




L’evoluzione dei modelli linguistici è accelerata significativamente negli ultimi anni. Ora gli utenti possono facilmente utilizzare modelli linguistici avanzati (LLM) tramite applicazioni come LM Studio.
Per chi lavora con queste applicazioni, un sistema in grado di gestire in modo efficiente i carichi di lavoro legati all’AI è fondamentale, e AMD punta a garantire proprio questo tipo di prestazioni.

LM Studio si basa sul progetto llama.cpp, un framework che permette una rapida implementazione degli LLM con design leggero, senza dipendenze e supporto per accelerazione sia su CPU che su GPU. Grazie all’uso delle istruzioni AVX2, LM Studio aumenta le prestazioni dei moderni LLM su CPU x86. Con gli APU Ryzen AI di AMD, gli utenti possono sfruttare queste capacità per accelerare lo sviluppo e l’implementazione delle applicazioni AI.
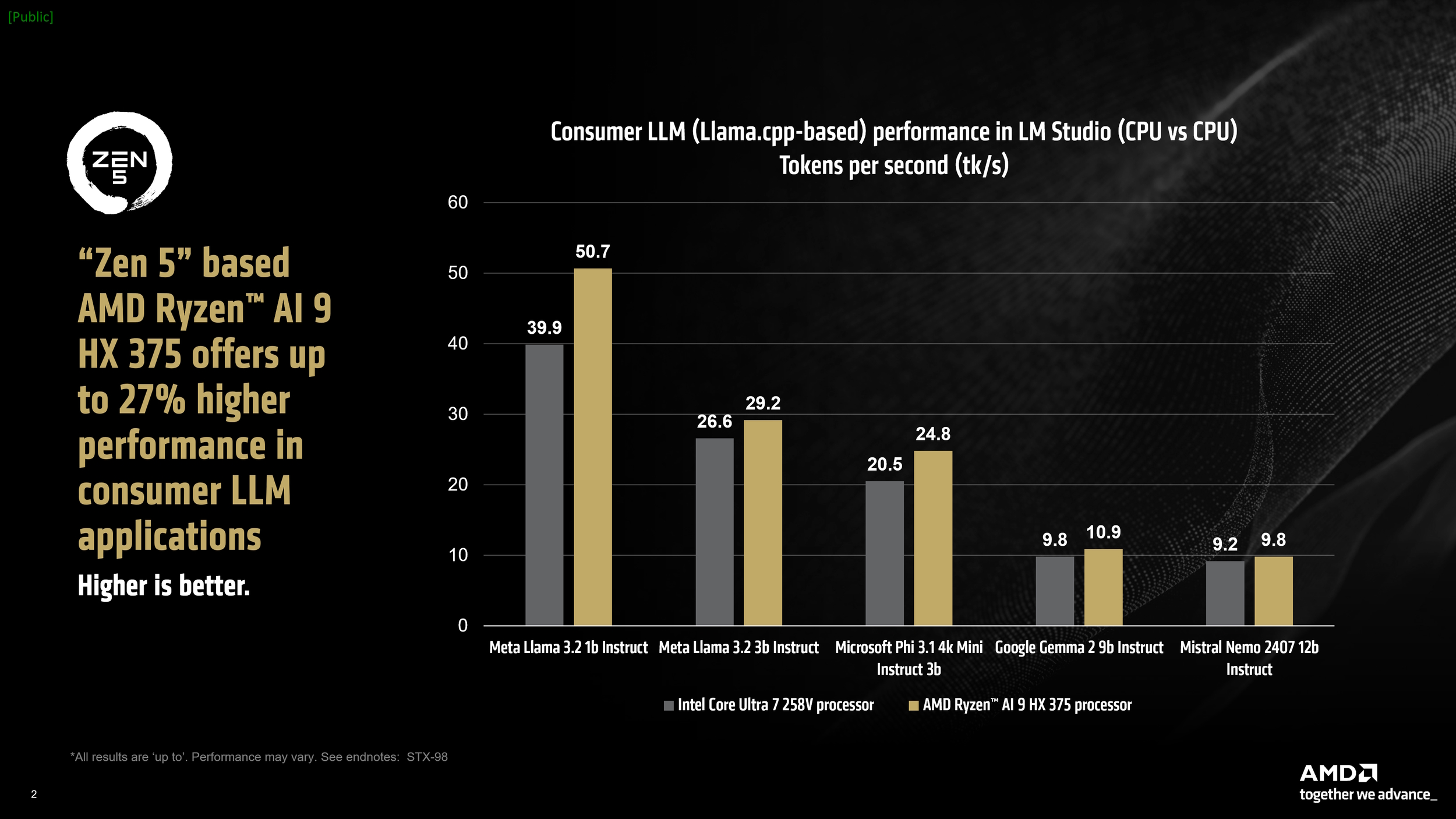
Come osservato da AMD, le prestazioni degli LLM sono sensibili alla velocità della memoria. Nei test, un laptop Intel a 8533 MT/s ha superato un laptop AMD a 7500 MT/s. Tuttavia, il Ryzen AI 9 HX 375 ha ottenuto un miglioramento del 27% in token per secondo (tk/s), una metrica che indica la velocità con cui un LLM genera output testuale.
