




 Sono ormai trascorsi diversi mesi dalla presentazione ufficiale delle prime soluzioni grafiche basate sull’innovativa architettura “Ampere” da parte del colosso di Santa Clara, soluzioni che, a detta della stessa azienda rappresentano un deciso passo avanti sia in termini prettamente prestazionali e sia in quanto ad efficienza e novità tecnologiche introdotte. Alla base di queste nuove soluzioni troviamo non soltanto l’avanzata tecnologia produttiva a 8 nanometri custom NVIDIA (8N), messa a punto dalla coreana Samsung, ma soprattutto una significativa ottimizzazione delle unità dedicate ai calcoli ray-tracing in tempo reale e all’intelligenza artificiale. Nel corso di questo nostro articolo andremo ad osservare una delle ultime proposte della nota e rinomata azienda INNO3D basata sul nuovissimo processore grafico di fascia media GeForce RTX 3070 Ti. Precisamente ci occuperemo del modello N307T3-086XX-1820VA45, un’interessante scheda grafica discreta contraddistinta dalla presenza di un accattivante ed efficiente sistema di raffreddamento proprietario a tripla ventola di tipo Dual-Slot. Non ci resta che augurarci che la lettura sia di vostro gradimento!
Sono ormai trascorsi diversi mesi dalla presentazione ufficiale delle prime soluzioni grafiche basate sull’innovativa architettura “Ampere” da parte del colosso di Santa Clara, soluzioni che, a detta della stessa azienda rappresentano un deciso passo avanti sia in termini prettamente prestazionali e sia in quanto ad efficienza e novità tecnologiche introdotte. Alla base di queste nuove soluzioni troviamo non soltanto l’avanzata tecnologia produttiva a 8 nanometri custom NVIDIA (8N), messa a punto dalla coreana Samsung, ma soprattutto una significativa ottimizzazione delle unità dedicate ai calcoli ray-tracing in tempo reale e all’intelligenza artificiale. Nel corso di questo nostro articolo andremo ad osservare una delle ultime proposte della nota e rinomata azienda INNO3D basata sul nuovissimo processore grafico di fascia media GeForce RTX 3070 Ti. Precisamente ci occuperemo del modello N307T3-086XX-1820VA45, un’interessante scheda grafica discreta contraddistinta dalla presenza di un accattivante ed efficiente sistema di raffreddamento proprietario a tripla ventola di tipo Dual-Slot. Non ci resta che augurarci che la lettura sia di vostro gradimento!
INNO3D GeForce RTX 3070 Ti X3 OC [N307T3-086XX-1820VA45] – Recensione di Gianluca Cecca | delly – Voto: 5/5
![]()
![]()
InnoVISION Multimedia Limited, fondata nel 1998 a Hong Kong, è un’azienda pionieristica nello sviluppo e nella produzione di una vasta gamma di prodotti hardware all’avanguardia per PC. Le prime operazioni di produzione iniziarono nel 1990 a Shenzhen, in Cina. In un primo momento l’azienda si concentrò esclusivamente su prodotti OEM / ODM e affidò le attività di ricerca a società specializzate ottenendo un immediato successo presso le principali riviste dedicate alle recensioni di componenti hardware per PC, divenendo una delle aziende asiatiche in più rapida crescita.
L’obiettivo della società è da sempre quello di offrire la migliore esperienza multimediale possibile agli utenti di PC e ai professionisti del settore, offrendo soluzioni innovative ad un prezzo accessibile. A completamento della gamma di prodotti InnoVISION fu introdotto il marchio di successo INNO3D, che comprende una gamma completa di soluzioni grafiche discrete basate su GPU NVIDIA, soluzioni video digitali / capture TV ed editing, schede audio InnoAX di classe high-end ed EIO, ed altre periferiche avanzate.
Il conseguimento da parte dell’azienda della certificazione ISO 9001:2000 assicura non soltanto uno standard di produzione elevato ma anche la massima qualità nella gestione ed efficienza nella distribuzione. La società ed il proprio team di progettisti di talento, sia ad Hong Kong che a Shenzen, sono infatti continuamente impegnati in ricerche di altissimo livello al fine di proporre prodotti sempre più innovativi e tecnologicamente avanzati.
InnoVISION vanta un significativo aumento della quota di mercato delle vendite di schede grafiche nel corso degli ultimi anni, grazie a prodotti estremamente competitivi e proposti al giusto prezzo pur senza rinunciare alla qualità ed a un supporto tecnico avanzato per poter soddisfare le esigenze dei clienti di tutto il mondo. Potete trovare maggiori informazioni sul sito ufficiale del produttore.
[nextpage title=”NVIDIA Ampere: Uno sguardo alla nuova architettura”]
Sin dall’invenzione della prima GPU (Graphics Processing Unit) al mondo nell’ormai lontano 1999, le soluzioni NVIDIA sono state costantemente in prima linea nella grafica 3D e nell’elaborazione accelerata, con accorgimenti mirati a fornire livelli rivoluzionari di prestazioni ed efficienza.

La nuovissima famiglia di processori grafici basati su architettura Ampere non fa ovviamente eccezione, ed è espressamente progettata per accelerare numerose tipologie di applicazioni e carichi di lavoro ad alta intensità. Rilasciata ufficialmente nel corso del mese di maggio dello scorso anno, la prima GPU Ampere, meglio nota con il nome in codice A100, offre incredibili accelerazioni per l’addestramento e l’inferenza AI, i carichi di lavoro HPC e le applicazioni di analisi dei dati.
Le declinazioni pensate per il mercato consumer, identificate con i nomi in codice GA10x, riprendono grossomodo quando già osservato in occasione della presentazione delle altrettanto rivoluzionarie soluzioni Turing, introducendo però una serie di nuove funzionalità e ottimizzazioni, mirate ad ottenere un livello di performance significativamente superiore. Il colosso di Santa Clara, infatti, stima come Ampere sia 1,7 volte più veloce nei carichi di lavoro basati sulla tradizionale rasterizzazione e fino a ben 2 volte più veloce nel ray-tracing in tempo reale.
Ancora una volta vengono puntati i riflettori su quello che molti definiscono come il “Santo Graal” nel campo del rendering grafico computerizzato, ovvero il ray-tracing in tempo reale, anche in sistemi a singola GPU. I nuovi processori grafici NVIDIA basati su architettura Ampere, infatti, implementano migliori e ancor più sofisticate unità dedicate all’esecuzione delle operazioni di ray-tracing (denominate per l’appunto “RT Cores”), eliminando così dispendiosi e poco efficienti approcci basati sull’emulazione software.
Queste nuove unità, combinate con la tecnologia software proprietaria NVIDIA RTX e con sofisticati algoritmi di filtraggio, consentono un rendering in ray-tracing in tempo reale, includendo oggetti e ambienti fotorealistici con ombre, riflessi e rifrazioni fisicamente precise.
L’architettura Ampere non solo migliora le già ottime funzionalità di ombreggiatura avanzate introdotte nella passata generazione, atte a migliorare le prestazioni, la qualità dell’immagine ed offrire nuovi livelli di complessità geometrica, ma ne introduce di nuove, tra cui il Ray-Traced Motion Blur accelerato in hardware, che osserveremo con più attenzione più avanti.
Non mancano poi tutti i miglioramenti apportati alla piattaforma CUDA dedicati alla capacità, alla flessibilità, alla produttività e alla portabilità delle applicazioni di elaborazione. Funzioni quali la programmazione indipendente dei Thread, il Multi-Process Service (MPS) accelerato via hardware, e gruppi cooperativi fanno tutti parte di questa nuova architettura NVIDIA.
Ampere è inoltre la prima architettura ad essere sviluppata con la recente ed avanzata tecnologia produttiva a 8 nanometri custom NVIDIA (8N), messa a punto dalla coreana Samsung e capace di garantire non soltanto un deciso incremento dell’efficienza energetica ma soprattutto di offrire la possibilità di integrare un maggior quantitativo di unità di calcolo, grazie ad una densità superiore, e nuove funzionalità all’interno del processore grafico.
NVIDIA ha da tempo dimostrato in modo inequivocabile come una migliore tecnologia produttiva possa incidere in maniera decisa nella fase di progettazione dell’architettura, consentendo agli ingegneri di apportare modifiche e ottimizzazioni particolari, come il perfezionamento delle latenze e la pulizia dei vari segnali, mirate a garantire prestazioni e frequenze operative in precedenza impensabili, pur senza stravolgerne le fondamenta. Nei paragrafi che seguono andremo a descrivere quelle che sono le più significative differenze e novità introdotte con la nuova architettura.
Ampere Streaming Multiprocessor (SM) e nuove unità Tensor Cores
Una delle principali differenze architetturali rispetto alla passata generazione riguarda le unità Streaming Multiprocessor (SM), ancora una volta comprensive di molte delle funzionalità implementate nelle soluzioni professionali, ma ora capaci di un throughput doppio per quanto riguarda le operazioni in virgola mobile (FP32). Secondo la stessa NVIDIA, questo genere di operazioni rappresenta la maggior parte del carico di lavoro medio in ambito grafico, di conseguenza sono state previste sostanziali differenze in termini di approccio rispetto alla passata generazione al fine di incrementare sia l’efficienza che le prestazioni, introducendo un’elaborazione FP32 a doppia velocità.
Nelle precedenti soluzioni Turing ogni partizione SM poteva seguire due datapath principali, uno per l’elaborazione di operazioni su interi (INT32) e uno per l’elaborazione di operazioni virgola mobile (FP32). Questo consentiva la possibilità di elaborare, per ogni ciclo di clock, un massimo di 16 operazioni INT32 e di 16 operazioni FP32.
Con le nuove Ampere ci sono stati dei cambiamenti abbastanza significativi; entrambi i due datapath principali sono ora in grado di elaborare operazioni FP32 (il primo percorso combina INT32 ed FP32, mentre il secondo soltanto FP32), con il risultato che ogni partizione SM può elaborare, per ogni ciclo di clock, o le solite 16 operazioni INT32 + 16 operazioni FP32, oppure un massimo di ben 32 operazioni FP32.

