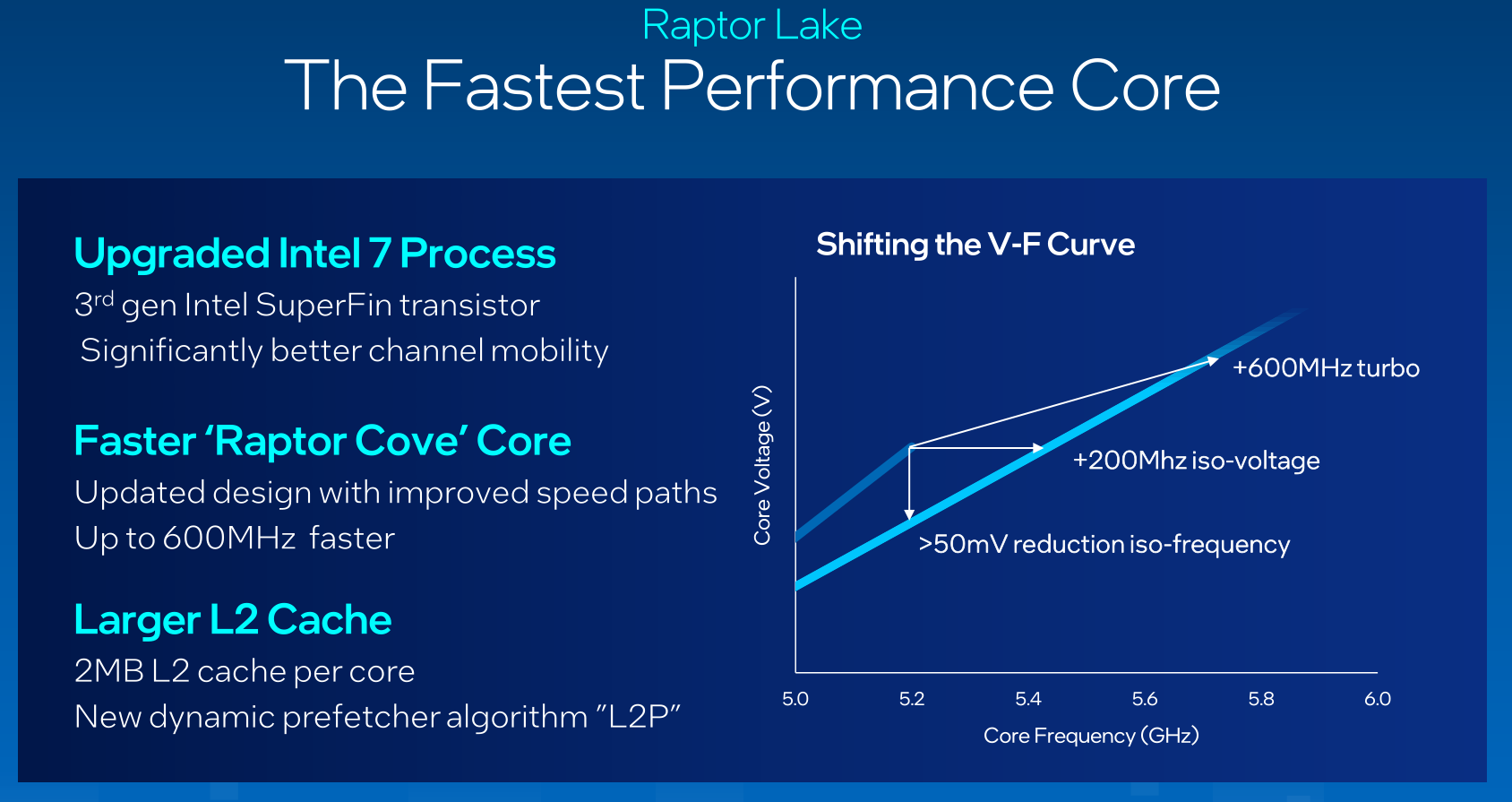
Nonostante i Performance Core (P-Core) integrati nelle nuove soluzioni mantengono inalterata l’architettura di base, a fronte degli interventi apportati l’azienda ha ugualmente deciso di ribattezzarli con un nuovo nome, abbandonando il “vecchio” Golden Cove in favore di Raptor Cove. A caratterizzare questi “nuovi” core troviamo cambiamenti nella struttura e nella gestione della memoria cache di secondo livello (Cache L2), per la quale è stato previsto un aumento della capacità pari a 1.6X, passando dagli 1.25MB a ben 2MB per core.
Introdotto anche un nuovo algoritmo di prefetcher dinamico, denominato L2P, pensato per regolare dinamicamente ed in tempo reale il comportamento del prefetcher in relazione al carico di lavoro in esecuzione. Oltre a questo, è stata aggiunta una particolare policy dinamica di tipo inclusive/non-inclusive (Dynamic INI) per la Cache L2 ed L3, migliorando le prestazioni tanto in single-thread quanto in multi-thread a seconda se venga adottata una policy L3 inclusiva (tutti i dati della memoria Cache L2 sono memorizzati anche all’interno della Cache L3) oppure una policy L3 non-inclusiva (solamente alcuni dati selezionati della Cache L2 verranno memorizzati anche all’interno della Cache L3).
Nel complesso, l’azienda statunitense stima che le sole modifiche alla cache siano in grado di assicurare un aumento delle prestazioni fino al 16% a seconda del carico di lavoro.
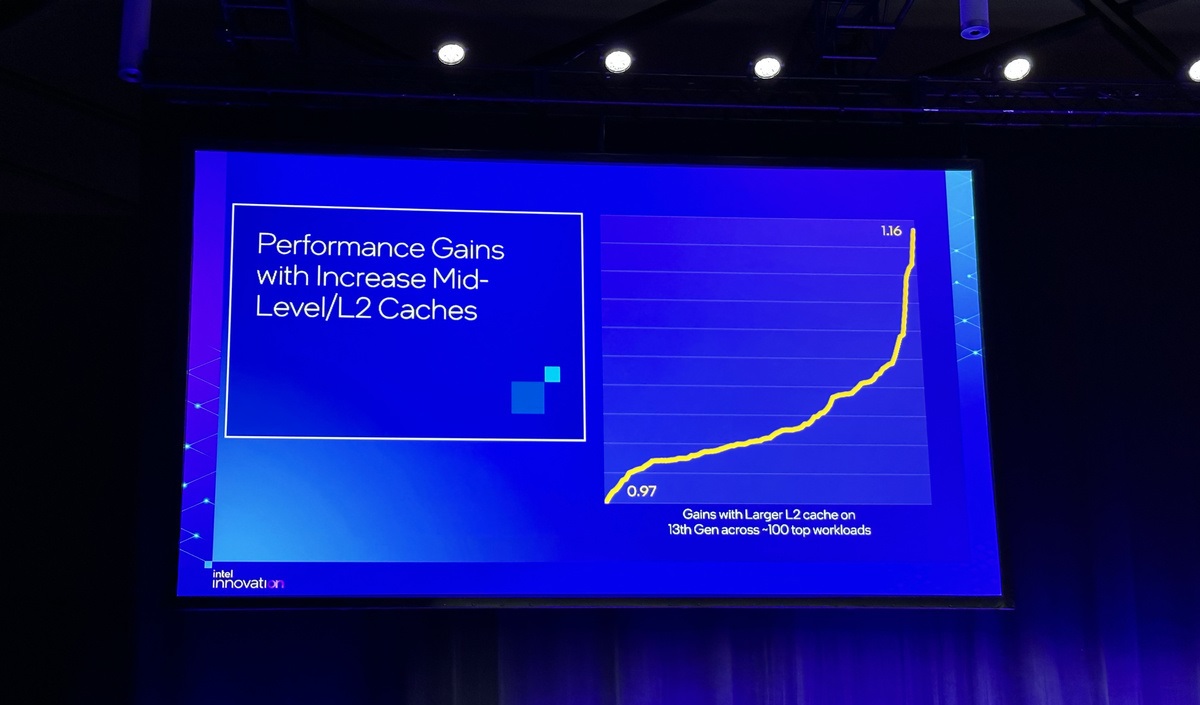
Come osservato nel precedente capitolo gli Efficient Core (E-Core) si contraddistinguono non soltanto per la loro notevole efficienza, scalabilità e performance di tutto rispetto, ma soprattutto per le loro relativamente piccole dimensioni. Un intero cluster, infatti, composto da quattro core Gracemont e relativa memoria Cache L2 condivisa, occupa a grandi linee lo stesso spazio che servirebbe per inserire un singolo Performance Core (P-Core) all’interno del die.
Dal momento che l’obiettivo dell’azienda americana era quello di incrementare le performance multi-thread, la via più semplice e a minor “costo” (in termini di spazio occupato all’interno del Die) per raggiungerlo non poteva che essere l’aggiunta di uno o più cluster di E-Core.
Rispetto alla precedente generazione è stata ampliata la memoria Cache L2 condivisa tra i quattro core del cluster, salendo da 2MB a 4MB. Eccetto questo non si evidenziano ulteriori interventi a livello prettamente architetturale a carico dei core Gracemont.
Al pari dei Performance Core (P-Core), e sempre grazie all’affinamento del processo produttivo Intel 7, anche la frequenza di clock dei piccoli core Gracemont ha subito un leggero ritocco verso l’alto. Confrontando i due modelli di punta, il Core i9 12900K della passata generazione, ed il nuovo Core i9 13900K assistiamo, infatti, ad un incremento di ben 400MHz, passando da 3.9GHz a ben 4.3GHz e contribuendo all’aumento del loro IPC.

Oltre a quanto riportato finora si aggiunge un rinnovato controller di memoria integrato (IMC), capace di assicurare il supporto a velocità di trasferimento superiori. Rispetto alle soluzioni della passata generazione, infatti, Raptor Lake vanta un supporto di base verso moduli di memoria DDR5 a 5.600MT/s (contro i 4.800MT/s di Alder Lake), oltre che alle più comuni DDR4-3200. Occorre tuttavia precisare che la velocità indicata si riferisce ad una configurazione classica 1 DPC (1 DIMM per canale). Installando due moduli per canale (2 DPC) si scende a quota 4.400MT/s (Alder Lake si fermava a 4.000MT/s).
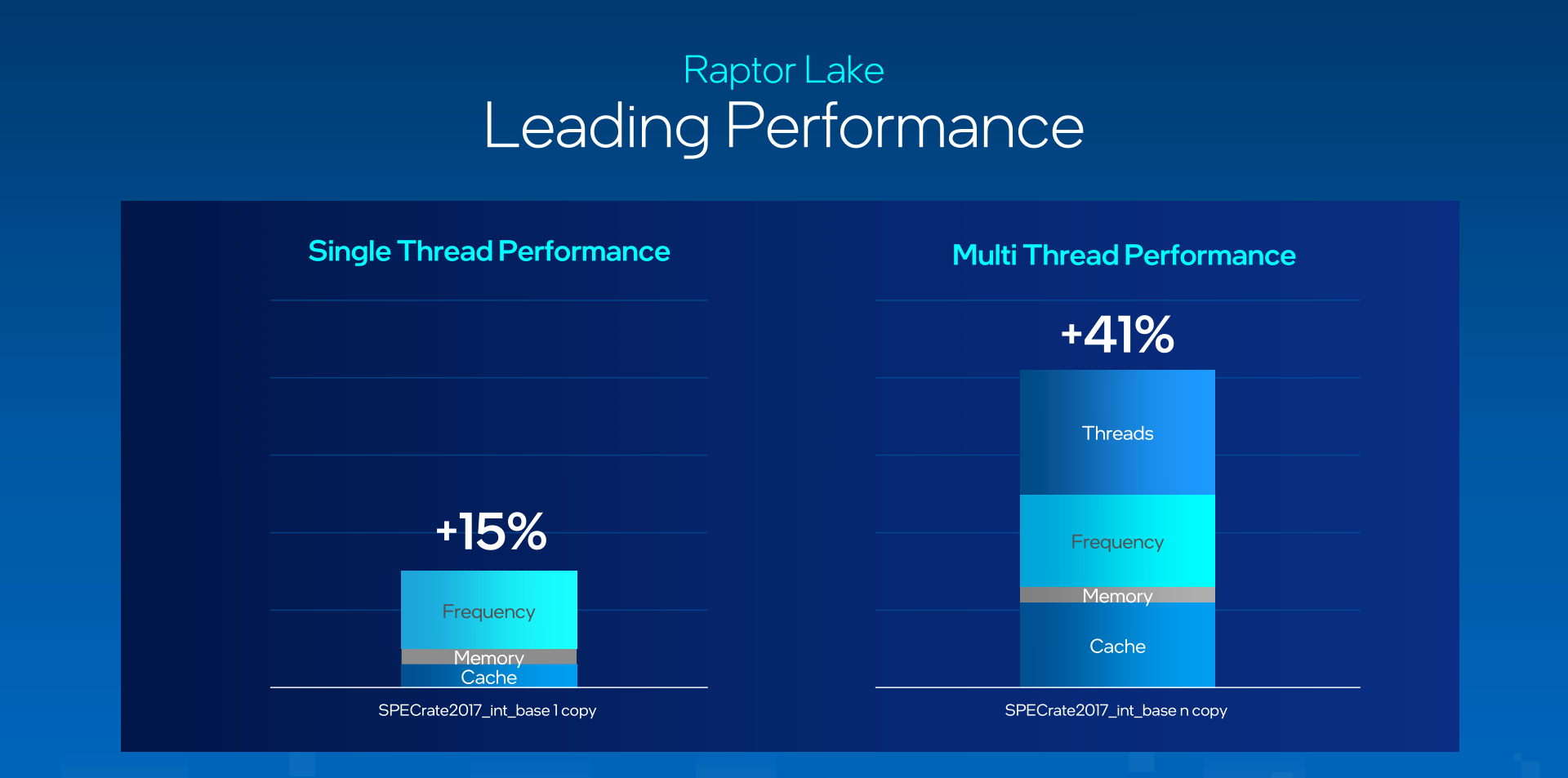
Come si evince dal grafico sopra riportato, l’insieme di tutti questi interventi assicura un deciso miglioramento delle prestazioni nel confronto tra i modelli di punta di nuova e precedente generazione, tanto in single-thread, dove viene raggiunto un +15%, quanto in multi-thread, dove viene superato addirittura il +40%.
[nextpage title=”Intel Core 13th Generation (Raptor Lake-S): Uno sguardo alla nuova line-up desktop”]
Il colosso di Santa Clara, ormai da qualche tempo a questa parte, ci ha abituati ad una strategia di lancio dall’alto verso il basso, partendo quindi dai modelli di fascia superiore, e di conseguenza più ricchi di funzionalità esclusive, per poi andare man mano a completare la sua line-up con le soluzioni di livello più basso.
Al momento della stesura di questo articolo è praticamente disponibile sul mercato l’intera line-up desktop mainstream di tredicesima generazione, comprendente tutti i modelli appartenenti alle famiglie Core i3, Core i5, Core i7 e Core i9 di base, con e senza componente grafica integrata, oltre che a più basso consumo.

Grazie al nuovo schema di nomenclatura semplificato, l’azienda rende più facile l’identificazione dei vari modelli in relazione alle loro caratteristiche, sottolineandone gli aspetti principali che li contraddistinguono.

Lo schema di denominazione Intel inizia con il marchio del processore, la linea di prodotti complessiva per cui è stato creato il processore. I nomi dei processori Intel più comuni iniziano con Intel® Core™ o con la nuova convenzione di denominazione dei marchi: Intel® Processor (che sostituirà le linee di prodotti Intel® Pentium® e Intel® Celeron® a partire dal 2024), una linea di prodotti economici creata per i consumatori attenti al prezzo. I processori Intel® Core™, al contrario, offrono prestazioni superiori e funzionalità aggiuntive, allo scopo di soddisfare un’utenza più esigente.

La serie di processori Intel® Core™ include un modificatore di marchio prima delle parti rimanenti del numero di modello. I processori Intel® Pentium® e Intel® Celeron® non utilizzano questa convenzione di denominazione. Oggi, la serie di processori Intel® Core™ include i modificatori i3, i5, i7 e i9. I numeri di modifica del marchio più alti offrono un livello più elevato di prestazioni e, in alcuni casi, funzionalità aggiuntive (come la tecnologia Intel® Hyper-Threading). Ad esempio, all’interno di una determinata famiglia di processori, un i9 supererà un i7, che a sua volta supererà un i5 e un i3.

Dopo la marca e il modificatore troviamo l’indicatore di generazione del processore. Le generazioni di processori Intel® sono identificate nel numero del processore nella maggior parte dei marchi di processori Intel® Core™, con la generazione elencata dopo il trattino. Quando un processore ha quattro o cinque cifre, le prime una o due cifre rappresentano la generazione. Ad esempio, un processore con le cifre 9700 è un processore di nona generazione, mentre uno con l’etichetta 13700 è un processore di tredicesima generazione.

Per la maggior parte dei processori Intel®, le ultime tre cifre del codice prodotto sono la SKU, che segue il numero di generazione e serve a differenziare le funzionalità all’interno di una famiglia di processori, tra cui velocità di clock di base, frequenza massima, dimensione della cache, numero di core/thread, supporto della memoria e altro. Uno SKU più alto sarà sinonimo di più funzionalità. Tuttavia, i numeri SKU non sono generalmente il miglior indicatore per il confronto tra diverse generazioni o linee di prodotti.

Ultimo, ma non per questo meno importante, è l’eventuale suffisso, pensato per fornire ulteriori informazioni circa alcune caratteristiche chiave che contraddistinguono uno specifico modello.

Prendendo come riferimento i modelli dedicati al segmento desktop, la lettera di suffisso indicherà quanto segue:
- K: Modello ad elevate prestazioni contraddistinto da funzionalità di overclocking, grazie al moltiplicatore completamente sbloccato;
- F: Modello privo di componente grafica abilitata. Sarà quindi necessario prevedere una soluzione grafica discreta;
- S: Modello speciale, contraddistinto ad esempio da frequenze di clock più elevate e quant’altro;
- T: Modello a più basso consumo;
- Nessun suffisso: Modello di base, privo di funzionalità specifiche per l’overclocking.
Queste lettere potranno in alcuni casi essere combinate tra loro, pur senza in alcun modo perdere o veder cambiato il loro significato. Per fare un esempio pratico, il microprocessore Core i9-13900KF avrà tutte le caratteristiche del normale Core i9-13900K, tra cui il moltiplicatore sbloccato per l’overclocking, ma si differenzierà a causa della componente grafica, che risulterà disabilitata di serie.
Sulla base di quanto descritto vi proponiamo una tabella riepilogativa delle caratteristiche tecniche principali di tutti i microprocessori Core di 12esima e di 13esima generazione finora presentati dall’azienda statunitense, così da consentirvi di fare un rapido confronto di quelle che sono le loro più significative differenze.
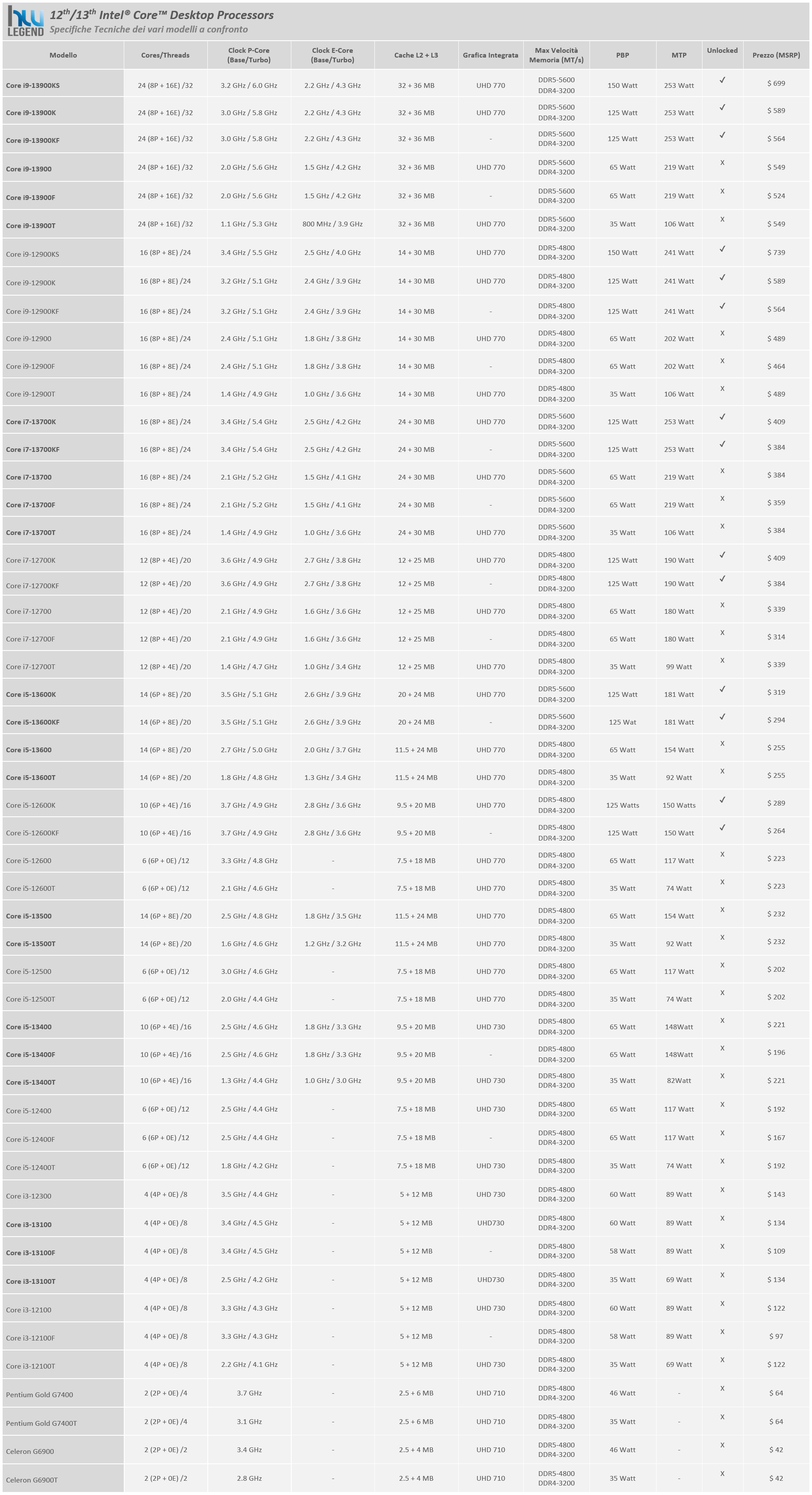
Come possiamo notare, quasi tutti i nuovi modelli prevedono un maggior quantitativo di core integrati, nello specifico di Efficient Core (E-Core) e di memoria cache, oltre che di un ritocco verso l’alto in termini di frequenze di clock in Turbo Boost. Solamente in alcuni modelli di fascia superiore si evidenzia una leggera riduzione della frequenza di clock di base, resa necessaria, con tutta probabilità, per mantenere un consumo accettabile a fronte delle varie aggiunte.
Per alcuni modelli di fascia inferiore, al contrario, l’azienda si è limitata ad una sorta di rebranding, mantenendo fondamentalmente inalterate le caratteristiche di base, compresa l’architettura dei P-Core che a dispetto delle apparenze rimane quella delle soluzioni Alder Lake (Golden Cove), e prevedendo esclusivamente un leggero aumento delle frequenze di clock. È il caso, ad esempio, dei microprocessori Core i3-13100 (e delle relative varianti F e T), che appaiono sostanzialmente identici, in termini prettamente tecnici, ai rispettivi modelli della precedente generazione che sostituiscono.
Un altro caso particolare è rappresentato dal modello Core i5-13400, nonché dalle sue varianti F e T, che seppur rappresentando un valido upgrade rispetto alle proposte equivalenti della passata generazione (ci riferiamo ovviamente all’aggiunta di un cluster E-Core completo, precedentemente assente), ne condivide le caratteristiche architetturali di base. Nonostante per questo modello sia prevista la disponibilità di due varianti in relazione allo stepping, precisamente identificate come C0/SMRBN (Alder-Lake) e B0/SMRBG (Raptor Lake), non si evidenzia alcuna differenza a livello tecnico e di specifiche tra di esse, con frequenze, quantitativo di memoria cache, limiti di potenza e quant’altro che appaiono infatti del tutto identici. Precisiamo che in questi modelli troviamo un cluster Gracemont contraddistinto da 2MB di memoria Cache L2 condivisa, e non i 4MB previsti nelle altre soluzioni di tredicesima generazione.
Concludiamo lacciandovi con un’interessante, video recensione del processore Intel Core i5 13400F, realizzata dal nostro Davide!
Buona visione ragazzi!
[nextpage title=”PCH Intel Serie 700: Principali Caratteristiche Tecniche e Novità”]
Come di consueto, in concomitanza con il debutto di una nuova architettura Core, è abitudine di Intel presentare anche una nuova linea di PCH, in questo caso appartenenti alla Serie 700 ed espressamente pensati per offrire pieno supporto verso i nuovissimi microprocessori di tredicesima generazione, meglio noti con il nome in codice “Raptor Lake” e sviluppati con l’avanzato processo produttivo a 10 nanometri denominato Intel 7.
Se con la passata generazione abbiamo assistito ad un cambiamento del tutto radicale, con l’introduzione, per la prima volta in ambito desktop di un’architettura di tipo ibrido ad elevate prestazioni, contraddistinta dalla presenza di differenti core all’interno della medesima CPU, con queste ultime soluzioni ci troviamo dinanzi ad interventi ben più marginali, che possiamo essenzialmente indicare come un semplice perfezionamento di quelle che erano le precedenti proposte.
![]()
![]()
Di conseguenza non sono state necessarie modifiche per quanto riguarda il socket di connessione, che rimane il tradizionale LGA-1700, con il risultato che sarà possibile utilizzare tutti i nuovi processori Raptor Lake anche sulle precedenti schede madri provviste di PCH serie 600, ovviamente previo aggiornamento del BIOS, oppure viceversa uno dei tanti microprocessori basati su architettura Alder Lake sulle nuove soluzioni dotate dei nuovi PCH Serie 700.
Sempre più che buona la differenziazione in relazione alle caratteristiche e alle funzionalità offerte, spaziando da modelli meno completi e di conseguenza più economici, come il B760 e l’H770, indubbiamente idonei all’utilizzo in soluzioni a basso costo e di più ridotte dimensioni, fino ad arrivare al modello più avanzato, il top di gamma Z790, pensato per la realizzazione di soluzioni rivolte ad un’utenza più esigente che necessita di maggiori funzionalità (come ad esempio il supporto all’overclocking) e flessibilità in quanto a possibilità di espansione.
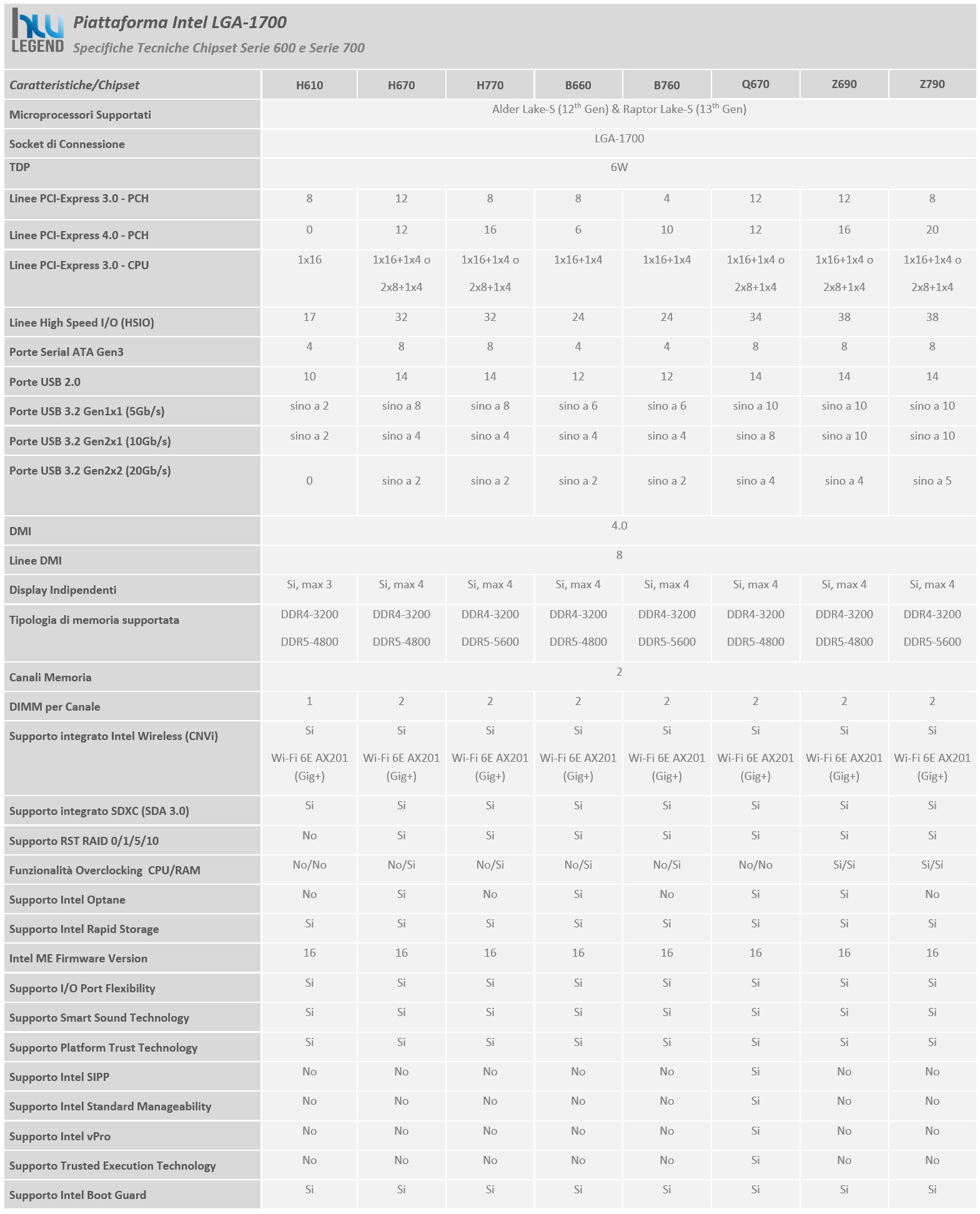
Facendo un rapido confronto con il precedente modello di punta di pari fascia, ovvero il PCH Z690 Express, le novità introdotte non possono essere definite sostanziali, ma sicuramente meritevoli di attenzione. Per quanto riguarda le funzionalità di rete viene ad esempio mantenuto il supporto Ethernet opzionale da 2.5Gbps e Wi-Fi 6E integrato (802.11ax), mentre tra le varie funzionalità esclusive non ritroveremo più il supporto alle soluzioni Intel Optane Memory, basate su tecnologia di memoria 3D XPoint, la cui divisione è in dismissione da parte dell’azienda di Santa Clara.
Nel diagramma che segue vi mostriamo la struttura del nuovo modello di punta della linea, per l’appunto lo Z790 Express:
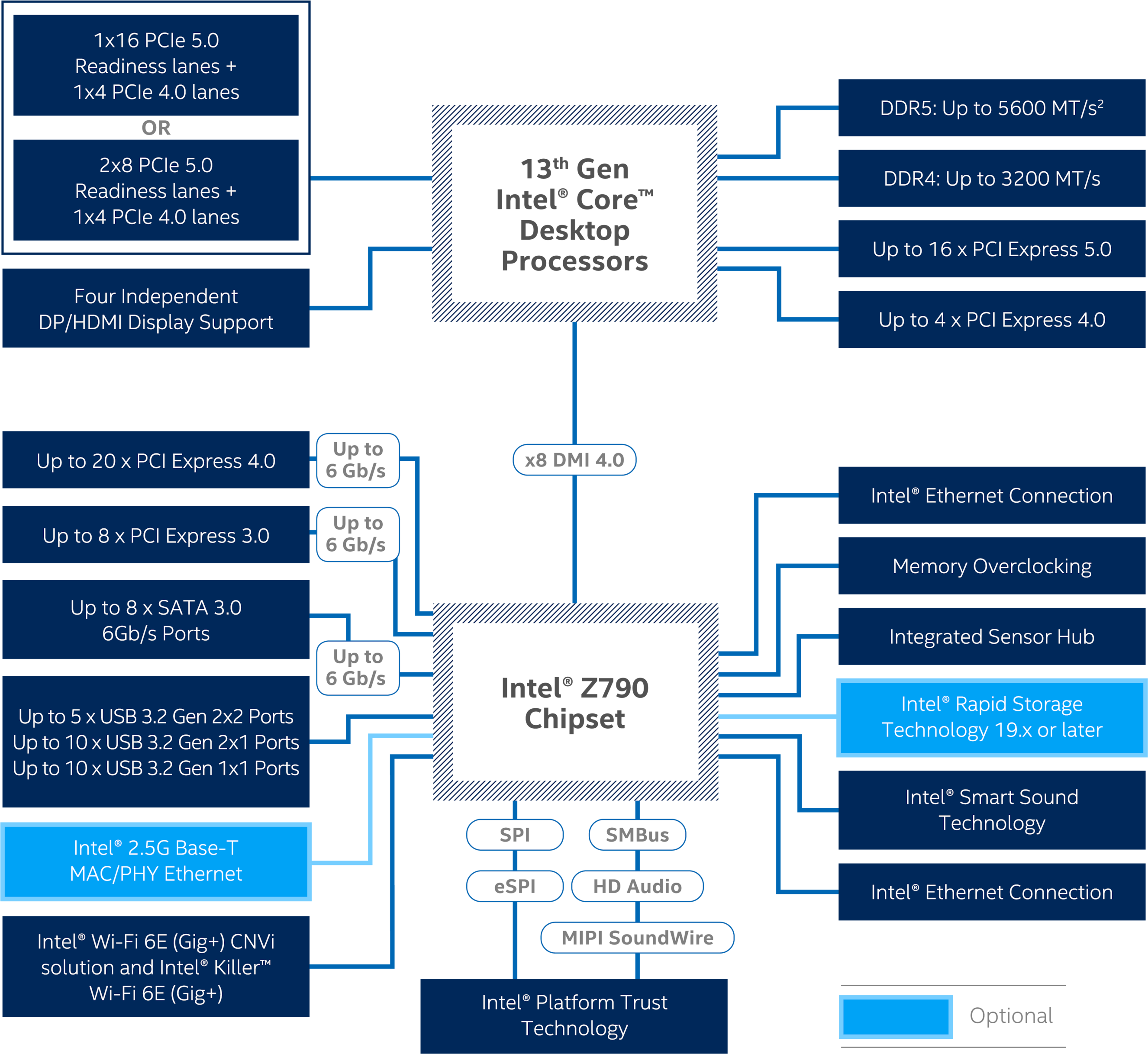
Come vediamo dal diagramma della nuova piattaforma, i microprocessori Raptor Lake-S di tredicesima generazione mantengono un Memory Controller Integrato (IMC) di tipo Dual Channel, con il pieno supporto verso i nuovissimi moduli di memoria ad elevate prestazioni DDR5. Il supporto verso i “vecchi” moduli di memoria DDR4 viene conservato, ma non troveremo schede madri in grado di ospitare entrambe le tipologie di memoria, o l’una o l’altra. Sarà quindi necessario prestare attenzione durante la scelta della scheda madre, leggendo con attenzione la tipologia di memoria supportata. Nel caso delle DDR4 la massima velocità di trasferimento certificata si mantiene a quota 3.200MT/s, assicurando una bandwith massima teorica pari a 51.2GB/s, mentre per le nuove soluzioni DDR5 è prevista la certificazione per una velocità massima che raggiunge i 5.600MT/s (contro i 4.800MT/s delle soluzioni della passata generazione), corrispondenti ad una bandwidth di ben 89.6GB/s.
Nessuna novità per quanto riguarda il Controller PCI-Express integrato nel microprocessore, sempre in grado di gestire un massimo di 20 linee PCI-Express, 16 delle quali conformi al nuovo standard Gen 5.0, e quindi capaci di assicurare una banda doppia rispetto alla precedente generazione (32GT/s contro 16GT/s). Sarà quindi possibile, qualora la propria scheda madre preveda degli slot necessari, realizzare sistemi Multi-GPU (NVIDIA SLI o AMD CrossFireX) in configurazione x8/x8, oppure installare un eventuale futura unità allo stato solido ad elevate prestazioni compatibile.
Il PCH è sempre collegato al microprocessore per mezzo di un Link DMI (Direct Media Interface) che si occupa di fungere da bridge fra la CPU stessa e i vari controller integrati e non. Con il nuovo DMI 4.0 vengono sfruttate ben otto linee PCI-Express 3.0 al fine di incrementare ulteriormente l’efficienza eliminando qualsiasi collo di bottiglia grazie ad una banda pari a ben 16GT/s.
Oltre a quanto detto, il nuovo Intel Z790 Chipset, include un sottosistema Audio High Definition, un’interfaccia di rete Gigabit e niente meno che ulteriori 28 linee PCI-Express, di cui 8 di tipo Gen 3.0 e 20 di tipo Gen 4.0 (rispettivamente troviamo quattro linee Gen 3.0 in meno e quattro linee Gen 4.0 in più rispetto al predecessore Z690 Express), la cui gestione è completa discrezione del produttore della scheda madre. Appare innegabile una flessibilità indubbiamente maggiore rispetto al passato e sarà di conseguenza del tutto lecito attendersi soluzioni provviste di molteplici interfacce di collegamento M.2 PCI-Express oppure SATA Express, anche in configurazione mista, a supporto delle più prestanti unità di SSD di nuova generazione presenti sul mercato.