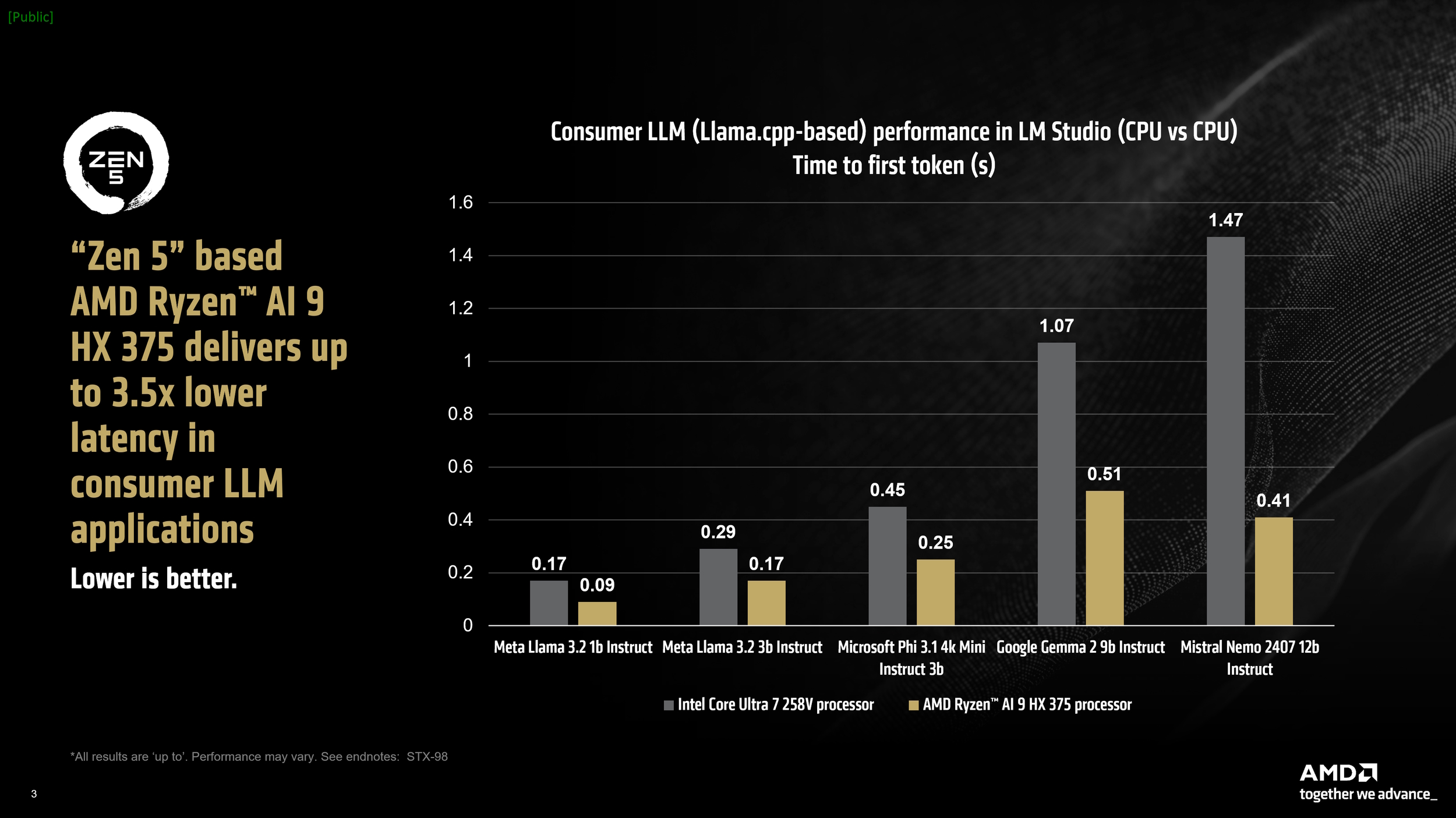
Nei test, il Ryzen AI 9 HX 375 ha elaborato fino a 50,7 token al secondo utilizzando il modello Meta Llama 3.2 1b Instruct a quantizzazione a 4 bit. Anche il tempo per il primo token ha mostrato un vantaggio del 3,5x rispetto ai concorrenti con modelli più grandi. Inoltre, LM Studio integra una versione ottimizzata di llama.cpp per accelerazione tramite Vulkan, che porta significativi miglioramenti di performance. Abilitando il trasferimento su GPU, si è osservato un incremento del 31% nelle prestazioni di Meta Llama 3.2 1b rispetto alla sola modalità CPU, e un incremento del 5,1% nei modelli più impegnativi.