I carichi di lavoro dei moderni videogiochi 3D prevedono un’ampia gamma di esigenze di elaborazione. Molti di questi si basano su un mix di istruzioni aritmetiche FP32, come FFMA, addizioni in virgola mobile (FADD) o moltiplicazioni in virgola mobile (FMUL), insieme a molte istruzioni intere più semplici per indirizzare e recuperare dati, confrontare o elaborare i risultati. L’aggiunta di funzionalità in virgola mobile al secondo percorso dati è indubbiamente in grado di assicurare un contributo notevole.
I miglioramenti delle prestazioni varieranno a livello di shader e applicazione a seconda della combinazione di istruzioni, più vi sarà uno sfruttamento pesante in termini di operazioni in virgola mobile e più la differenza in performance rispetto a Turing sarà marcata. NVIDIA evidenzia come il raddoppio del throughput FP32 incida anche in ambito Ray-Tracing, precisamente per quanto riguarda le operazioni di Denoising, oppure in applicativi professionali quali V-Ray e similari.
Del tutto invariato il quantitativo di unità SM per ogni blocco TPC (Thread/Texture Processing Clusters), sempre pari a due unità, così come in Turing. Ognuna di queste integra al proprio interno 64 core FP32/INT32 e altrettanti core FP32, di tipo concurrent, ovvero in grado di operare in parallelo e contemporaneamente. Proprio questo aspetto rappresentava una delle differenze più significative, e con il maggior impatto in termini di performance, introdotte con l’architettura Turing.
Il colosso californiano, infatti, aveva evidenziato un deciso incremento dell’efficienza, ricordando che per ogni 100 istruzioni in virgola mobile il processore grafico si trova a dover processare almeno 36 istruzioni di tipo integer, e sottolineando così come la possibilità di operare in parallelo e in contemporanea su l’una o l’altra tipologia di istruzione rappresenti un punto chiave delle moderne architetture grafiche.
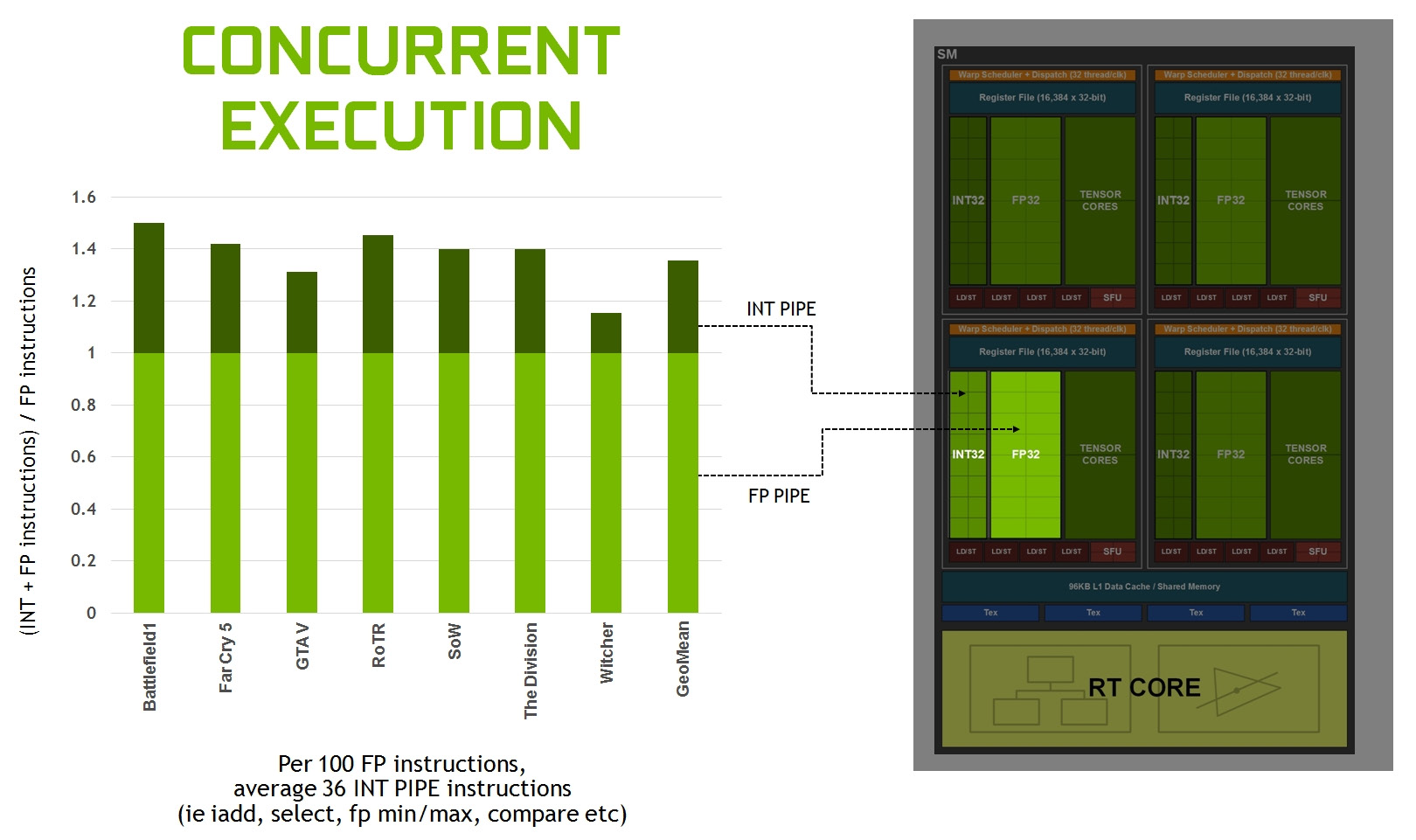
Ad essere radicalmente rivista ed ottimizzata è stata anche l’architettura della Cache e della memoria condivisa (Shared Memory), ora basate su un design di tipo unificato in grado di essere riconfigurato a seconda del carico di lavoro per allocare più memoria per la L1 o per la memoria condivisa a seconda delle necessità. La capacità della cache di dati L1 è aumentata a 128 KB per ogni SM, contro i 96 KB previsti in Turing. In modalità di calcolo sono ora supportate le seguenti configurazioni:
- 128 KB L1 + 0 KB Shared Memory;
- 120 KB L1 + 8 KB Shared Memory;
- 112 KB L1 + 16 KB Shared Memory;
- 96 KB L1 + 32 KB Shared Memory;
- 64 KB L1 + 64 KB Shared Memory;
- 28 KB L1 + 100 KB Shared Memory.
Oltre ad incrementare le dimensioni della memoria cache L1 del 33% (dai 6912KB di TU102 a ben 10752KB di GA102), è stata raddoppiata anche la larghezza di banda della memoria condivisa, con prestazioni che raggiungono i 128 byte/clock per SM contro i 64 byte/clock della soluzione Turing. La larghezza di banda L1 totale della nuova GeForce RTX 3080 raggiunge quota 219 GB/sec contro i 116 GB/sec della precedente soluzione GeForce RTX 2080 SUPER.
L’insieme di questi interventi assicura un significativo impatto sulle prestazioni, semplificando allo stesso tempo la programmazione e l’ottimizzazione necessaria all’ottenimento di prestazioni prossime al picco massimo. Sempre all’interno dello Streaming Multiprocessor (SM), troviamo le unità computazionali specifiche che hanno rappresentato il vero e proprio punto di svolta rispetto alle architetture pre-Turing, ovvero Tensor Cores e RT Cores, giunte rispettivamente alla terza e alla seconda generazione.
In ognuna delle unità SM presenti in Ampere troviamo un quantitativo pari a 4 unità Tensor Cores a precisione mista, ed 1 unità RT Cores che analizzeremo nel dettaglio più avanti. Rispetto a Turing, quindi, troviamo un numero dimezzato di unità Tensor Cores, tuttavia ognuna di quelle ora presenti vanta, come vedremo, potenzialità di gran lunga superiori. Le unità Tensor Cores osservate in occasione della presentazione dell’architettura Turing, introducevano le modalità di precisione INT8 e INT4, capaci di gestire operazioni quantistiche e supportavano appieno, inoltre, la modalità FP16 per carichi di lavoro che richiedono un maggior livello di precisione.
I nuovi Tensor Cores dell’architettura Ampere sono stati riorganizzati per migliorarne l’efficienza e ridurre il consumo energetico. Con la terza generazione di queste unità vengono accelerati ancor più tipi di dati e viene implementato il supporto hardware per l’elaborazione di matrici con pattern sparsi, assicurando un raddoppio del throughput anche grazie alla possibilità di saltare elementi non necessari. Nella configurazione GA10x ogni SM ha il doppio del throughput di un Turing SM durante l’elaborazione di matrici sparse, pur mantenendo lo stesso throughput totale di un Turing SM per le operazioni ad alta densità.
Il supporto Sparsity consente ai processori grafici Ampere di fornire in modo efficiente un enorme aumento del throughput rispetto a Turing; basandosi su stime NVIDIA una GeForce RTX 3080 è in grado di offrire un throughput operativo di ben 2,7 volte superiore rispetto ad una precedente GeForce RTX 2080 SUPER.
Sempre prendendo come esempio la soluzione GeForce RTX 3080 scelta da NVIDIA, basata sulla variante semi-completa del processore grafico di fascia alta GA102, troviamo implementati un totale di 272 Tensor Cores, come anticipato 4 per ognuna delle unità SM presenti, e 1 per ogni blocco di elaborazione previsto all’interno della SM stessa.
Ognuno di essi può eseguire fino a 128 operazioni FMA (Fused Multiply-add) in virgola mobile per ciclo di clock utilizzando input FP16, che salgono a ben 256 con matrice sparsa. Moltiplicando questo dato per il quantitativo di unità previste all’interno di ogni SM otteniamo un totale di 512 operazioni di tipo FP16 oppure 1.024 operazioni con matrice sparsa per ogni ciclo di clock.