La gestione delle connessioni video (ora fino a quattro display indipendenti) è ancora completamente a carico del microprocessore e non più del PCH stesso come avveniva nei modelli precedenti alla serie 9. Mantenuto il pieno supporto non soltanto alla risoluzione 4K UHD, ma anche all’HDR (High Dynamic Range) ed alla profondità colore a 10bit.
Al pari dei precedenti modelli anche i nuovi PCH della Serie 700 sono in grado di garantire il supporto nativo verso lo standard Thunderbolt 4 tramite connessione USB Type-C, vantando la piena compatibilità verso tutte le specifiche del protocollo USB4. Rispetto alla passata generazione non viene incrementata la velocità di trasferimento (come al contrario avvenuto dalla seconda alla terza generazione), restando ancorati a quota 40Gb/s, ma verrà potenziato l’intero ecosistema, offrendo per la prima volta dock provvisti di ben quattro porte Thunderbolt e definendo uno standard universale per quanto riguarda il cavo, per il quale è prevista una lunghezza massima di 2 metri. Ricordiamo che lo standard Thunderbolt consente, tramite una singola connessione USB Type-C, il passaggio di dati, video e alimentazione.
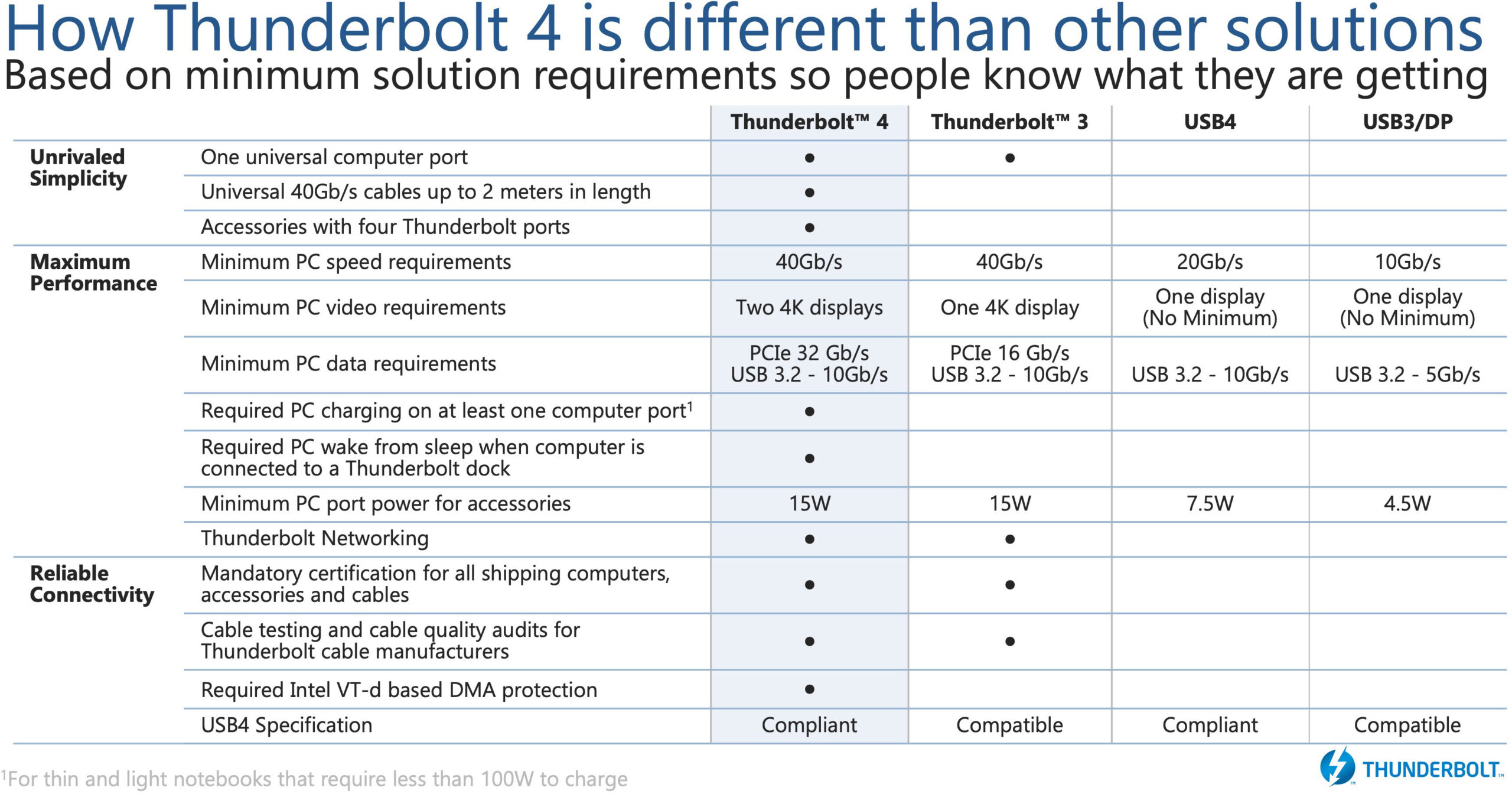
Specifiche del genere appaiono più che sufficienti per gestire, ad esempio, una soluzione grafica discreta esterna (molto in voga in ambito mobile, al fine di espandere le potenzialità del comparto grafico integrato) oppure una coppia di monitor con pannelli 4K a 60Hz. Valori di tutto rispetto anche sotto il profilo energetico, con possibilità di alimentare periferiche esterne fino a ben 100W di potenza, includendo funzionalità di ricarica veloce.