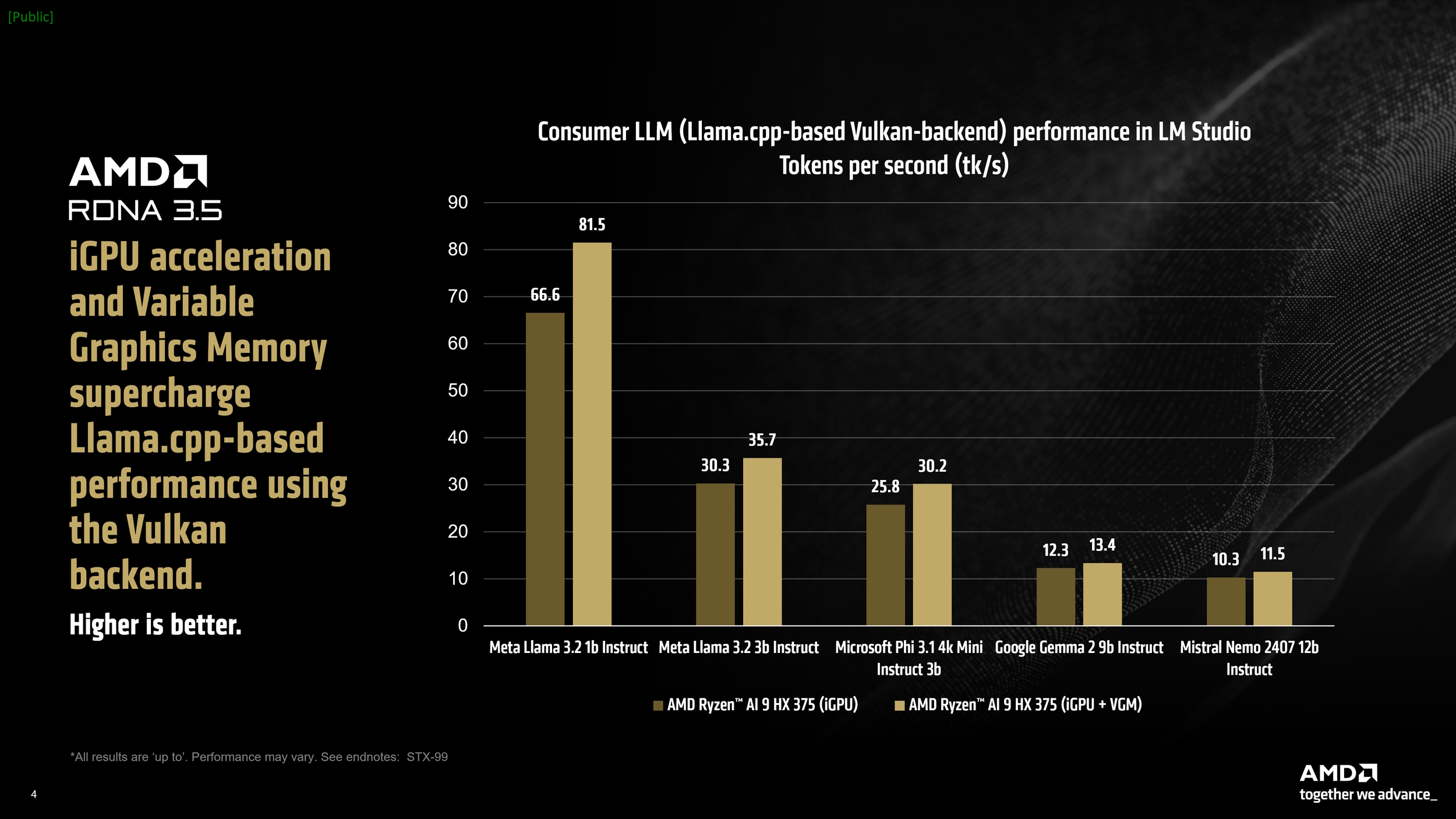
La Variable Graphics Memory (VGM), introdotta con la serie Ryzen AI 300, è utile per i carichi di lavoro AI, poiché consente di ampliare la memoria dedicata della GPU integrata fino al 75% della RAM di sistema. AMD ha rilevato un aumento del 22% nelle prestazioni per il Meta Llama 3.2 1b con VGM abilitato (16GB), che arriva al 60% utilizzando l’accelerazione GPU insieme a VGM.