La funzione Fine-Grained Structured Sparsity può sfruttare le reti di deep learning per raddoppiare il throughput delle operazioni Tensor Core rispetto alla generazione precedente. I Tensor Cores di terza generazione accelerano le funzionalità di intelligenza artificiale come NVIDIA DLSS per la AI Super-Resolution (ora con supporto fino a 8K), l’app NVIDIA Broadcast per comunicazioni video e vocali ottimizzate con AI e l’app NVIDIA Canvas per la pittura basata su AI.
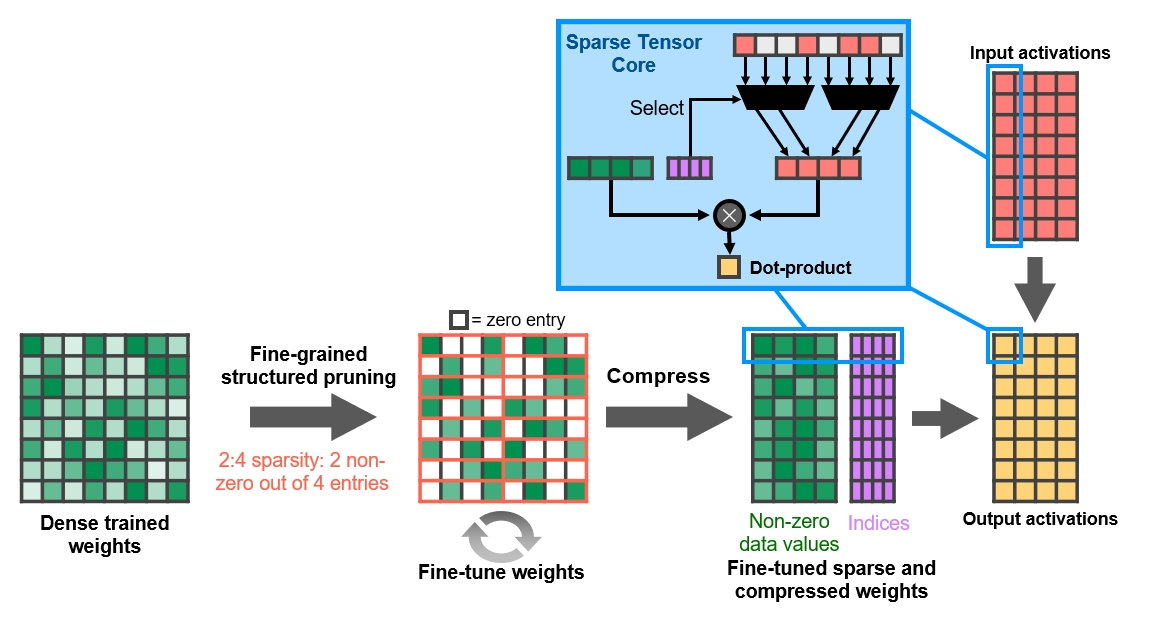
Gli ingegneri NVIDIA hanno scoperto che, poiché le reti di deep learning sono in grado di evolversi durante il processo di formazione in base ai feedback, in generale il vincolo della struttura non influisce sulla precisione della rete addestrata per l’inferenza. Ciò consente di inferire l’accelerazione anche con Sparsity.
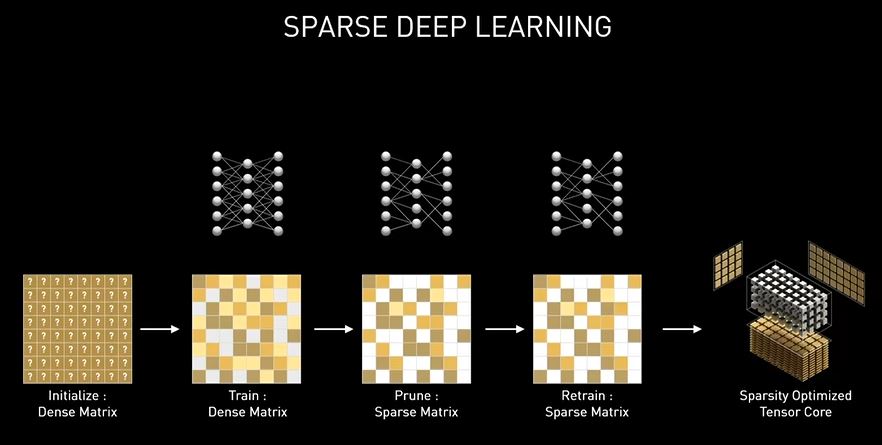
Inoltre, il design Tensor Cores di terza generazione aumenta ulteriormente le prestazioni grezze e introduce le nuove modalità di precisione TF32 e BFloat16 dedicate ad alcune funzionalità basate sull’intelligenza artificiale dei servizi neurali NVIDIA NGX. Ad esempio BF16 è un’alternativa a IEEE FP16 e include un esponente a 8 bit, una mantissa a 7 bit e 1 sign-bit. Sia FP16 che BF16 hanno dimostrato di addestrare con successo le reti neurali in modalità a precisione mista, abbinando i risultati dell’addestramento FP32 senza aggiustamento iper-parametrico.
Entrambe le modalità FP16 e BF16 dei Tensor Cores forniscono un throughput matematico 4 volte superiore rispetto allo standard FP32 nelle GPU GA10x. Oggi, la matematica predefinita per l’addestramento AI è FP32, senza l’accelerazione Tensor Core. L’architettura Ampere introduce il pieno supporto per TF32, consentendo di utilizzare i Tensor Core in fase di addestramento AI per impostazione predefinita senza alcuno sforzo da parte dell’utente.
Le operazioni senza unità Tensor dedicate continuano a utilizzare il percorso dati FP32, mentre in modalità TF32 i Tensor Cores leggono i dati FP32 e utilizzano lo stesso intervallo di FP32 con una precisione interna ridotta, prima di produrre un output IEEE FP32 standard. TF32 include un esponente a 8 bit (uguale a FP32), mantissa a 10 bit (stessa precisione di FP16) e 1 sign-bit. La modalità TF32 di una GPU con architettura Ampere offre un throughput doppio rispetto allo standard FP32.
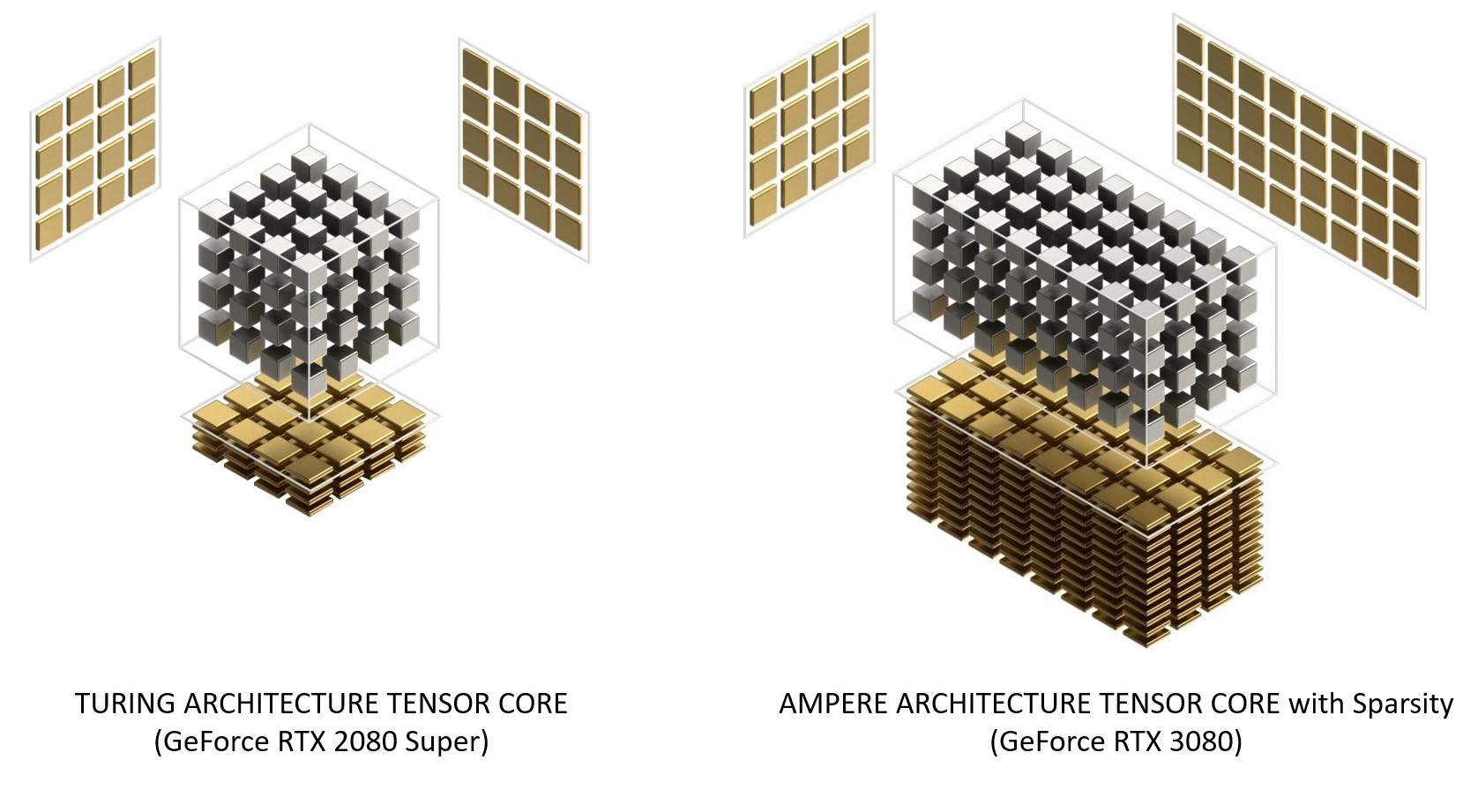
Grazie ai Tensor Cores abbiamo visto sdoganare il deep-learning anche in ambito gaming; nello specifico vengono accelerate alcune funzionalità basate sull’intelligenza artificiale al fine di migliorare la qualità grafica nei titoli di nuova generazione, il rendering ed altre applicazioni lato client. Alcuni esempi di funzionalità NGX AI sono il Deep-Learning Super Sampling (DLSS), l’AI InPainting, l’AI Super Rez e l’AI.
Nuovo sottosistema di Memoria GDDR6X by Micron Technology
Poiché le risoluzioni dello schermo continuano ad aumentare e le funzionalità shader e le tecniche di rendering diventano sempre più complesse, la larghezza di banda e la capacità complessiva della memoria video dedicata giocano un ruolo sempre più rilevante nelle prestazioni dei moderni processori grafici.
Per mantenere un livello di frame rate e una velocità di calcolo più elevati possibili, la GPU non solo ha bisogno di più larghezza di banda di memoria, ma necessita anche di un ampio quantitativo di memoria dedicata da cui attingere per offrire prestazioni costanti e sostenute. Proprio per questi motivi NVIDIA lavora da diverso tempo a stretto contatto con le principali realtà dell’industria DRAM, così da implementare in ogni sua GPU la migliore e più avanzata tecnologia di memoria disponibile.
in passato abbiamo assistito a soluzioni grafiche dotate, per la prima volta in assoluto, di prestanti ed innovative HBM2, GDDR5X e GDDR6, con Ampere assistiamo al debutto ufficiale, in ambito consumer, delle nuovissime memorie GDDR6X messe a punto da Micron Technology. Certamente questa nuova tipologia rappresenta un grande passo avanti nella progettazione della memoria DRAM GDDR ad elevate prestazioni, tuttavia non bisogna pensare che la sua implementazione non abbia richiesto comunque notevoli sforzi. Gli ingegneri NVIDIA, infatti, hanno dovuto ridisegnare completamente il circuito I/O ed il canale di comunicazione tra la GPU e i moduli di memoria stessi, al fine di garantire la massima stabilità ed efficienza a frequenze di funzionamento così elevate.
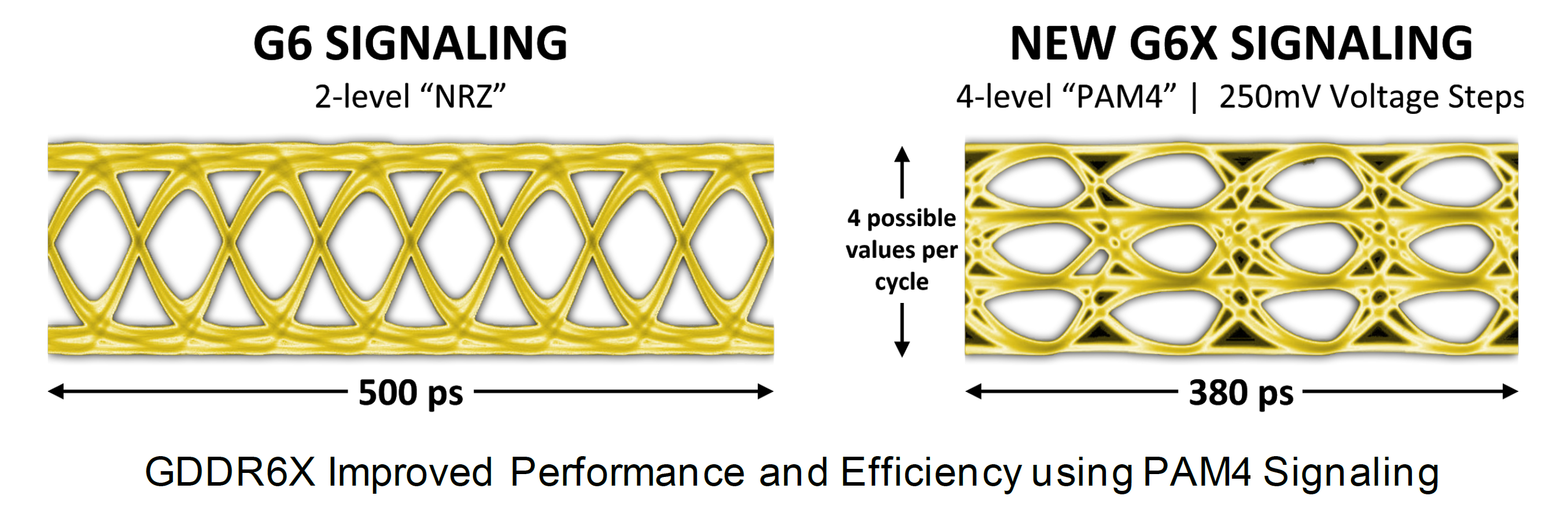
Il sottosistema di memoria di Ampere vanta infatti una frequenza di clock pari a ben 19.5Gbps, aspetto che assicura non soltanto un notevole miglioramento dell’efficienza energetica rispetto alla memoria GDDR6 utilizzata nelle GPU Turing di fascia alta (TU102), ma anche un incremento della larghezza di banda di picco superiore al 50%, raggiungendo per la prima volta su una GPU consumer una bandwith superiore ai 900GB/s.
Per ottenere questa svolta, sono state introdotte innovative tecnologie di trasmissione del segnale e di modulazione di ampiezza dell’impulso, così da ridefinire completamente il modo in cui il sottosistema di memoria sposta i dati. Utilizzando le tecniche di segnale multi-livello PAM4, GDDR6X trasferisce più dati e a una velocità molto più veloce, spostando due bit di informazioni alla volta e raddoppiando la velocità di dati I/O del precedente schema di segnale PAM2/NRZ.
I carichi di lavoro affamati di dati, come inferenza AI, Ray-Tracing in tempo reale e rendering video a risoluzione fino ad 8K, possono ora essere alimentati con dati a velocità elevate, aprendo nuove opportunità per il computing e nuove esperienze per l’utente finale.
Nell’immagine riportata poco sopra si nota come la stessa quantità di dati può essere trasferita attraverso l’interfaccia GDDR6X a una frequenza dimezzata rispetto a GDDR6. In alternativa, GDDR6X può raddoppiare la larghezza di banda effettiva rispetto a GDDR6 a una determinata frequenza operativa.
Il supporto PAM4 rappresenta un grande aggiornamento rispetto all’NRZ a due livelli previsto nelle memorie GDDR6. Invece di trasmettere due bit di dati ogni ciclo di clock (un bit sul fronte di salita e un bit sul fronte di discesa del clock), PAM4 invia due bit per fronte di clock, codificati utilizzando quattro diversi livelli di tensione. I livelli di tensione sono divisi in passi di 250mV, con ogni livello che rappresenta due bit di dati – 00, 01, 10 o 11 inviati su ogni fronte di clock (sempre tecnologia DDR).

Con il nuovo design viene ridotto al minimo il rumore e le variazioni dovute al processo, alla temperatura e alla tensione di alimentazione, inoltre, grazie ad un più ampio clock-gating viene notevolmente ridotto il consumo di energia durante i periodi di minore utilizzo, con conseguente e significativo miglioramento dell’efficienza energetica complessiva.
Tecnologia di Compressione della Memoria
Le GPU NVIDIA utilizzano ormai da tempo diverse tecniche di compressione della memoria al fine di ridurre le esigenze di larghezza di banda grazie all’archiviazione in formato compresso, e senza perdita di qualità, dei dati di colore del frame buffer con possibilità, da parte del processore grafico, sia di lettura che di scrittura degli stessi. La riduzione della larghezza di banda garantita dalla compressione della memoria offre una serie di vantaggi, tra cui:
- Riduzione della quantità di dati scritti verso la memoria;
- Riduzione della quantità di dati trasferiti dalla memoria alla Cache L2 (un blocco di pixel compresso, infatti, produrrà un ingombro sulla memoria inferiore rispetto a un blocco non compresso);
- Riduzione del quantitativo di dati trasferiti tra differenti client (come ad esempio tra le Texture Unit ed il Frame Buffer).
La pipeline di compressione del processore grafico prevede diversi algoritmi pensati per determinare in maniera intelligente il modo più efficace per comprimere i dati. Tra questi, quello indubbiamente più significativo è rappresentato dalla tecnica di compressione del colore di tipo Delta (Delta Color Compression), ossia la capacità della GPU di analizzare le differenze tra il colore dei pixel presenti all’interno di un blocco, che verrà successivamente memorizzato come riferimento, ed i successivi blocchi che compongono il dato completo.
In questa maniera anziché utilizzare un grosso quantitativo di spazio per registrare la mole di dati nella sua interezza, verrà immagazzinato esclusivamente l’insieme di pixel di riferimento con l’aggiunta dei valori differenti (per l’appunto “delta”) rilevati rispetto allo stesso. Di conseguenza, se il delta tra un blocco e l’altro è sufficientemente piccolo saranno necessari solamente pochi bit per identificare il colore dei singoli pixel, riducendo nettamente lo spazio necessario per la memorizzazione dei dati.
Con la nuova architettura sono stati ulteriormente migliorati i già ottimi ed avanzati algoritmi di compressione della memoria implementati nelle soluzioni della passata generazione, offrendo così un ulteriore incremento dell’ampiezza di banda effettiva e contribuendo a ridurre in maniera ancor più marcata la quantità di byte che il processore grafico deve recuperare dalla memoria per singolo frame.
L’insieme di queste migliorie, in abbinamento all’impiego dei nuovi moduli di memorie GDDR6X operanti a ben 19.5Gbps, assicura un notevole aumento dell’ampiezza di banda effettiva, aspetto di fondamentale importanza per mantenere l’architettura bilanciata e sfruttare nel migliore dei modi la architettura delle unità SM.
[nextpage title=”NVIDIA Ampere: Uno sguardo alla nuova architettura – Parte Prima”]
Il ray-tracing è una tecnologia di rendering estremamente impegnativa dal punto di vista computazionale, capace di simulare realisticamente l’illuminazione di una scena e dei suoi oggetti. In ambito professionale e cinematografico, seppur si faccia uso massiccio, ormai da diversi anni, di questa tecnica, sfruttando ad esempio gli strumenti Iray ed OptiX messi a disposizione da NVIDIA, non è mai stato possibile riprodurre tali effetti in alta qualità ed in tempo reale, specialmente affidandosi ad un singolo processore grafico.
Sempre a causa di questa sua natura intensiva in termini di elaborazione, questa tecnica non ha mai trovato impiego in ambito videoludico per attività di rendering significative. Come ben noto, infatti, i giochi che richiedono animazioni fluide ad elevati framerate si basano su ormai rodate tecniche di rasterizzazione, in quanto meno impegnative da gestire. Seppur scene rasterizzate possono vantare tutto sommato un bell’aspetto, non mancano purtroppo limitazioni significative che ne compromettono il realismo.
Nuove unità RT Cores e Ray-Traced Motion Blur

Ad esempio, il rendering di riflessi e ombre, utilizzando esclusivamente la rasterizzazione, necessita di semplificazioni di presupposti che possono causare diversi tipi di artefatti. Allo stesso modo, le scene statiche possono sembrare corrette fino a quando qualcosa non si muove, le ombre rasterizzate spesso soffrono di aliasing e fughe di luce e le riflessioni nello spazio possono riflettere solo gli oggetti visibili sullo schermo. Questi artefatti, oltre che compromettere il livello di realismo dell’esperienza di gioco, per essere in parte risolti obbligano gli sviluppatori a ricorrere ad effetti e filtri supplementari, con ovvio aumento delle richieste necessarie in termini di potenza elaborativa.
L’implementazione del ray-tracing in tempo reale su singola GPU è stata un’enorme sfida tecnica, che ha richiesto a NVIDIA quasi dieci anni di ricerca, progettazione e stretta collaborazione con i suoi migliori ingegneri in campo software. Tutti questi sforzi hanno portato alla messa a punto della tecnologia software NVIDIA RTX e di unità hardware specifiche espressamente dedicate al ray-tracing, denominate RT Cores e implementate per la prima volta nel 2018, in occasione del debutto di processori grafici basati su architettura Turing.