Concludiamo con l’ultima, ma non meno importante, caratteristica confermata anche in questi nuovi PCH. Ci riferiamo alla tecnologia di protezione Intel Device Protection with Boot Guard, pensata per garantire la massima protezione durante la fase di avvio del sistema.
[nextpage title=”Sistema di Prova e Metodologia di Test”]
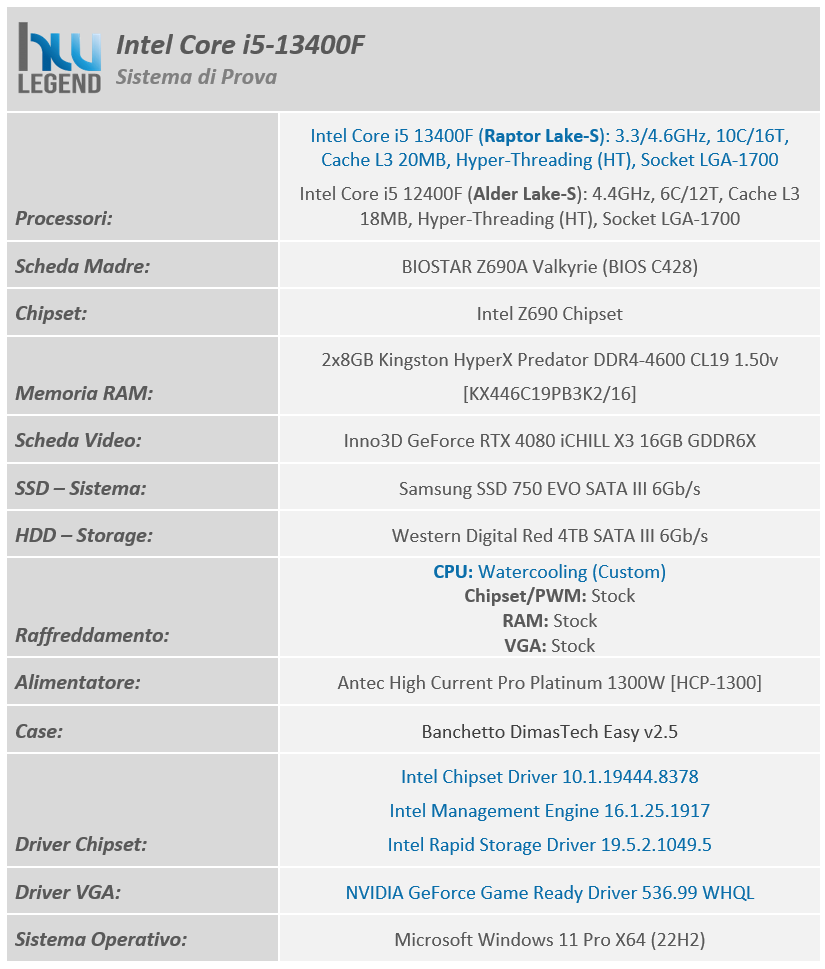
Le nostre prove sono state condotte con l’obiettivo di analizzare le performance velocistiche del nuovo microprocessore Core i5-13400F, recentemente presentato da Intel e dalla stessa gentilmente fornitoci, ponendolo a diretto confronto con il modello della passata generazione che va di fatto a sostituire, ovvero il Core i5-12400F. La scheda madre utilizzata è la nuova BIOSTAR Z790 Valkyrie.
Tutti i test eseguiti sono stati ripetuti per ben tre volte, al fine di verificare la veridicità dei risultati. L’hardware è stato montato su di un banchetto di produzione DimasTech.
Nella tabella che segue vi mostriamo i dettagli del sistema di prova utilizzato:
Per meglio osservare le potenzialità offerte dall’attuale nuovo microprocessore di fascia media di classe Core i5 abbiamo condotto le nostre prove basandoci su due differenti livelli d’impostazione, preventivamente testati al fine di non incorrere in problemi causati dall’instabilità:
- Default: Intel Core i5 13400F (Default) / Turbo Boost Abilitato / RAM 1.600MHz (3.200MT/s) 14-14-14-34-1T – Gear1/IMC:MCLK (1:1) 1.600MHz;
Per questo profilo ci siamo mantenuti fedeli alle specifiche di riferimento di Intel per quanto riguarda il microprocessore e i principali parametri operativi (Memoria RAM e tensioni di alimentazione). Di conseguenza abbiamo lasciato attiva la tecnologia proprietaria Turbo Boost, fissato i limiti di potenza ai valori previsti dall’azienda (PL1=65W/PL2=148W) e rispettato quella che è la massima frequenza certificata per il comparto di memoria DDR4 in abbinamento ad un microprocessore Raptor Lake-S e a moduli Single Rank in configurazione 1 DPC (singolo modulo per canale) su scheda madre 2 SPC (due slot per canale), ovvero 1.600MHz (3.200MT/s).
- OC-Daily: Intel Core i5 13400F (Default) / Turbo Boost Abilitato / RAM 2.300MHz (4.600MT/s) 19-26-26-45-1T – Gear2/IMC:MCLK (1:2) 1.150MHz.
Al contrario del precedente livello d’impostazione, il nostro profilo “OC Daily” prevede un’oveclocking di tipo manuale, nello specifico però fondamentalmente limitato al comparto di memoria. Il microprocessore in esame, infatti, non prevede alcuna possibilità di intervento manuale di quelli che sono i principali parametri utili allo scopo. L’unica via per aumentare le frequenze di clock sarebbe quella di procedere con l’aumento del Base Clock (BCLK), dai canonici 100MHz predefiniti, ai 102.9MHz massimi concessi da Intel. Ma onestamente ci sentiamo di sconsigliare tale pratica, in quanto si potrebbe incorrere in instabilità per un guadagno, in termini prestazionali, del tutto esiguo.
Ci siamo quindi limitati a rimuovere i limiti di potenza (PL1/PL2) e a sfruttare al meglio il nostro comparto di memoria, che prevede moduli Kingston HyperX Predator DDR4 accreditati di una frequenza operativa di 2.300MHz (4.600MT/s), cosa per la quale non si è reso necessario mettere mano alla frequenza di Base Clock (BCLK) ma, al contrario, ci è semplicemente bastato impostare l’apposito moltiplicatore DRAM e attivare il profilo XMP previsto, mantenendosi in specifica.
Su questa piattaforma, tuttavia, ricordiamo che l’impostazione di una frequenza di clock del comparto di memoria tanto elevata, va modificare automaticamente quelli che sono i rapporti predefiniti tra IMC (Memory Controller Integrato) ed MCLK (Memory Clock), passando dalla normale ratio 1:1 (Gear 1) ad una ratio 1:2 (Gear 2). Questo comporta, di conseguenza, un dimezzamento della frequenza del controller di memoria stesso, che si ritroverà così ad operare in condizione asincrona rispetto ai moduli di memoria, aspetto che comporterà una leggera perdita prestazionale in alcuni particolari scenari, a causa dell’inevitabile aumento della latenza.
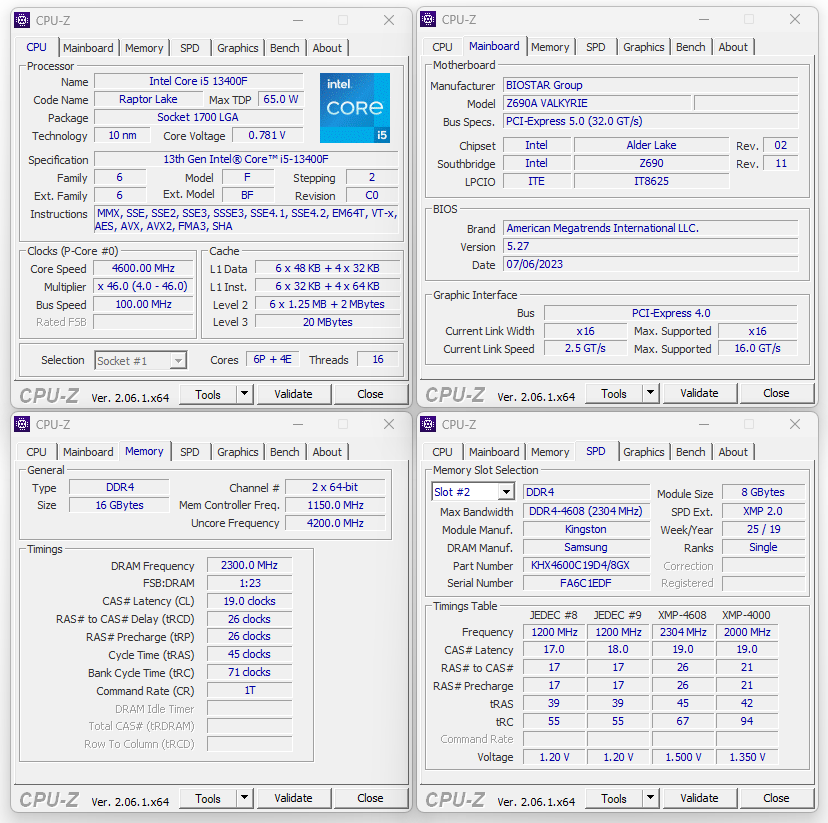
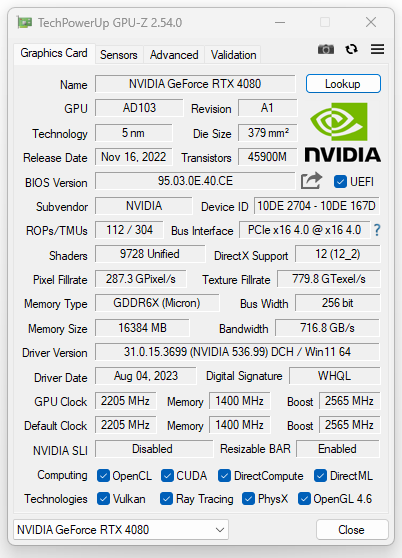
La scheda grafica utilizzata, una INNO3D GeForce RTX 4080 iCHILL X3, è stata mantenuta entro le specifiche previste dal produttore (2.205MHz/1.400MHz/2.565MHz). I driver utilizzati sono gli NVIDIA Game Ready 536.99, provvisti di certificazione WHQL.
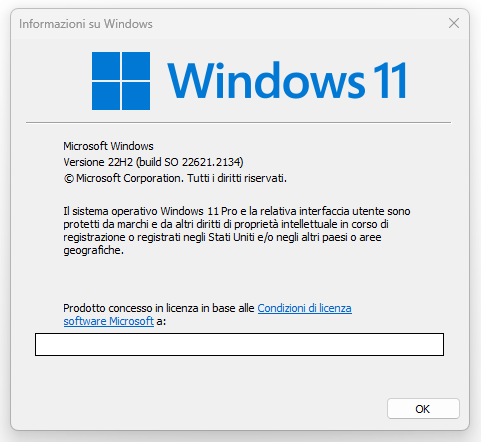
Il sistema operativo, Microsoft Windows 11 Pro X64, è da intendersi privo di qualsiasi ottimizzazione particolare, ma comprensivo di tutti gli aggiornamenti rilasciati fino al giorno della stesura di questo articolo (Versione 22H2 – build 22621.2134).
Queste le applicazioni interessate, suddivise in tre tipologie differenti:
Prestazioni Rendering e Calcolo
- Cinebench R15 64bit;
- Cinebench R20 64bit;
- Cinebench R23 64bit;
- POV Ray 3.7 64bit;
- V-Ray Benchmark 5.02.00 64bit;
- Indigo Benchmark 4.4.15 64bit;
- Corona Benchmark 10 64bit;
- Blender 3.6.1 64bit;
- Geekbench Pro 6.1.0;
- Euler3D Benchmark v2.2;
- Fritz Chess Benchmark v4.3;
- SiSoftware Sandra Lite (31.133);
- AIDA64 Extreme 6.90.6500.
Prestazioni Multimedia, Web Browsing e Compressione
- Google Chrome 64bit;
- WinRAR 6.23 64bit;
- 7-Zip 23.01 64bit;
- VeraCrypt 1.25.9;
- HWBOT RealBench 2.44;
- HWBOT X265 Benchmark 2.3.0;
- UL 3DMark 11 Advanced Edition v1.0.179;
- UL 3DMark Advanced Edition v2.26.8125;
- UL PCMark 10 Professional Edition v2.1.2636 64bit;
- UL Procyon Professional Edition v2.6.848 64bit;
- Unigine2 Superposition Benchmark v1.1.
Prestazioni Giochi DirectX 11 / DirectX 12
- Assassin’s Creed Valhalla – DX12;
- Cyberpunk 2077 – DX12;
- F1 2022 – DX12;
- Shadow of the Tomb Raider – DX12;
- Watch Dogs: Legion – DX12.
Siamo pronti per osservare ed analizzare i risultati ottenuti.
[nextpage title=”Prestazioni Rendering e Calcolo”]
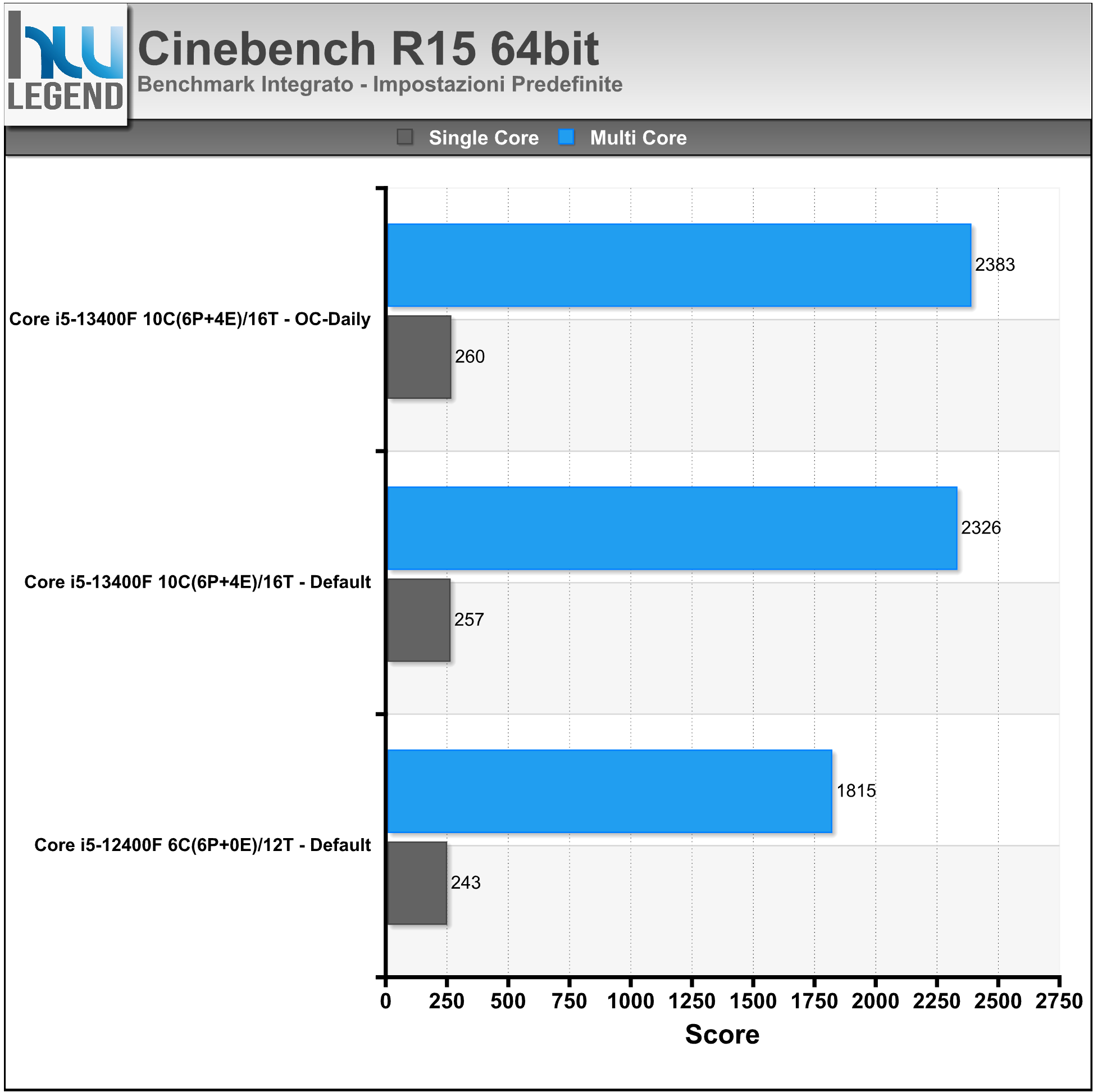
Cinebench R15, R20 e R23 sono una vera e propria suite di test multi piattaforma in grado di calcolare le capacità prestazionali del vostro computer. Il programma è basato sul software di animazione CINEMA 4D ed è lo strumento perfetto per valutare le performance della CPU e del comparto grafico su svariate piattaforme fra cui Windows e Mac OS X.
Cinebench sfrutta le potenzialità del processore centrale del sistema mediante l’utilizzo combinato di calcoli complessi finalizzati al completamento del rendering di un’immagine campione. È possibile eseguire il test in modalità “Single”, sfruttando un solo “core”, oppure “Multi”, sfruttando quindi tutti i “core” disponibili.
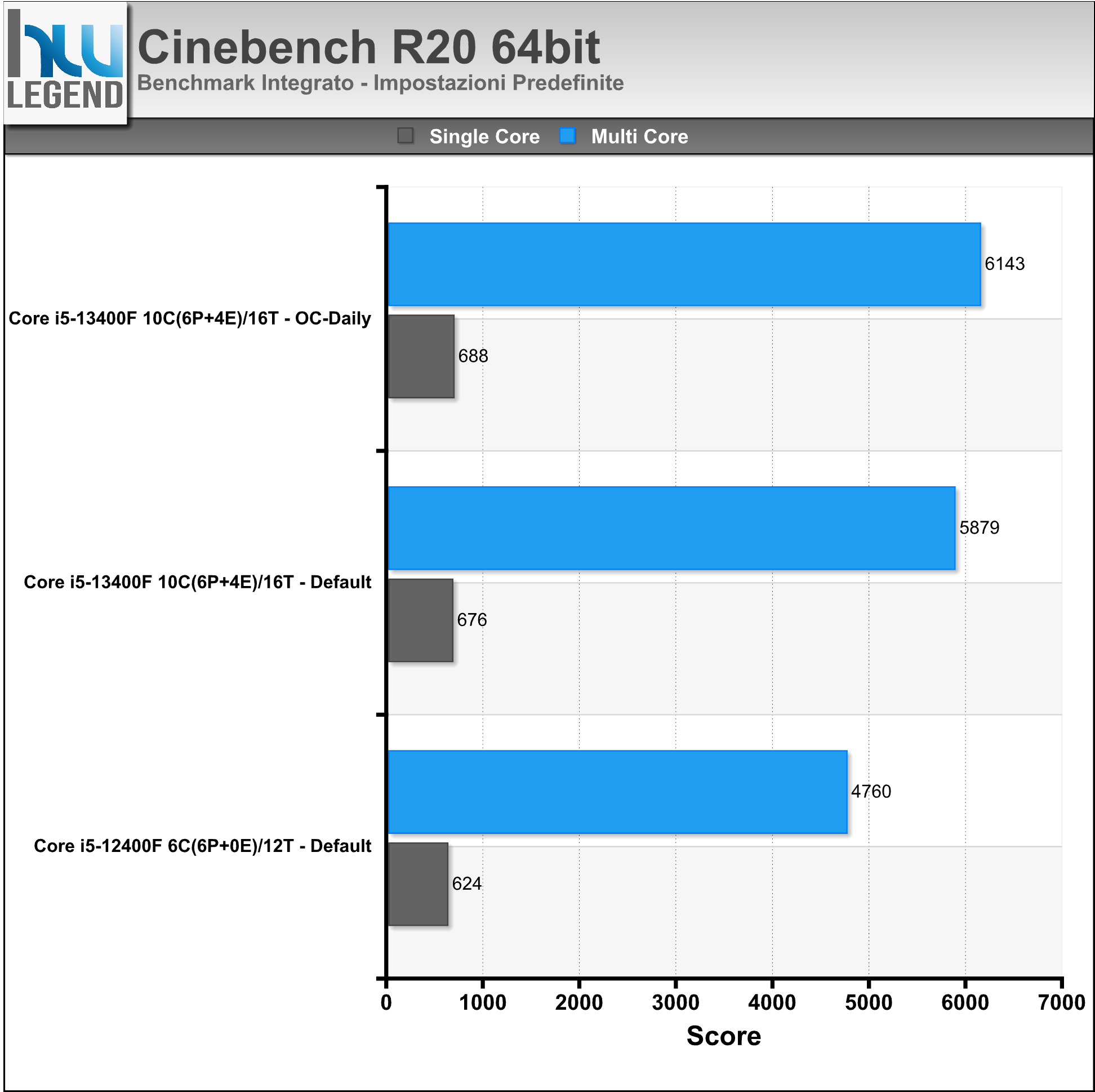
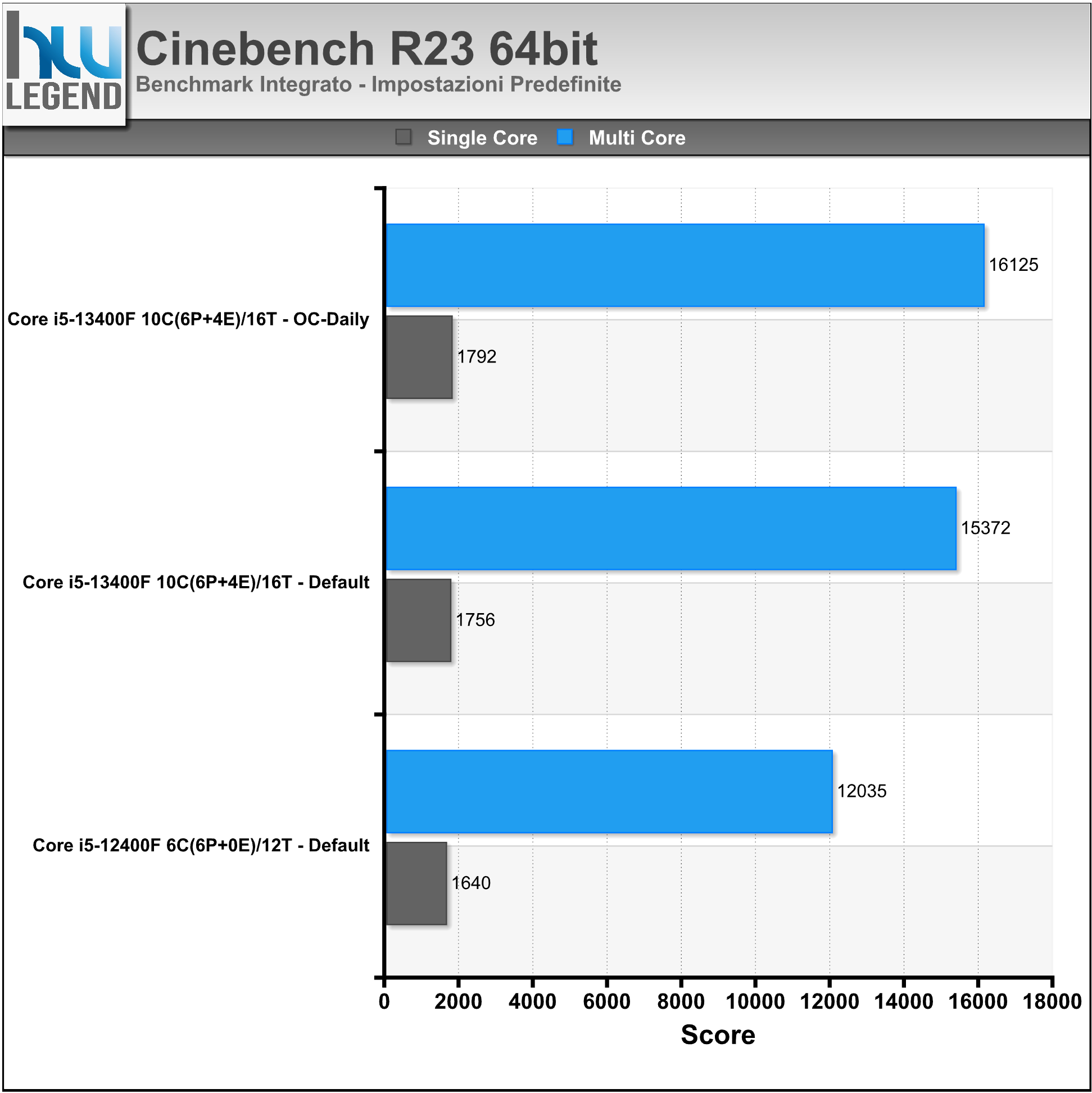
Riportiamo nei grafici il punteggio finale del rendering con 1Core/1Thread e fino a 10Core/16Thread.
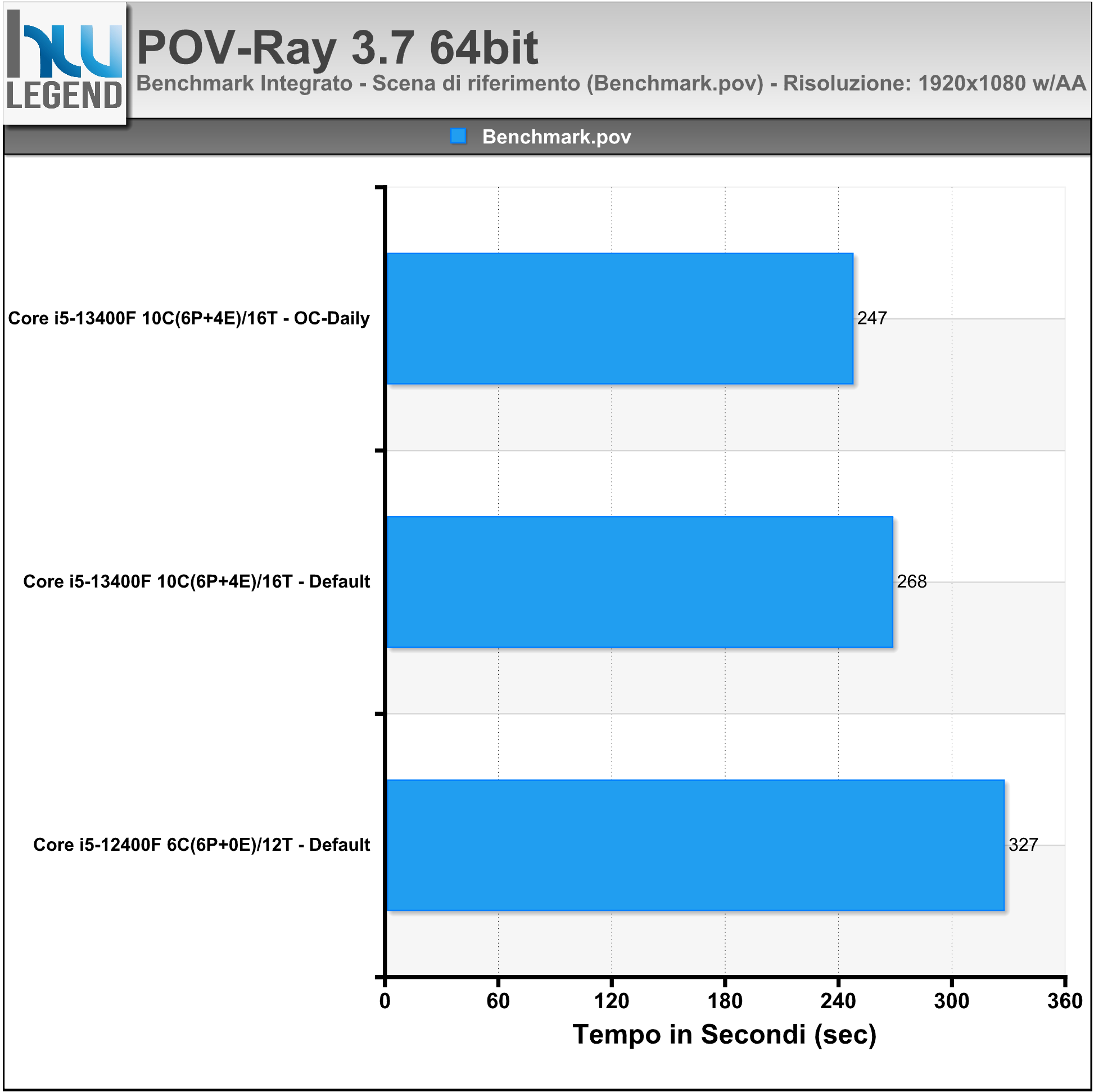
POV-Ray è un famosissimo programma per la creazione di immagini tridimensionali. Vanta un motore per RayTracing tra i più avanzati. Sarà possibile creare immagini 3D, geometriche e non, di tipo foto realistico e di altissima qualità. La costruzione dell’immagine si ottiene mediante un linguaggio di programmazione di tipo matematico basato sulla geometria analitica nello spazio.
Nel grafico il tempo (in Secondi) necessario per portare a termine il rendering della scena di riferimento “Benchmark.pov”, a risoluzione Full-HD (1920×1080) e filtro AA 0.3.
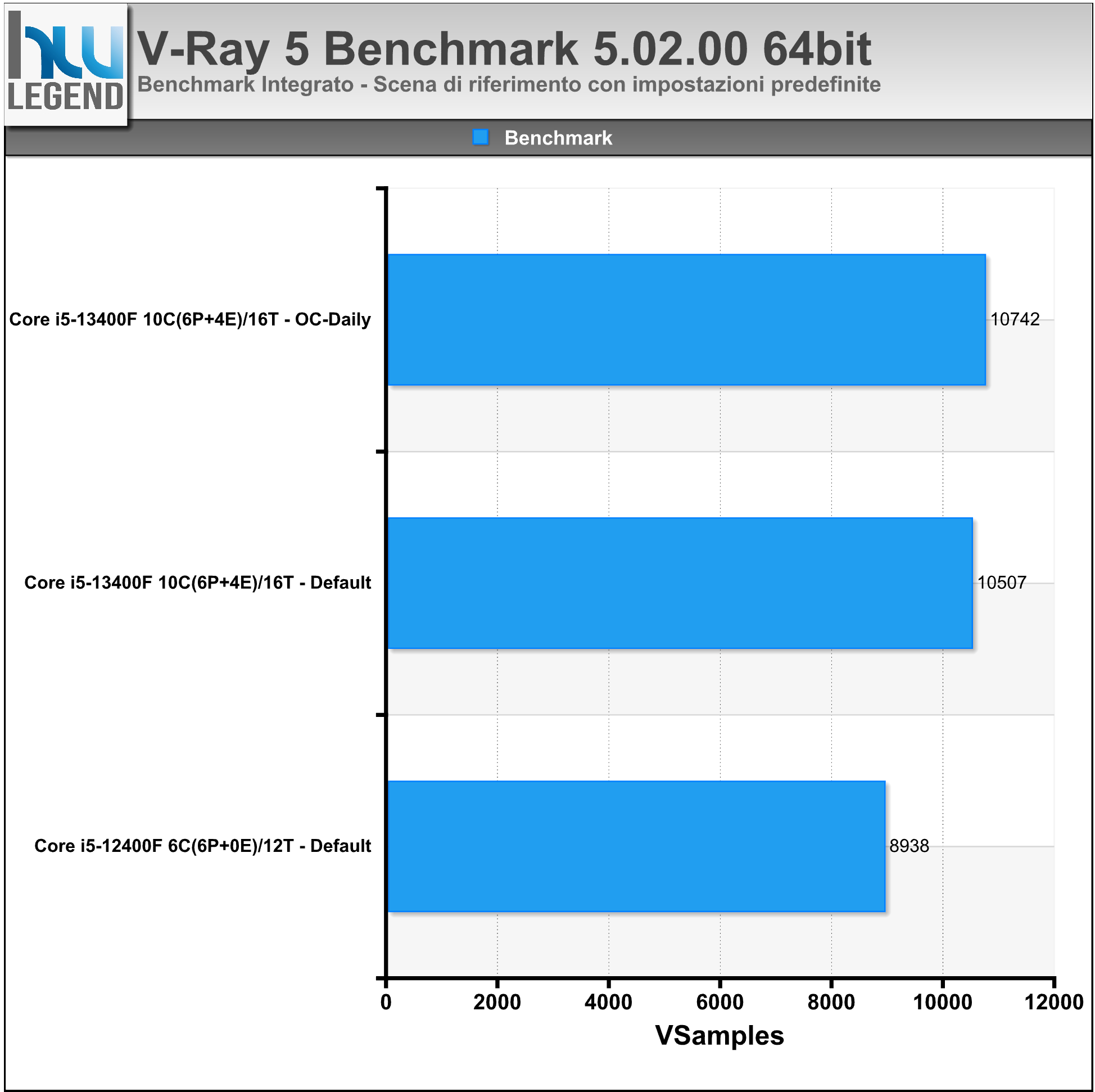
V-Ray Next Benchmark è un tool completamente gratuito per la misura delle performance velocistiche del proprio hardware nel rendering con V-Ray. È disponibile gratuitamente, previa registrazione su chaosgroup.com e verrà eseguito senza requisiti di licenza come applicazione autonoma. Il programma prevede la possibilità di eseguire rendering di raytrace sfruttando la CPU oppure la/e schede grafiche presenti. V-Ray è uno dei principali raytracers al mondo e viene utilizzato in molte industrie in fase di architettura e progettazione automobilistica. È stato utilizzato anche in oltre 150 immagini cinematografiche e numerose serie televisive episodiche. Ha inoltre vinto un premio Oscar per il conseguimento scientifico e tecnico nel 2017.
Nel grafico lo score finale (espresso in VSamples) ottenuto al termine del rendering della scena di riferimento, eseguito con impostazioni predefinite.
Indigo Bench è un’applicazione di benchmark standalone basata sul motore di rendering avanzato di Indigo 4, utile per misurare le prestazioni delle moderne CPU e GPU. Grazie all’utilizzo di OpenCL standard del settore, è supportata un’ampia varietà di GPU di NVIDIA, AMD e Intel. Il programma è completamente gratuito e può essere utilizzato senza una licenza Indigo su Windows, Mac e Linux.
Nel grafico lo score ottenuto in seguito al completamento del rendering di entrambe le scene di riferimento previste, eseguito con impostazioni predefinite.
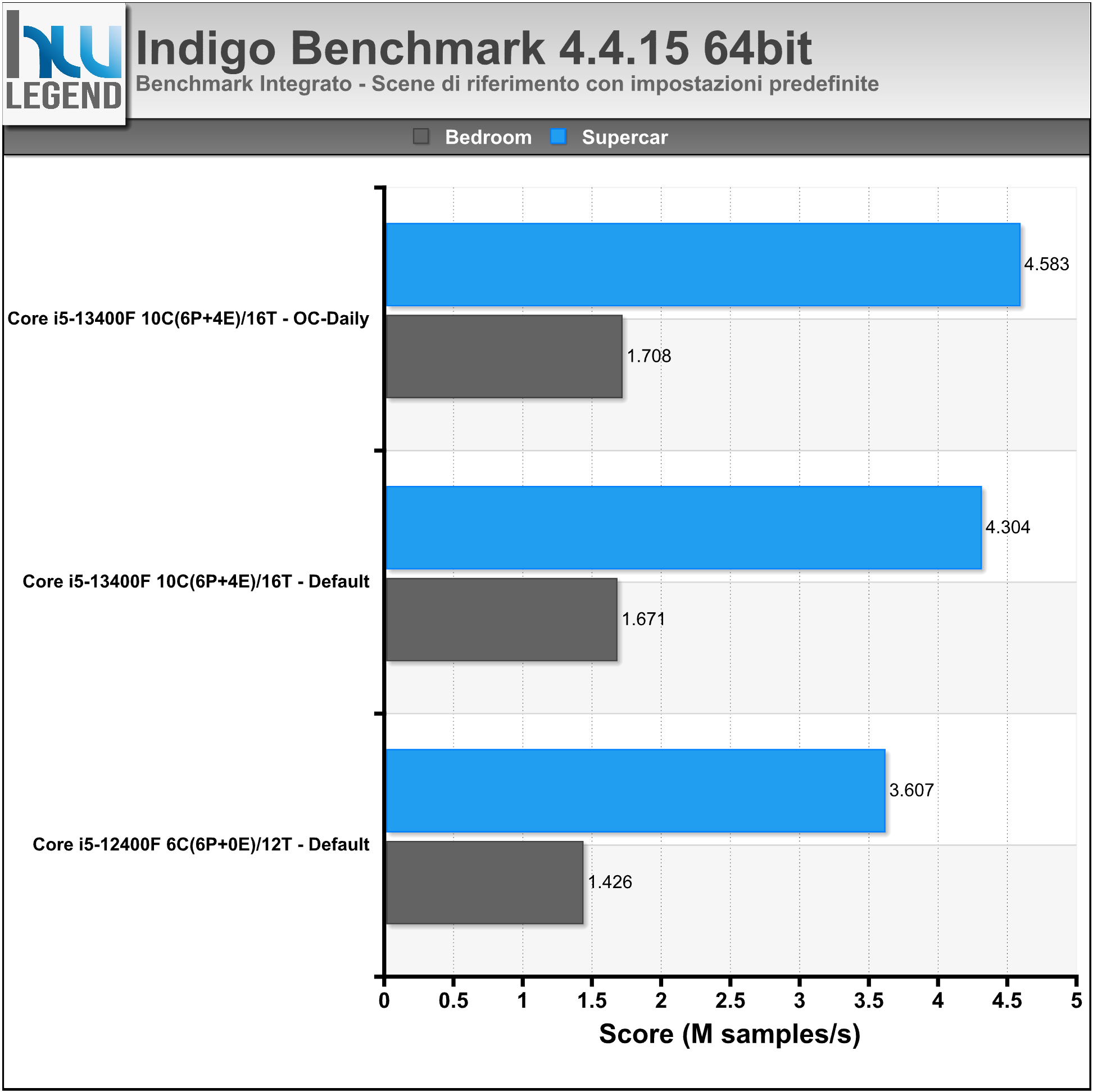
Chaos Corona 10 Benchmark è un tool completamente gratuito per la misura delle performance velocistiche del proprio microprocessore nel rendering fotorealistico di una scena di riferimento. Nonostante la sua giovane età, Corona è diventato un renderer pronto per la produzione ed in grado di creare risultati di qualità elevata.
Nel grafico lo score finale (espresso in Rays/sec) ottenuto al completamente dell’elaborazione, eseguita con impostazioni predefinite.
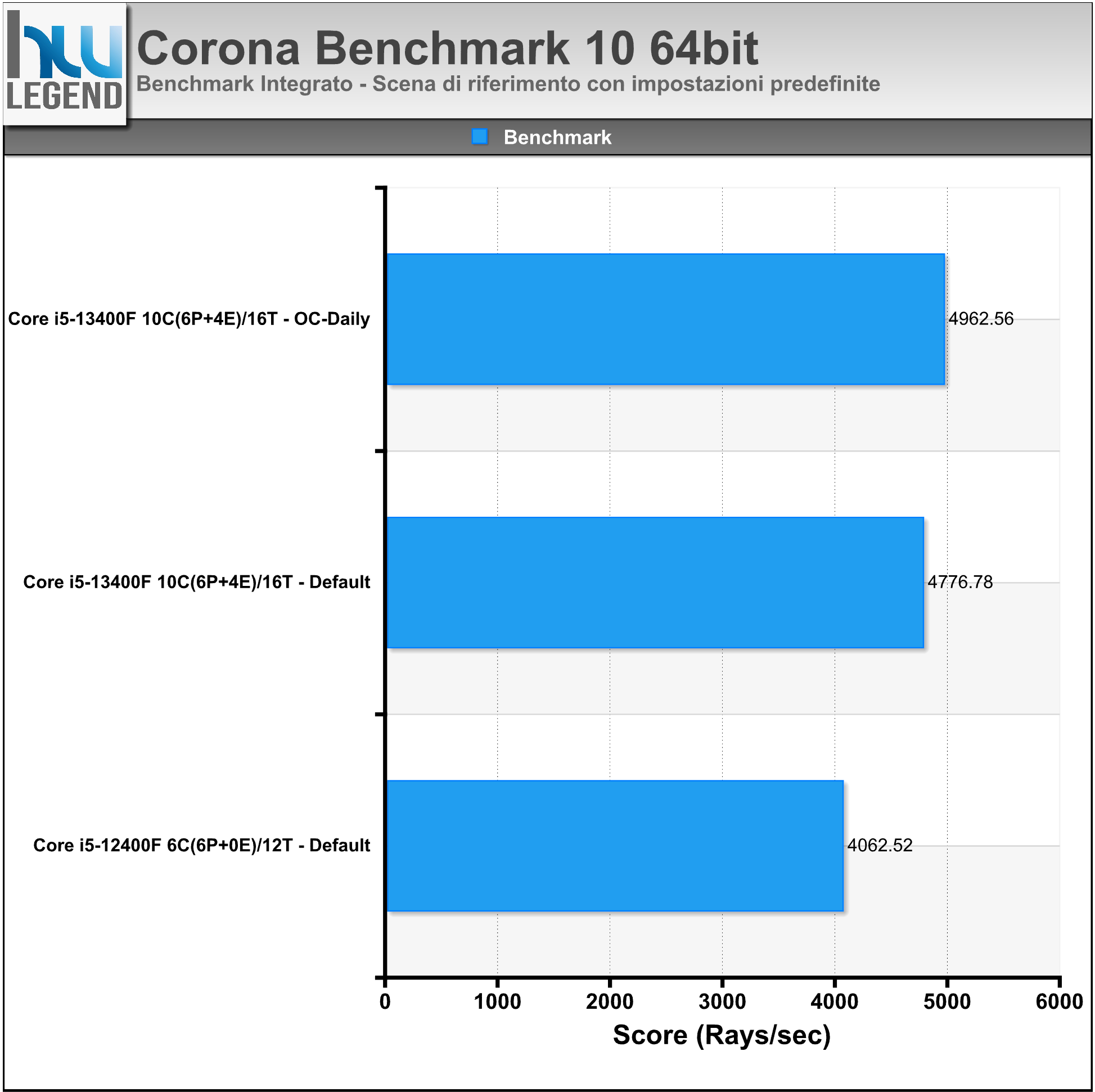
Blender è un famoso programma (completamente Open Source) di modellazione 3D, animazione e rendering. Viene spesso utilizzato anche per il calcolo delle performance dei microprocessori.
Nel grafico il tempo (in Secondi) necessario al rendering della scena di riferimento “BMW Benchmark”, eseguita con impostazioni predefinite.
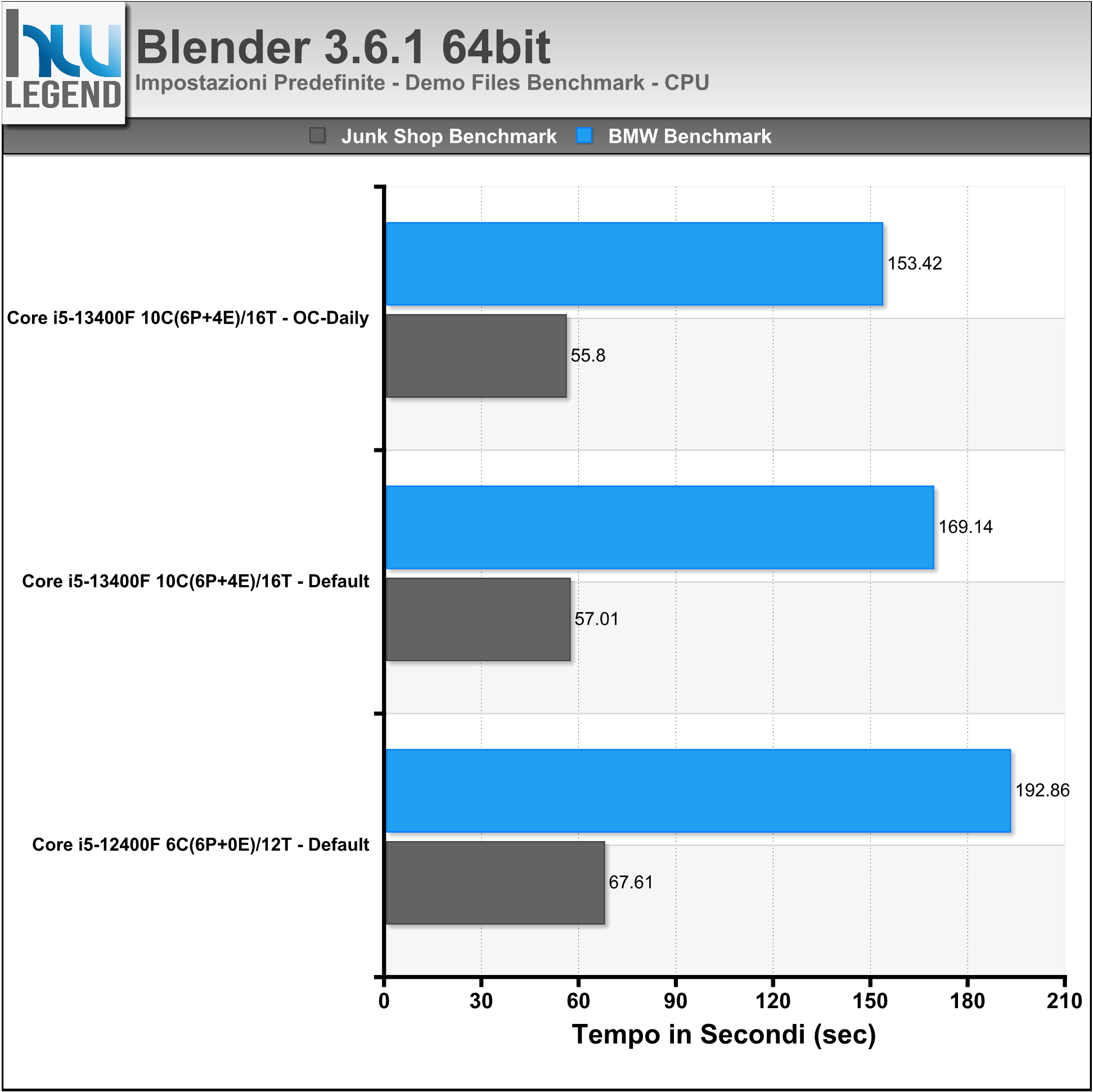
La più recente versione del software multi piattaforma messo a punto da Primate Labs, meglio noto come Geekbench, consente di misurare in maniera precisa ed affidabile le prestazioni della propria macchina, fornendo risultati facilmente comparabili grazie ad un completo database online. Il programma prevede carichi di lavoro in grado di simulare scenari tipici di utilizzo e, grazie al nuovo sistema di punteggio, mostra le performance single-core e multi-core in maniera separata.
Euler3D, basato sulla routine di analisi strutturale STARS Euler3D, è un software di benchmark che misura le prestazioni velocistiche del microprocessore mediante l’esecuzione di calcoli fluidodinamici. Il programma è ottimizzato per sfruttare appieno il multi-threading.
Nel grafico il risultato rilasciato al termine del test integrato, espresso in Hz.
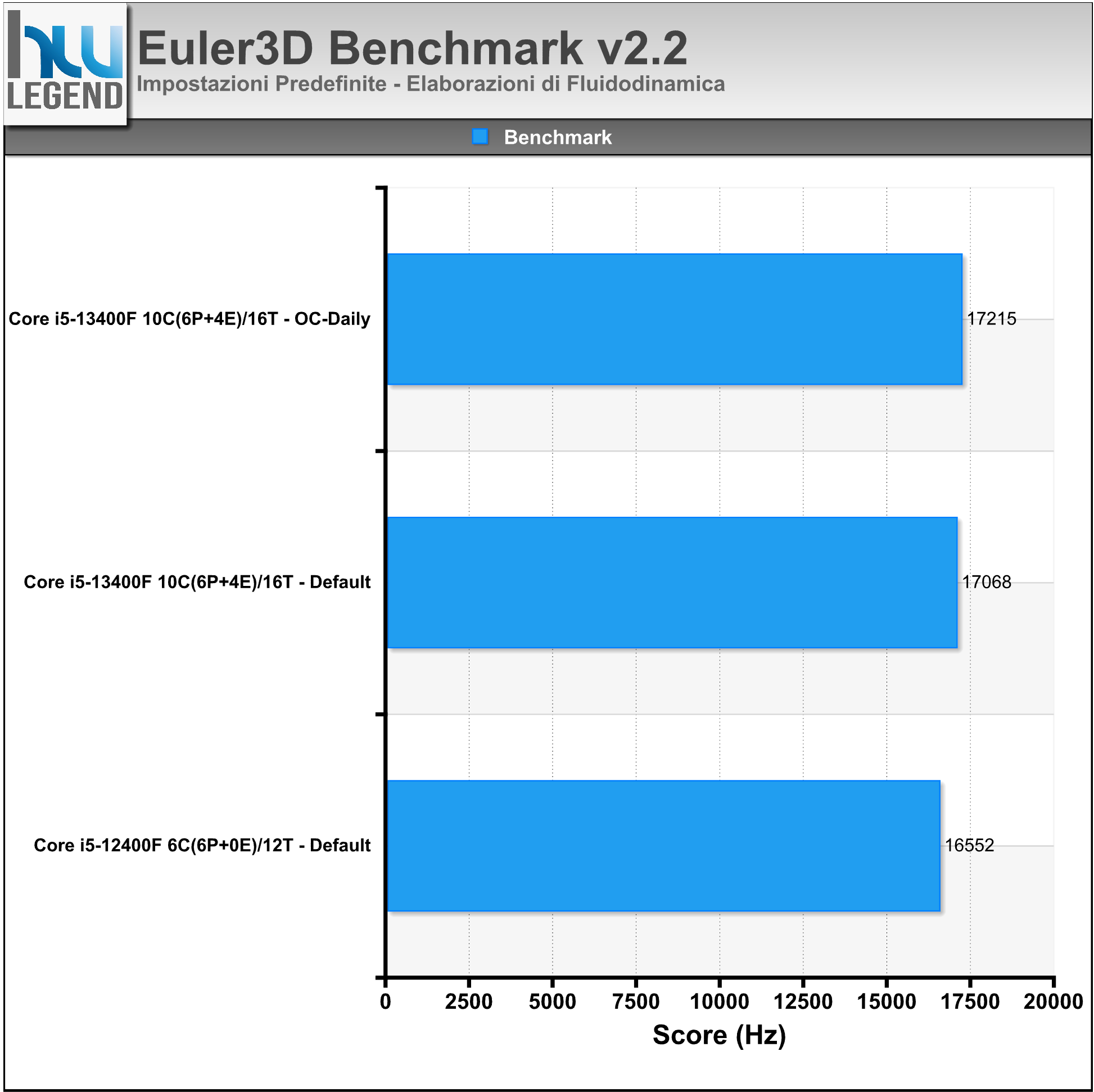
[nextpage title=”Prestazioni Rendering e Calcolo – Parte Prima”]
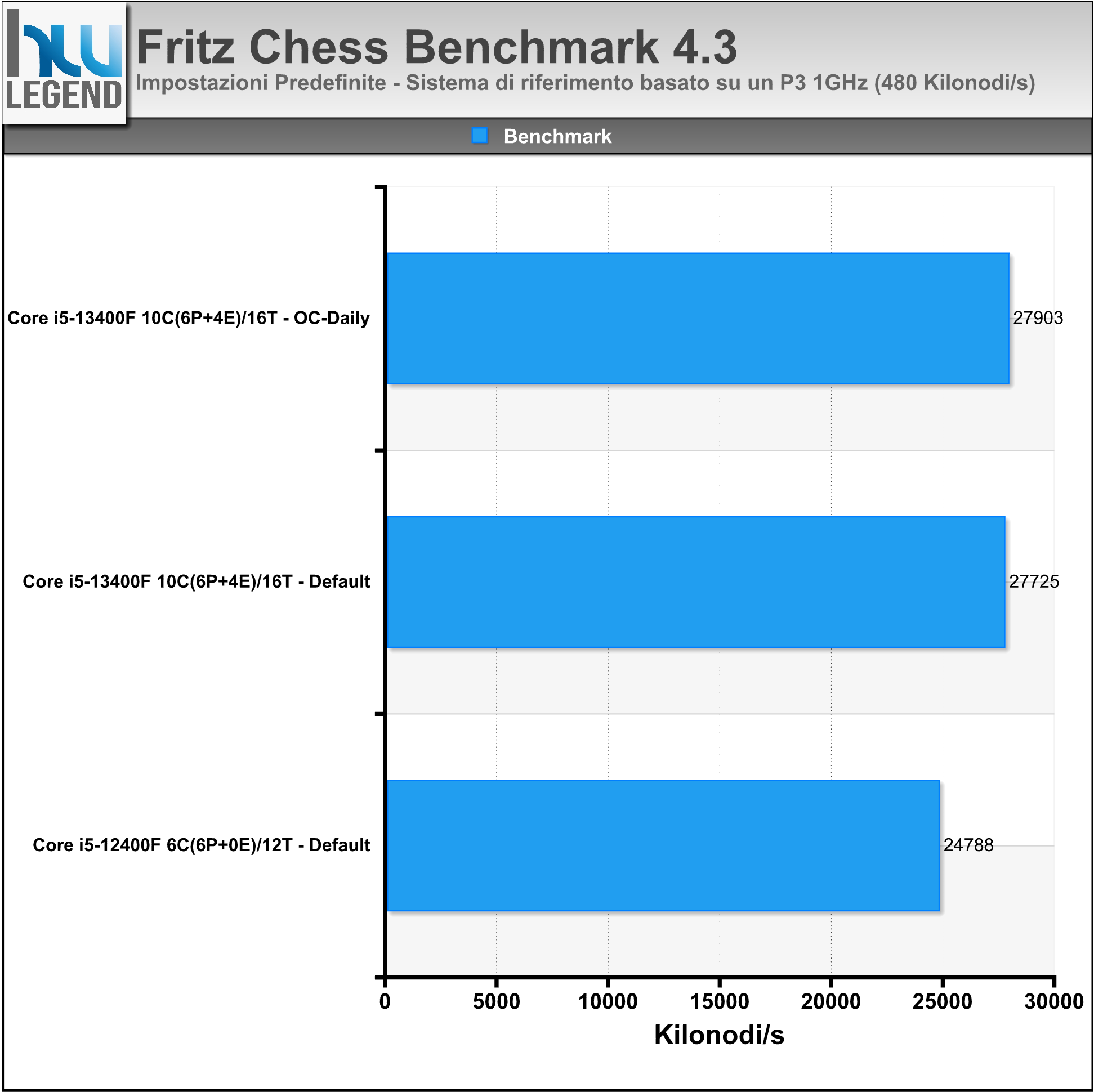
Fritz Chess è un interessante software che consente di misurare le performance della CPU basandosi sulla simulazione del gioco degli scacchi.
Il motore Fritz originale, sviluppato da Morsch-Feist e campione del mondo nel 1995, è stato impiegato fino alla release Fritz 13 (2012). Il programma è in grado di sfruttare appieno fino a otto core.
Nel grafico il risultato complessivo ottenuto (espresso in Kilonodi al secondo).
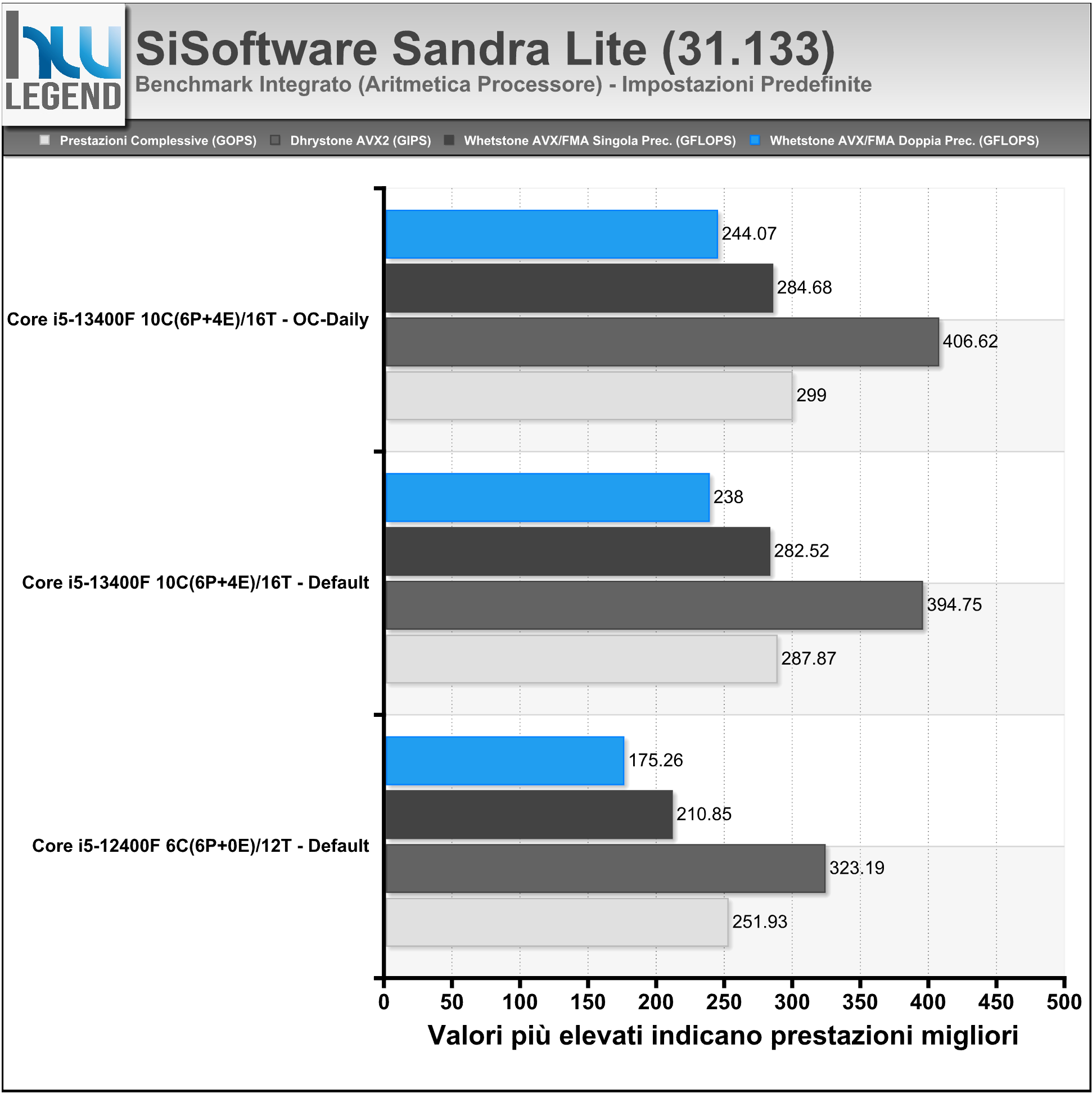
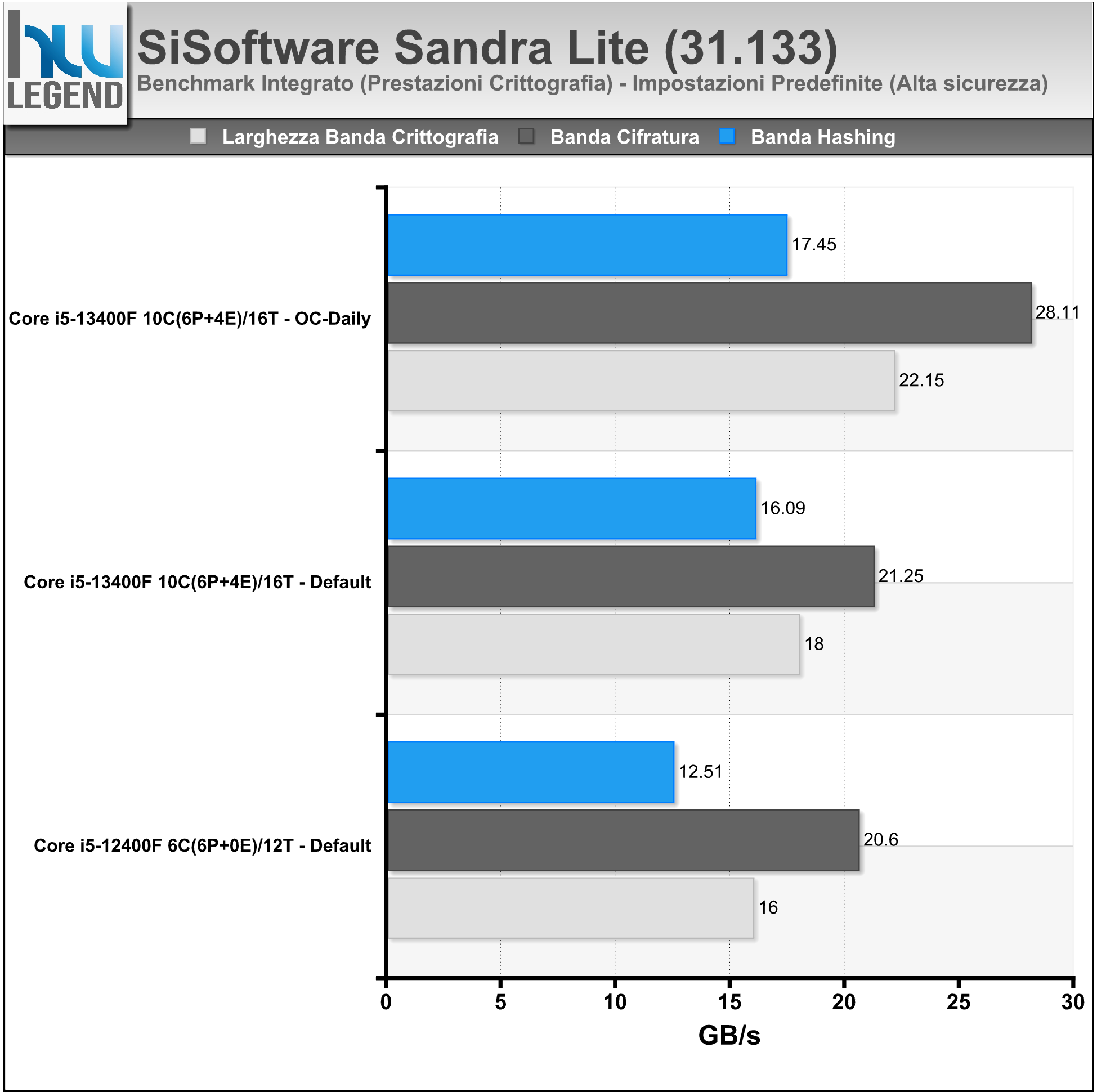
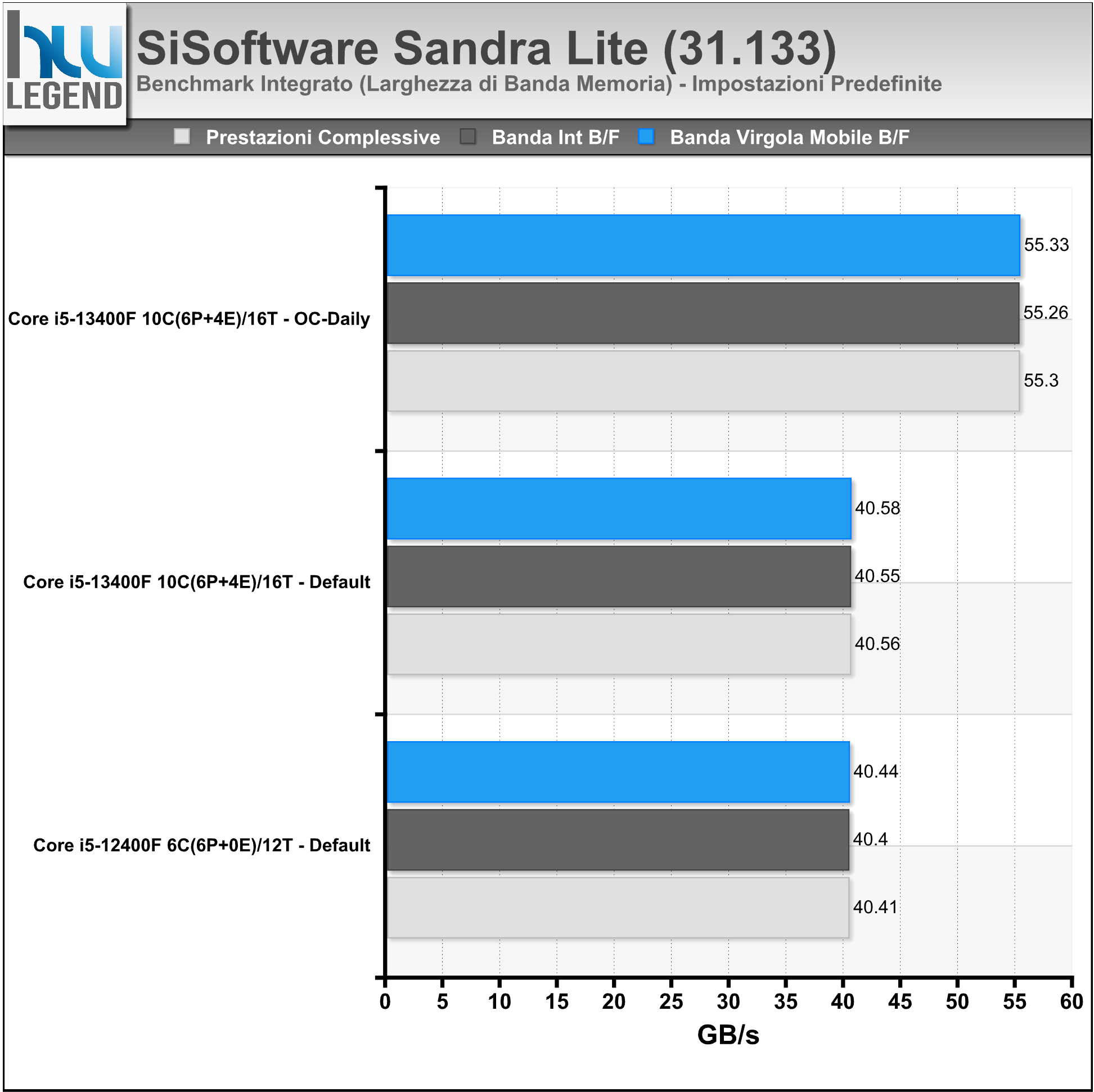
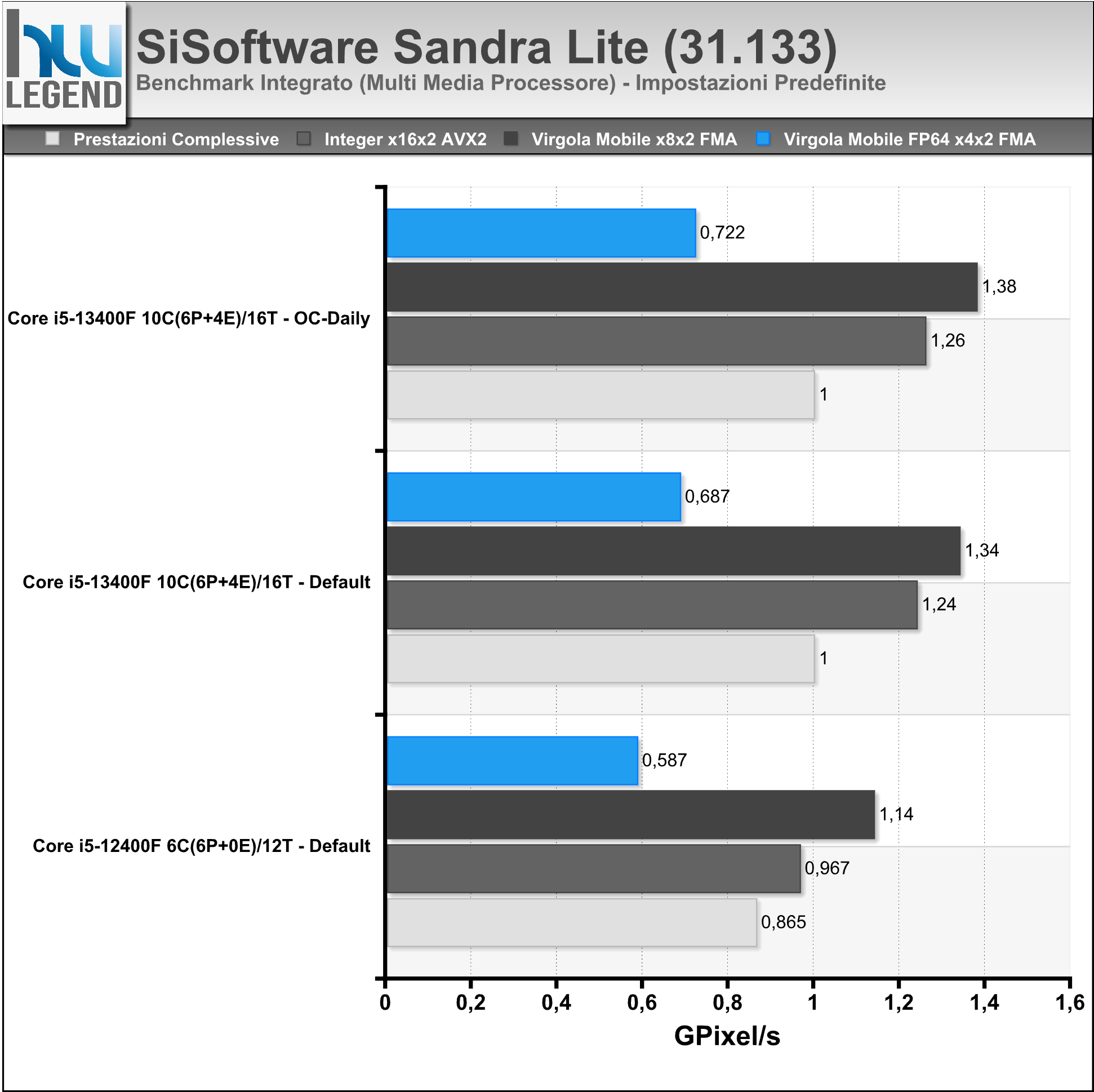
Sandra è un tool di benchmark per l’intero sistema PC, aggiornato per testare le ultime tecnologie disponibili sul mercato. Il software è in grado di assicurare la maggiore compatibilità hardware possibile unita ad un accurato reporting delle prestazioni e delle problematiche del sistema.
Abbiamo eseguito i principali test sulla CPU e sul comparto RAM, a seguire i risultati ottenuti.
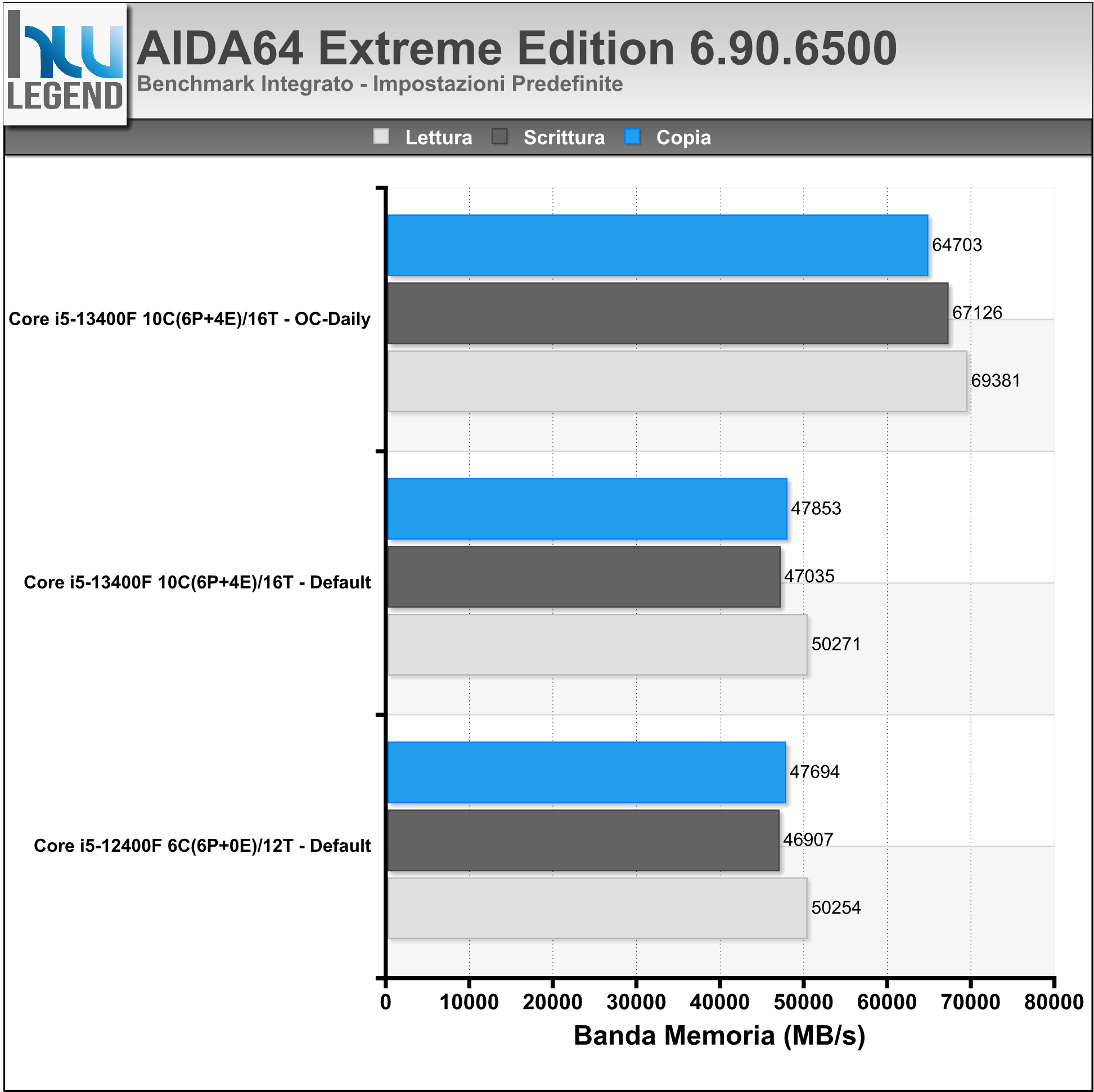
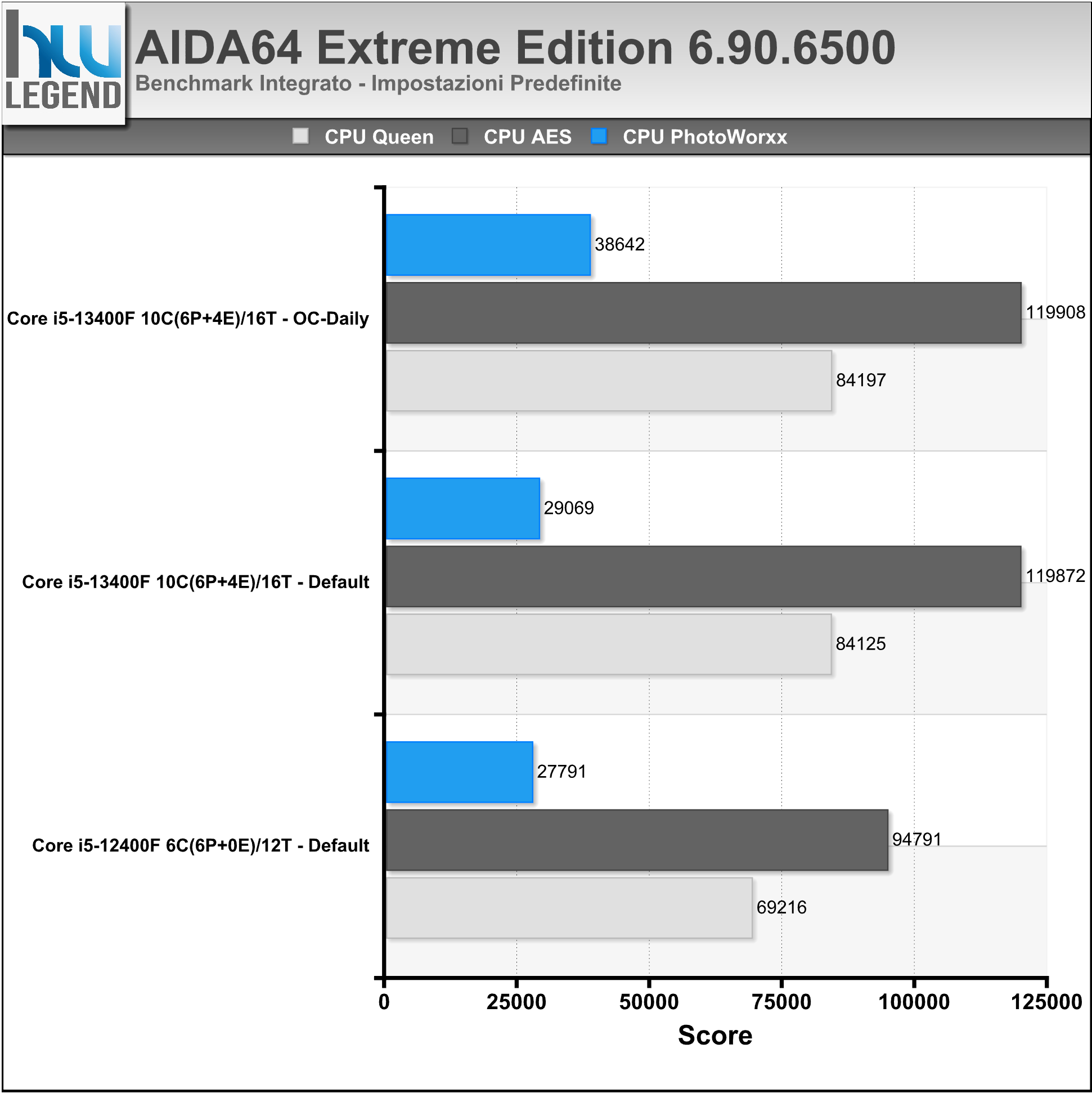
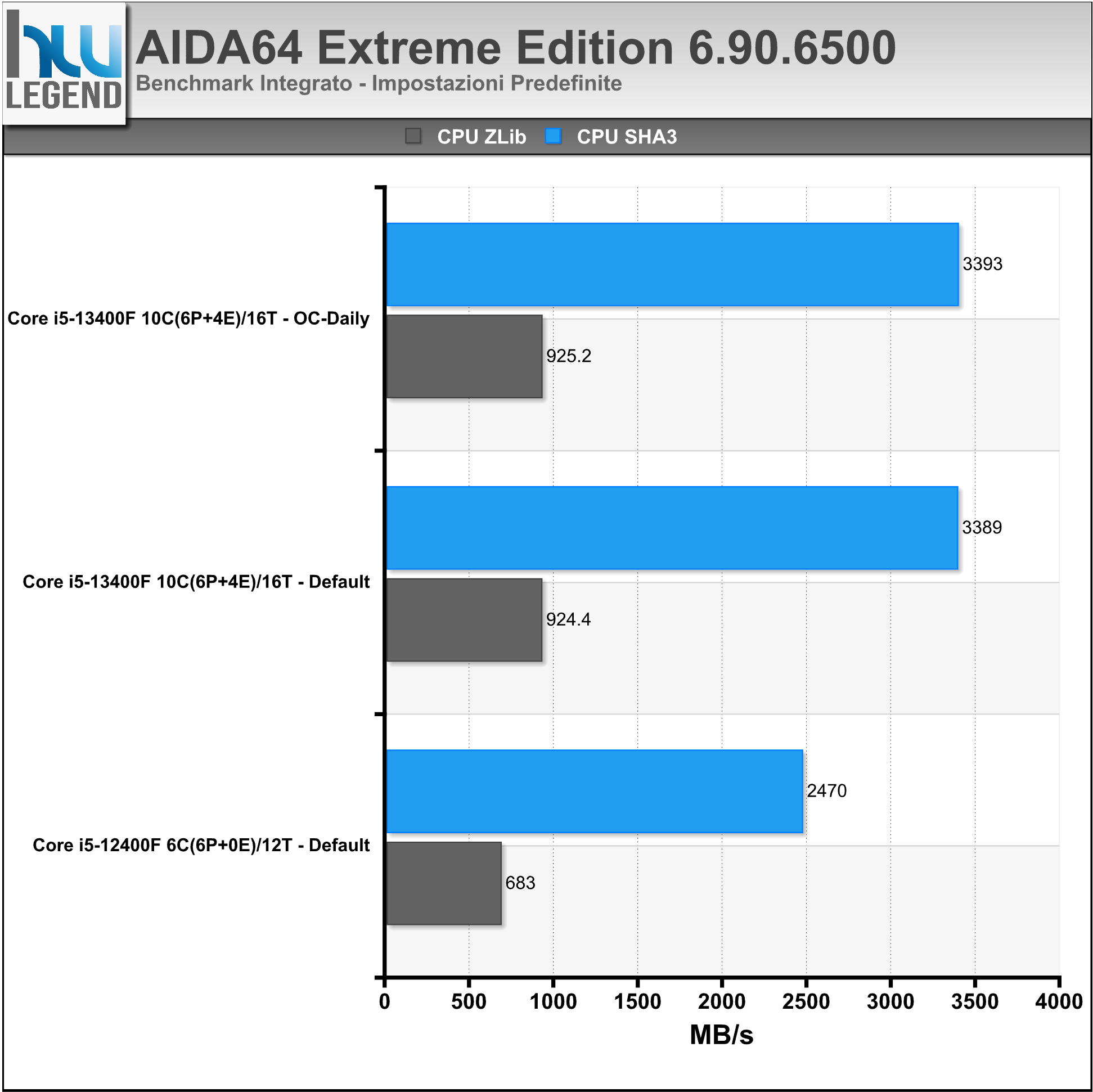
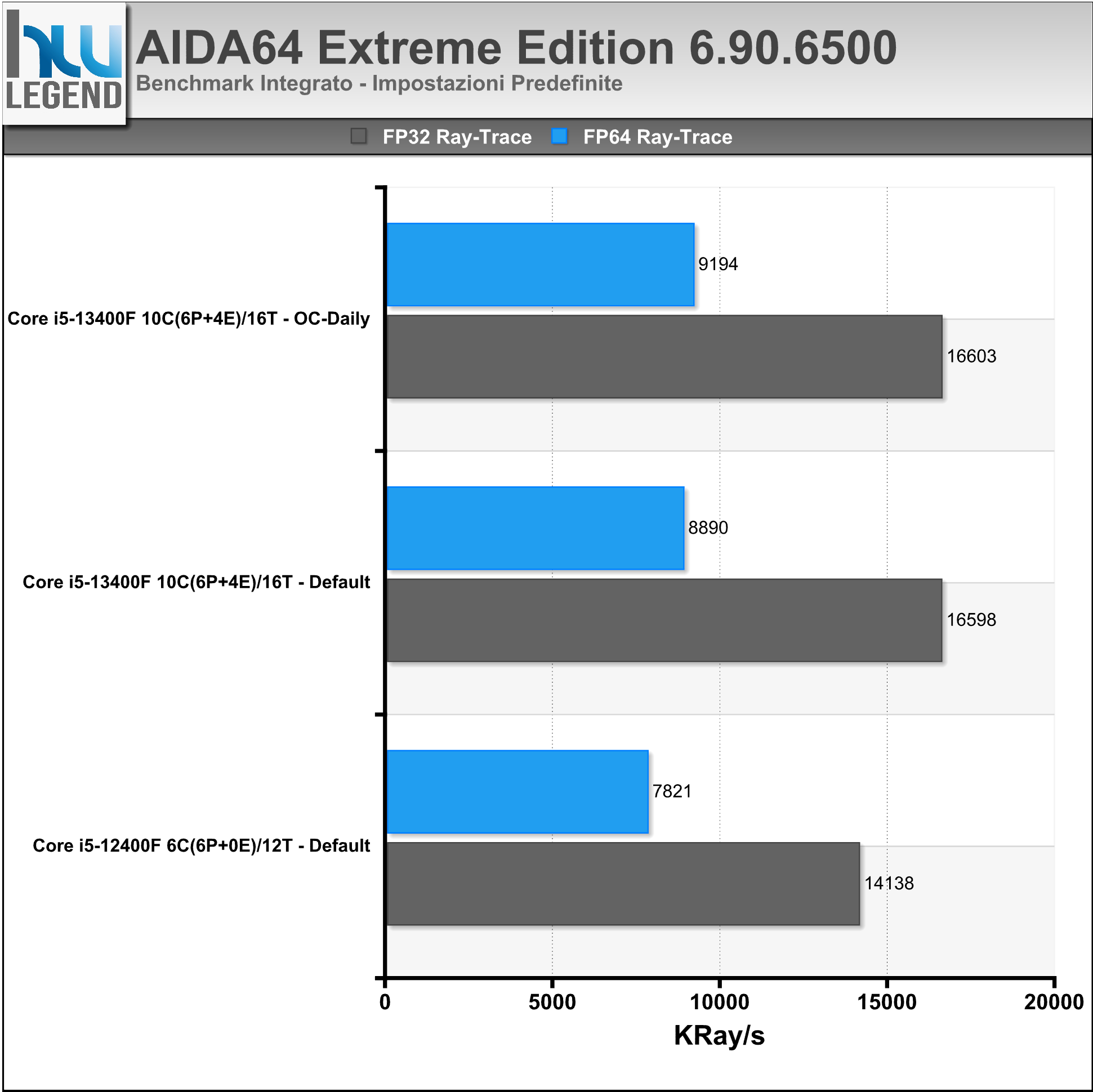
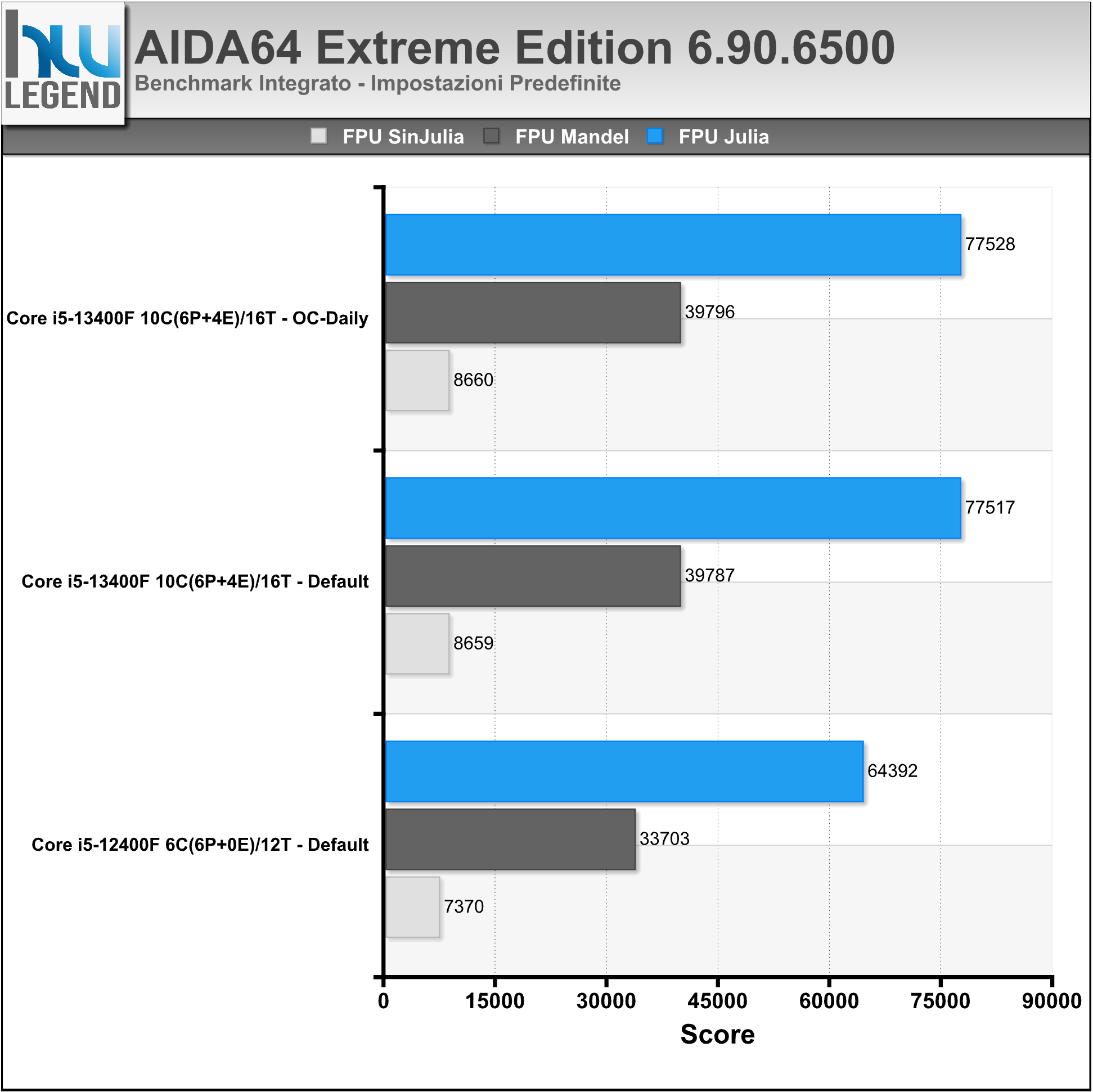
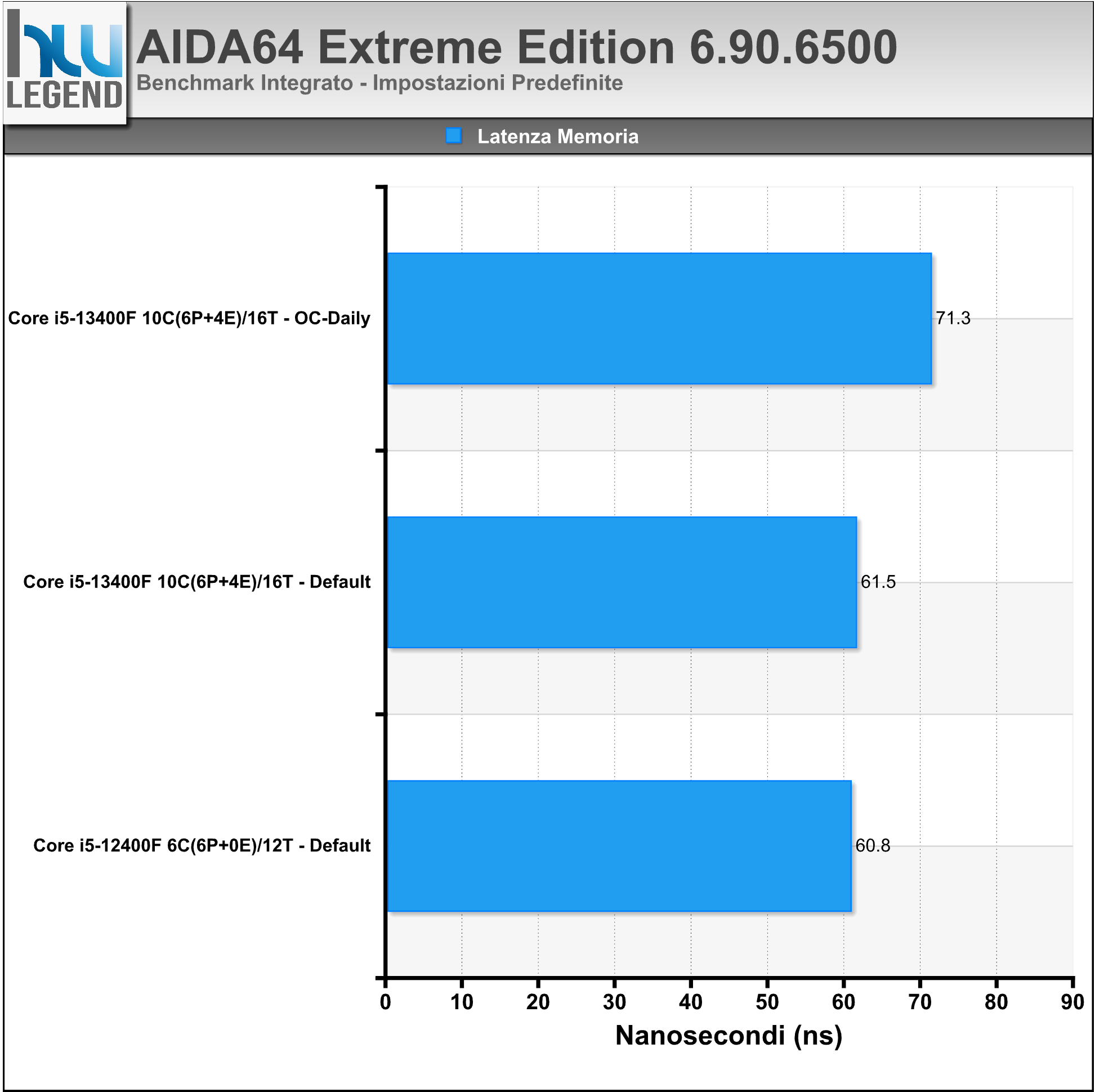
AIDA64 è un famoso programma che ci consente di tenere sotto controllo i punti vitali del nostro computer, quali temperature, voltaggi applicati e prestazioni. Al suo interno, infatti, troviamo numerosi test, utili per misurare, e comparare, le performance registrate dalle varie componenti (CPU, Memorie, HDD etc.).
Nei grafici i risultati riguardanti i benchmark integrati delle RAM e della CPU/FPU.
[nextpage title=”Prestazioni Multimedia, Web Browsing e Compressione”]
Google Chrome è senza dubbio il browser web più diffuso e completo in circolazione.
Dal momento che la navigazione sul web rappresenta lo scenario d’utilizzo principale del PC per la maggior parte dell’utenza abbiamo deciso di introdurre alcuni test specifici atti a misurare le performance in “web browsing” del proprio sistema. Per farlo ci siamo basati sui più diffusi web benchmark basati reperibili in rete, nello specifico:
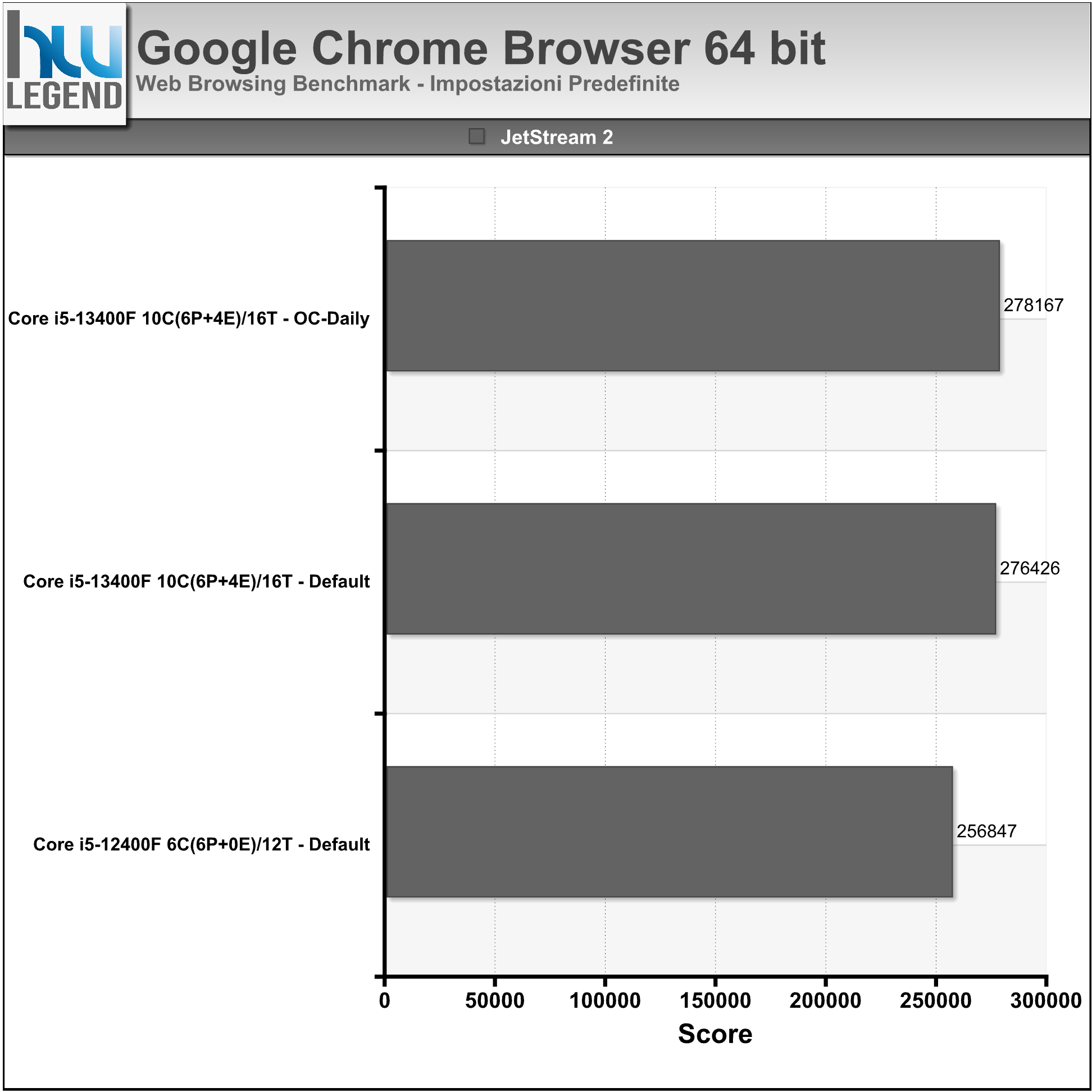
- JetStream 2: JetStream 2 è una suite che prevede una serie di avanzati benchmark in JavaScript e WebAssembly allo scopo di determinare le prestazioni del browser. Premia i browser che si avviano rapidamente, eseguono rapidamente il codice e funzionano stabilmente e senza problemi;
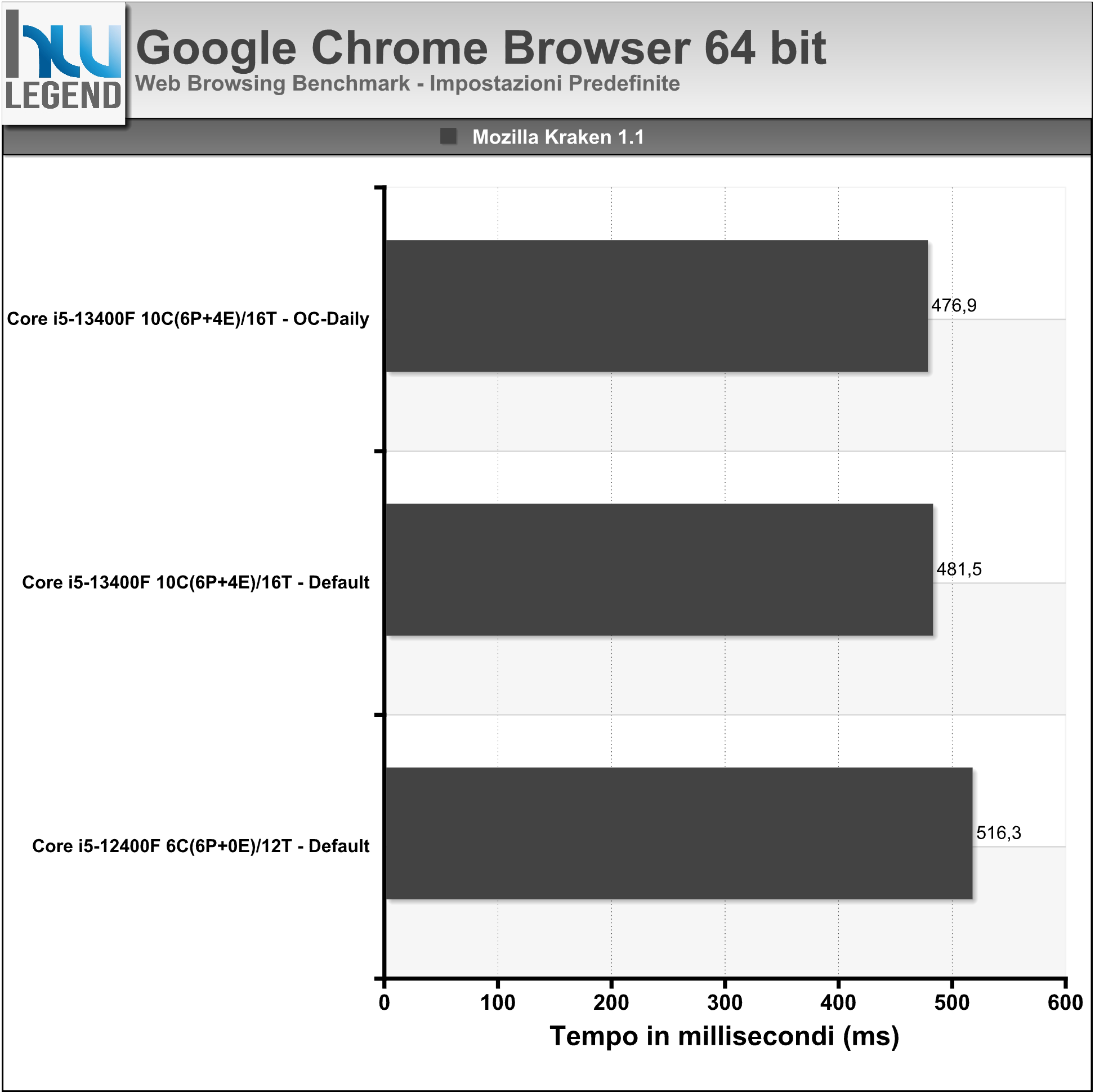
- Mozilla Kraken v1.1: Kraken è un benchmark in JavaScript creato da Mozilla che misura la velocità del browser nel portare a termine una serie di test specifici tratti da applicazioni e librerie del mondo reale in modo da offrire una buona panoramica delle prestazioni in browsing;
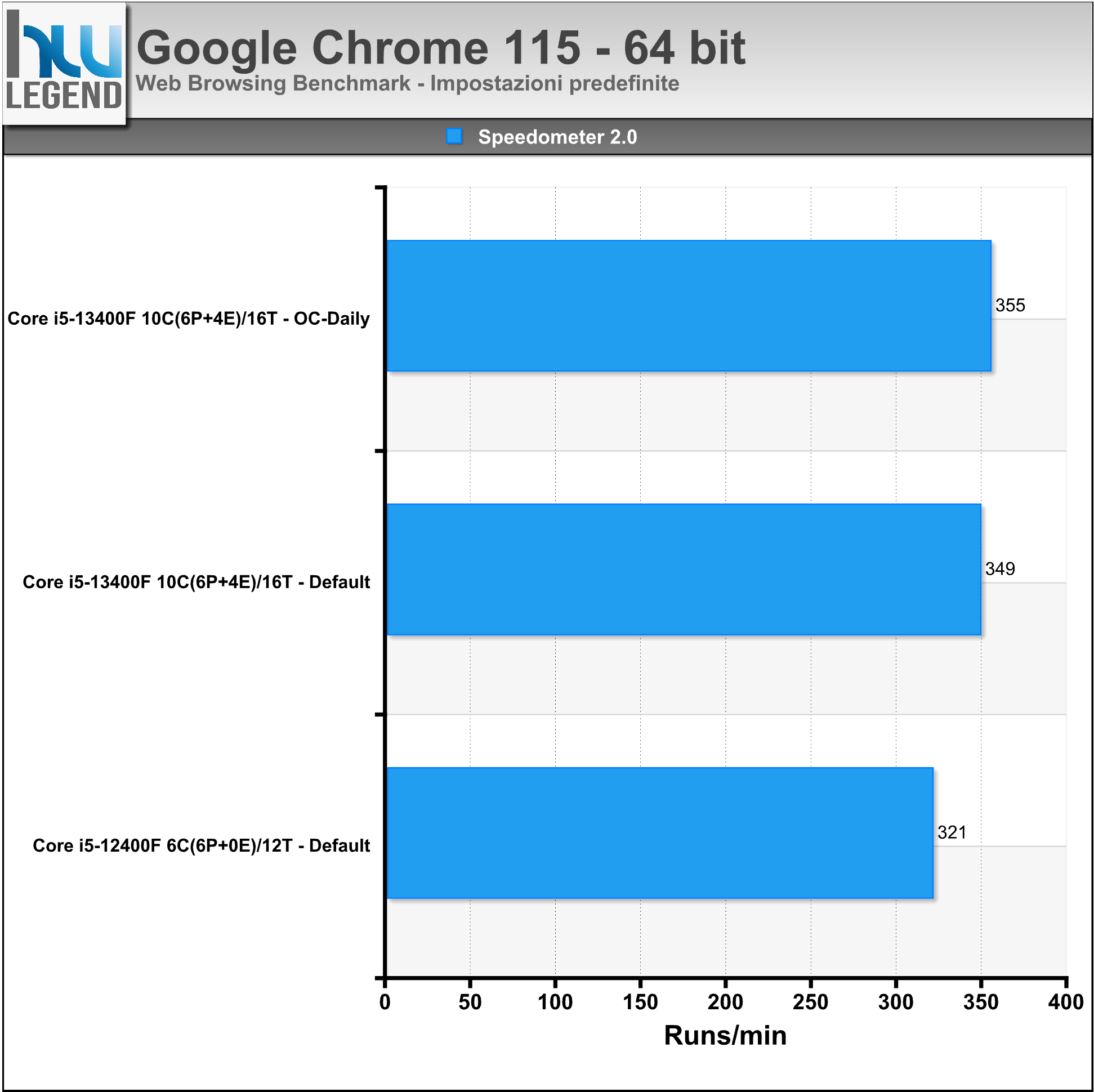
- Speedometer 2.0: Speedometer è un benchmark che misura la reattività del browser utilizzando una serie di applicazioni web demo per simulare le azioni dell’utente, come l’aggiunta di elementi (una sorta di “lista di cose da fare”);
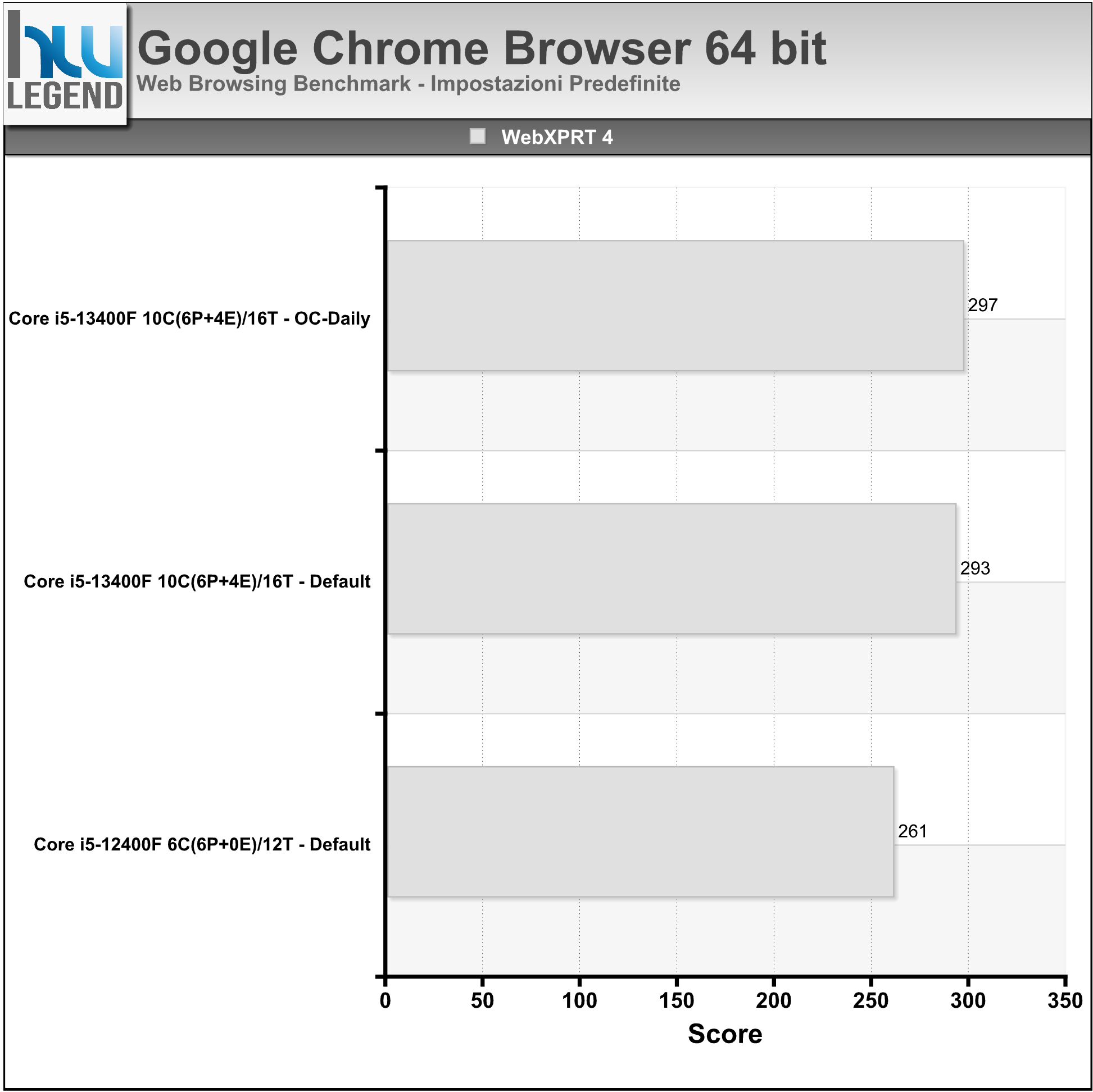
- WebXPRT 4: WebXPRT 4 è uno dei più completi benchmark del browser in circolazione, pensato per misurare con assoluta precisione ed affidabilità le prestazioni con le tipiche applicazioni Web. Contiene test basati su HTML5, JavaScript e WebAssembly creati per rispecchiare le tipiche attività quotidiane, come il miglioramento delle foto, l’organizzazione dei media tramite intelligenza artificiale, la crittografia delle note, la scansione OCR utilizzando WASM, i grafici e la produttività.
Nei grafici i risultati ottenuti utilizzando l’ultima versione del browser Google Chrome:
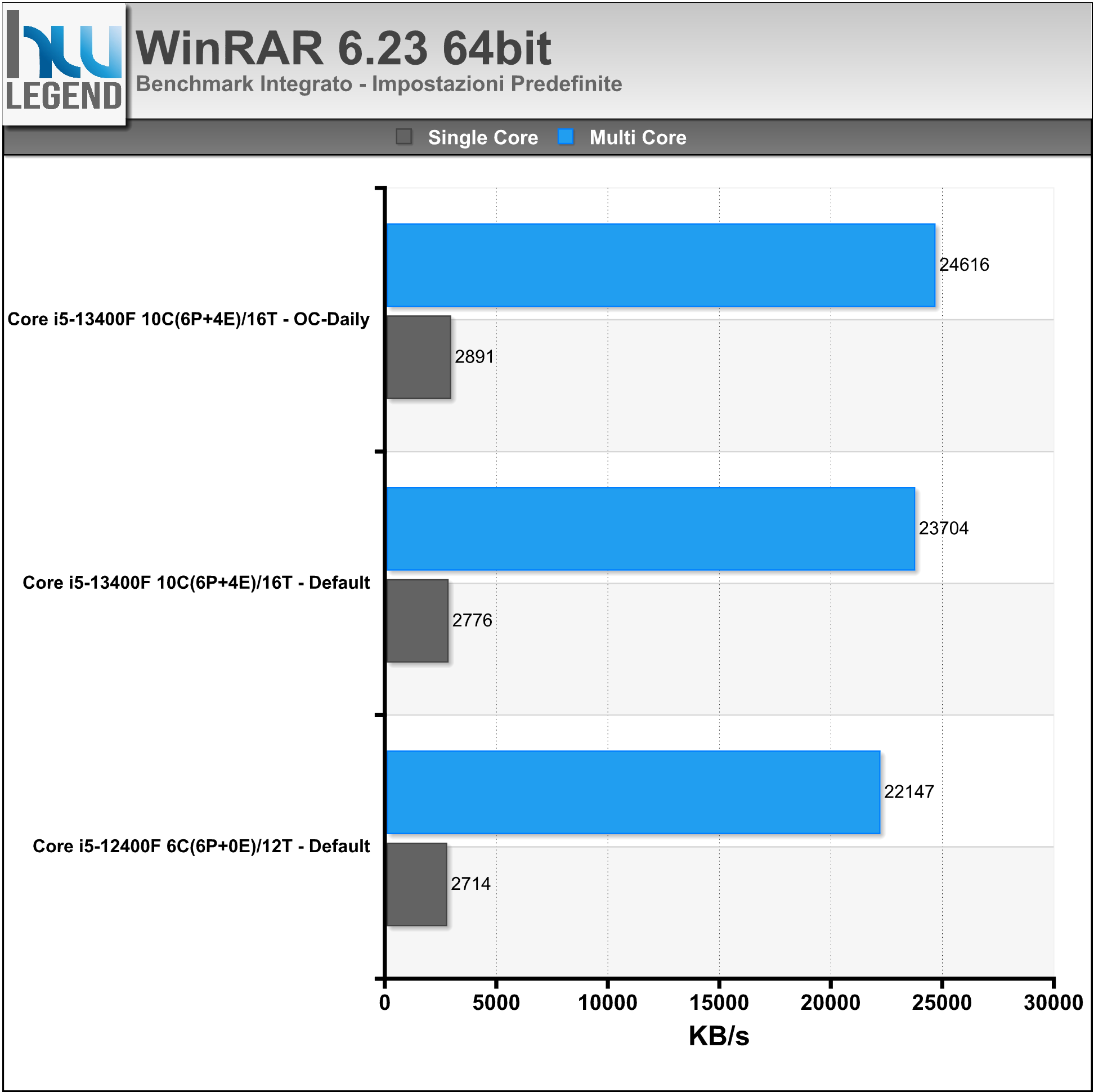
WinRAR è un famoso programma di compressione con il quale si misura la potenza della CPU nel comprimere un file campione restituendo il valore del dato compresso in KB/s (Rate).
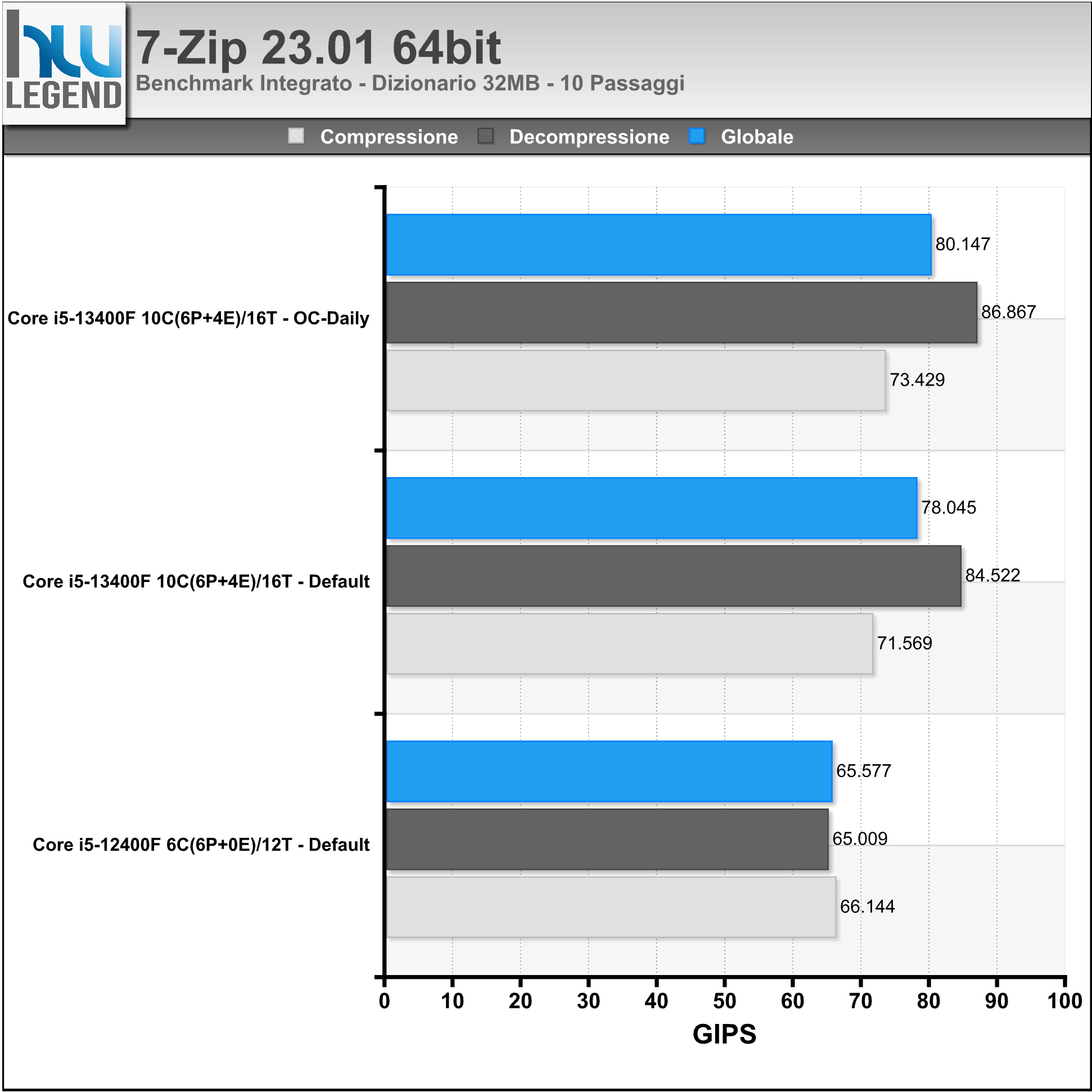
7-Zip è un noto programma di compressione/decompressione che al suo interno integra un Tool per la misura delle prestazioni della macchina. Anche in questo caso saranno riportati nel grafico quanti KB/s il sistema, e in particolar modo la CPU, sia in grado di comprimere/decomprimere.
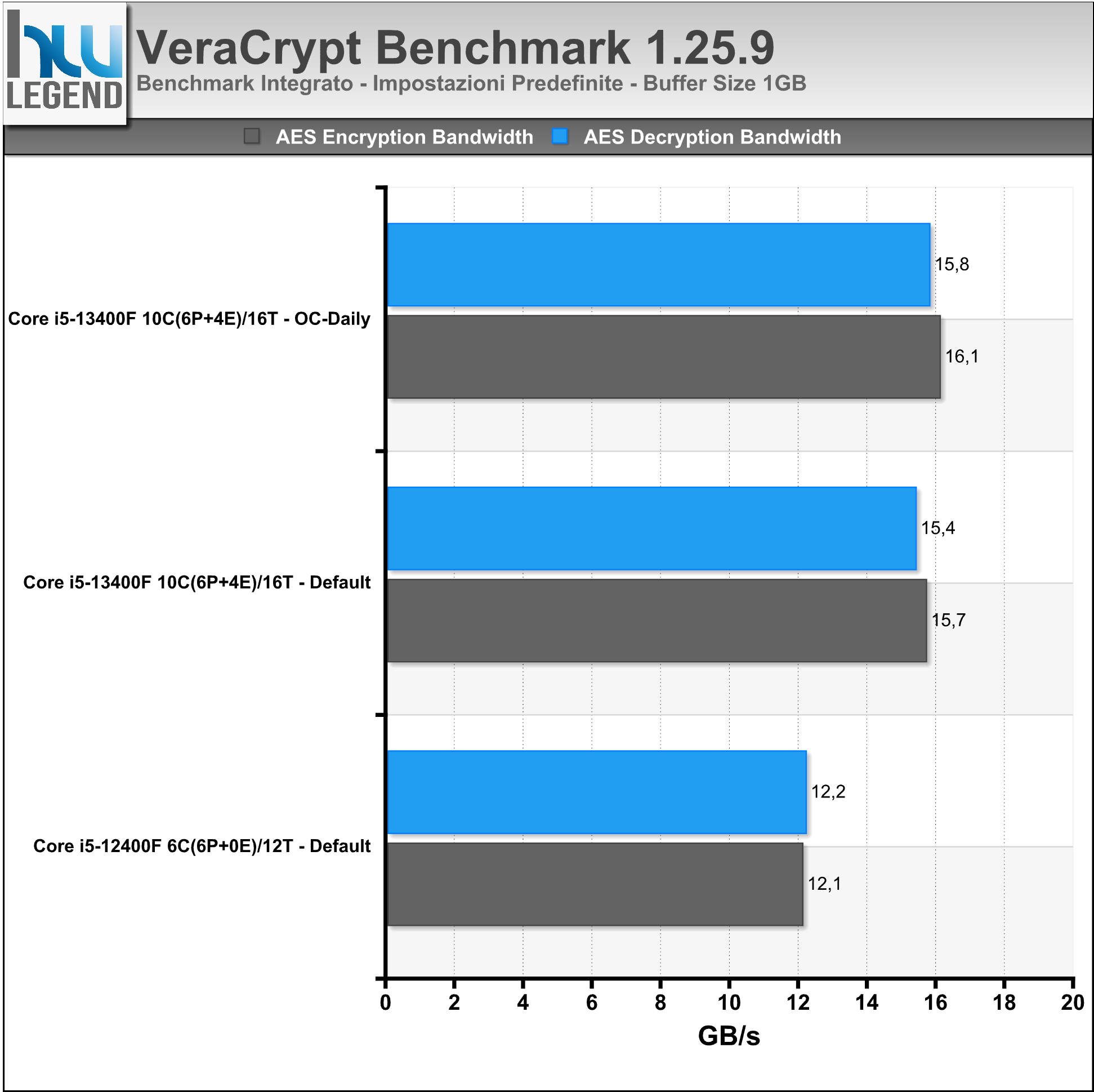
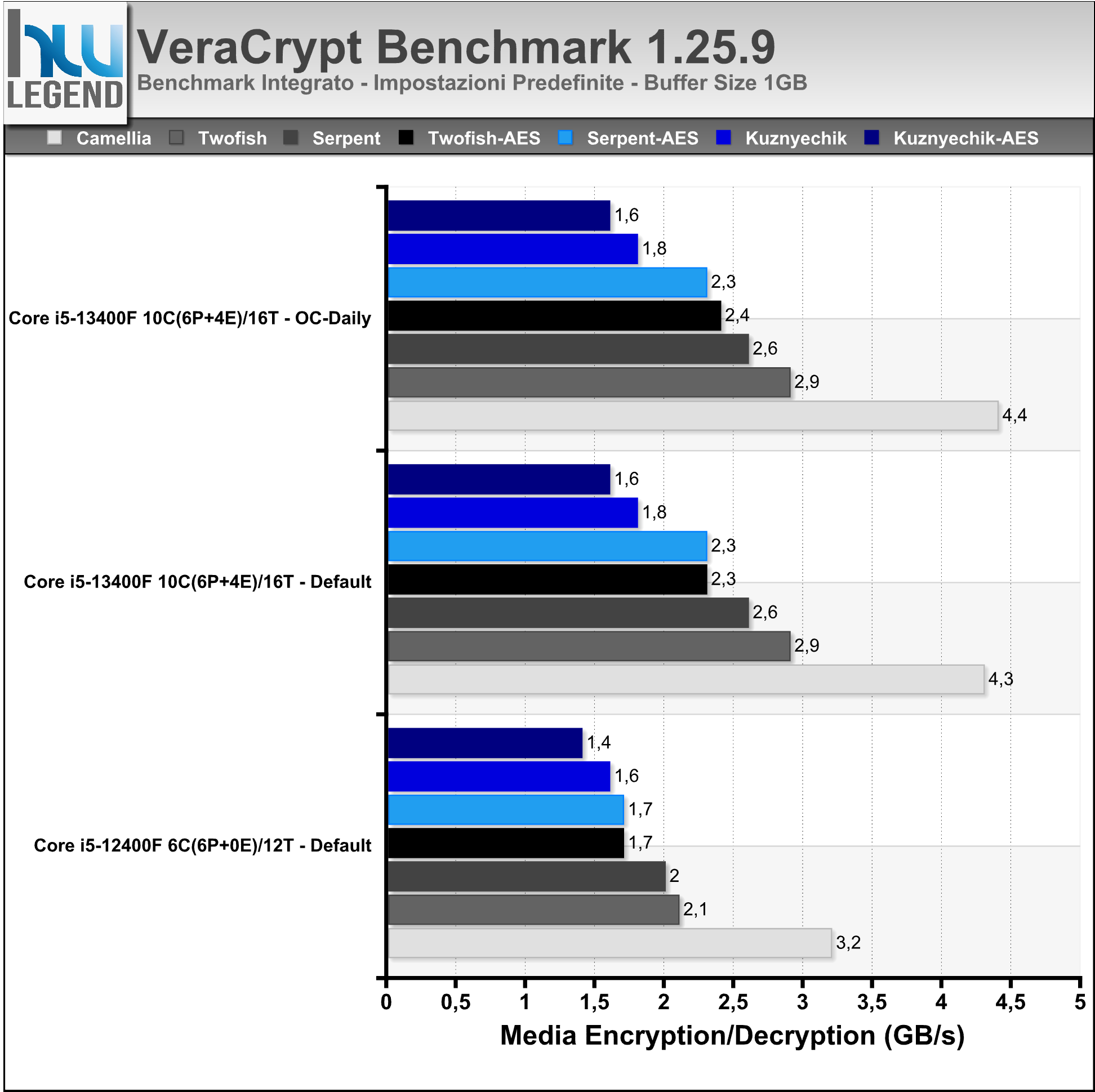
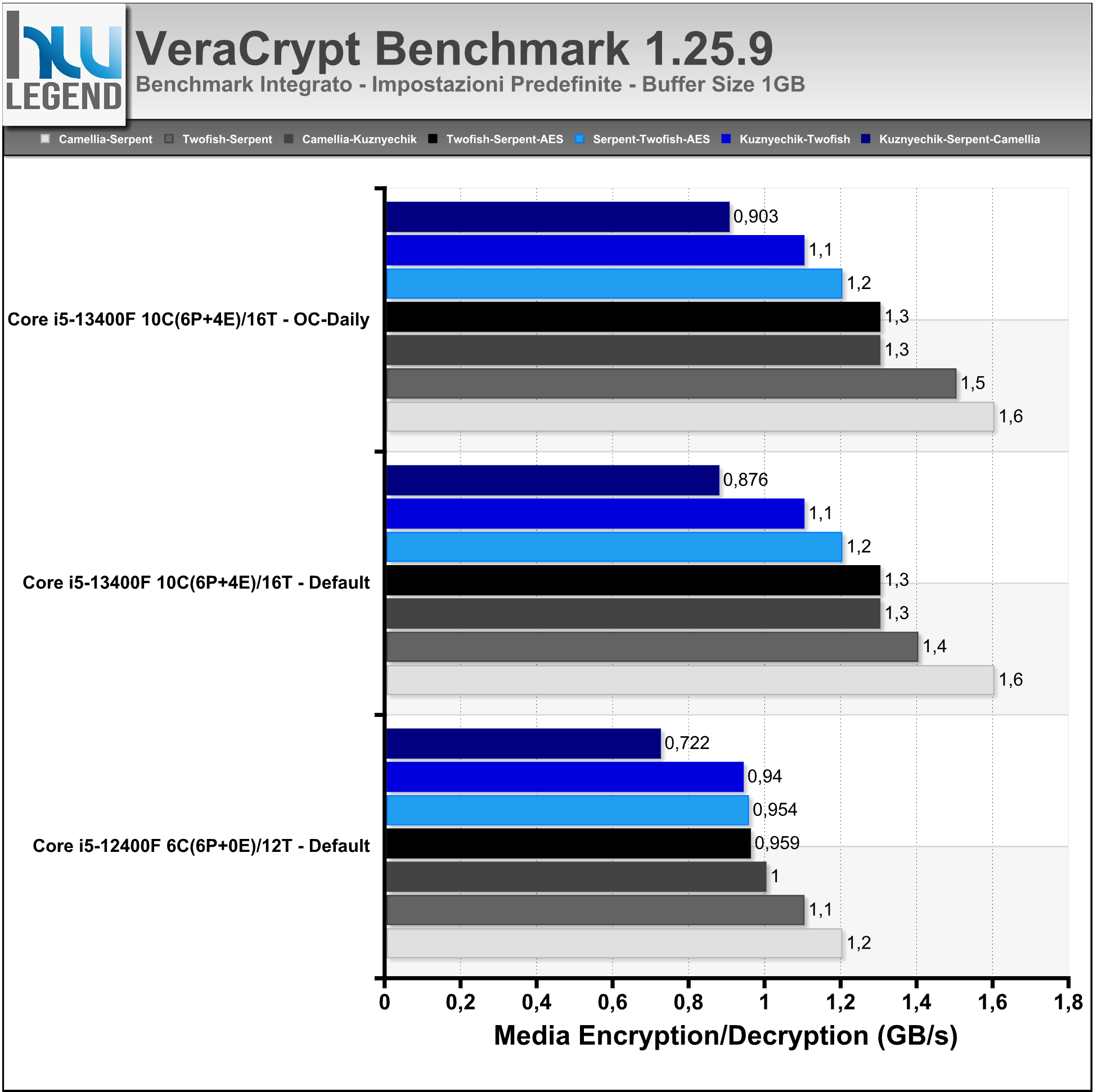
VeraCrypt è un programma applicativo open-source usato per la cifratura “on-the-fly” (OTFE). Può creare un disco virtuale crittografato mediante l’utilizzo di un file o crittografare un’intera partizione oppure, su Windows, l’intero hard disk con un’autenticazione all’avvio. Secondo gli sviluppatori con le versioni più recenti del programma sono stati apportati miglioramenti riguardanti la sicurezza e risolti problemi emersi dall’audit esterno realizzato sul codice del precedente TrueCrypt.
Nei grafici i risultati dei benchmark integrati nel programma.
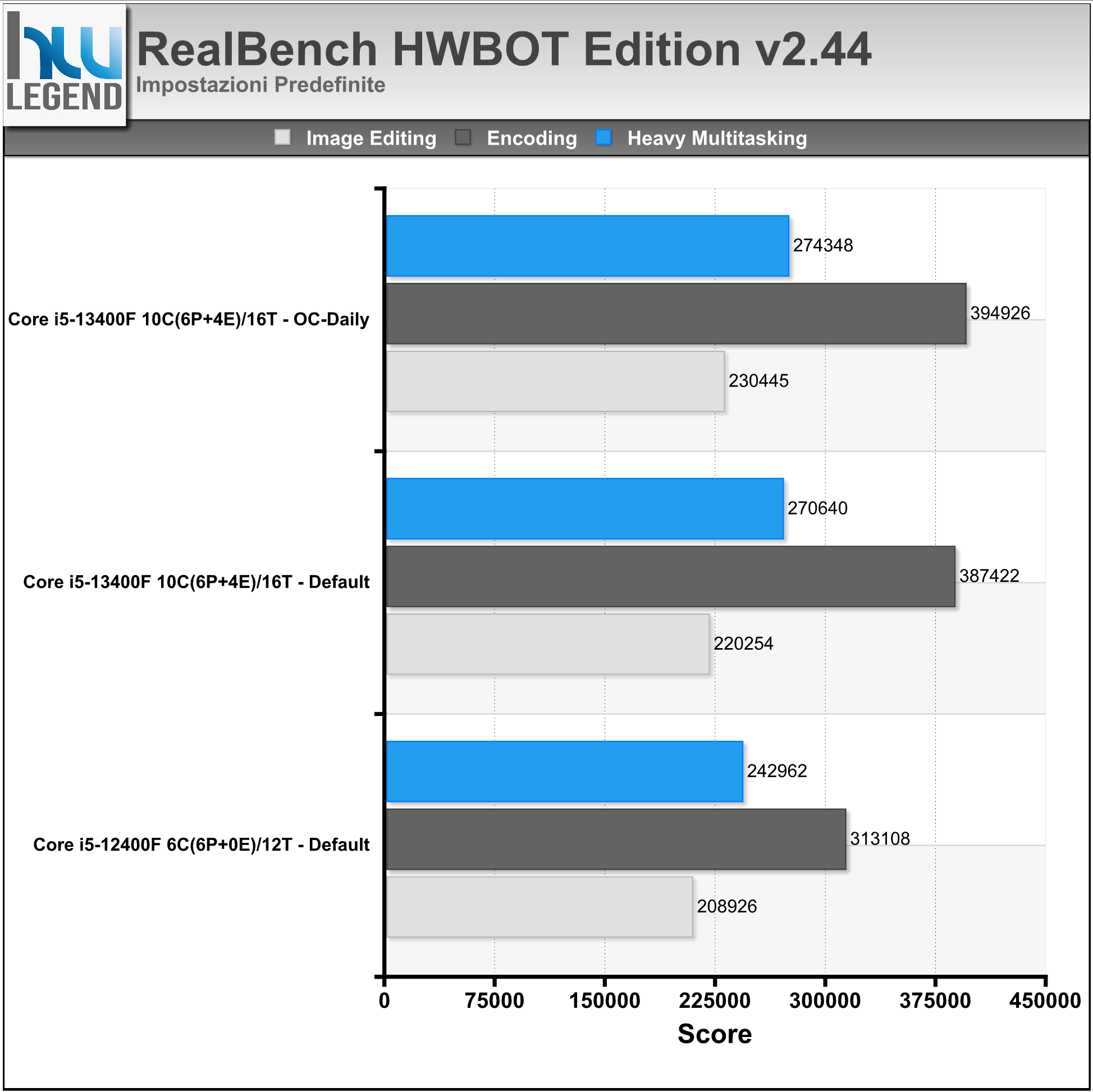
HWBOT Realbench è un software di benchmark recentemente introdotto sul noto sito HWBOT, completamente gratuito e basato sull’ormai rodato Realbench di ASUS. Il programma, sviluppato in collaborazione con i migliori professionisti dell’overclock, sfrutta applicazioni Open Source e semplici ma efficaci script per misurare le prestazioni reali del sistema e fornire un punteggio imparziale dovuto solamente alla potenza di calcolo effettiva.
Il programma sfrutta, inoltre, le più recenti istruzioni come SSE4, AVX e DXVA, ed è presente anche un test “burn in” per verificare l’affidabilità della macchina sotto stress prolungato, molto utile appunto per verificare la stabilità in condizione di overclocking. I numerosi software open-source adottati, tra cui Blender, Handbrake, GIMP e LuxMark supportano le più recenti estensioni per sfruttare al meglio le CPU di nuova generazione.
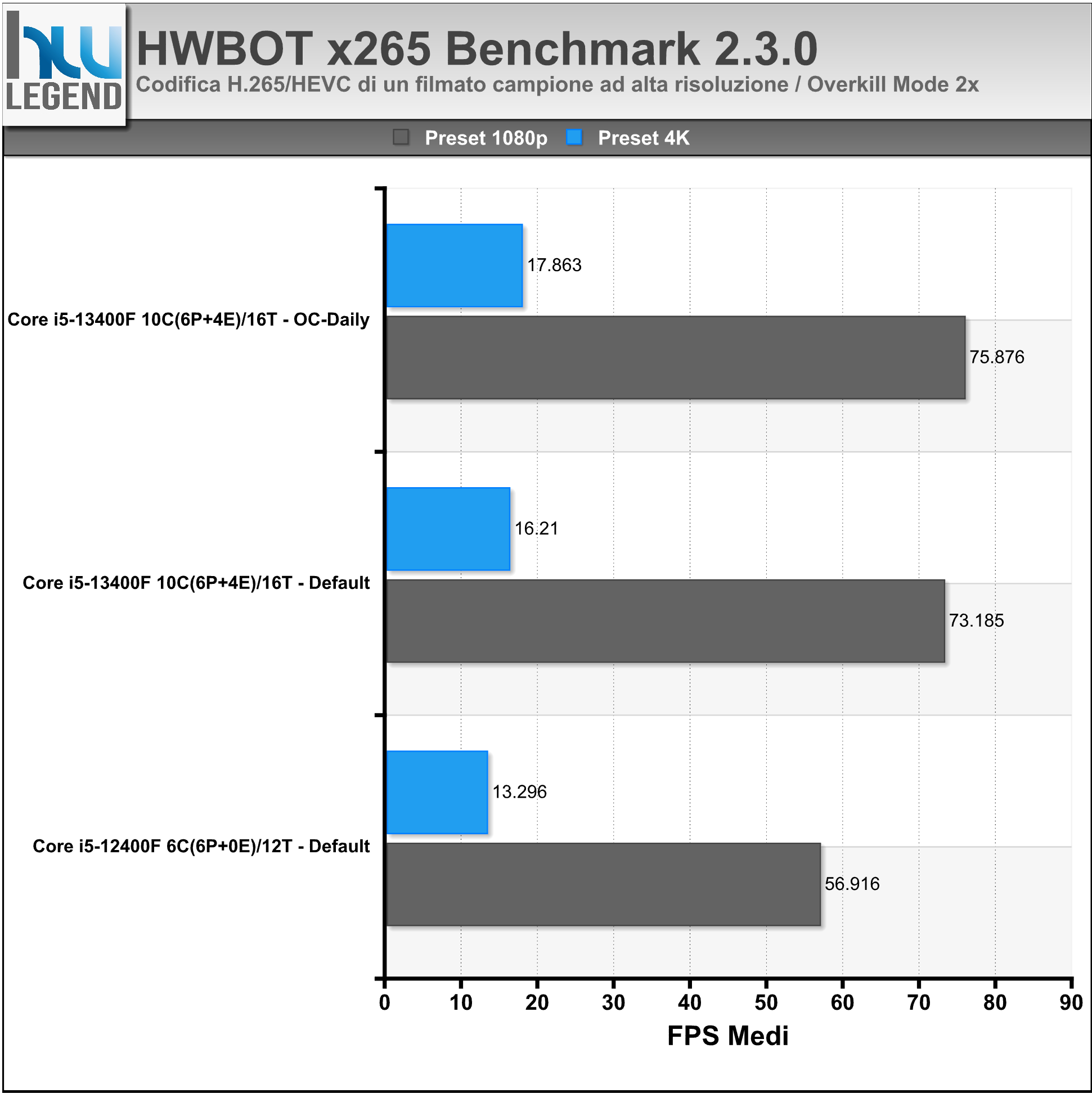
HWBOT X265 Benchmark è un nuovo test recentemente introdotto sul noto sito HWBOT con il quale è possibile testare la potenza della propria CPU. Il suo funzionamento è basato sulla misurazione delle performance in termini di codifica video H.265/HEVC utilizzando dei filmati campione ad alta risoluzione.
Nel grafico i risultati ottenuti, eseguendo il test sia con il preset 1080p che con il più pesante 4K, espressi in FPS medi. In questa pagine (1080p / 4K) è disponibile un database, costantemente aggiornato, in cui poter confrontare i risultati ottenuti da molteplici microprocessori.
[nextpage title=”Prestazioni Multimedia e Compressione – Parte Prima”]
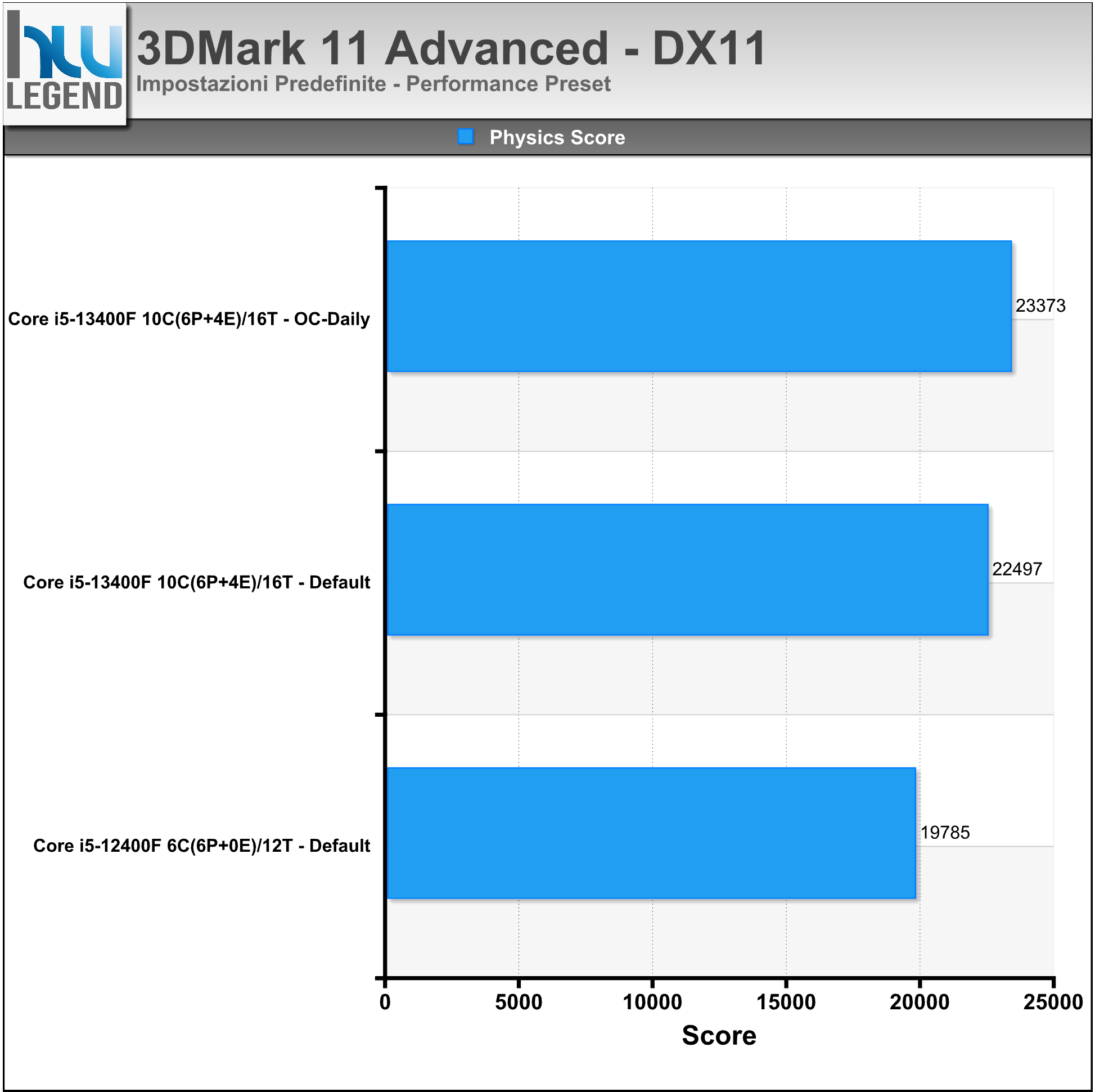
La penultima versione del famoso software richiederà obbligatoriamente la presenza nel sistema sia di una scheda video con supporto alle API DirectX 11. Secondo Futuremark, i test sulla tessellation, l’illuminazione volumetrica e altri effetti usati nei giochi moderni rendono il benchmark moderno e indicativo sulle prestazioni “reali” delle schede video. La versione Basic Edition (gratuita) permette di fare tutti i test con l’impostazione “Performance Preset”.
C’è un test, chiamato Audio Visual Demo, eseguibile alla risoluzione massima 720p. La versione Basic consente di pubblicare online un solo risultato. Non è possibile modificare la risoluzione e altri parametri del benchmark. 3DMark 11 Advanced Edition non ha invece alcun tipo di limitazione.
Il benchmark si compone di sei test, i primi quattro con il compito di analizzare le performance del comparto grafico, con vari livelli di tessellazione e illuminazione. Il quinto test non sfrutta la tecnologia NVIDIA PhysX, bensì la potenza di elaborazione del processore centrale. Il sesto e ultimo test consiste, invece, in una scena precalcolata in cui viene sfruttata sia la CPU, per i calcoli fisici, e sia la scheda grafica.
I test sono stati eseguiti in DirectX 11 sfruttando il preset Performance. Nel grafico il punteggio ottenuto nel Physics Test.
La nuova versione del famoso software è senza dubbio la più potente e flessibile mai sviluppata da Futuremark (attualmente UL Benchmarks). Per la prima volta viene proposto un programma multipiattaforma, capace di eseguire analisi comparative su sistemi operativi Windows, Windows RT, Android e iOS. Le prestazioni velocistiche della propria soluzione grafica possono essere osservate sfruttando nuovi ed inediti Preset: Ice Storm, Cloud Gate, Sky Diver, Fire Strike, Time Spy, Port Royal e Speed Way.
Il primo, Ice Storm, sfrutta le funzionalità delle librerie DirectX 9.0 ed è sviluppato appositamente per dispositivi mobile, quali Tablet e Smartphone senza comunque trascurare i computer di fascia bassa. Il secondo, Cloud Gate è pensato per l’utilizzo con sistemi più prestanti, come ad esempio notebook e computer di fascia media, grazie al supporto DirectX 10. Il terzo, Sky Diver, fa da complemento offrendo un punto di riferimento ideale per laptop da gioco e PC di fascia medio-alta con supporto DirectX 11. Infine, gli ultimi preset, denominati Fire Strike, Time Spy, Port Royal e Speed Way, sono pensati per l’analisi dei moderni sistemi di fascia alta, contraddistinti da processori di ultima generazione e comparti grafici di assoluto livello con pieno supporto DirectX 11 (Fire Strike), DirectX 12 (Time Spy) e DirectX 12 & DirectX Raytracing (Port Royal e Speed Way).
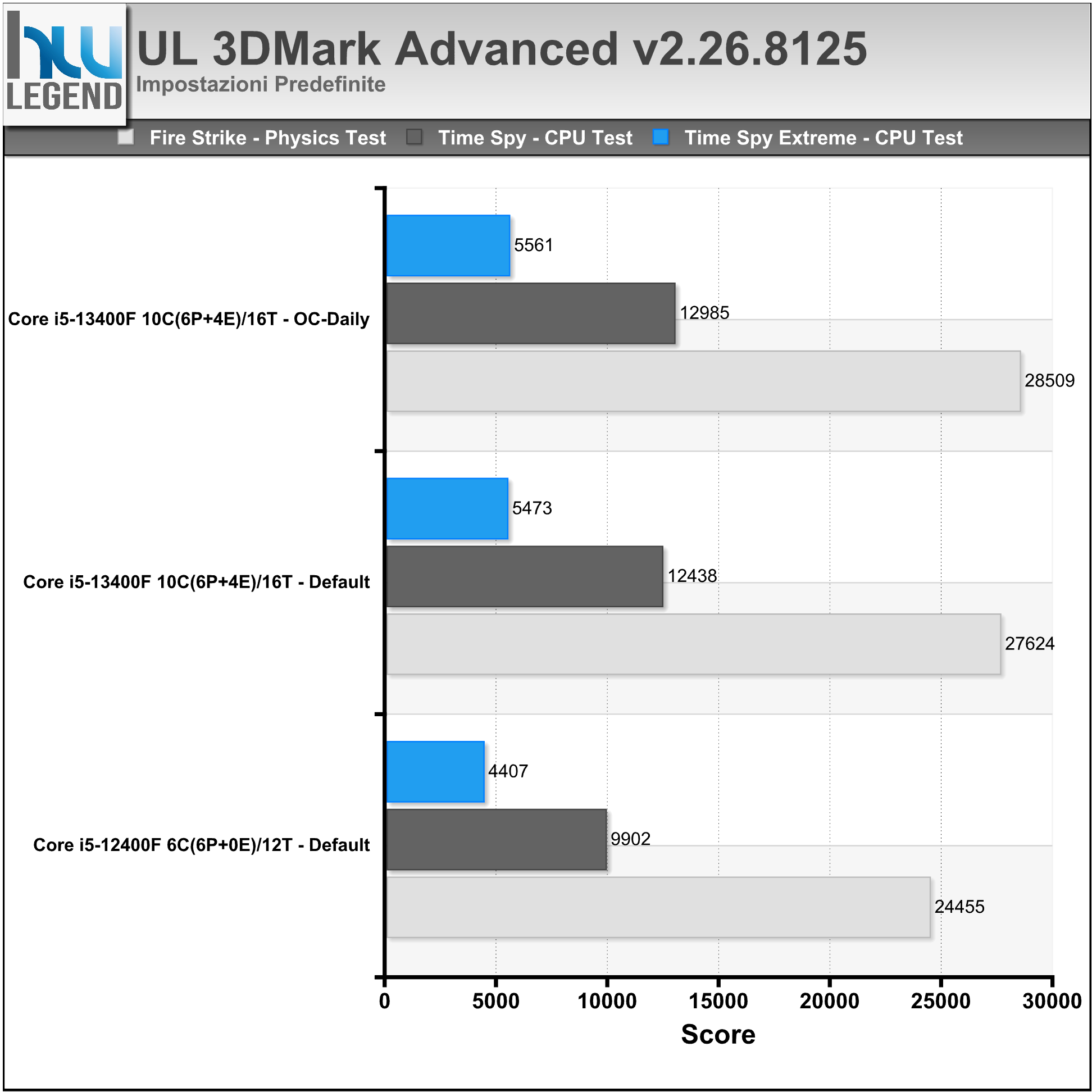
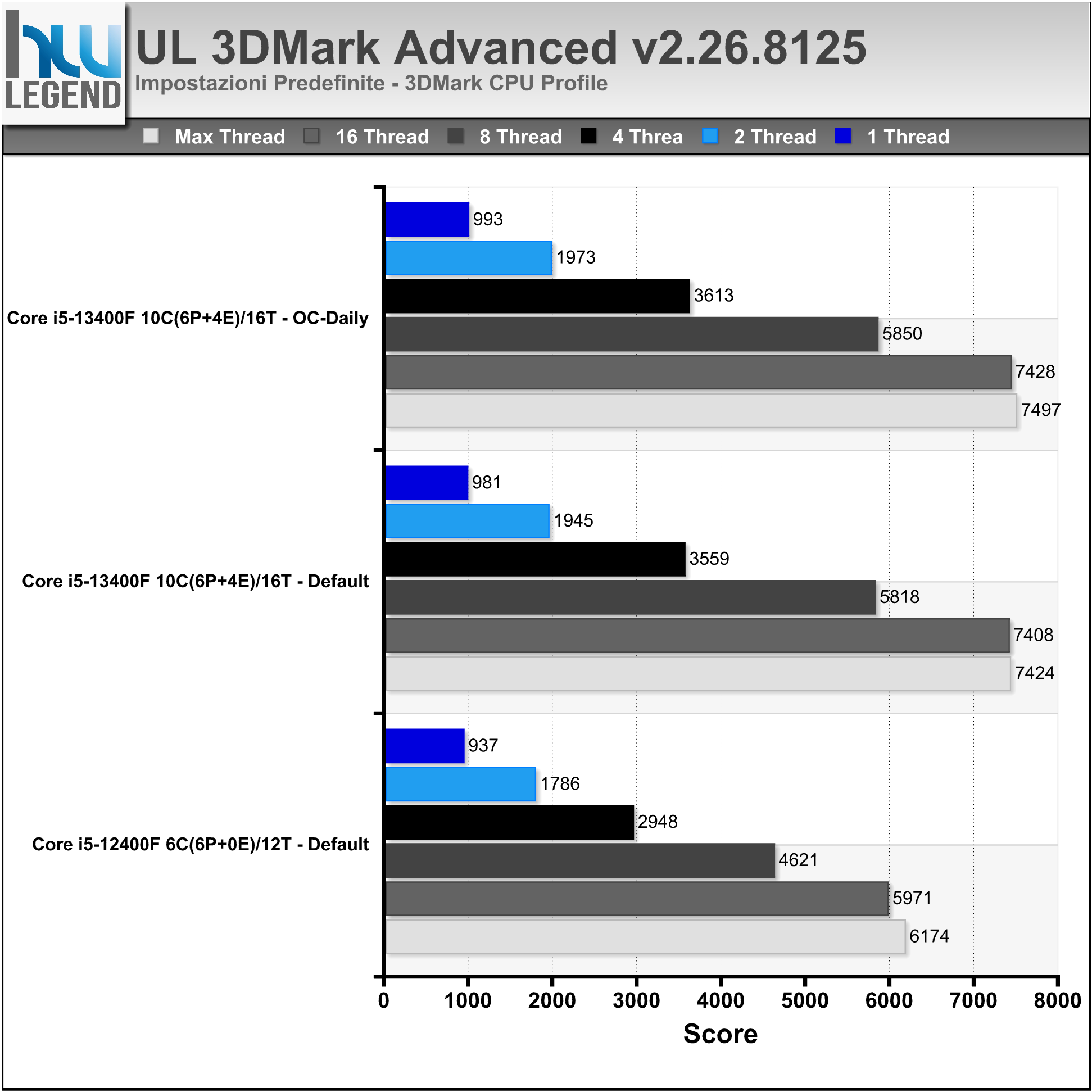
I nostri test sono stati eseguiti sfruttando i preset Fire Strike (Normal) e Time Spy (Normal ed Extreme), oltre che il più recente pacchetto CPU Profile. Nei grafici i punteggi ottenuti nei relativi Psysics e CPU Test.
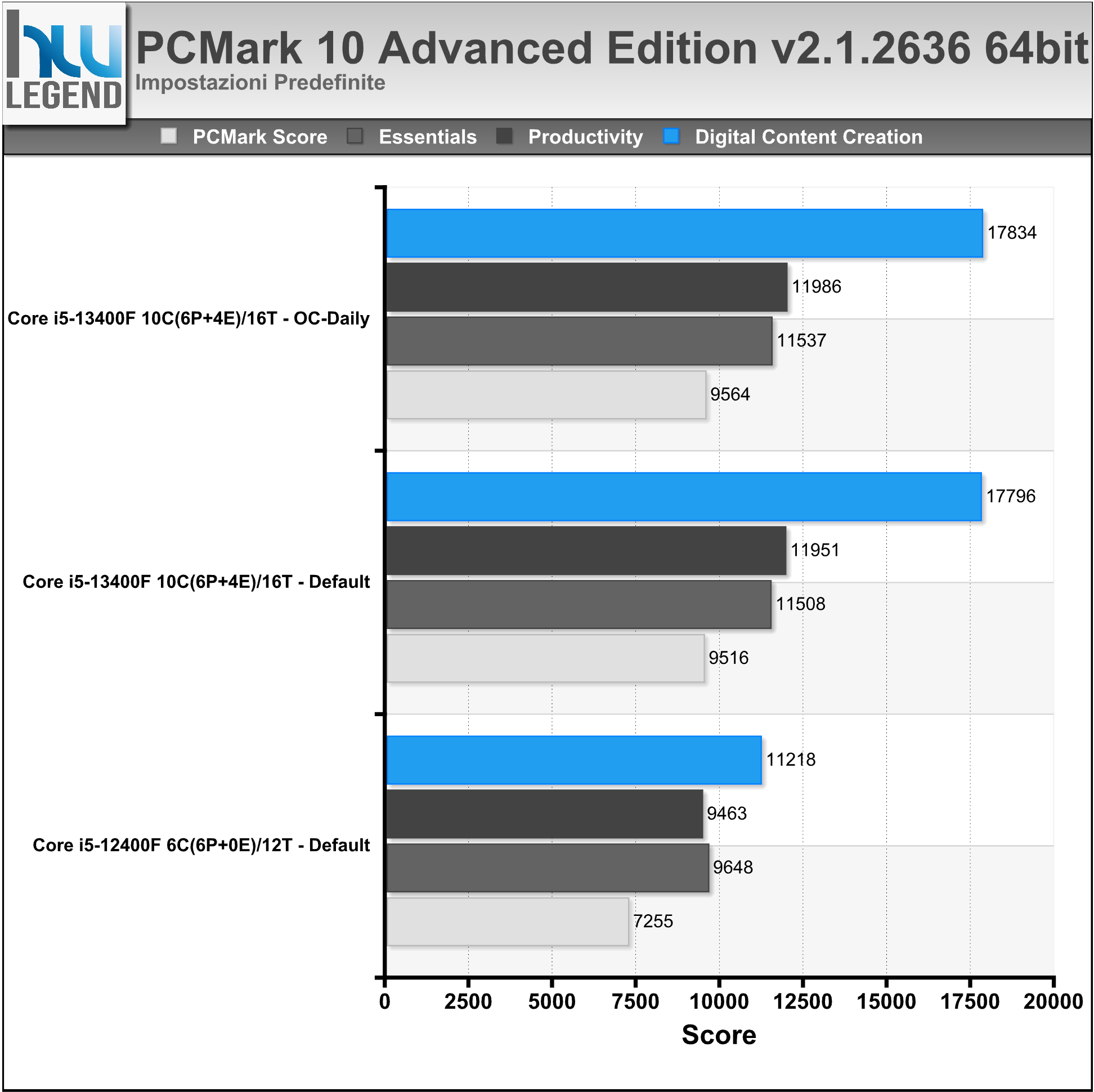
PCMark è un’ormai noto programma di benchmarking e test del sistema sviluppato da UL Benchmarks, in grado di fornire una precisa indicazione di quelle che sono le reali prestazioni del proprio sistema o dei singoli reparti (CPU, Memoria RAM, Storage etc.).
Per le nostre prove ci siamo affidati all’ultima versione del programma (PCMark 10 Professional v2.1.2636), in maniera da poter offrire un quadro il più possibile preciso delle prestazioni del sistema in esame. Nei grafici riportiamo il risultato complessivo ottenuto (PCMark Score) e quello delle singole tipologie di test: Essentials, Productivity e Digital Content Creation.
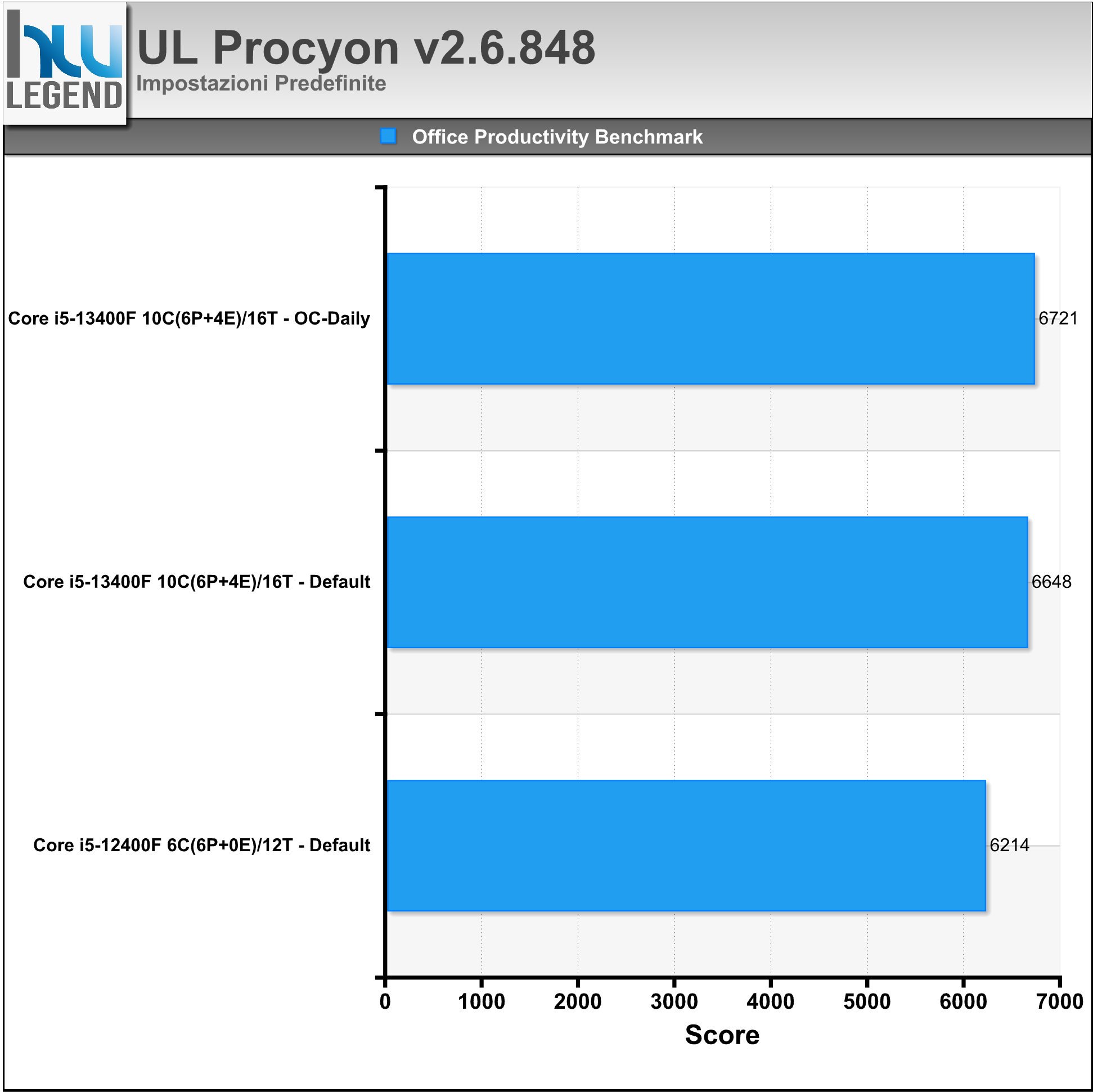
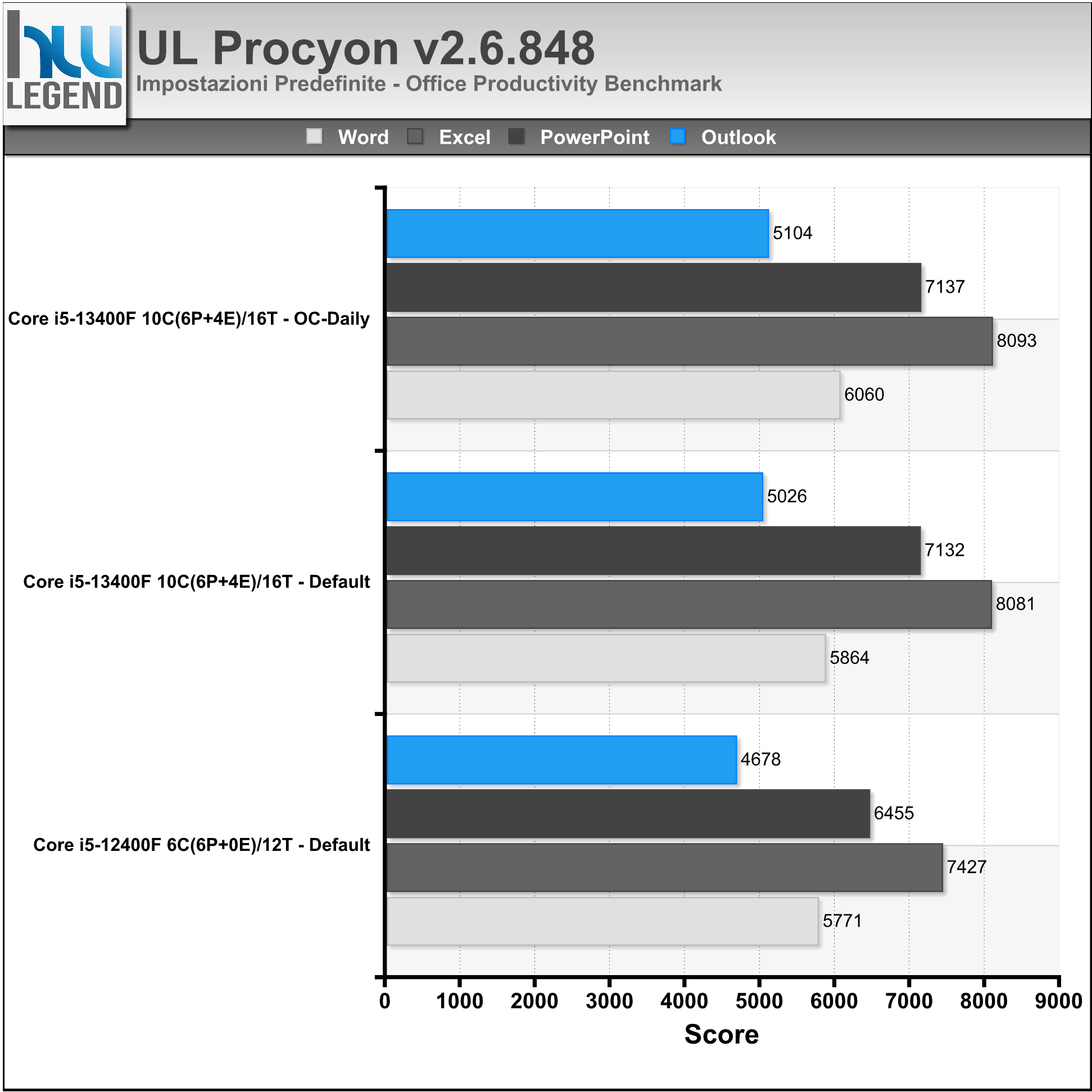
Procyon è il nuovo e potente software di benchmarking sviluppato da UL Benchmarks, espressamente pensato per l’utenza professionale (industria, imprese, vendita al dettaglio) e la stampa. Il programma si compone di diversi benchmark integrati, ognuno con caratteristiche differenti ma ben integrato in un’interfaccia e set di funzionalità comuni. Ogni benchmark è progettato per un caso d’uso specifico e utilizza applicazioni reali ove possibile. L’azienda sta lavorando a stretto contatto con diversi partner del settore al fine di garantire che ogni serie di test integrati in Procyon sia accurata, pertinente e imparziale.
Per le nostre prove ci siamo affidati all’ultima versione del programma gentilmente fornitaci dall’azienda (Procyon Professional v2.6.848), in maniera da poter offrire un quadro il più possibile preciso delle prestazioni del sistema in esame.
Nei grafici riportiamo il risultato complessivo ottenuto sfruttando la suite Office Productivity Benchmark che, come facilmente intuibile, utilizza le applicazioni di Microsoft Office (nel nostro caso la versione 2021) per misurare le prestazioni offerte dal PC per scopi di produttività d’ufficio. Il benchmark si basa su attività rilevanti e del mondo reale che utilizzano Microsoft Word, Excel, PowerPoint e Outlook, combinando l’importanza di testare le prestazioni con le stesse app che gli impiegati usano quotidianamente con la comodità di un test standardizzato ed in grado di produrre risultati coerenti e ripetibili.
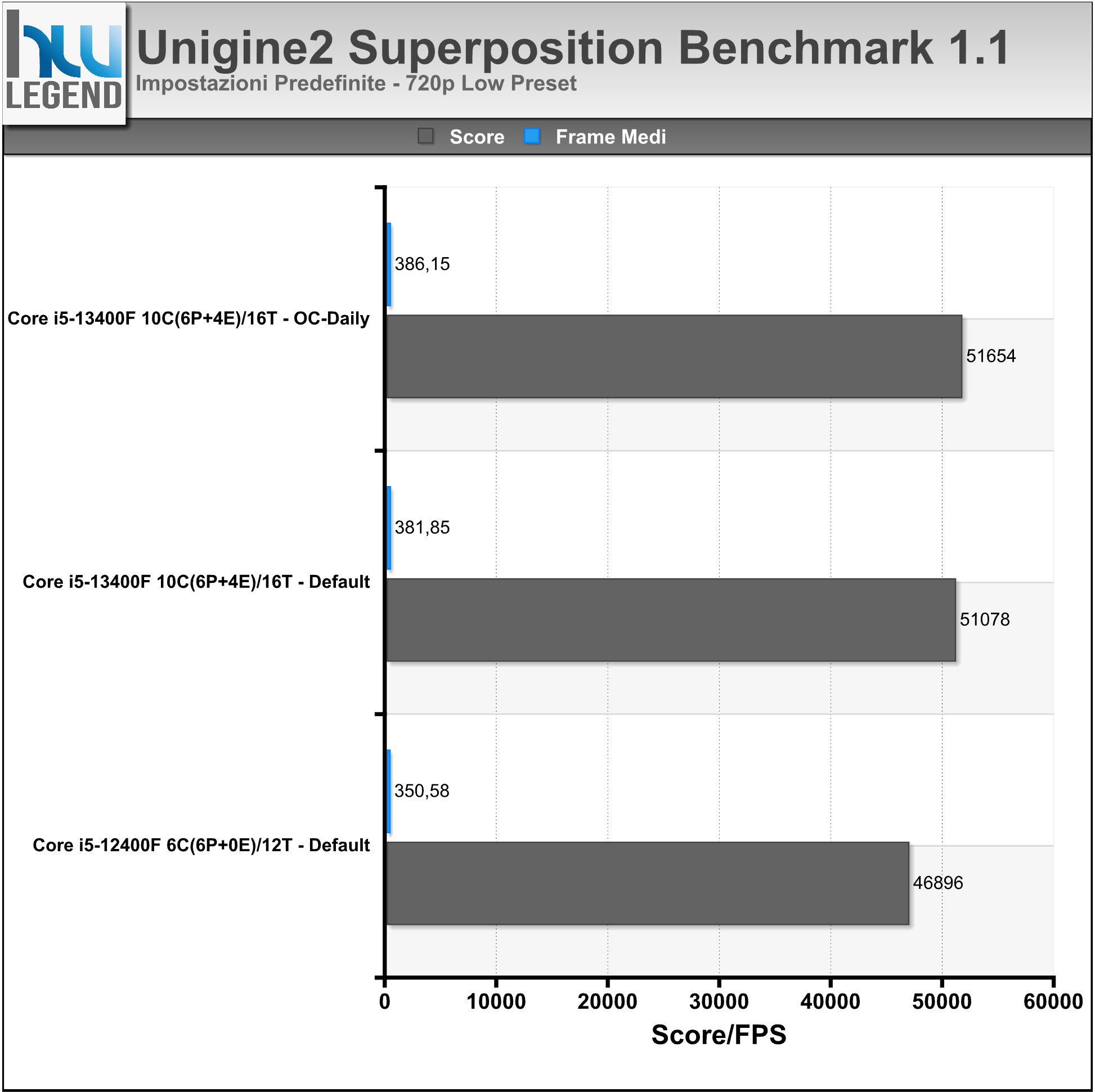
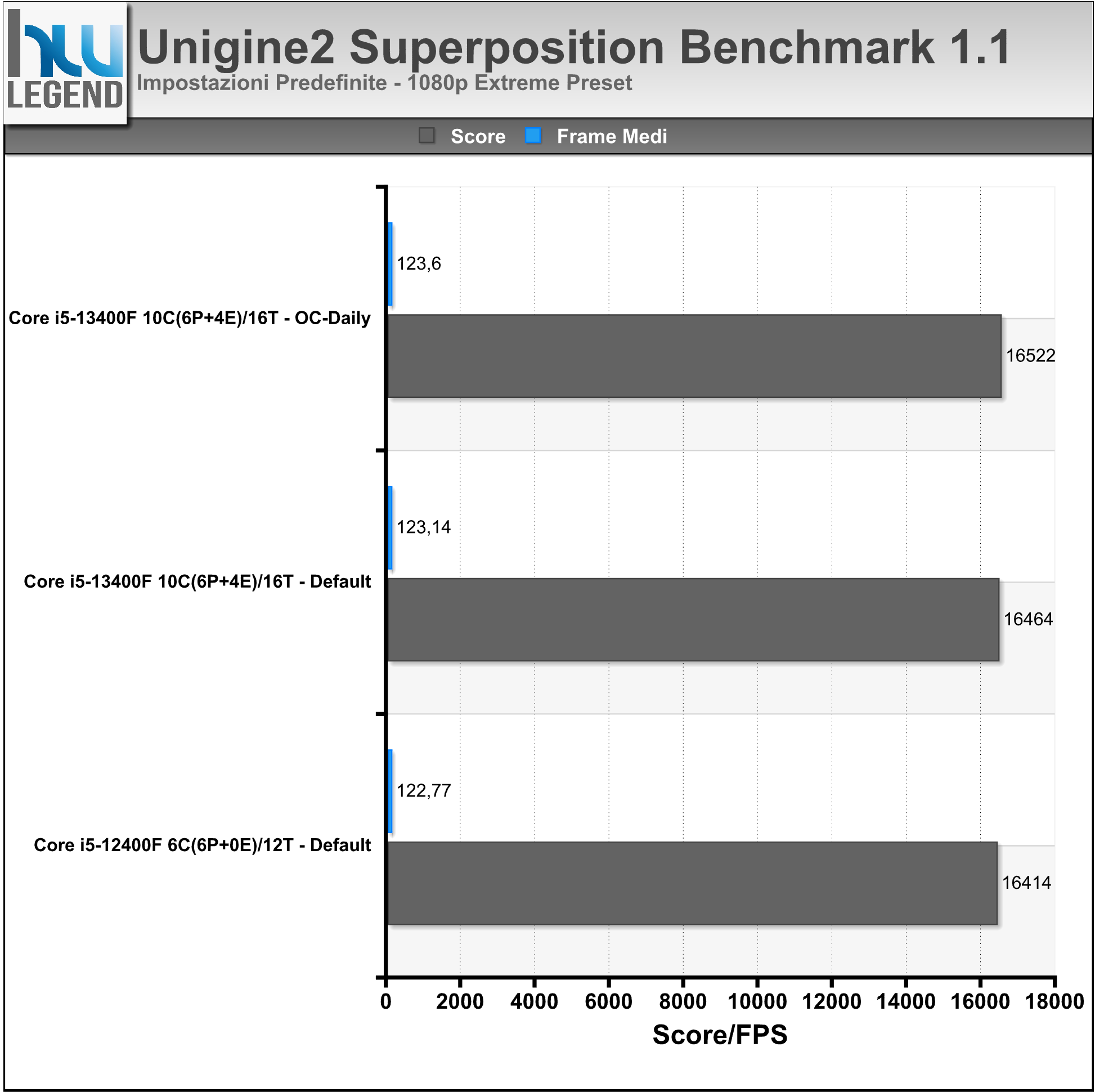
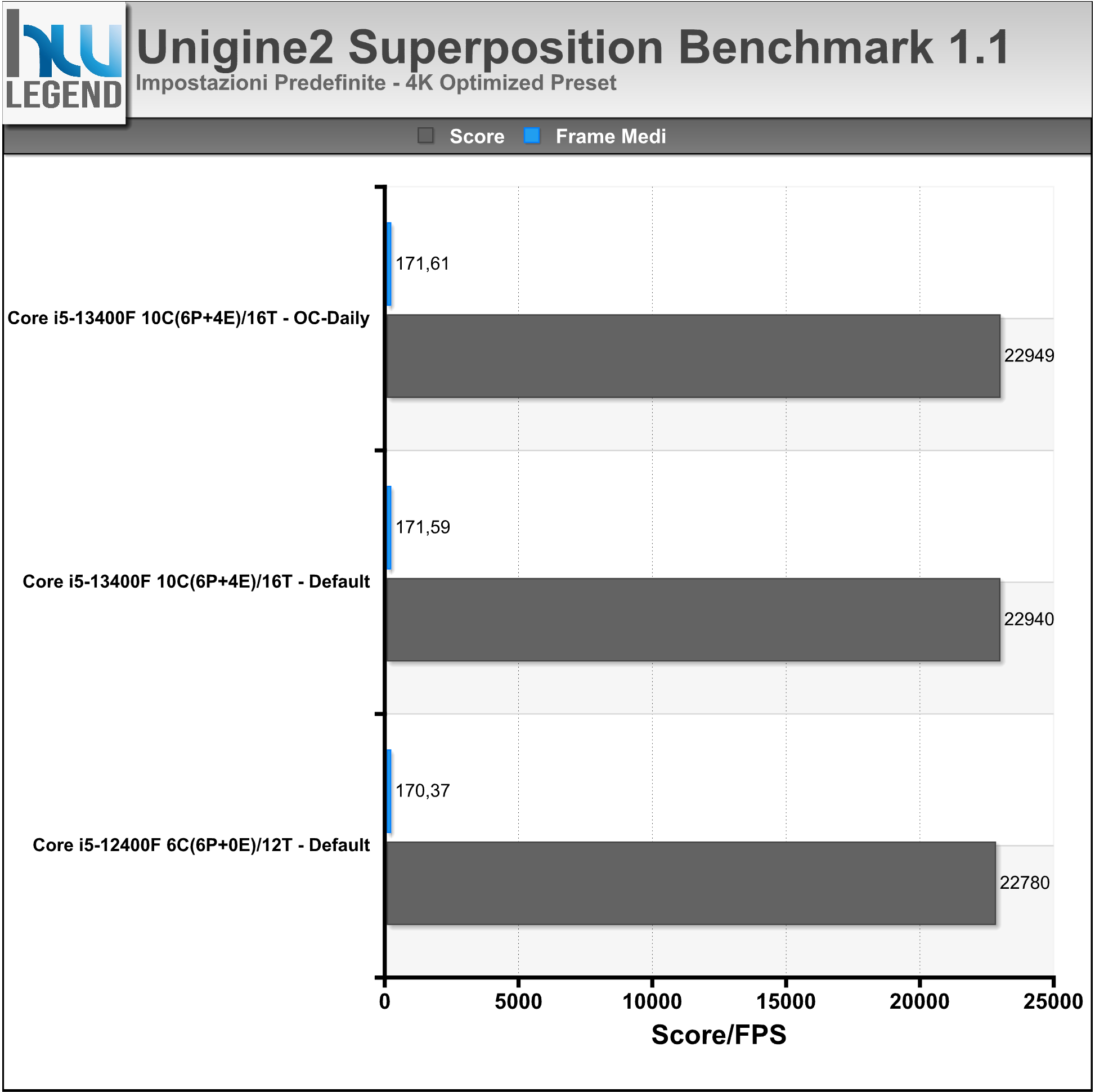
Direttamente dagli sviluppatori degli apprezzati Heaven e Valley, e seppur con un leggero ritardo sulla tabella di marcia, ecco che finalmente vede la luce il nuovo software di benchmark Superposition, basato sul potente motore grafico di nuova generazione Unigine 2, capace di spremere all’inverosimile anche le più prestanti soluzioni grafiche sul mercato.
Come di consueto sono previsti vari profili predefiniti, che consentiranno di ottenere risultati, in termini prettamente prestazionali, facilmente confrontabili. Rispetto al passato è stato implementato un database online, nel quale verranno raccolti i risultati ottenuti dagli utenti e poter quindi fare confronti su ben più larga scala. Oltre a questo sono state introdotte nuove modalità, a cominciare da una simulazione interattiva dell’ambiente, denominata “Game”, alla possibilità di sfruttare i più moderni visori per realtà virtuale, come Oculus Rift e HTC Vive. Viene inoltre offerta la possibilità di verificare la piena stabilità del proprio comparto grafico, grazie allo “Stress Test” integrato (esclusiva della versione Advanced del programma).
I test sono stati condotti utilizzando i preset 720p Low, 1080p Extreme e 4K Optimized. Nel grafico i risultati ottenuti, espressi sotto forma di Score finale e di FPS medi.
[nextpage title=”Prestazioni Giochi”]
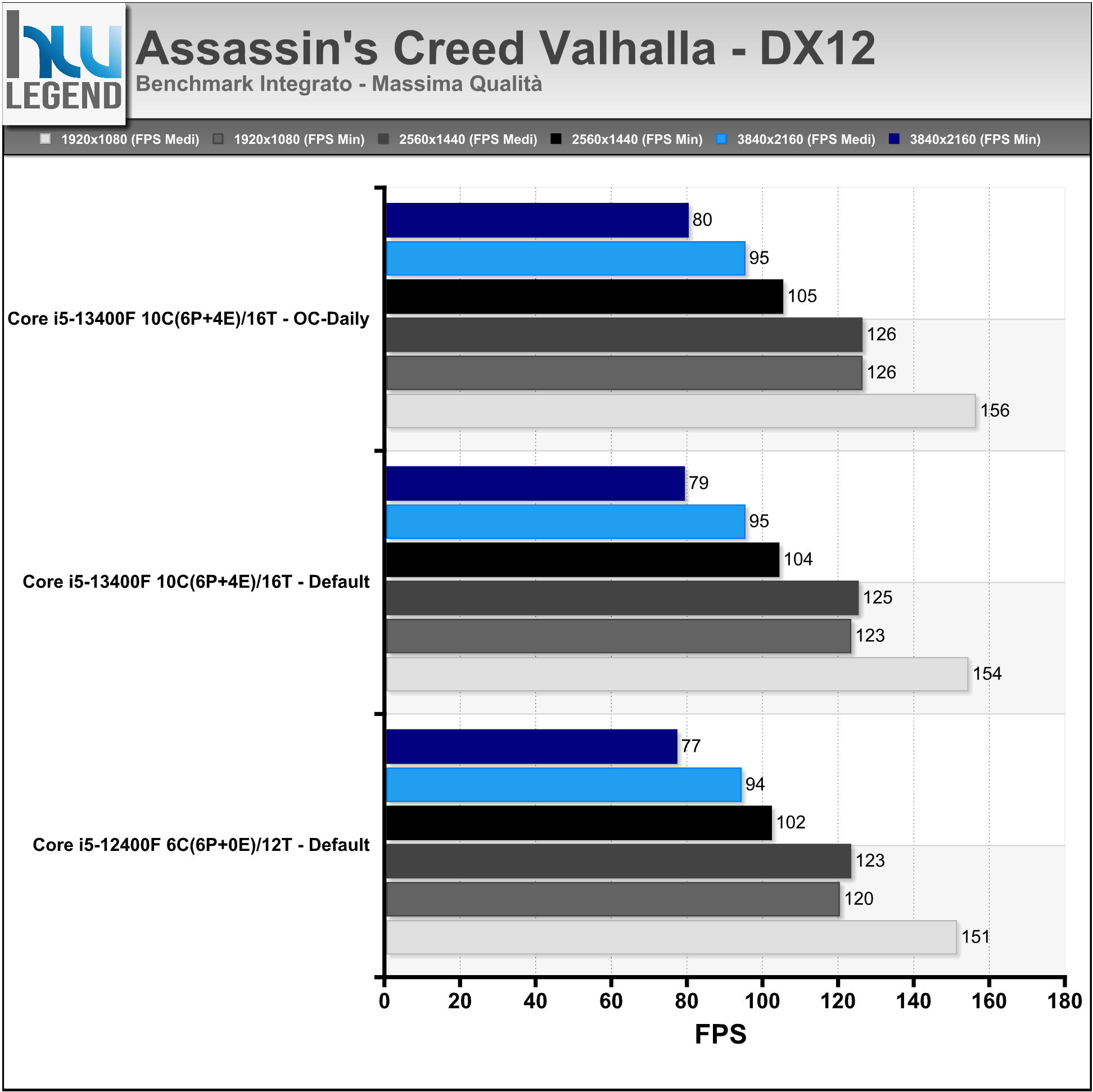
Assassin’s Creed: Valhalla è un videogioco sviluppato da Ubisoft Montreal e pubblicato da Ubisoft. È il dodicesimo capitolo della saga principale di Assassin’s Creed, sequel di Assassin’s Creed: Odyssey, pubblicato nel 2018.
Un anno dopo aver rivissuto le memorie della Misthios, Layla Hassan si trova nel New England per indagare su due eventi apparentemente non correlati: il progressivo rinforzo del campo geomagnetico (fenomeno che causa un’eterna aurora boreale) e il ritrovamento del corpo di un guerriero vichingo del IX secolo, risalente a ben due secoli prima della presenza norrena in America.
Nonostante sia ancora turbata dalla morte di Victoria Bibeau, e sebbene senta un forte influsso proveniente dal Bastone di Hermes, Layla decide di rivivere attraverso l’Animus le memorie del guerriero vichingo, coadiuvata dai due Assassini Shaun Hastings e Rebecca Crane….