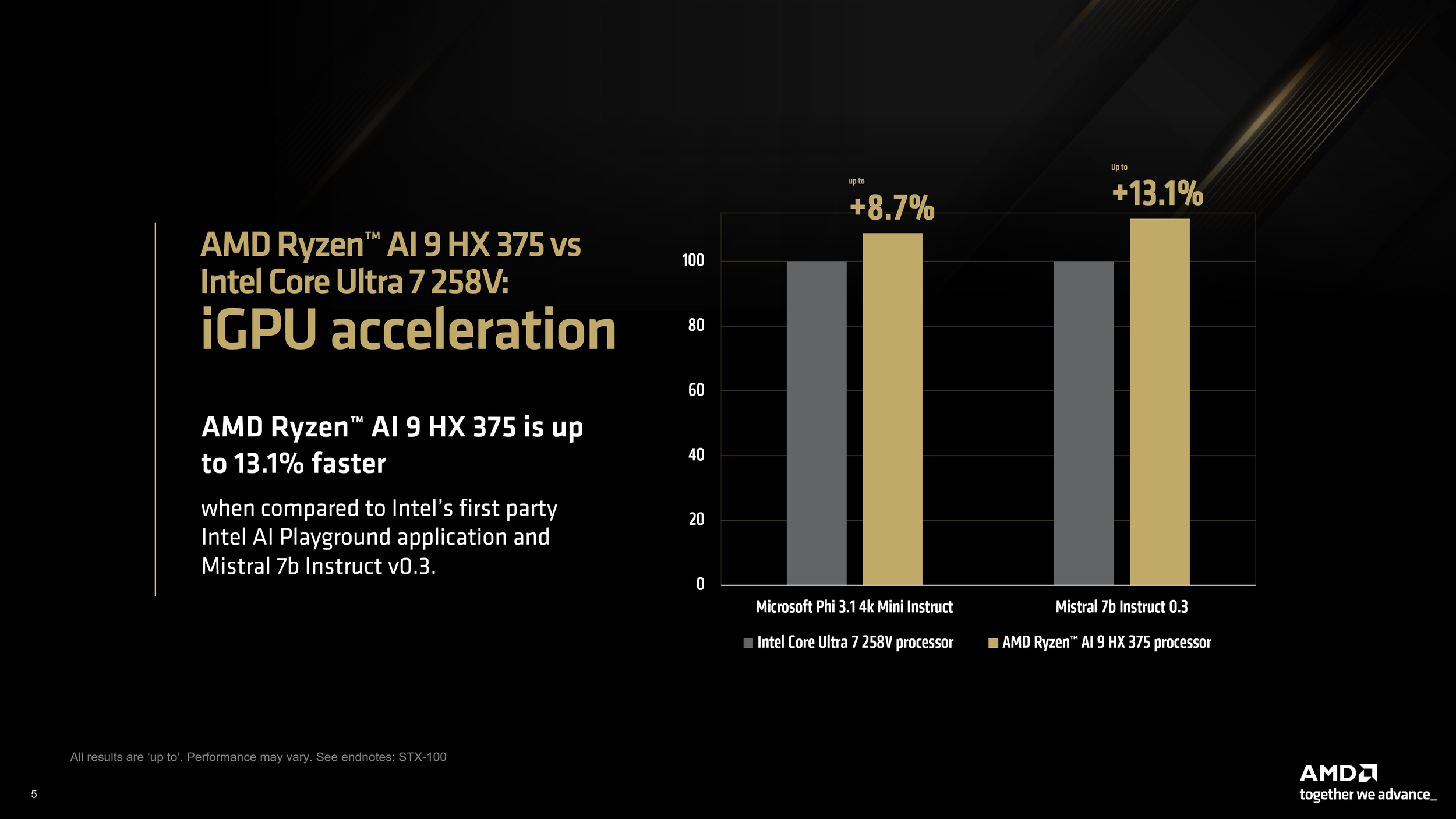
Anche i modelli più grandi, come Mistral Nemo 2407 12b, hanno beneficiato di miglioramenti delle prestazioni fino al 17% rispetto ai benchmark solo CPU. Infine, utilizzando i modelli Mistral 7b v0.3 e Microsoft Phi 3.1 Mini da Intel AI Playground, AMD ha mostrato che il Ryzen AI 9 HX 375 supera il Core Ultra 7 258V rispettivamente dell’8,7% e del 13,1%.
HW Legend Staff