L’approccio scelto da NVIDIA appare del tutto intelligente, prevedendo una combinazione ibrida tra le due sopracitate tecniche di rendering. In questa maniera la rasterizzazione continuerà ad essere utilizzata laddove è più efficace, allo stesso tempo il ray-tracing verrà previsto esclusivamente negli ambiti nei quali è in grado di assicurare il maggior vantaggio visivo, come nel rendering dei riflessi, delle rifrazioni e delle ombre.
A detta del colosso americano questo approccio rappresenta ad oggi il miglior compromesso possibile tra qualità e realismo grafico e onere computazionale. Nell’immagine che segue viene illustrato, in modo schematico, il funzionamento della nuova pipeline di rendering ibrida:
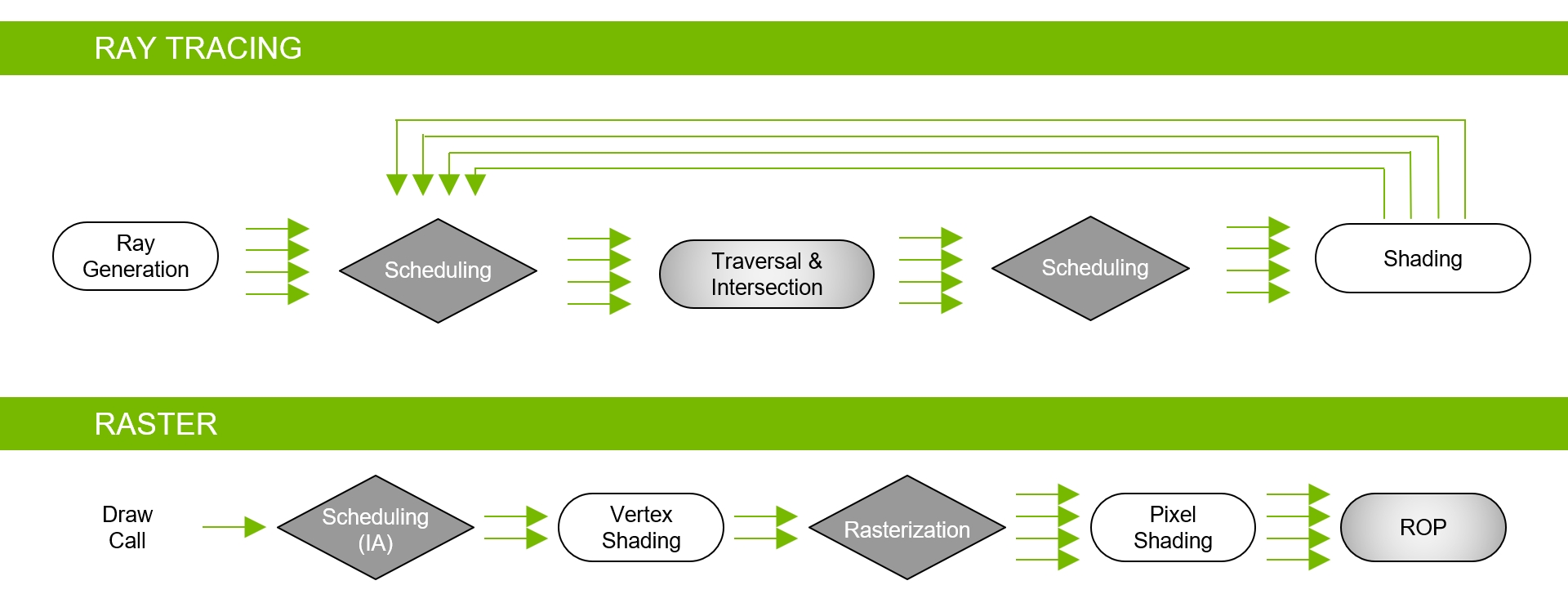
Anche se questi moderni processori grafici consentono un ray-tracing in tempo reale, il numero di raggi primari o secondari espressi per pixel o superficie varia in base a numerosi fattori, tra cui la complessità della scena, la risoluzione, gli ulteriori effetti grafici renderizzati nella scena stessa e, naturalmente, la potenza elaborativa del processore grafico.
Non dobbiamo di conseguenza aspettarci che centinaia di raggi debbano o possano essere rappresentati in tempo reale. Sono, infatti, necessari molti meno raggi per pixel quando si utilizza l’accelerazione tramite RT Cores in combinazione con tecniche di filtraggio di riduzione del rumore avanzate. NVIDIA ha quindi messo a punto degli specifici moduli denominati Denoiser-Tracing, capaci di sfruttare appositi algoritmi basati sull’intelligenza artificiale allo scopo di ridurre in modo significativo il quantitativo di raggi per pixel richiesti pur senza compromettere in maniera marcata la qualità dell’immagine.