Il gioco, presentato lo scorso mese di novembre su PC, è in grado di sfruttare le API DirectX 12. I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:
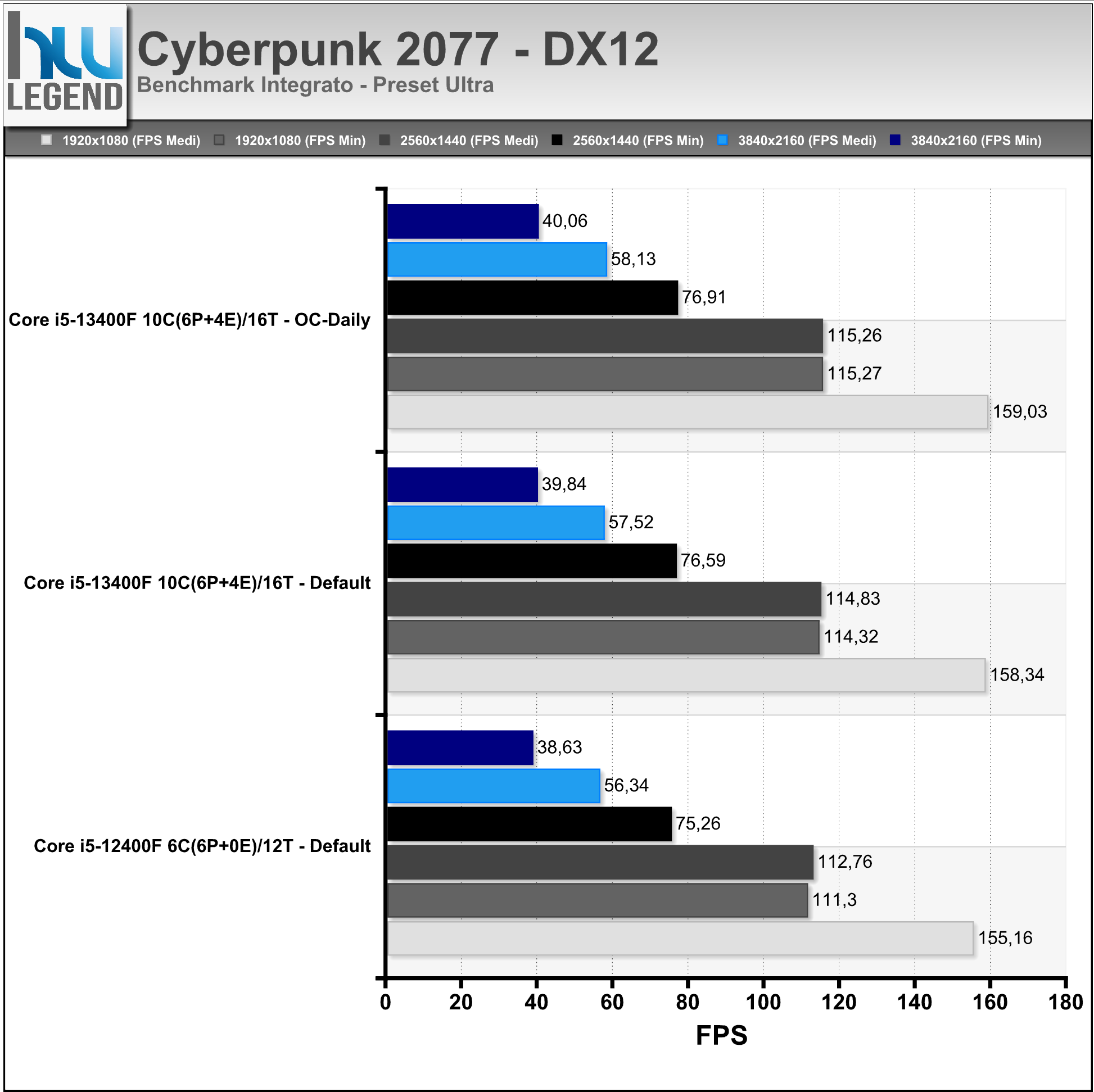
Cyberpunk 2077 è un videogioco sparatutto in prima persona di genere action RPG e open world, sviluppato da CD Projekt RED e pubblicato da CD Projekt il 10 dicembre 2020 inizialmente per Xbox One, Microsoft Windows, PlayStation 4 e Google Stadia.
Night City è una megalopoli americana controllata da corporazioni. Vede il conflitto tra le dilaganti guerre tra bande contendendosi il dominio. La città fa affidamento alla robotica per aspetti quotidiani come la raccolta dei rifiuti, la manutenzione e il trasporto pubblico. I senzatetto abbondano ma non gli viene preclusa la modifica cibernetica, dando luogo a dipendenza cosmetica e conseguente violenza.
Il gioco inizia con la selezione di uno dei tre percorsi di vita per il personaggio V controllato dal giocatore: Nomade, vita da strada o Corporativo. Tutti e tre i percorsi coinvolgono V che inizia una nuova vita a Night City con il delinquente locale Jackie Welles (Jason Hightower) ed il netrunner, T-Bug.
Nel 2077, il fixer locale Dexter DeShawn (Michael-Leon Wooley) assume V e Welles per rubare un biochip noto come “il relic” dalla Arasaka Corporation. Dopo esserne entrati in possesso, il piano va storto quando assistono all’omicidio del leader della megacorp Saburo Arasaka (Masane Tsukayama) per mano del figlio traditore Yorinobu (Hideo Kimura). Yorinobu insabbia l’omicidio come un avvelenamento ed avvia un intervento della sicurezza dove T-Bug verrà uccisa dai netrunner dell’Arasaka. V e Welles fuggono, ma Jackie viene ferito a morte e la custodia protettiva del Chip viene danneggiata, costringendo V a inserire il biochip nel cyberware della sua testa….
Il gioco è in grado di sfruttare le ultime DirectX 12, oltre che il ray-tracing dei riflessi, ombre e illuminazione tramite API DirectX Raytracing (DXR) e la tecnologia Deep Learning Super-Sampling (DLSS) di NVIDIA.