Un esempio pratico di questo interessante approccio è stato mostrato nella demo Reflections creata dalla Epic Games in collaborazione con ILMxLAB e NVIDIA. L’implementazione del ray-tracing in tempo reale nel motore grafico Unreal Engine 4 sfrutta le API Microsoft DXR e la tecnologia NVIDIA RTX per portare su schermo illuminazioni, riflessioni, ombre e occlusione ambientale di qualità cinematografica, il tutto eseguito su una singola GPU Quadro RTX 6000 o GeForce RTX 2080 Ti.
Con la nuovissima architettura Ampere debutta anche la seconda generazione di unità RT Cores, unità rese ancor più prestanti ed efficienti rispetto al passato. NVIDIA stima una gestione delle intersezioni raggi-triangoli a velocità doppia rispetto alla scorsa generazione. Le nuove unità RT Cores, inoltre, confermano il pieno supporto verso le tecnologie di ray-tracing NVIDIA RTX e OptiX, le API Microsoft DXR e le più recenti API Vulkan Ray-Tracing, e possono accelerare le tecniche utilizzate in molte delle seguenti operazioni di rendering e non-rendering:
- Riflessioni e Rifrazioni;
- Ombre e Occlusione ambientale;
- Illuminazione Globale;
- Baking istantanea e offline della lightmap;
- Immagini e anteprime in alta qualità;
- Raggi primari nel rendering VR;
- Occlusion Culling;
- Fisica, rilevamento delle collisioni e simulazioni di particelle;
- Simulazioni audio (ad esempio tramite NVIDIA VRWorks Audio basata sull’API OptiX);
- Intelligenza artificiale;
- In-engine Path Tracing (non in tempo reale) per generare immagini di riferimento per la messa a punto di tecniche di rendering in tempo reale di eliminazione del rumore, composizione del materiale e illuminazione della scena.
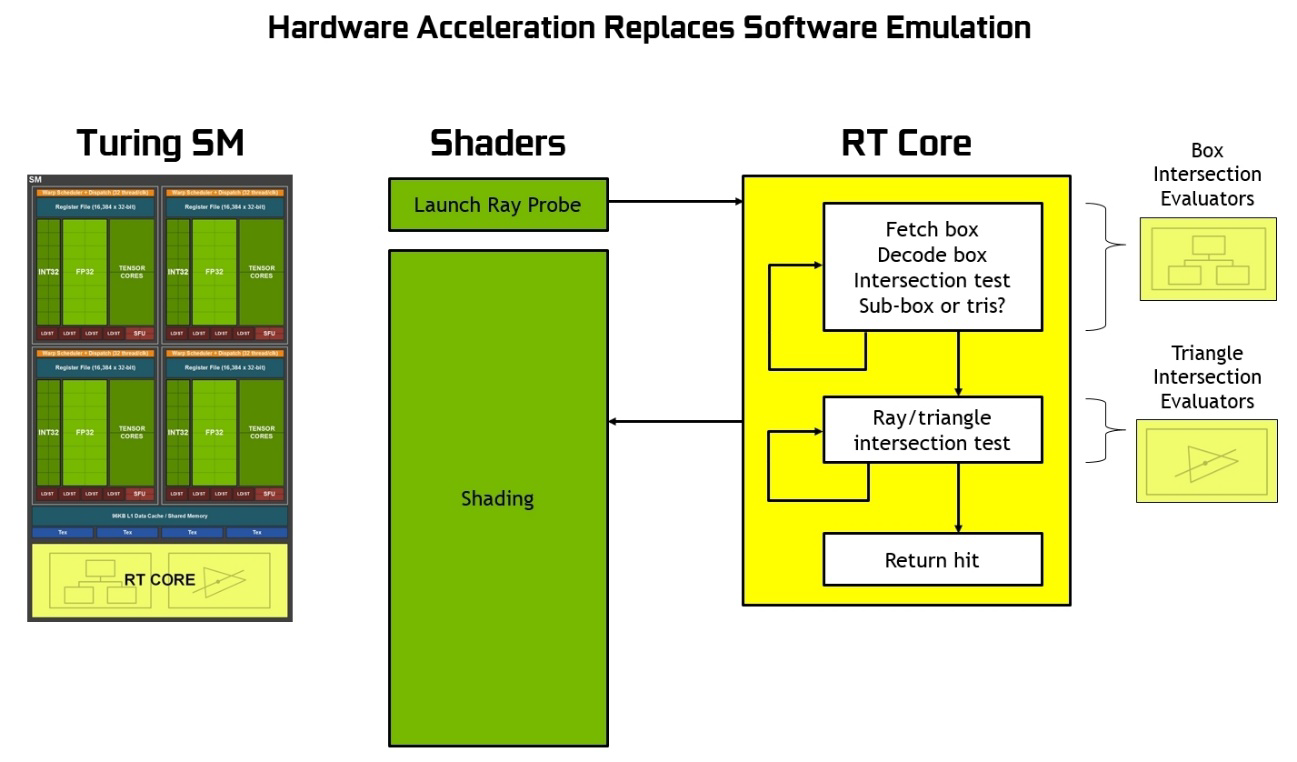
Gli RT Cores, inoltre, sono in grado di gestire in hardware la cosiddetta Bounding Volume Hierarchy (BVH), un particolare algoritmo di scomposizione gerarchica delle superfici tridimensionali che finora richiedeva un’emulazione di tipo software per essere eseguita. Nello specifico l’obiettivo è quello di individuare tutti quei triangoli che incrociano effettivamente uno dei raggi di luce presenti nella scena.
Le unità hardware lavorano insieme ad avanzati filtri di denoising all’interno dell’efficiente struttura di accelerazione della BVH sviluppata dagli ingegneri NVIDIA al fine di ridurre drasticamente la mole di lavoro a carico delle SM, consentendo a queste ultime di dedicarsi ad altre tipologie di operazioni, quali l’ombreggiatura dei pixel e dei vertici e quant’altro. Funzioni come la costruzione e il refitting BVH sono gestite direttamente dai driver, mentre la generazione e l’ombreggiatura dei raggi sono a carico dell’applicazione attraverso nuovi tipi di shader.
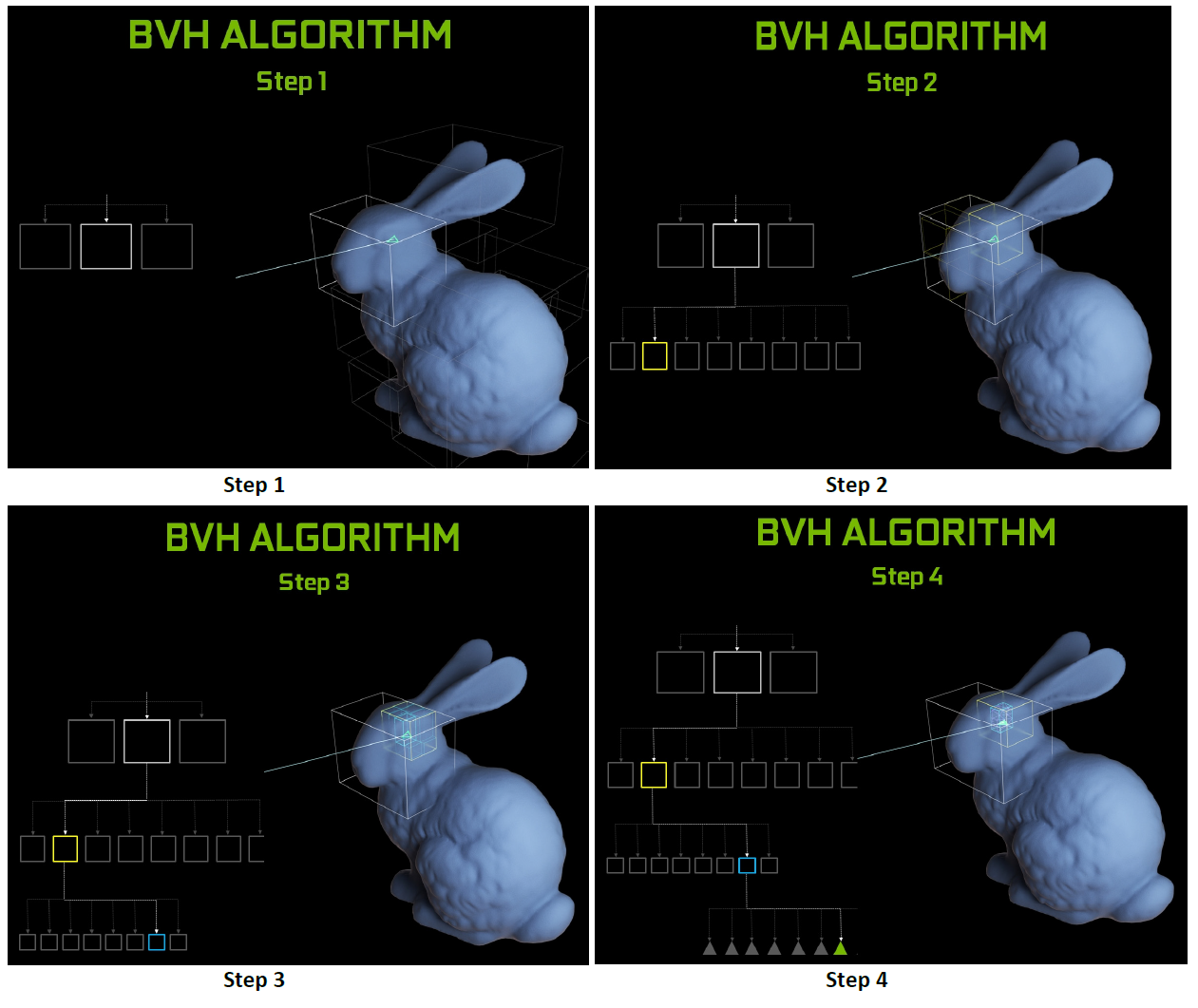
Per comprendere meglio la funzione dei nuovi RT Cores e cosa accelerano esattamente, dovremmo prima spiegare come viene eseguito il ray-tracing su GPU o CPU senza un motore hardware dedicato. In questo caso, come descritto da NVIDIA, sono gli shader a lanciare il cosiddetto “raggio sonda” che innesca il processo BVH vero e proprio, comprendente tutti i suddetti test di intersezione raggio/triangolo.
A seconda della complessità della scena da elaborare possono essere necessari migliaia di slot di istruzioni per ogni raggio proiettato fino al momento in cui non verrà effettivamente colpito un triangolo, che sarà successivamente colorato sulla base del punto di intersezione (o se al contrario non ne viene colpito alcuno, il colore di sfondo può essere usato per l’ombreggiatura del pixel stesso). Stiamo parlando di un processo estremamente intensivo dal punto di vista computazionale, al punto da essere considerato impensabile da eseguire in tempo reale facendo uso di una GPU sprovvista di accelerazione ray-tracing in hardware.
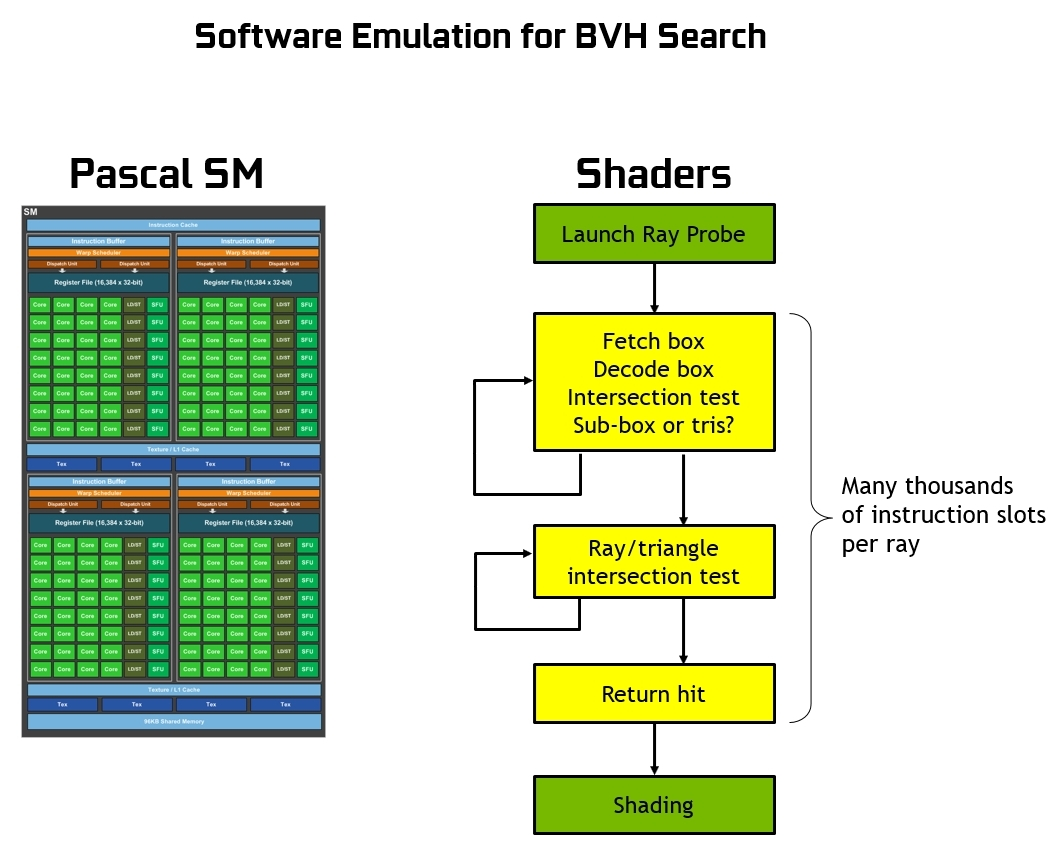
La presenza di questo genere di unità dedicate, al contrario, consente un’elaborazione efficiente di tutti i test di intersezione tra i raggi proiettati e i triangoli, sgravando la SM di migliaia di slot di istruzioni per ogni singolo raggio proiettato. Un vantaggio enorme se pensiamo alla mole di calcoli che sarebbero necessari per un’intera scena.
All’interno di ogni unità RT Cores di Turing vi sono una coppia di sotto-unità specializzate: la prima si occupa dell’elaborazione della scena e della sua suddivisione, dapprima in grandi rettangoli (denominati box) e successivamente in ulteriori rettangoli sempre più piccoli fino ad arrivare ai singoli triangoli; la seconda invece si occupa della gestione dei calcoli di intersezione tra i raggi proiettati e i triangoli, restituendo un risultato in termini di colorazione o meno dei pixel. Alle unità SM, di conseguenza, viene esclusivamente affidato l’onere di lanciare il “raggio sonda”, trovandosi di fatto in gran parte libere di svolgere eventualmente altre operazioni grafiche o computazionali.
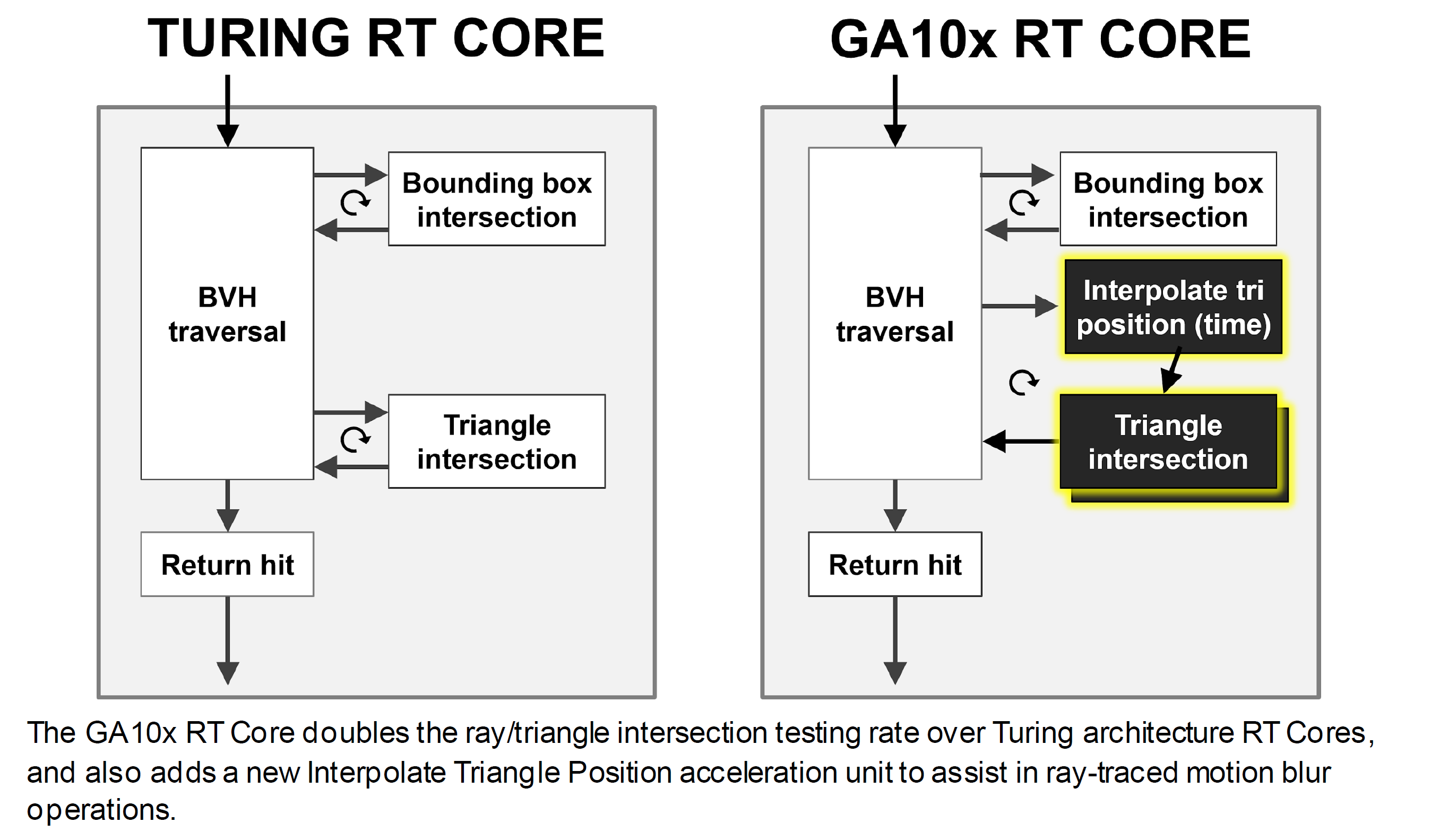
Nelle nuove unità RT Cores di seconda generazione, NVIDIA ha apportato diverse ottimizzazioni; dapprima è intervenuta sull’unità “Triangle Intersection”, velocizzandola e dotandola di risorse dedicate al fine di limitare tutti quegli scenari in cui avrebbe potuto rappresentare un collo di bottiglia, in secondo luogo ha aggiunto una nuova sotto-unità, denominata Interpolate Triangle Position, espressamente pensata per l’implementazione del Motion Blur in ambito Ray-Tracing.
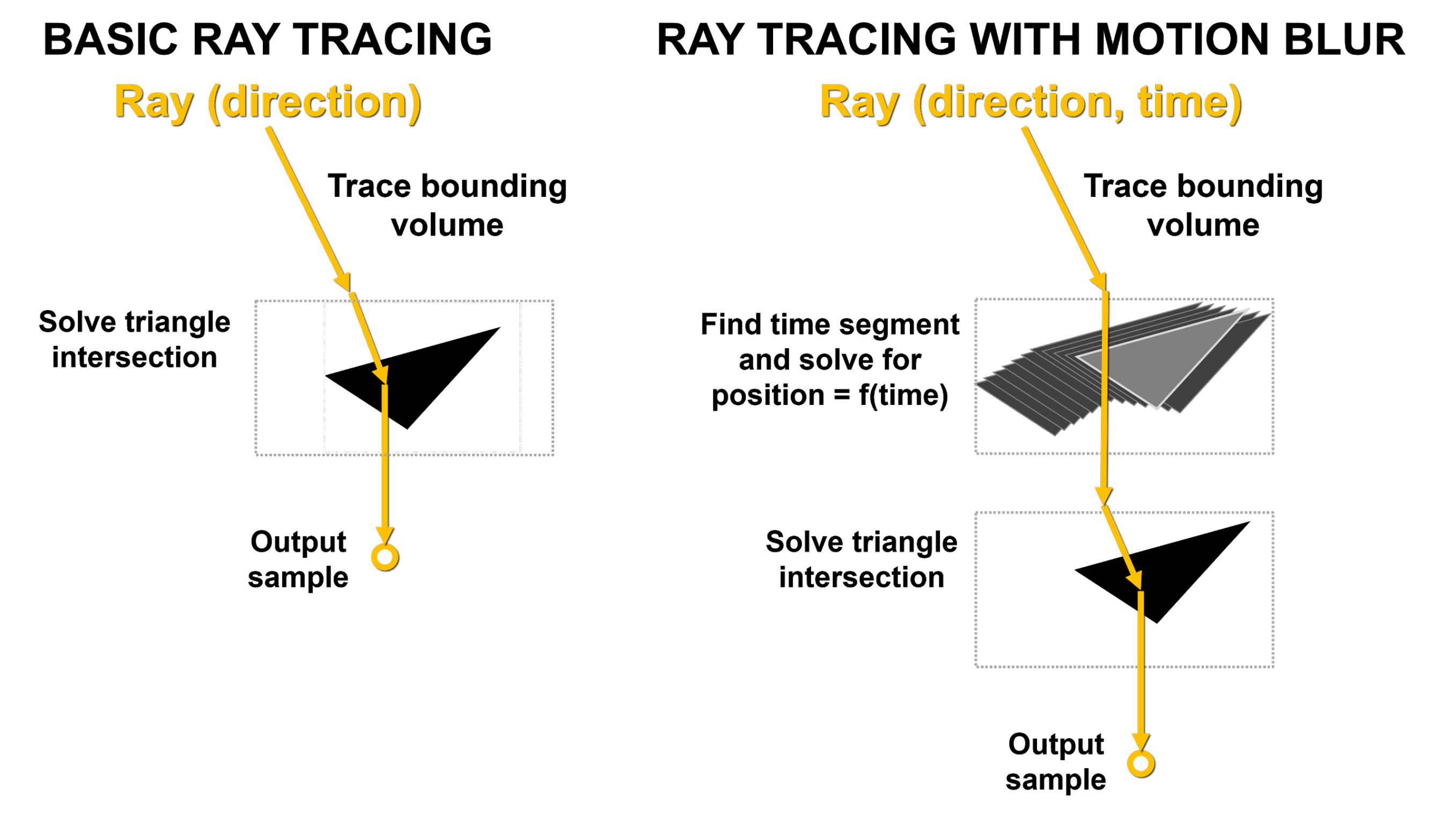
Il Motion Blur è un effetto di computer grafica molto popolare e importante utilizzato in film, giochi e molti diversi tipi di applicazioni di rendering professionali per simulare meglio la realtà o semplicemente per creare interessanti effetti artistici. Per comprenderlo al meglio basta pensare a come una telecamera genera l’effetto. Un’immagine fotografica non viene creata istantaneamente, ma al contrario viene creata esponendo la pellicola alla luce per un periodo di tempo finito.
Gli oggetti che si muovono abbastanza velocemente rispetto all’apertura dell’otturatore della fotocamera appariranno come strisce o macchie nella foto. Affinché una GPU crei sfocature di movimento dall’aspetto realistico quando gli oggetti nella scena (geometrie) si muovono rapidamente davanti a una telecamera statica o la telecamera sta scansionando oggetti statici o in movimento, deve simulare il modo in cui una telecamera e un film riprodurrebbero tali scene.
Gli effetti di sfocatura ad alta qualità possono essere molto dispendiosi in termini di calcolo, spesso richiedendo il rendering e la fusione di più fotogrammi in un determinato intervallo di tempo. Potrebbe essere necessaria anche la post-elaborazione per migliorare ulteriormente i risultati. Un certo numero di trucchi e metodi di scelta rapida vengono spesso utilizzati per il Motion Blur in tempo reale, come nei giochi, ma la sfocatura può mancare di realismo. Ad esempio, le immagini potrebbero essere innaturalmente macchiate, rumorose o presentare artefatti di ghosting/strobo, oppure l’effetto potrebbe mancare del tutto nei riflessi e nei materiali traslucidi.
Al contrario, il Motion Blur con Ray-Tracing può essere più accurato, realistico e senza artefatti indesiderati, ma può anche richiedere molto tempo e notevoli risorse per portarne a termine il rendering su una GPU, soprattutto senza l’accelerazione hardware delle operazioni di Ray-Tracing, parte integrante dell’esecuzione di effetti di sfocatura.
Diversi algoritmi o combinazioni di algoritmi possono essere impiegati per eseguire il Motion Blur con Ray-Tracing. Un metodo diffuso spara casualmente nella scena una serie di raggi con time-stamp. Un BVH in grado di sfocare in movimento restituisce le informazioni sui colpi del raggio rispetto alla geometria che si muove nel tempo, campionate al time-stamp associato a ciascun raggio. Questi campioni vengono quindi ombreggiati e combinati per creare l’effetto sfocato finale.
È possibile riprendere più raggi in una scena e gli RT Cores accelerano i calcoli eseguendo test di intersezione raggio/triangolo e restituendo risultati per creare effetti di sfocatura. Tuttavia, eseguire il Motion Blur sulla geometria in movimento può essere più impegnativo entro un dato intervallo di tempo poiché le informazioni BVH cambiano mentre gli oggetti si muovono.
Ed è proprio questo che rappresenta la sfida più grande a cui hanno dovuto far fronte gli ingegneri NVIDIA; con il Motion Blur i triangoli nella scena non sono più fissati nel tempo. Nel Ray-Tracing di base, ogni triangolo è definito all’interno della struttura di accelerazione BVH. Quando viene tracciato un raggio, vengono eseguiti i test raggio/riquadro di delimitazione e intersezione raggio/triangolo e, se viene colpito un triangolo, le informazioni sul risultato vengono campionate e restituite.
Con il Motion Blur nessun triangolo ha una posizione fissa. Fortunatamente il BVH prevede una formula che possiamo riassumere così: “se mi dici che ore sono, posso dirti dove si trova questo triangolo nello spazio”. Ad ogni raggio viene quindi assegnato un time-stamp che indica il tempo da tracciare, alimentando le equazioni BVH per risolvere la posizione del triangolo e l’intersezione raggio/triangolo. Per ovvi motivi, se questo processo non fosse accelerato dall’hardware della GPU, rappresenterebbe un enorme collo di bottiglia data l’ingente mole da calcoli necessari.
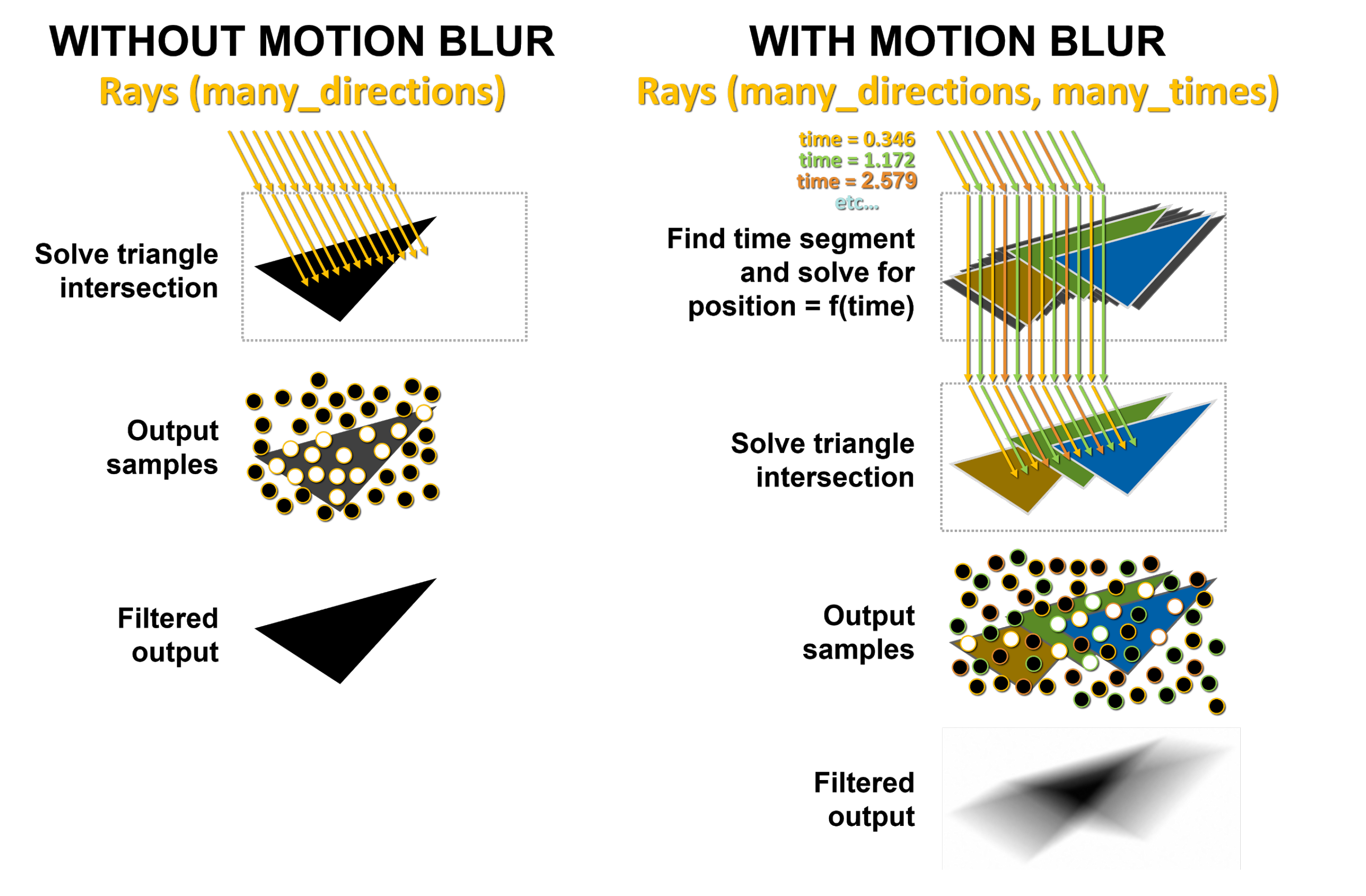
Sul lato sinistro dell’immagine sopra riportata, la ripresa dei raggi nella scena senza movimento potrebbe avere, come mostrato, molti raggi, ma colpiscono tutti lo stesso triangolo nello stesso punto nel tempo. I punti bianchi mostrano dove hanno effettivamente colpito il triangolo e l’output viene prodotto e restituito. Con il Motion Blur, ogni raggio esiste in un momento diverso nel tempo.
Di seguito sono mostrati tre colori dei raggi a scopo illustrativo per differenziarli, ma a ogni raggio viene assegnato in modo casuale un time-stamp diverso. Ad esempio, i raggi arancioni cercano di intersecare triangoli arancioni in punti diversi nel tempo, quindi i raggi verdi e blu cercano di intersecare rispettivamente triangoli verdi e blu. Il risultato è un output filtrato più macchiato e matematicamente corretto come mostrato in basso, derivato da un mix di campioni generati dai raggi che colpiscono i triangoli in diverse posizioni in diversi punti nel tempo.
[nextpage title=”NVIDIA Ampere: Uno sguardo alla nuova architettura – Parte Seconda”]
La nuova unità Interpolate Triangle Position è in grado di generare triangoli nel BVH tra le rappresentazioni triangolari esistenti in base al movimento degli oggetti, in modo che i raggi possano intersecare i triangoli nelle loro posizioni previste nello spazio dell’oggetto ai tempi specificati dai time-stamp dei raggi.
Questa nuova unità consente un rendering accurato della sfocatura del movimento con Ray-Tracing fino a otto volte più veloce rispetto all’architettura GPU di Turing. Il Motion Blur con accelerazione hardware implementato nell’architettura Ampere è pienamente supportato in numerosi software professionali, quali ad esempio Blender 2.90, Chaos V-Ray 5.0, Autodesk Arnold e Redshift Renderer 3.0.X utilizzando l’API NVIDIA OptiX 7.0. L’incremento prestazionale è notevole, una nuova GeForce RTX 3080 è infatti capace di risultare fino a ben cinque volte più veloce di una precedente GeForce 2080 SUPER basata su architettura Turing.

Oltre alle unità di accelerazione dedicate anche varie tecniche di filtraggio avanzate possono aiutare ad incrementare le prestazioni e la qualità dell’immagine senza richiedere l’aggiunta di ulteriori raggi. Il “Denoising” ad esempio consente di migliorare la qualità visiva di immagini disturbate, ovvero costruite con dati sparsi, presentare artefatti casuali, rumore di quantizzazione o altre tipologie di rumore.
Così come esistono diversi tipi e cause di rumore dell’immagine, allo stesso modo esistono anche svariati metodi per risolvere questo genere di problematica. Il Denoising Filtering, ad esempio, consente di ridurre il tempo impiegato al rendering di immagini ray-traced ad alta fedeltà visivamente prive di rumore, sfruttando specifici algoritmi messi a punto da NVIDIA, basati o meno sull’intelligenza artificiale a seconda del caso di applicazione specifico.
Anche la qualità delle ombre è fondamentale per rendere maggiormente realistica l’atmosfera di una scena. Nella maggior parte dei giochi vengono utilizzate tecniche di Shadow Mapping in quanto veloci, semplici da implementare e non richiedono buffer speciali. L’approccio previsto è del tutto semplice e parte dal presupposto che qualunque oggetto visibile da una fonte di luce dovrà per forza apparire illuminato, al contrario qualunque oggetto non visibile sarà in ombra. Il risultato finale, seppur certamente gradevole a vedersi, non potrà certamente vantare il massimo dell’accuratezza.