I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:
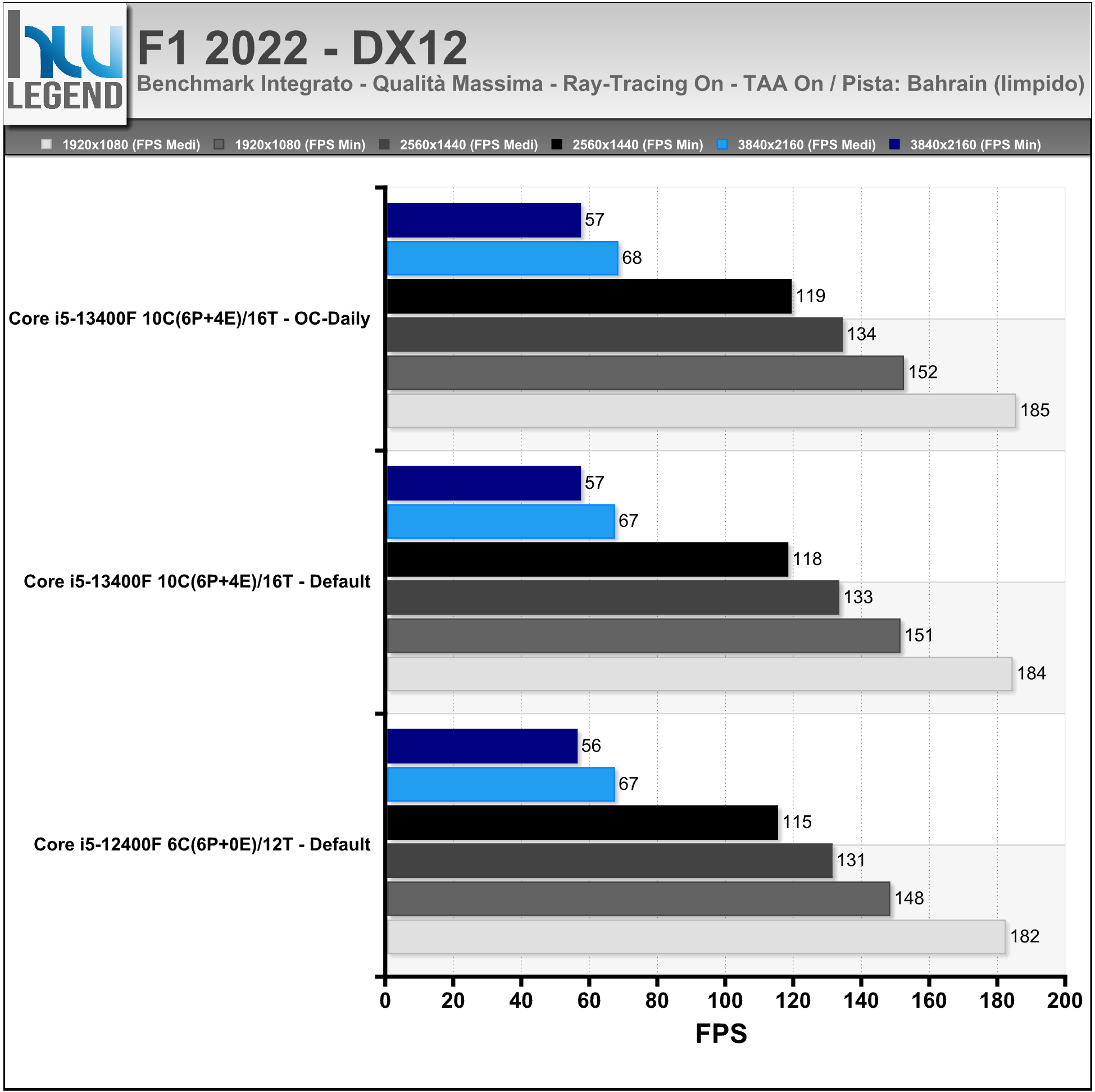
F1 22 (o anche Formula 1 2022) è un videogioco di guida sviluppato da Codemasters, ed uscito il primo luglio 2022. È il secondo capitolo della serie distribuito da EA Sports, dopo aver acquisito Codemasters a metà febbraio 2021. È basato sul campionato mondiale di Formula 1 2022 e sui campionati di Formula 2 2022 e 2021.
Il gioco, presentato lo scorso mese di giugno su PC, è in grado di sfruttare le API DirectX 12, oltre che il ray-tracing tramite API DirectX Raytracing (DXR) e la tecnologia Deep Learning Super-Sampling (DLSS) di NVIDIA.