Il ray-tracing, combinato con il denoising, consente alle GPU Turing e Ampere di superare i limiti delle Shadow Map, come la mancata corrispondenza della risoluzione, che rende difficile generare bordi accurati in presenza di ombre dure, e l’ìndurimento del contatto. Quest’ultimo può essere approssimato con tecniche quali Percentage Closer Soft Shadows (PCSS) e Distance Field Shadows, la prima (PCSS) particolarmente intensiva dal punto di vista computazionale e non ugualmente in grado di generare ombre completamente corrette in presenza di aree di illuminazione arbitrarie; la seconda (DFS) è fortemente limitata dalla geometria statica nelle attuali implementazioni.
Con l’accelerazione del ray-tracing basata su tecnologia NVIDIA RTX, in aggiunta ai sofisticati algoritmi di denoising veloce, le ombre ray-traced possono facilmente sostituire le obsolete Shadow Map e fornire una tecnica pratica per simulare l’indurimento del contatto fisicamente corretto in presenza di qualsiasi tipologia di illuminazione presente.

Come possiamo osservare in quest’ultima immagine, l’implementazione della Shadow Map seppur riesca ad uniformare i bordi delle ombre non è in grado di rappresentare un corretto indurimento dei contatti. Le ombre ray-traced vengono generate dalla stessa fonte di luce direzionale con angoli di cono variabili. Con questa tecnica si possono ricreare, se lo si desidera, ombre con bordi completamente duri (come mostrato nell’immagine in basso a destra con angolo di cono pari a 0°), oppure ombre morbide con indurimento corretto in relazione all’angolo di cono (figure mostrate sulla destra con angolo di cono pari a 1,5° e 10°).

L’aspetto che più mostra i vantaggi, in termini di qualità visiva, del ray-tracing, riguarda però i riflessi, specialmente se utilizzati in scene ricche di materiali speculari e lucidi. Le tecniche più comuni utilizzate oggi, come la Screen-space Reflections, seppur molto costose in quanto a risorse elaborative, spesso producono buchi e artefatti nell’immagine renderizzata.
Le sonde Cubemap, per lo più statiche e a bassa risoluzione, non rappresentano una soluzione accettabile in presenza di materiali lucidi all’interno di scene con illuminazione prevalentemente statica. Le riflessioni planari sono limitate dal numero che può essere generato facendo uso di tecniche basate sulla rasterizzazione.
I riflessi ray-traced, al contrario, combinati con il denoising, evitano tutti questi problemi e producono riflessi privi di artefatti e fisicamente corretti, assicurando un deciso impatto visivo. Nelle immagini che seguono andremo a mostrare l’implementazione della tecnologia NVIDIA RTX all’interno dell’ultimo capitolo dell’apprezzata serie Battlefield, sviluppato da DICE.


Come possiamo osservare l’attivazione della tecnologia RTX assicura un maggior quantitativo di effetti all’interno della scena di gioco. Ad esempio è possibile osservare la rappresentazione di riflessi realistici sulla macchina provocati da un’esplosione scoppiata al di fuori dello schermo. Questo genere di riflessi sarebbe stato impossibile da riprodurre facendo uso di tecniche Screen-space Reflection, restituendo la scena visibile nell’immagine “RTX Off”.


In questa seconda serie di immagini viene mostrato un altro problema alla base dei riflessi di tipo non ray-traced. Nello specifico, nonostante sia presente un parziale riflesso sul suolo, possiamo osservarne la mancanza all’interno del mirino (correttamente riprodotto nella scena “RTX On”).
Sono varie le tecnologie che unite assieme hanno reso possibile la gestione in tempo reale del ray-tracing da parte dei processori grafici Turing e Ampere. Tra queste, volendo fare una breve sintesi, troviamo:
- Rendering Ibrido: riduce la quantità di ray-tracing necessaria nella scena continuando a utilizzare la rasterizzazione per i passaggi di rendering in cui è considerata efficace, limitando il ray-tracing per i passaggi di rendering in cui la rasterizzazione è in difficoltà non riuscendo ad assicurare un impatto visivo realistico;
- Algoritmi di riduzione del rumore (Denoising) delle immagini;
- Algoritmo BVH: utilizzato per rendere le operazioni di ray-tracing molto più efficienti riducendo il numero di triangoli che devono essere effettivamente testati per trovare quelli effettivamente colpiti dai raggi di luce presenti nella scena;
- RT Cores: tutte le ottimizzazioni precedentemente elencate hanno contribuito a migliorare l’efficienza del ray-tracing, ma non abbastanza da renderlo vicino al tempo reale. Tuttavia, una volta che l’algoritmo di BVH è diventato standard, è emersa l’opportunità di realizzare un acceleratore accuratamente predisposto per rendere le operazioni necessarie estremamente più efficienti. Le unità RT Cores messe a punto da NVIDIA sono proprio quell’acceleratore, capace di rendere le GPU notevolmente più veloci nell’elaborazione ray-tracing. Gli RT Cores di seconda generazione, implementati nell’architettura Ampere raddoppiano il tasso di test di intersezione raggio/triangolo rispetto alle precedenti soluzioni Turing, assicurando un livello prestazionale sensibilmente superiore.
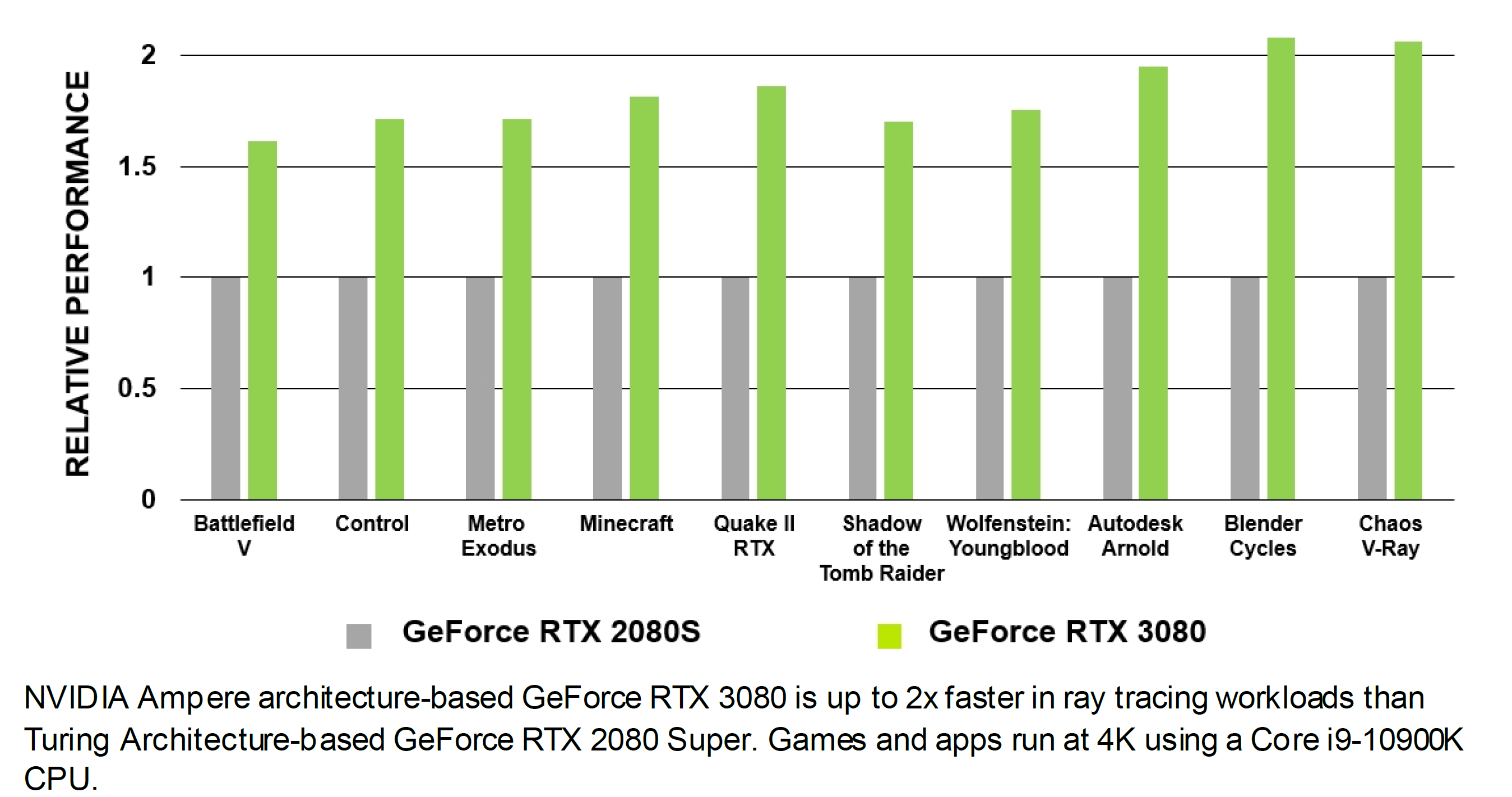
In ambito prettamente videoludico NVIDIA ha mostrato i vantaggi di tutte le migliorie tecnologiche implementate nelle ultime architetture prendendo come esempio l’apprezzato titolo Wolfenstein: Youngblood. Come ormai abbiamo ben compreso, il Ray-Tracing in tempo reale richiede un notevole sforzo computazionale, che sarebbe di gran lunga fuori portata se fosse demandato ai soli shader (CUDA Cores).
Una soluzione grafica priva di unità dedicate, quale ad esempio una vecchia Pascal (GeForce GTX 1000 Series) non sarebbe in grado di assicurare performance accettabili in presenza di calcoli Ray-Tracing a carico dei soli shader. Nell’esempio proposto da NVIDIA, infatti, una GeForce GTX 1080Ti riesce a calcolare un frame tradizionale in 12ms, che salgono a ben 92ms introducendo anche il Ray-Tracing, rendendo il titolo praticamente ingiocabile.
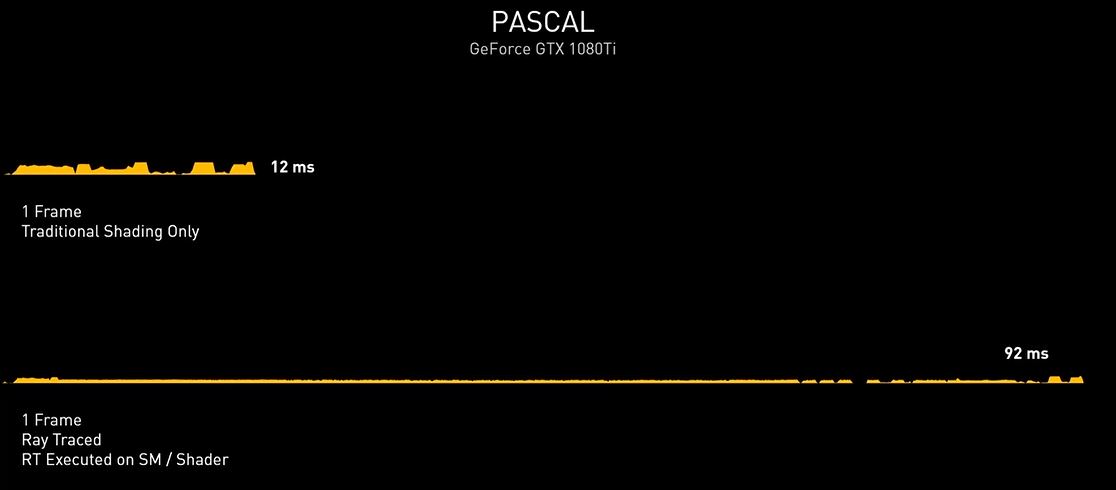
Con l’architettura Turing sono stati ulteriormente ottimizzati gli shader, rendendoli di gran lunga più performanti, arrivando quasi a dimezzare il tempo di rendering e scendendo dai famosi 92ms necessari alla soluzione Pascal, fino ad appena 51ms.
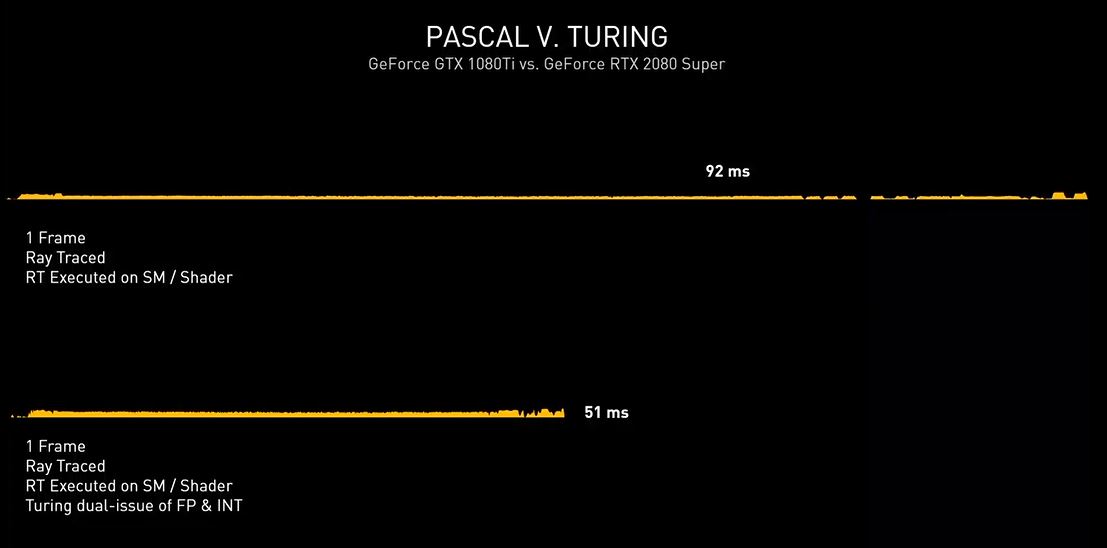
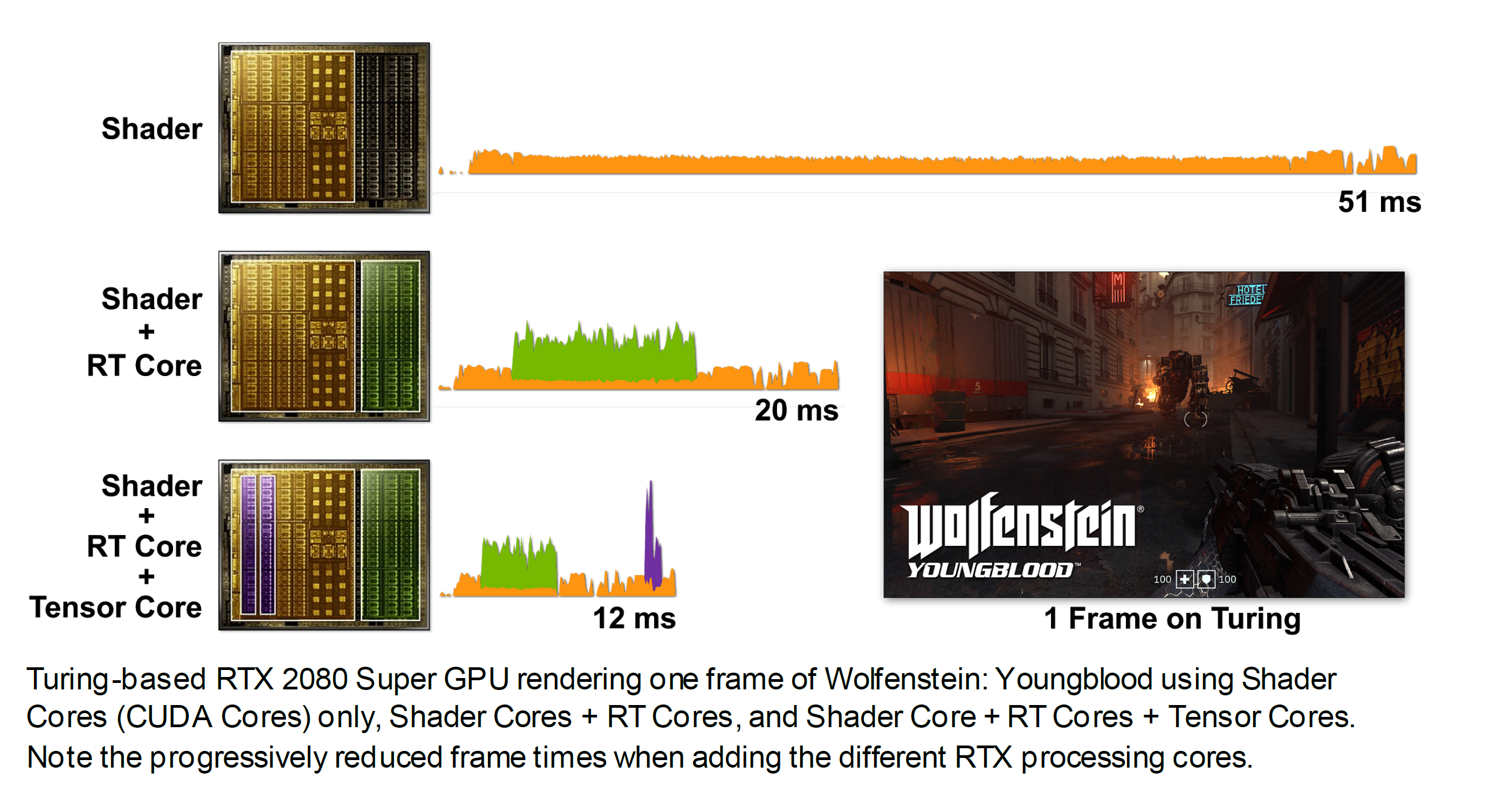
La possibilità da parte di Turing di dirottare parte del lavoro su unità dedicate RT Cores e dei Tensor Cores, però, ha consentito di accelerare ancor più l’elaborazione come possiamo osservare nell’immagine che segue, in cui viene mostrata in azione una GeForce RTX 2080 SUPER. Usando esclusivamente gli shader occorrono 51ms per eseguire questo ipotetico singolo fotogramma (~20FPS). Quando il lavoro di Ray-Tracing viene spostato sugli RT Cores il tempo di rendering si riduce notevolmente, scendendo fino a 20ms (50FPS).
L’utilizzo dei Tensor Cores, per abilitare il DLSS, consente di scendere ulteriormente fino a raggiungere soli 12ms (~83FPS). Tirando semplicemente le somme, nel tempo necessario a Pascal per calcolare un frame tradizionale (12ms), la soluzione Turing è in grado non soltanto di occuparsi dello shading, ma anche del Ray-Tracing tramite RT Cores e di tutti i molteplici calcoli a carico dei Tensor Cores.
La recente architettura Ampere migliora ulteriormente questa situazione, forte di interventi ed ottimizzazioni espressamente mirati ad incrementarne l’efficienza e le prestazioni, quali come abbiamo osservato il raddoppio delle unità in virgola mobile (FP32), il maggior quantitativo e la differente gestione della memoria Cache, oltre che ovviamente la presenza di ancor più veloci unità dedicate RT Cores di seconda generazione.