I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:
Circa due mesi dopo la sua precedente avventura, Lara Croft e il suo amico Jonah sono nuovamente sulle tracce della Trinità. Seguendo gli indizi lasciati dal padre di Lara, i due arrivano a Cozumel, in Messico, per spiare il capo della cellula locale, il dottor Pedro Dominguez; durante una spedizione in una tomba già visitata dall’organizzazione, Lara scopre alcune notizie circa una misteriosa città nascosta. Successivamente, camuffandosi con gli abiti tipici per il dia de los muertos, Lara riesce a seguire gli adepti della Trinità, scoprendo così che Dominguez è addirittura il capo dell’organizzazione e che è sulle tracce di una misteriosa reliquia nascosta in un tempio non ancora localizzato. Vivi momenti di pura azione, conquista nuovi luoghi ostili, combatti usando tattiche di guerriglia ed esplora tombe mortali in questa evoluzione del genere action survival.
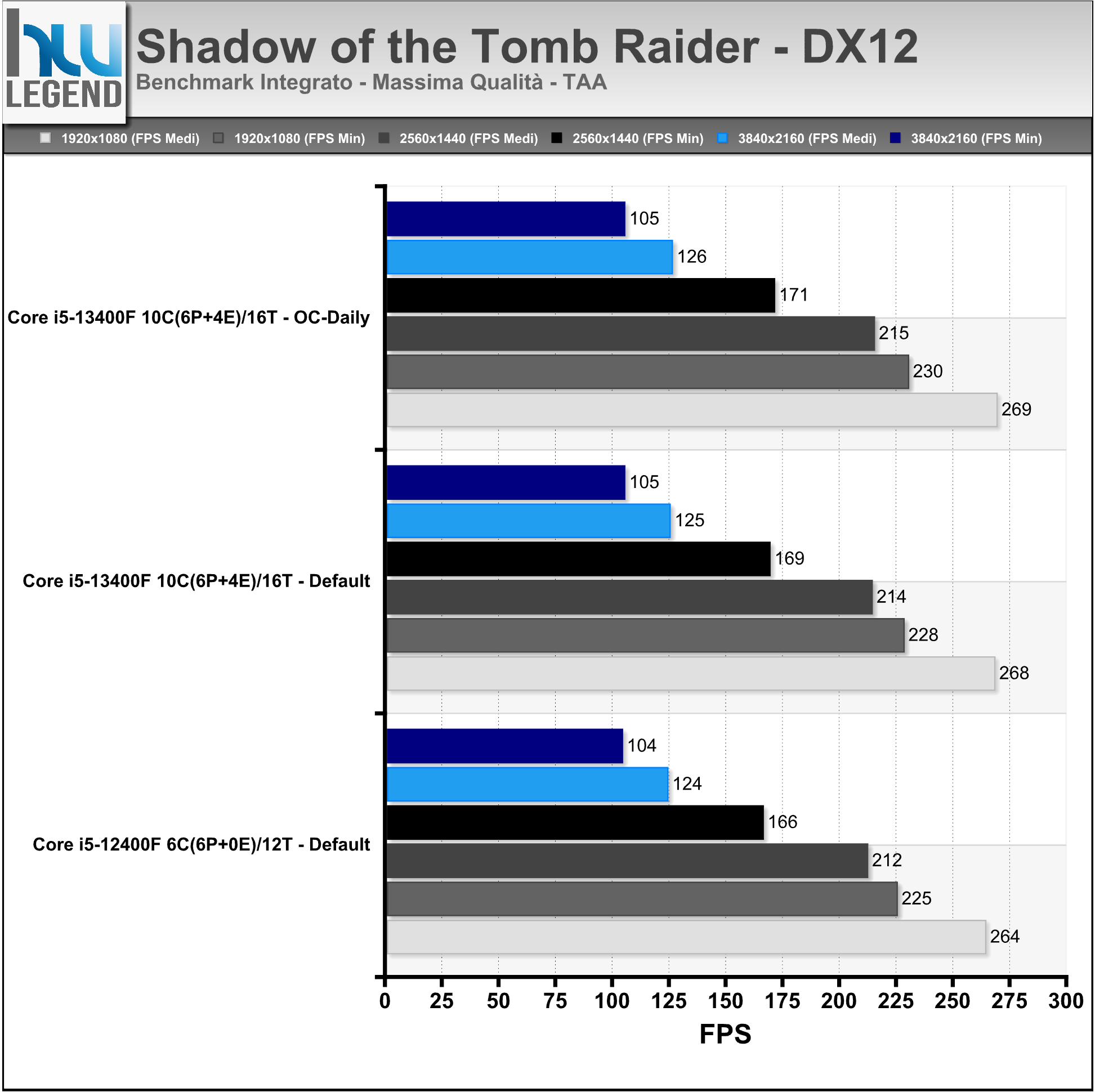
L’ultimo capitolo della saga (il settimo in ordine cronologico), presentato lo scorso mese di settembre su PC, è sviluppato dalla Crystal Dynamics e distribuito da Square Enix ed è in grado di sfruttare le ultime DirectX 12, oltre che il ray-tracing delle ombre tramite API DirectX Raytracing (DXR) e la tecnologia Deep Learning Super-Sampling (DLSS) di NVIDIA.

I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:

Watch Dogs: Legion è un videogioco di genere action-adventure sviluppato da Ubisoft Toronto e distribuito da Ubisoft il 29 ottobre 2020 su Microsoft Windows, PlayStation 4, Xbox One e Google Stadia, il 10 novembre su Xbox Series X e S, ed il 12 novembre su PlayStation 5. È il terzo capitolo della serie Watch Dogs e sequel di Watch Dogs 2.
Nel 2026, grazie a un sistema di sorveglianza avanzato noto come ctOS, il gruppo hacker londinese DedSec ha preso il controllo del Regno Unito nell’atto di combattere la Albion, società di sicurezza privata, il quale, influenzando il governo, ha creato uno stato autoritario. Per affrontarli, il gruppo potrà reclutare ogni cittadino di Londra, ognuno con le proprie capacità, problematiche e esperienze. Assoldandoli all’interno del DedSec per liberare la città, ogni personaggio nel gioco avrà le proprie abilità e fornirà un’influenza dinamica alla narrativa del gioco man mano che la storia avanzerà…
Il gioco è in grado di sfruttare le ultime DirectX 12, oltre che il ray-tracing dei riflessi tramite API DirectX Raytracing (DXR) e la tecnologia Deep Learning Super-Sampling (DLSS) di NVIDIA.

I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:
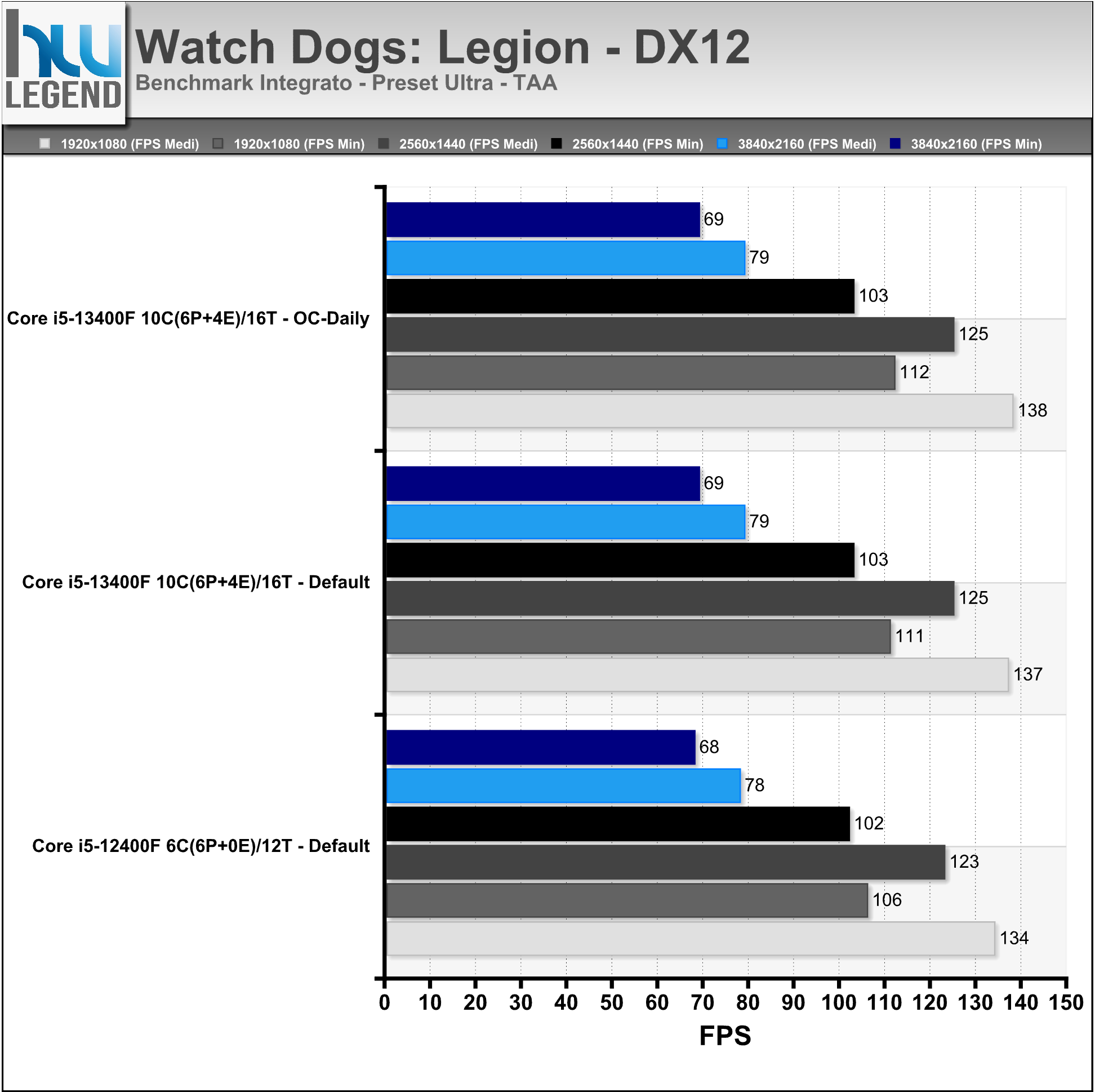
[nextpage title=”Temperature e Consumi Rilevati”]
In questa ultima sezione andremo osservare quello che è l’andamento delle temperature d’esercizio e dei consumi effettivi del nostro microprocessore, sia in condizione di riposo (Idle) e sia con differenti carichi di lavoro (Full-Load).
Per la registrazione dei dati abbiamo sfruttato le funzionalità di logging offerte dal noto programma HWiNFO64 7.60-5170, attualmente tra i più affidabili nelle rilevazioni.
Le misurazioni sono state ripetute più volte, nei grafici che seguiranno osserveremo le letture nelle seguenti condizioni:
- Idle con funzionalità di risparmio energetico attivate;
- Full-Load (Single-Thread) eseguendo il Cinebench R23 in loop (10min) in modalità Single-Core;
- Full-Load (Multi-Thread) eseguendo il Cinebench R23 in loop (10min) in modalità Multi-Core;
- Full-Load (Gaming) eseguendo il benchmark integrato nel gioco Metro Exodus Enhanced Edition a risoluzione 1080p (Maxed);
- Full-Load Stress eseguendo 30 minuti di Prime95 v30.8 build 17 in modalità Small-FFTs.
Prima di mostrarvi però i grafici riepilogativi vi alleghiamo alcuni screenshot delle prove svolte, sia con i limiti di potenza predefiniti da Intel per il microprocessore Core i5 13400F in esame (PL1=65W/PL2=148W) e sia con tali limiti rimossi manualmente (PL1/PL2=Disabled), così che possiate eventualmente estrapolare ulteriori informazioni utili:
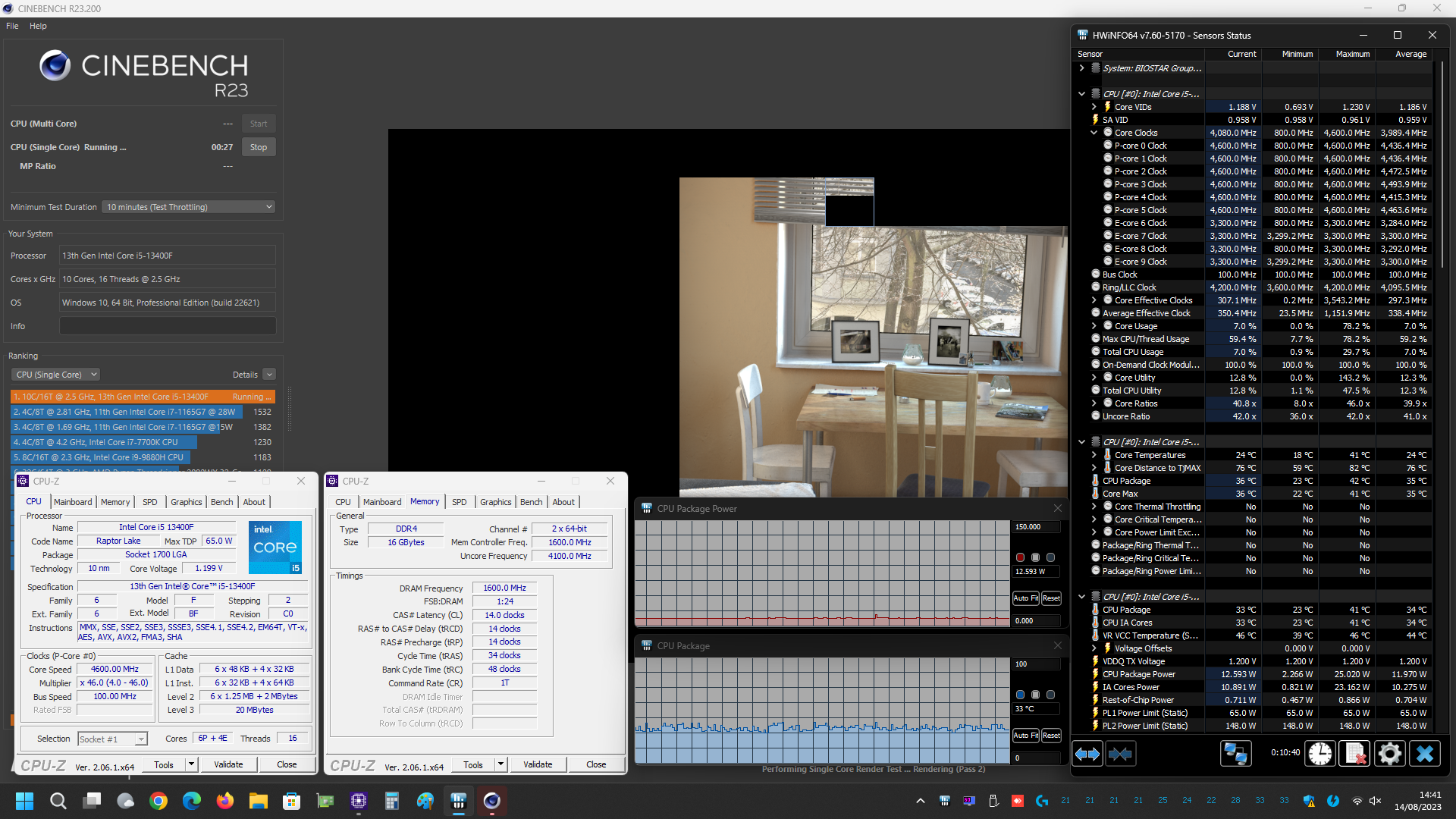
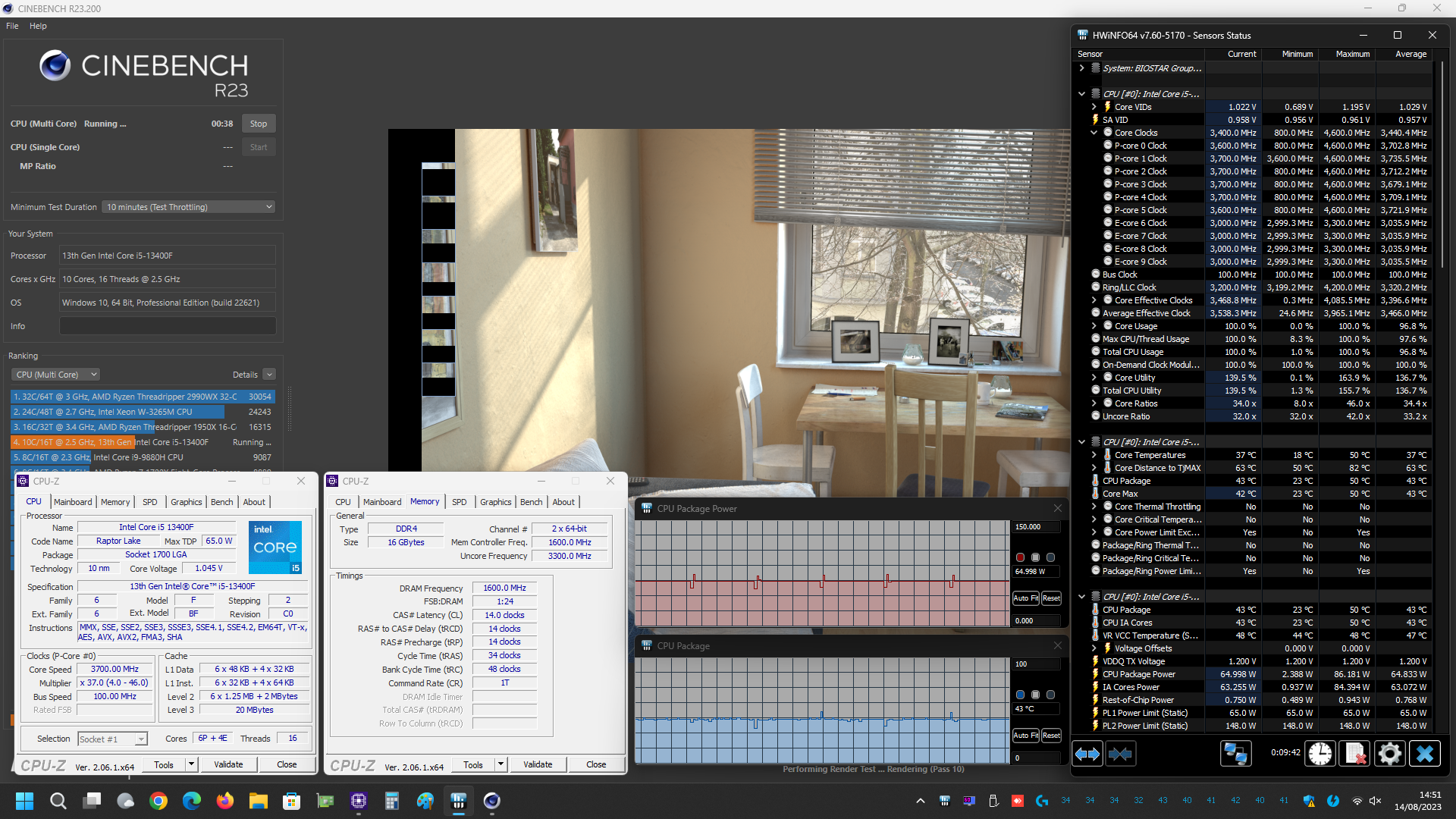
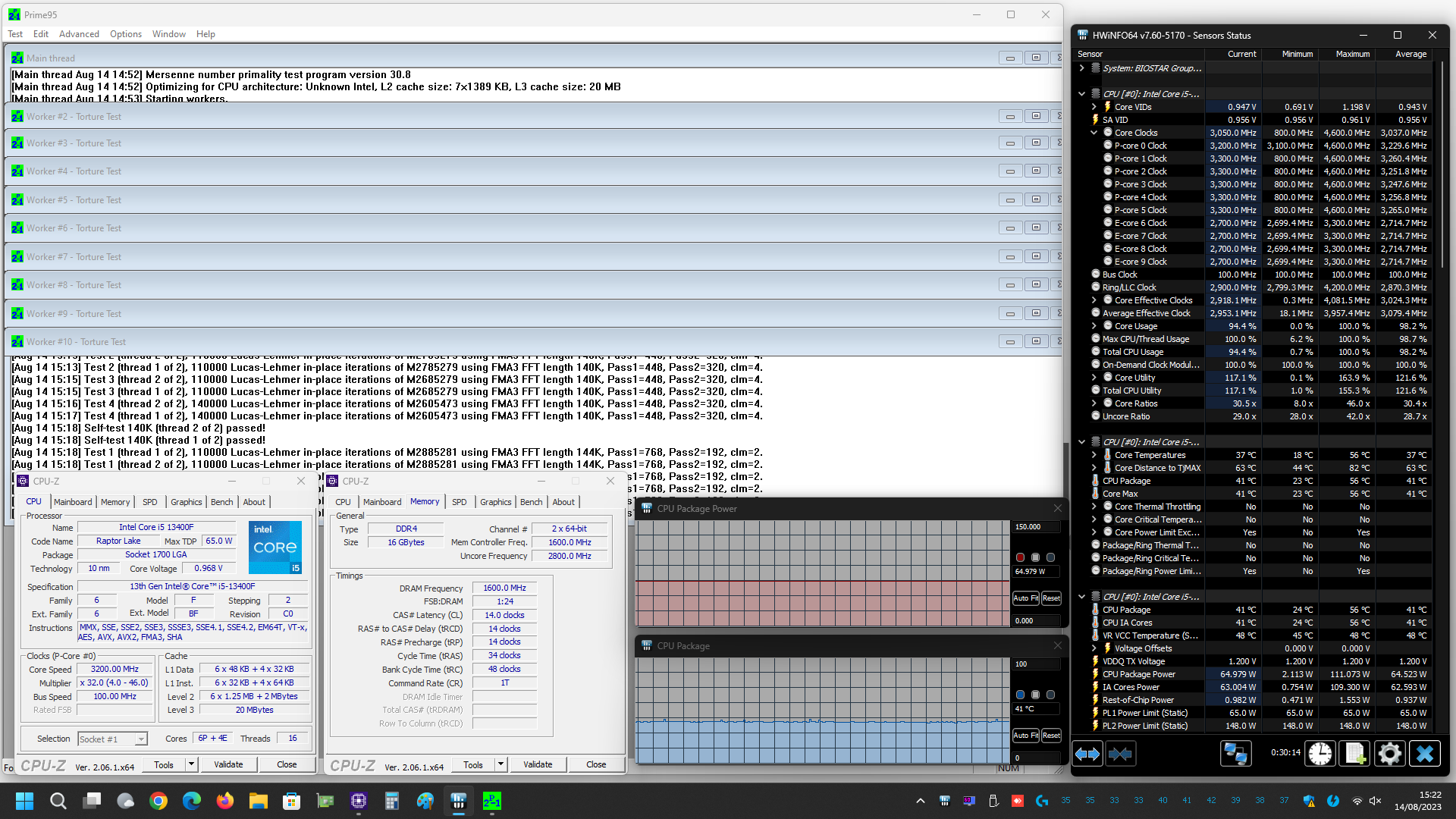
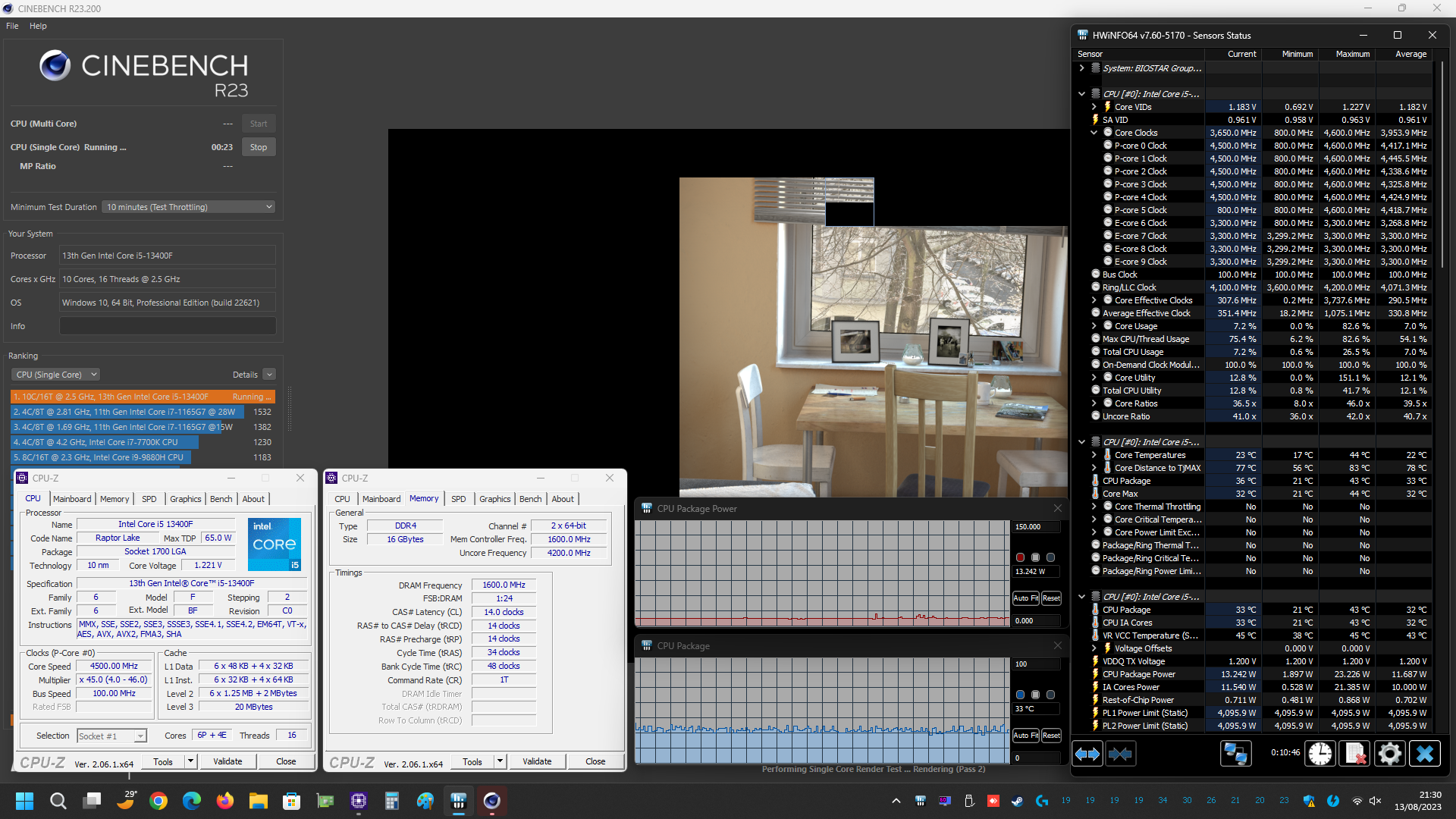
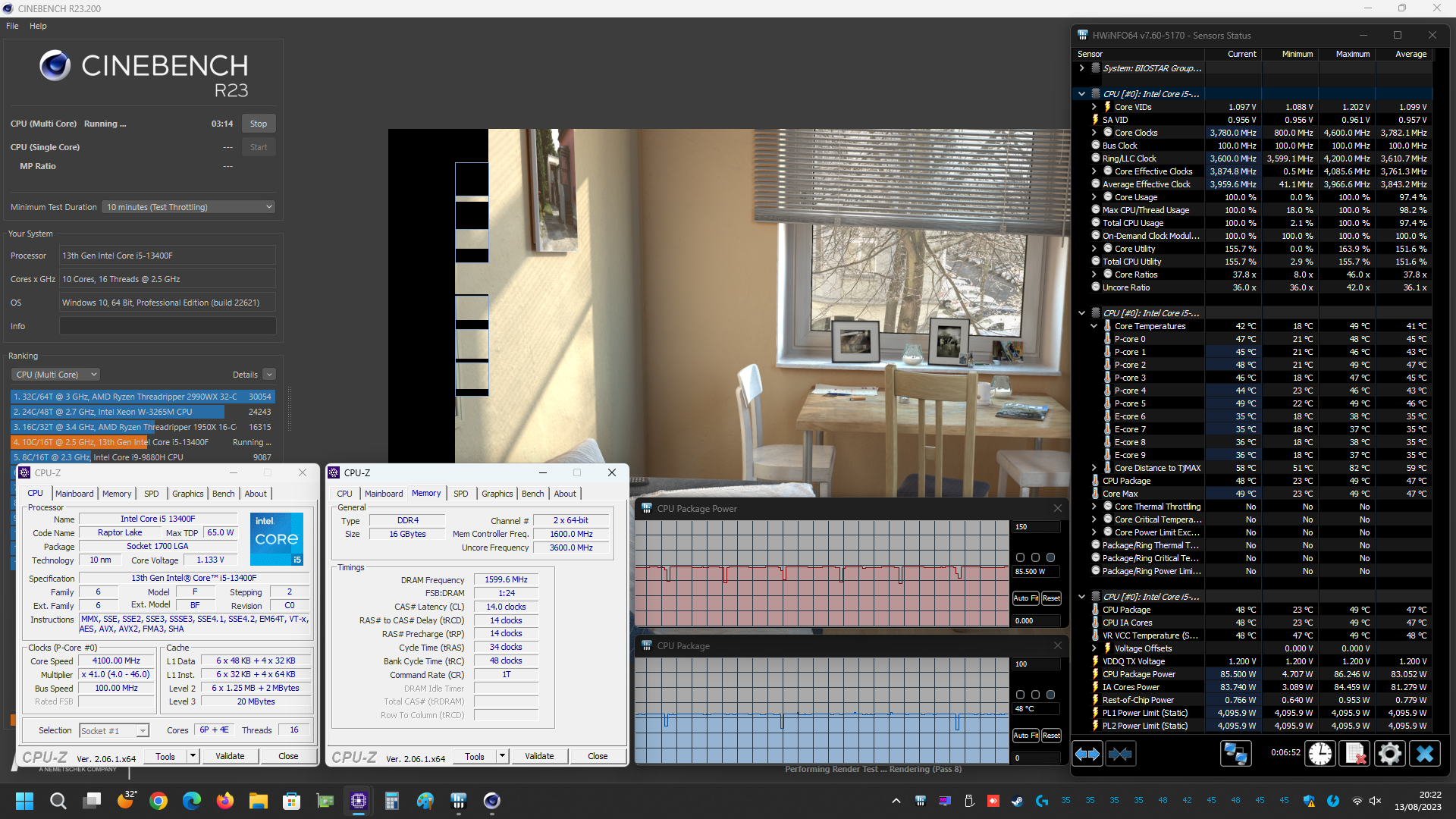
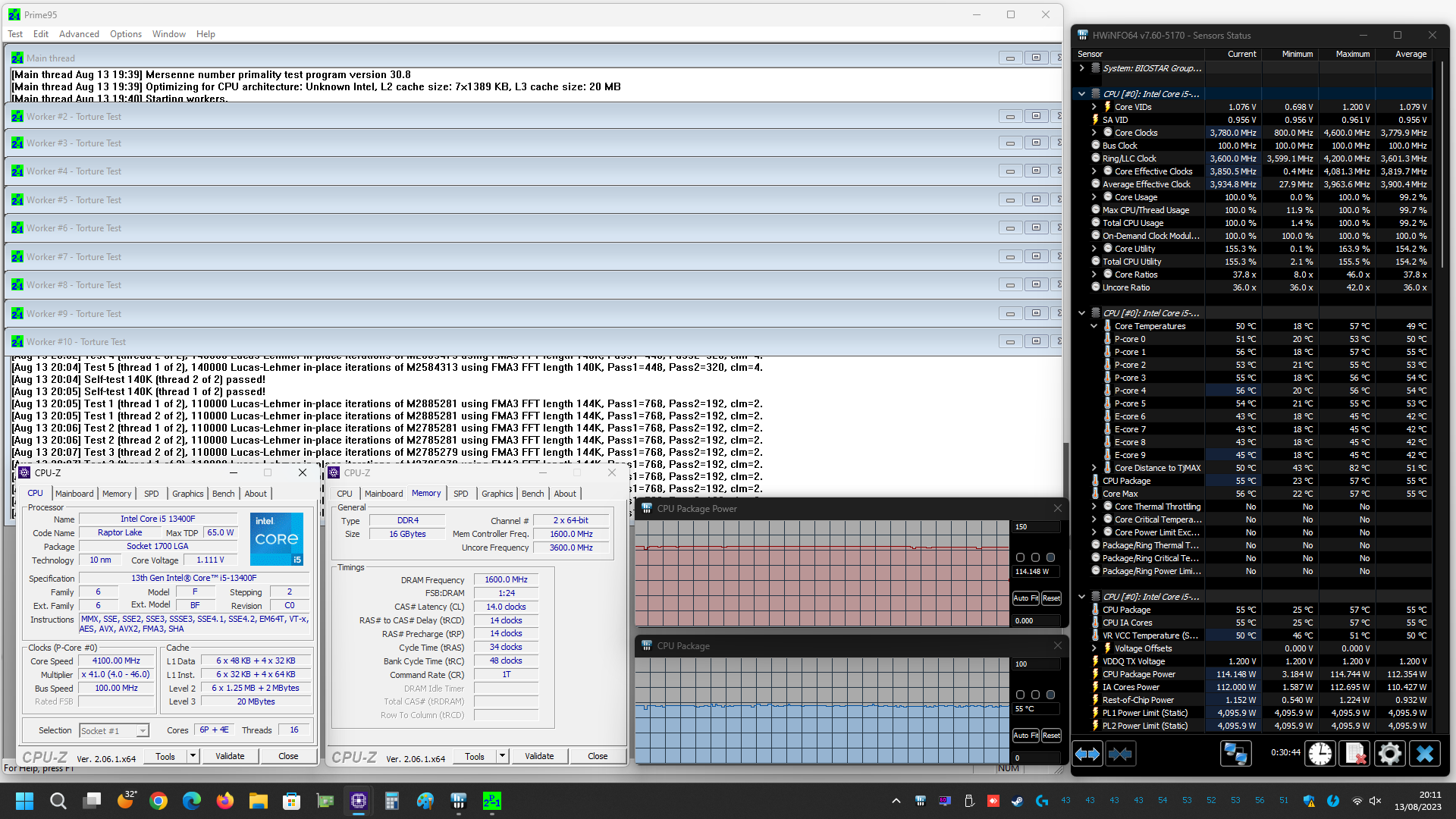
Grafico Andamento Temperature Rilevate (CPU Package Temp)
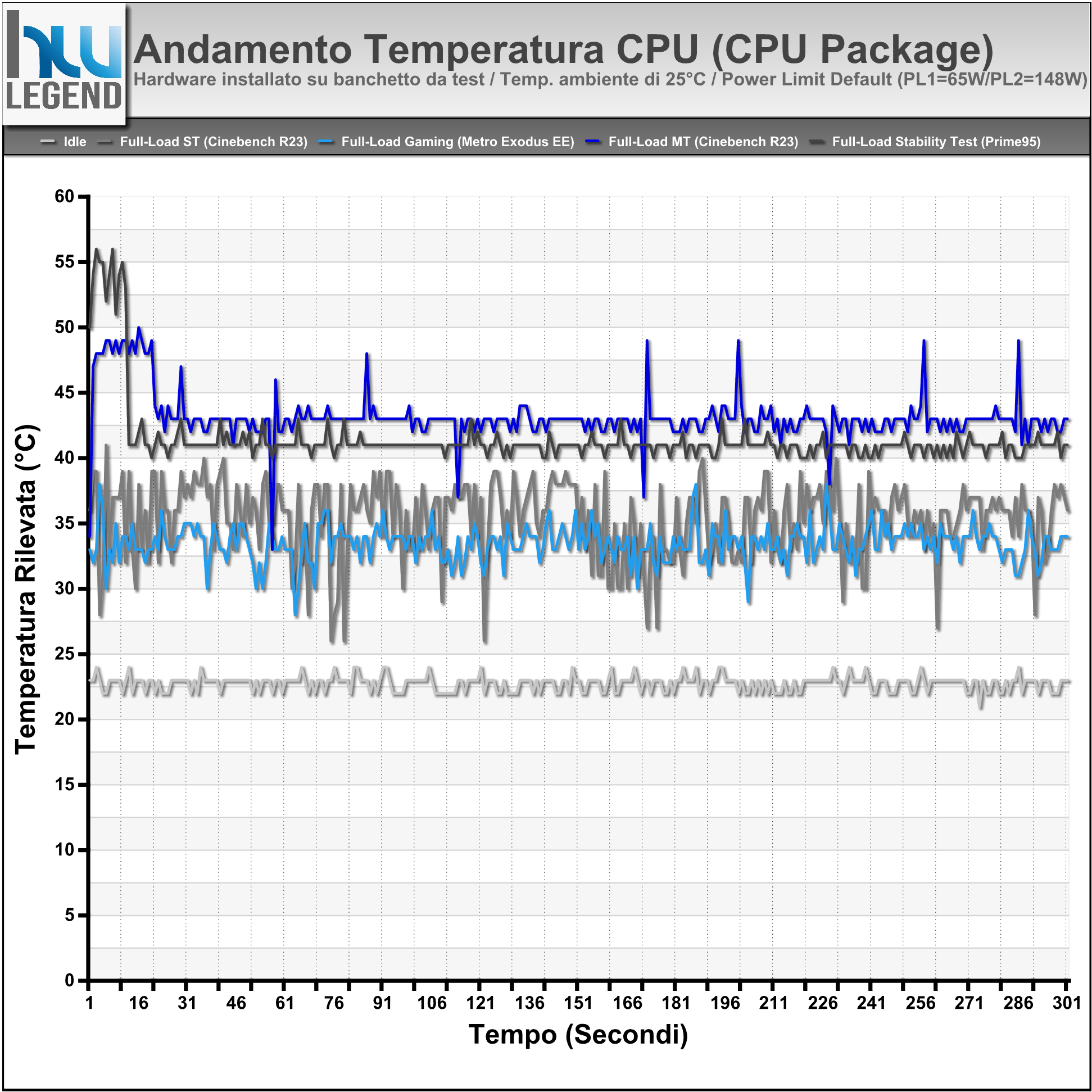
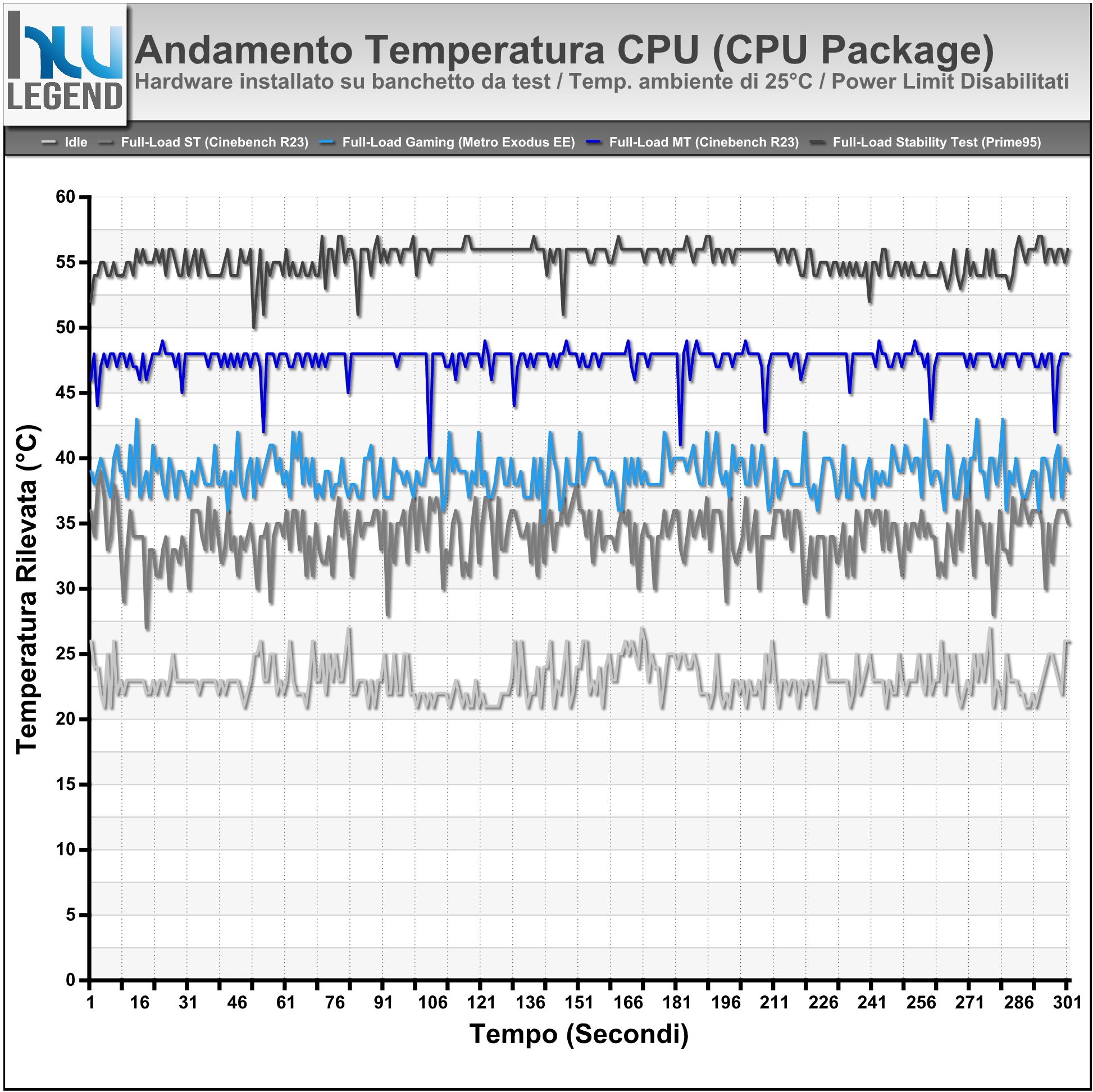
Per l’esecuzione delle nostre prove ci siamo affidati, come di consueto, su di un sistema di raffreddamento a liquido di tipo custom, con hardware installato su di un classico banchetto da test. È doveroso quindi evidenziare come questo genere di soluzione sia indubbiamente in grado di assicurare temperature sensibilmente inferiori rispetto a quelle potenzialmente ottenibili facendo uso di un tradizionale chassis e/o di sistemi di dissipazione ad aria o liquido All-in-One (AIO).
Come osserviamo dai grafici le temperature si mantengono su livelli veramente molto bassi, aspetto che non fa che confermare l’ottima efficienza nello scambio del calore tra Die e IHS, grazie alla particolare saldatura prevista ormai su tutta la line-up mainstream dell’azienda.
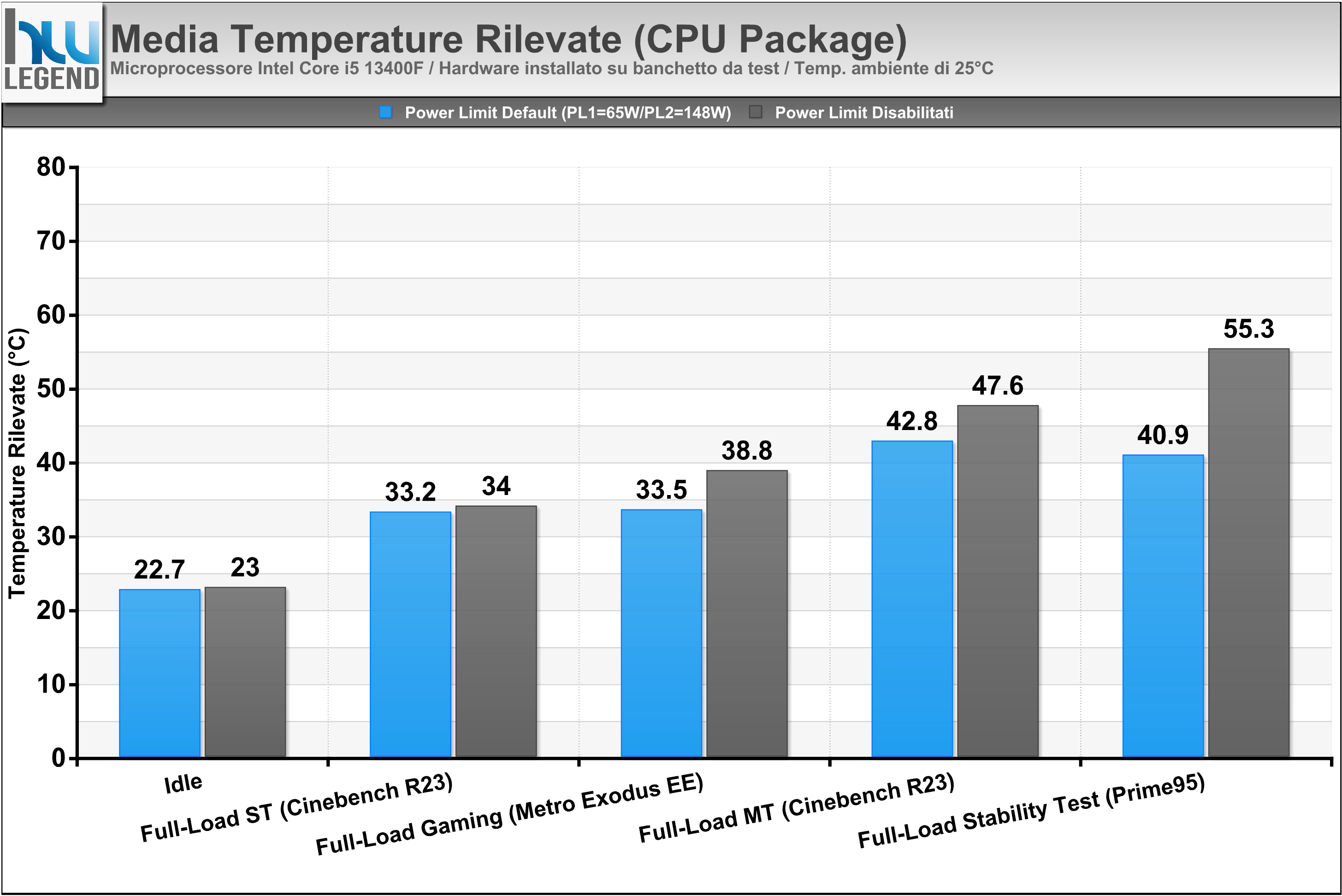
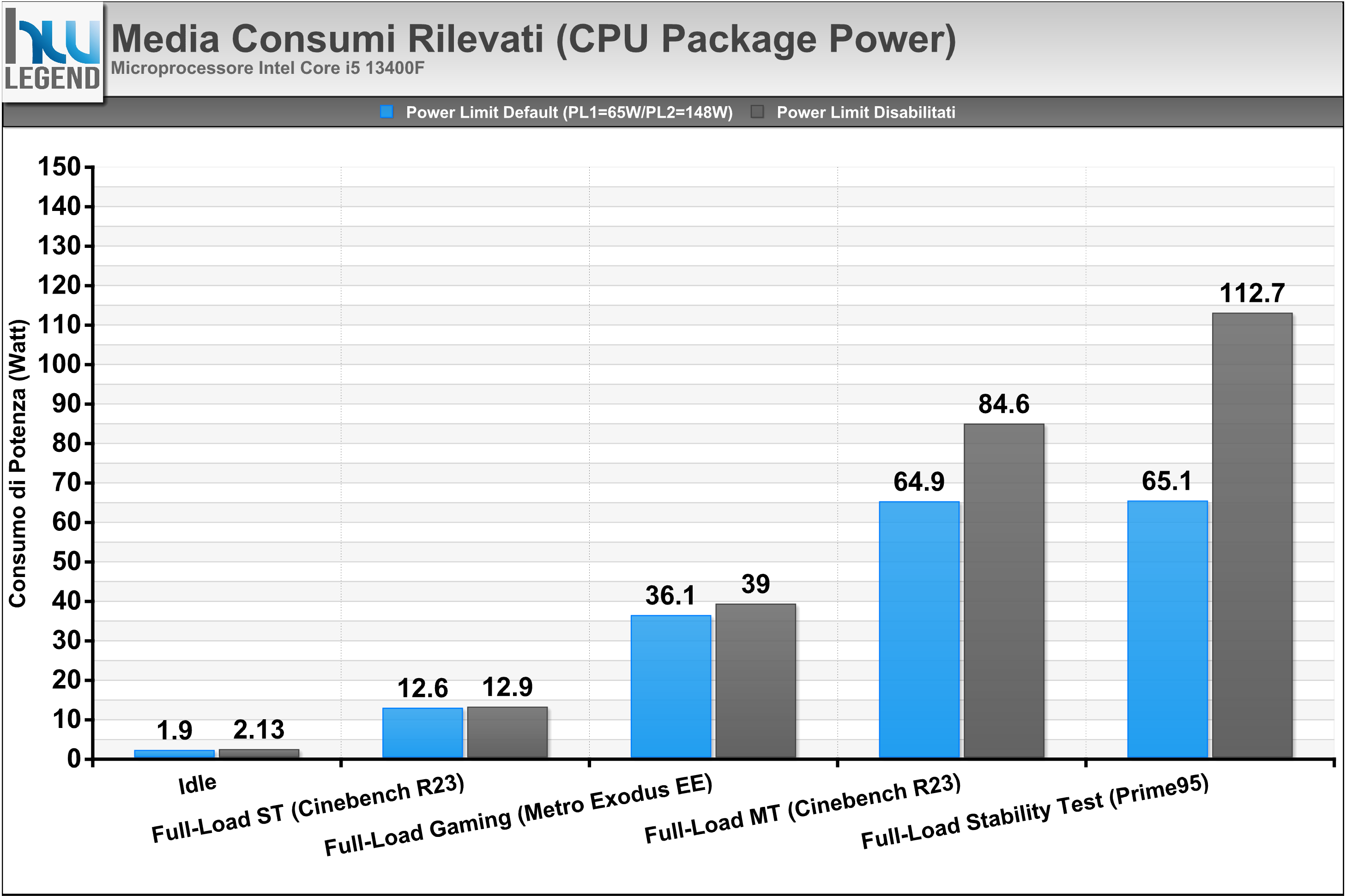
Grafico Andamento Potenza Rilevata (CPU Package Power)
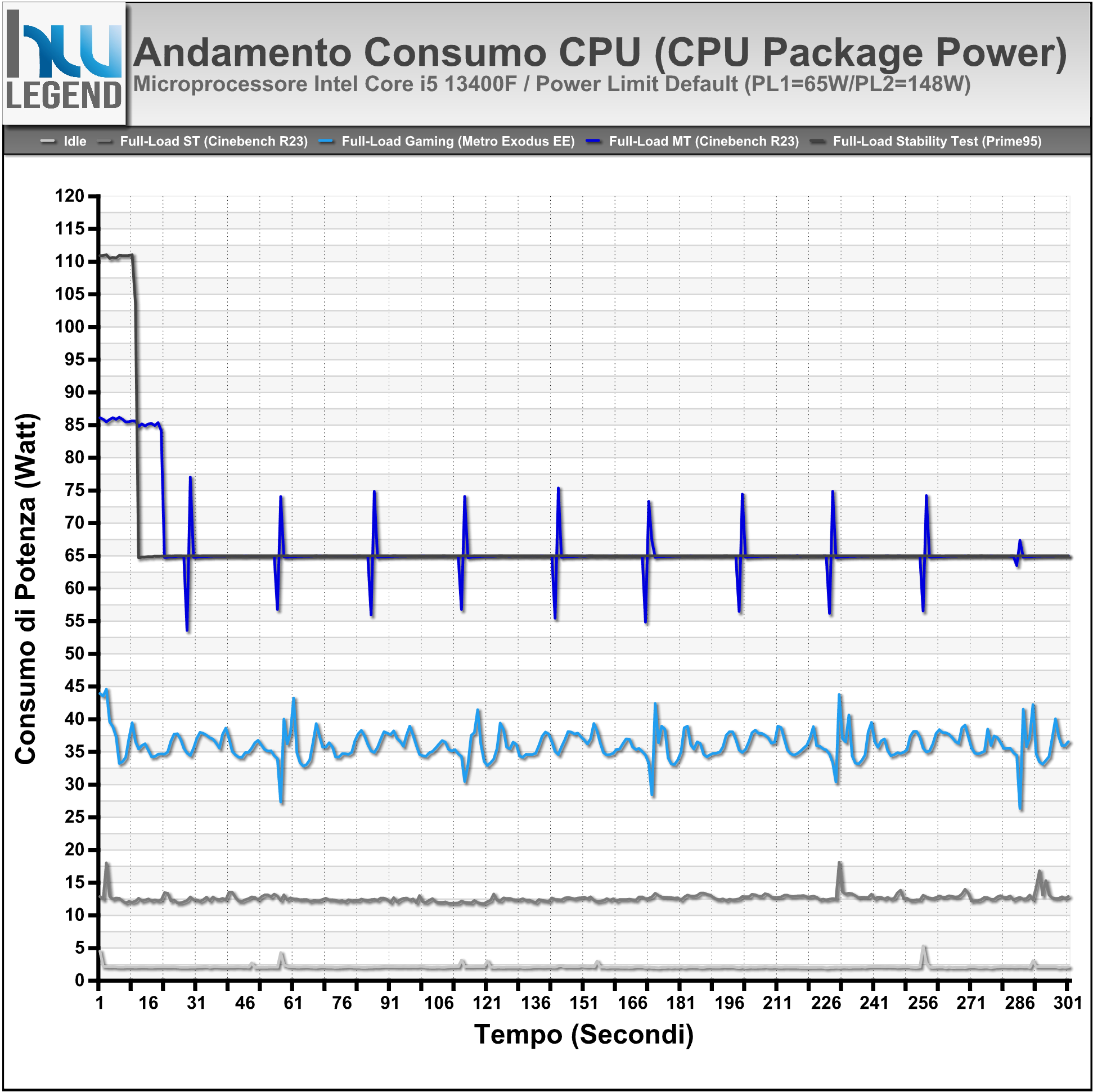
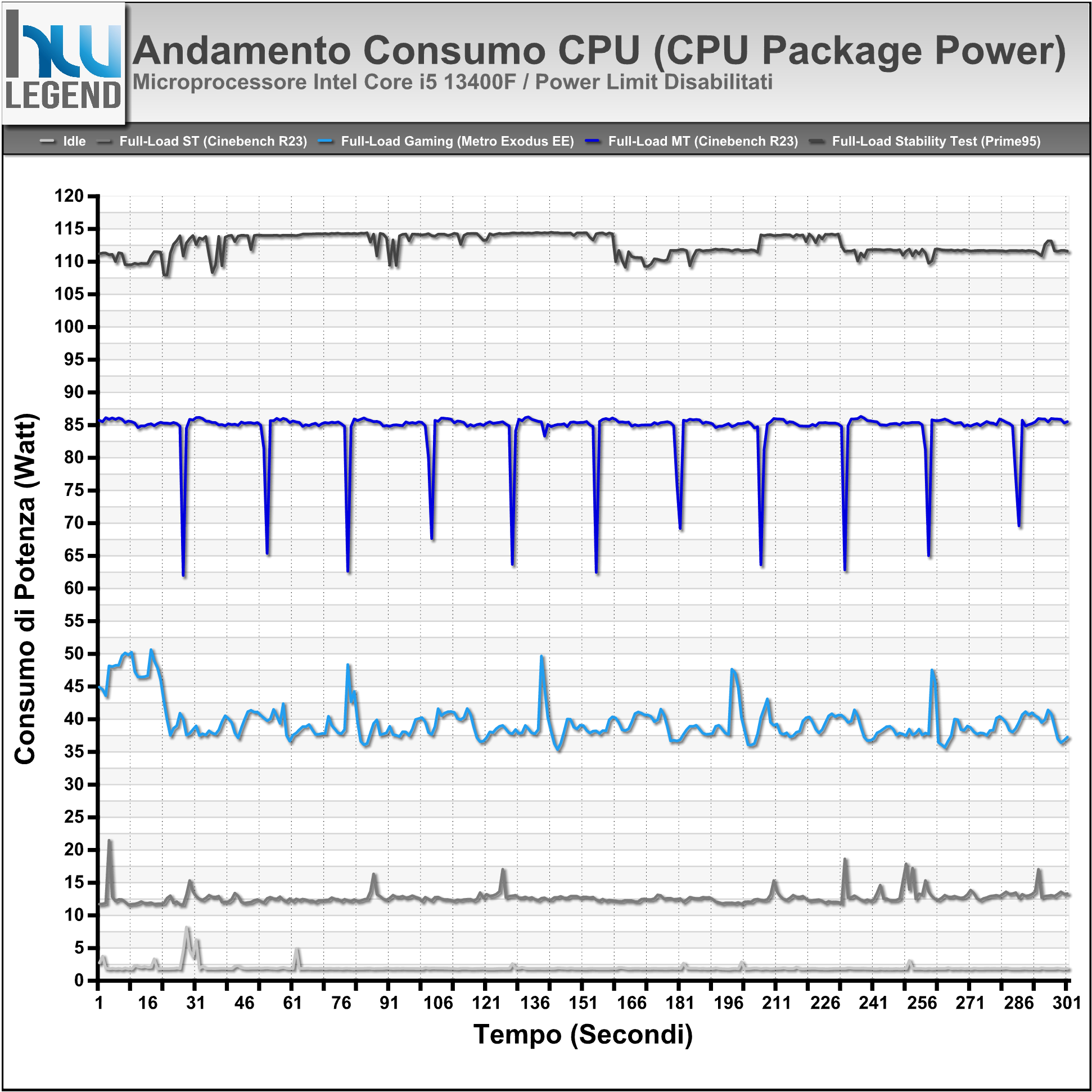
Anche le misurazioni in termini di consumo non fanno che confermare la bontà e l’efficienza della soluzione Core i5 in esame, con valori che si dimostrano del tutto contenuti in relazione alle performance velocistiche offerte.
Soffermandoci per un momento sulle prove condotte con i limiti di potenza predefiniti, nello specifico con Processor Base Power (PBP) fissato pari a 65W (ex PL1) e Maximum Turbo Power (MTP) pari a 148W (ex PL2), osserviamo che il microprocessore raggiunge ugualmente i valori ottenuti, al contrario, con tali limiti rimossi manualmente all’interno del BIOS della scheda madre, ma li riesce a mantenere solamente per pochi secondi.
Questo comportamento, che osserviamo più marcatamente con carichi di lavoro maggiormente impegnativi, come il Cinebench R23 eseguito in modalità Multi-Core oppure il Prime95 in modalità Small-FFTs, è del tutto normale e previsto dalla stessa Intel in fase di progettazione del microprocessore. Gli algoritmi alla base del funzionamento del Turbo Boost, infatti, prevedono che in alcune circostanze, e per un periodo di tempo limitato, possa essere oltrepassato il valore di potenza di base (il suddetto Processor Base Power), al fine di assicurare un sensibile incremento prestazionale durante elaborazioni breve durata, grazie al mantenimento più prolungato di frequenze di clock più elevate. A lungo termine, tuttavia, tutto tornerà automaticamente alla normalità e nel pieno rispetto dei limiti di potenza.
Mantenendo l’impostazione predefinita viene certamente assicurata la massima efficienza dal punto di vista del rapporto tra prestazioni e consumo di potenza effettivo. Nel grafico che segue vi mostriamo una stima dell’efficienza del nuovo Core i5 13400F, espressa in termini di “Punti per Watt”, calcolata sulla base dei risultati ottenuti eseguendo il software Cinebench R23 sia in modalità Single-Core che in Multi-Core.
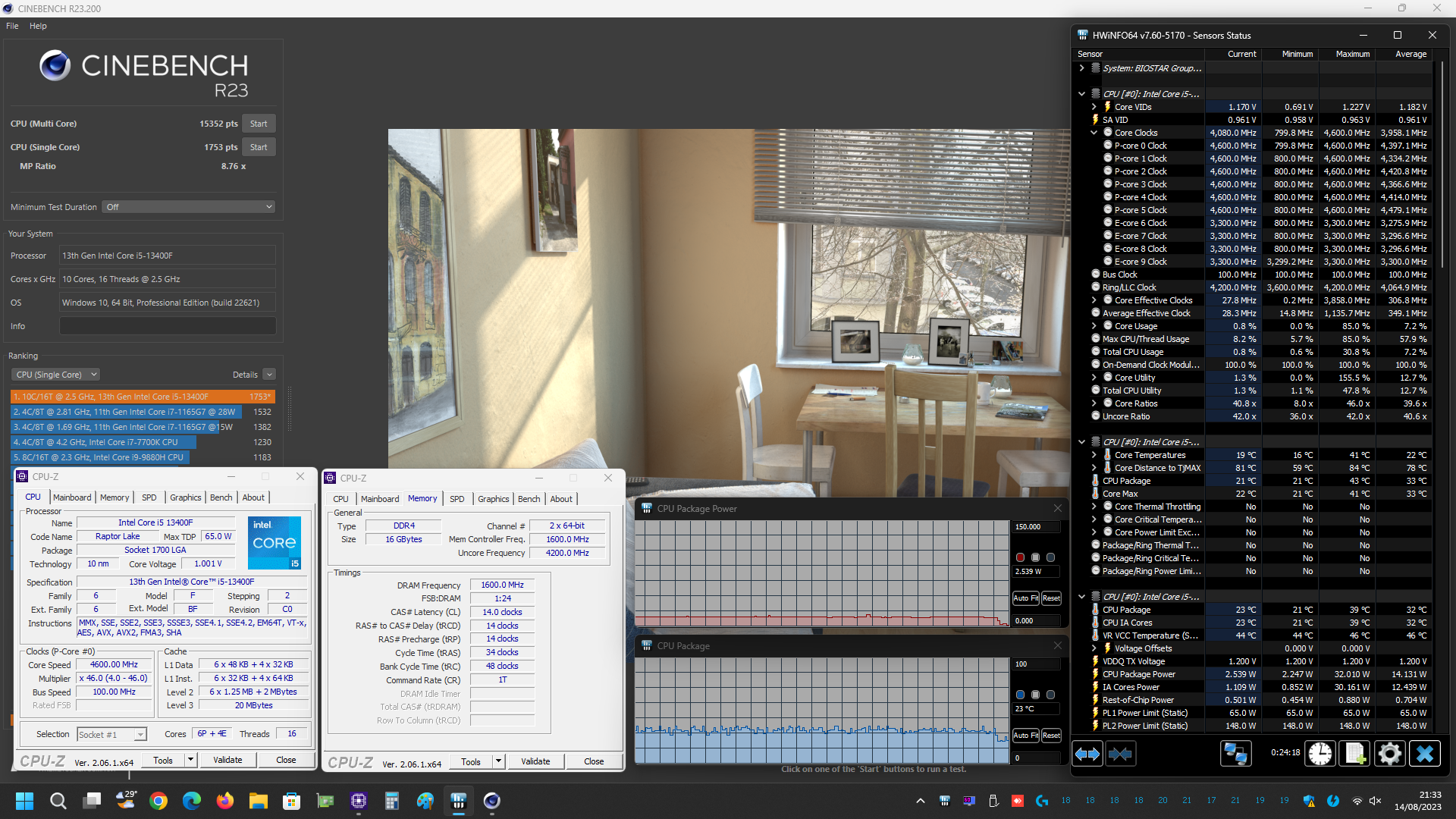
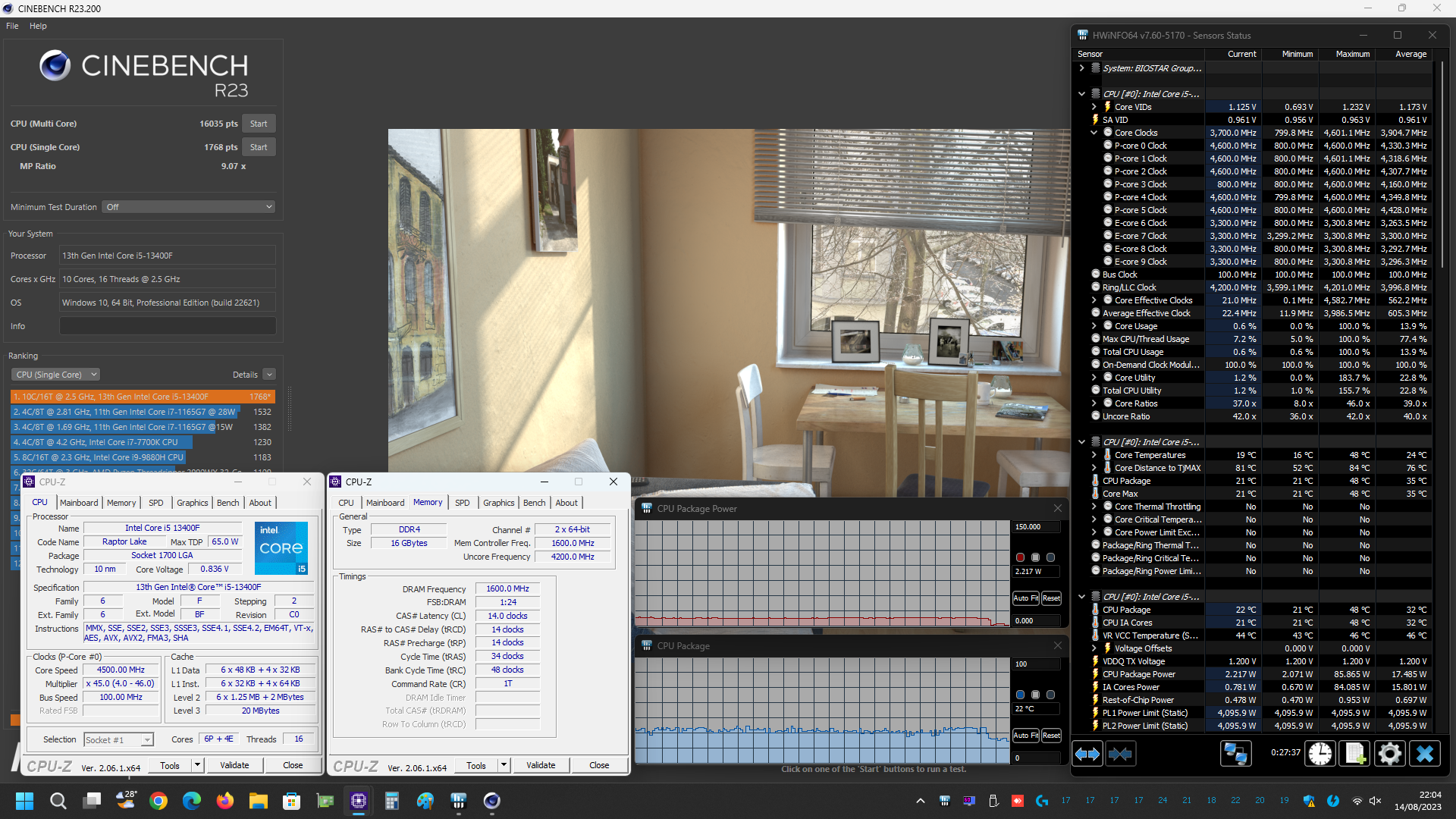
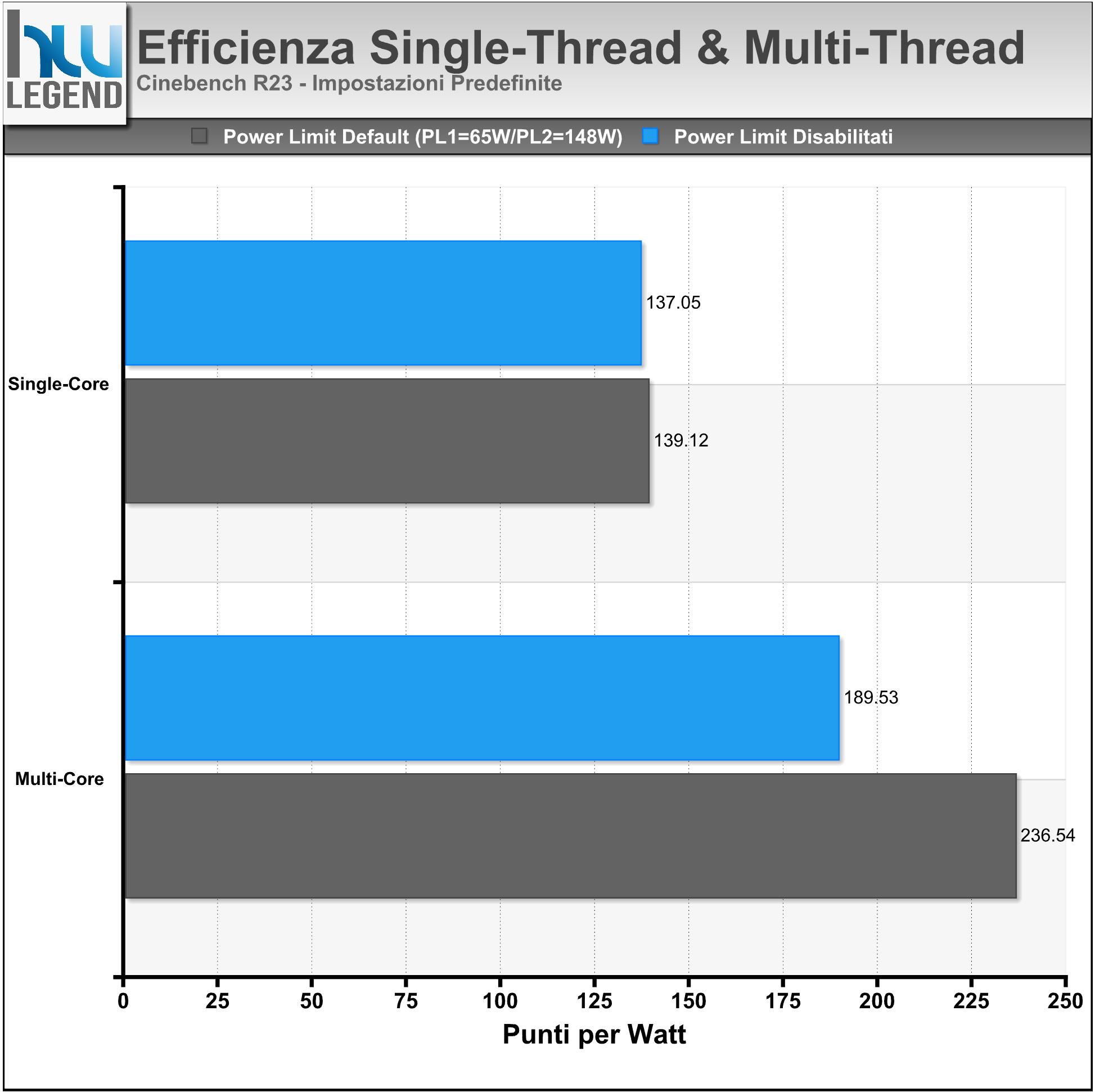
Come prevedibile la maggiore efficienza la si ottiene con carichi di lavoro multi-thread, dove la rimozione dei limiti di potenza assicura per ovvi motivi un aumento delle prestazioni, ma inferiore rispetto al consumo medio effettivo che comporta il mantenimento di frequenze di clock più elevate. L’impostazione dei parametri energetici operativi di default, al contrario, comporta un’esigua riduzione delle prestazioni MT, quantificabile nell’ordine del 4%, a fronte però di un abbattimento dei consumi pari al 23%.
[nextpage title=”Conclusioni”]
Ed eccoci giunti al capitolo conclusivo di questo nostro articolo, in cui abbiamo avuto modo di toccare con mano le potenzialità offerte dal nuovo microprocessore Core i5 13400F, una soluzione che, come osservato, appare indiscutibilmente molto interessante, tanto dal punto di vista prettamente prestazionale, quanto in termini di pura efficienza. L’azienda statunitense, con questo particolare modello, che ricordiamo essere privo di componente grafica integrata attiva, si rivolge espressamente a tutti coloro che intendono realizzare una configurazione bilanciata ed in grado di garantire una buona esperienza d’uso a 360° pur senza dover necessariamente affrontare un notevole esborso di denaro.
Alla base di questo microprocessore troviamo l’innovativa architettura ibrida ad elevate prestazioni di Intel, considerata dalla stessa come una svolta epocale nel mondo dei microprocessori desktop x86, in grado di alzare l’asticella ad un livello superiore, in termini di scalabilità ed efficienza, rispetto agli approcci più tradizionali, grazie alla presenza di due differenti tipologie di core nello stesso Die.
Precisamente troveremo una serie di core altamente performanti, denominati per l’appunto Performance-Core (o P-Core), espressamente pensati per dare il meglio in ambiti single-thread, per i quali alte frequenze e IPC (Istruzioni per Ciclo) ricoprono un ruolo di fondamentale importanza, basti pensare al gaming o alla produttività; ed altri core più semplici, denominati Efficient-Core (o E-Core), messi a punto allo scopo non solo di massimizzare l’efficienza in tutti quegli scenari che prevedono carichi altamente parallelizzabili, lavorando in concerto con i P-Core, come ad esempio facendo uso di software di rendering, ma anche di farsi carico delle varie operazioni in background meno esigenti, come la sincronizzazione della posta o la gestione del software antivirus, sgravando così i P-Core da una notevole mole di calcoli al fine di poter contare sulle loro piene potenzialità laddove siano veramente capaci di fare la differenza.
Tuttavia, il nuovo Core i5 13400F, pur presentandosi all’appello con credenziali di tutto rispetto, ben 6 P-Core e 4 E-Core integrati per un totale di ben 16 Thread, ci lascia con poco di amaro in bocca a causa dell’assenza di tutte le migliorie architetturali introdotte con le soluzioni Raptor Lake. Nello specifico, come osservato, questo specifico modello, seppur rappresentando un valido upgrade rispetto alla proposta equivalente della passata generazione (ci riferiamo ovviamente all’aggiunta di un cluster E-Core completo, precedentemente assente nel Core i5 12400), ne condivide le caratteristiche architetturali di base, compresa l’architettura dei P-Core che a dispetto delle apparenze rimane quella delle soluzioni Alder Lake (Golden Cove). Allo stesso modo, il cluster Gracemont potrà disporre di 2MB di memoria Cache L2 condivisa, e non i 4MB previsti nelle altre soluzioni di tredicesima generazione.

Di conseguenza, in alcuni particolari scenari, tra cui il gaming, il minor quantitativo di memoria cache a disposizione dei core comporterà una sensibile riduzione delle prestazioni, che si manterranno più vicine ai livelli delle soluzioni della passata generazione che non a quelle delle ultime proposte del marchio. Con questo non vogliamo in alcun modo sottintendere che il nuovo modello sia scarso in senso assoluto, anzi l’esatto opposto dal momento che stiamo pur sempre parlando di prestazioni più che soddisfacenti nonché superiori alla maggior parte delle proposte concorrenti di pari fascia.
La nostra suite di prova prevede l’utilizzo dei più noti e diffusi applicativi e giochi, scelti in maniera da poter offrire un quadro complessivo preciso ed affidabile delle performance velocistiche offerte dalla soluzione in esame. Osservando i risultati ottenuti appare innegabile il passo avanti rispetto al modello di pari fascia della passata generazione, soprattutto in multi-threading dove l’aggiunta di Efficient Core assicura un deciso aumento delle prestazioni complessive. Al contrario, con carichi di lavoro prettamente single-thread, la differenza appare di gran lunga più contenuta, del resto, come sottolineato, non si evidenziano differenze in termini architetturali, ma solamente un leggero aumento della frequenza di clock.
A tutto questo si aggiunge il prezzo altamente competitivo che contraddistingue da sempre i microprocessori di classe Core i5-x400, nonché tutta una serie di vantaggi che l’azienda mette a disposizione dell’utenza più affezionata.
Per prima cosa la possibilità di poter utilizzare qualsiasi scheda madre della passata generazione, dal momento che viene mantenuta la piena compatibilità con tutti i PCH appartenenti alla serie 600. Oltre a questo, non va in alcun modo sottovalutato il supporto verso i moduli di memoria ad elevate prestazioni DDR4, aspetto che permetterà a molti utenti di contenere, e non di poco, la spesa complessiva per l’assemblaggio del nuovo sistema, magari riutilizzando KIT già in loro possesso.

In questo momento storico più che mai, inoltre, tutti noi stiamo assistendo impotenti ad un aumento medio del costo dell’energia che non sembra volersi fermare. In considerazione di questo non possono che far piacere soluzioni, come quella in esame, contraddistinte da un’elevata efficienza in termini prettamente energetici, capaci quindi di incidere positivamente sulla bolletta.
Non solo, minori consumi si traducono anche in un minor sviluppo di calore, assicurando temperature d’esercizio notevolmente più basse. Come abbiamo osservato nella sezione dedicata, infatti, il nuovo Core i5 13400F si è dimostrato essere un microprocessore particolarmente fresco in ogni ambito di utilizzo, anche il più gravoso a cui è stato sottoposto. Questo consentirà all’utente di poter eventualmente sfruttare il dissipatore di calore fornito in dotazione, più che adeguato allo scopo, oppure di potersi affidare a soluzioni di raffreddamento alternative in ogni caso meno spinte, andando a contenere ulteriormente la spesa finale. Oltre a questo, sarà possibile prendere in considerazione questo microprocessore per la realizzazione di sistemi con fattore di forma ridotto, spesso contraddistinti da spazi interni più risicati e minori potenzialità in termini di airflow.
Il nuovo Intel Core i5 13400F è disponibile su Amazon Italia al prezzo di 233,20€ IVA compresa, cifra certamente molto interessante ed estremamente competitiva, ancor più se consideriamo le caratteristiche tecniche e le indubbie potenzialità offerte da questo prodotto, che lo rendono preferibile, a nostro avviso, rispetto alle soluzioni concorrenti di pari fascia, anche grazie alla possibilità, come precisato, di potersi affidare a moduli di memoria DDR4, ormai reperibili a basso costo, o addirittura magari già in proprio possesso. Ricordiamo che questo particolare modello non dispone della componente grafica integrata attiva, come si evince dalla presenza del suffisso “F” nella nomenclatura; di conseguenza occorrerà prevedere una soluzione grafica discreta nella propria configurazione.
Pro:
- Basato sull’innovativa architettura ibrida ad elevate prestazioni;
- Avanzata tecnologia produttiva proprietaria a 10 nanometri, denominata Intel 7;
- Eccellente efficienza dal punto di vista energetico;
- Presenza di 6 P-Core e 4 E-Core integrati per un massimo di ben 16 Thread;
- Prestazioni velocistiche più che soddisfacenti sia con carichi di lavoro Single-Thread che Multi-Thread;
- Grazie all’aggiunta degli Efficient-Core viene assicurato un deciso passo avanti in MT rispetto alla soluzione di pari fascia della passata generazione che viene sostituita (Core i5 12400);
- Piena compatibilità con tutti i PCH serie 600 e serie 700;
- Memory Controller Integrato di tipo Duad-Channel con supporto verso moduli ad elevate prestazioni sia DDR4 che DDR5;
- Supporto PCI-Express Gen 5.0;
- Temperature d’esercizio sempre molto contenute;
- Buon dissipatore di calore proprietario fornito in dotazione;
- Ottime tecnologie proprietarie supportate;
- Rapporto prezzo/prestazioni estremamente interessante.
Contro:
- Nulla da segnalare.
Si ringrazia ![]()
![]() per il campione fornitoci.
per il campione fornitoci.
Gianluca Cecca – delly – Admin di HW Legend

![Cop - Kingston FURY Renegade G5 NVMe M.2 SSD 2TB [SFYR2S2T0]](https://www.hwlegend.tech/wp-content/uploads/2025/10/Cop-Kingston-FURY-Renegade-G5-NVMe-M.2-SSD-2TB-SFYR2S2T0-150x150.webp "Kingston FURY Renegade G5 NVMe M.2 SSD 2TB [SFYR2S/2T0]")