Il risultato ottenuto è del tutto soddisfacente, basti pensare che viene ancora una volta quasi dimezzato il tempo di rendering necessario, passando dai 19ms della soluzione Turing, ad appena 11ms di Ampere (nel confronto osserviamo una GeForce RTX 2080 SUPER vs GeForce RTX 3080).

Prendendo come riferimento un frame contenente shading, calcoli Ray-Tracing e DLSS, l’architettura Turing impiegherebbe 13ms per portarne a termine l’elaborazione, mentre ad Ampere ne bastano 7,5ms operando nella stessa maniera, che scendono ulteriormente fino ad appena 6,7ms sfruttando l’efficiente esecuzione parallela dei calcoli di cui è capace la nuova architettura messa a punto da NVIDIA.
[nextpage title=”NVIDIA Ampere: Deep Learning Super-Sampling (DLSS) ora fino a risoluzione 8K”]
Nei giochi di ultima generazione i frame renderizzati non vengono visualizzati direttamente sullo schermo, ma al contrario si trovano a dover passare attraverso un processo di miglioramento post-elaborazione dell’immagine che combina l’input di più frame renderizzati al fine di rimuovere artefatti visivi come l’aliasing preservando il più possibile il livello di dettaglio.
Un esempio pratico è il Temporal Anti-Aliasing (TAA), un particolare algoritmo messo a punto da NVIDIA per migliorare la qualità di visione eliminando l’aliasing, basato sulla campionatura tra pixel allo scopo di procedere con operazioni di media e pulizia dell’immagine. Questa tecnica, nonostante sia tra le più comuni in uso al momento, presenta diverse limitazioni, tra le quali spicca un risultato finale, in termini visivi, molto meno nitido rispetto ad esempio al multi-sampling o al super-sampling, che però richiedono molte più risorse per essere applicati.
Proprio per questo motivo i ricercatori NVIDIA si sono impegnati nello studio di soluzioni alternative per l’analisi e l’ottimizzazione delle immagini capaci di assicurare la massima qualità al minimo “costo” prestazionale, arrivando alla conclusione che l’intelligenza artificiale poteva essere la chiave per mettere la parola fine al problema.
Nei capitoli precedenti abbiamo fatto riferimento ad ImageNet, precisando come l’elaborazione e la classificazione delle immagini su larga scala sia l’applicazione d’uso in cui il deep-learning ha mostrato il meglio di sé, raggiungendo una capacità sovrumana nel riconoscere animali, volti, automobili o dettagli specifici nel confronto tra centinaia di migliaia di immagini.
Il principio alla base della tecnica di miglioramento dell’immagine pensata da NVIDIA è fondamentalmente il medesimo, basato quindi sullo sfruttamento della rete neurale per il confronto tra immagini, ma anziché ricercare dettagli o specifiche tipologie di cose o oggetti, ci si limiterà ad osservare i pixel grezzi delle immagini al fine di estrarre informazioni utili per combinare in maniera intelligente i dettagli dei vari fotogrammi così da ottenere un’immagine finale in alta qualità.
Questa nuova tecnica prende il nome di Deep Learning Super-Sampling (DLSS) e, sfruttando una rete neurale (DNN) sviluppata da NVIDIA, assicura un output di qualità superiore rispetto al TAA, andando però quasi a dimezzarne la richiesta elaborativa necessaria a livello di shader.
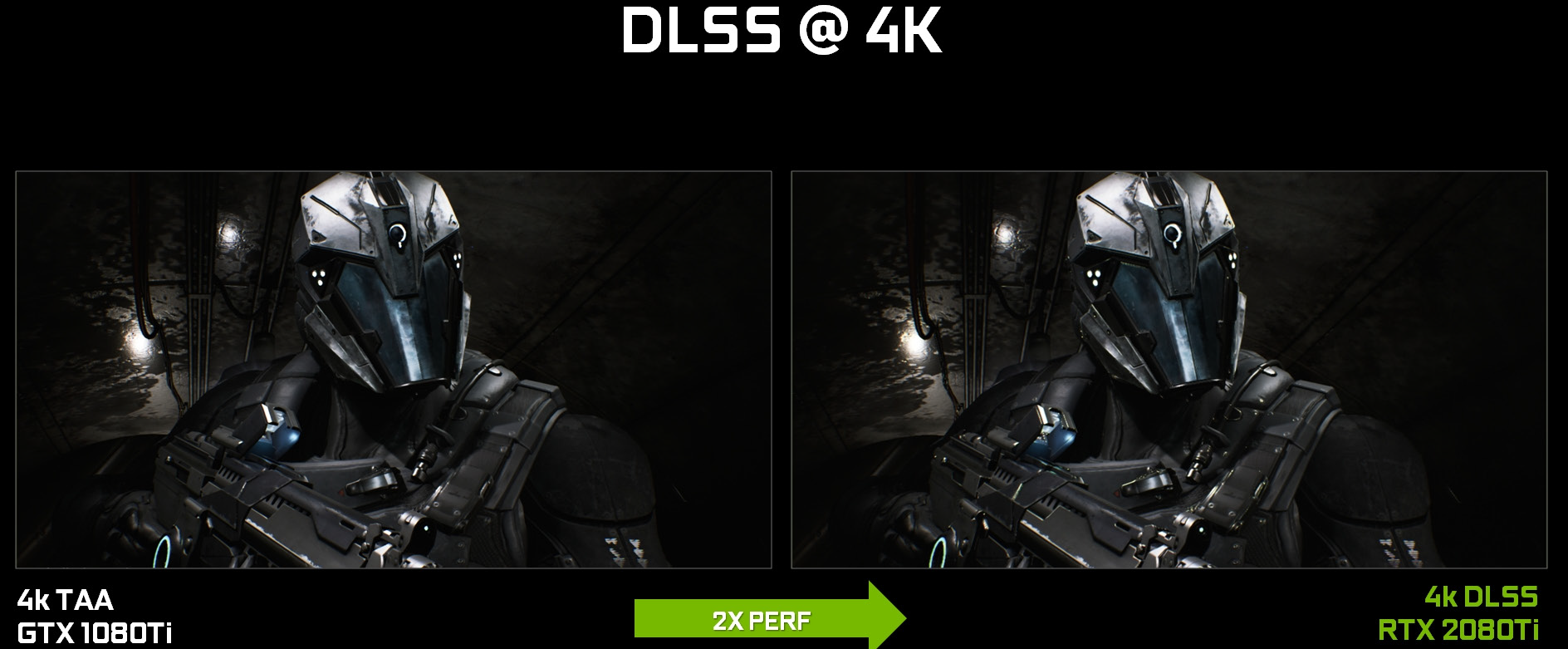
L’immagine sopra riportata mostra un confronto tra il vecchio TAA ed il nuovo DLSS nella demo UE4 Infiltrator. Il Deep Learning Super-Sampling, come possiamo vedere con i nostri occhi, restituisce una qualità dell’immagine molto simile al TAA, ma con prestazioni notevolmente superiori.
La combinazione tra la notevole potenza computazione della nuova GeForce RTX 2080 Ti ed il pieno supporto al DLSS, reso possibile dalla presenza di unità dedicate (Tensor Cores), consente di raddoppiare le prestazioni rispetto alla precedente soluzione di pari fascia GeForce GTX 1080 Ti basata su architettura Pascal.

In varie occasioni il colosso americano ha più volte sottolineato come il DLSS, preso in modalità 2X, sia in grado di riprodurre risultati equivalenti, in termini di definizione dell’immagine, all’applicazione di un tradizionale anti-aliasing super-sampled 64X, quest’ultima però impossibile da gestire in tempo reale con le attuale potenze computazionali disponibili.

La chiave di questo notevole risultato risiede però nel processo di “addestramento” della rete neurale; più immagini di riferimento verranno raccolte dalla DNN di NVIDIA e più sarà possibile ottenere un risultato superiore in termini di qualità dell’immagine. Sono numerosi gli esempi in cui grazie al DLSS si è in grado di ottenere un’immagine finale di qualità paragonabile o addirittura più nitida in alcuni dettagli rispetto alla nativa, pur potendo contare su una maggiore prestazione.

Con la nuova architettura Ampere il DLSS è stato ulteriormente migliorato, sfruttando sia le maggiori prestazioni offerte dalle unità Tensor Core di terza generazione e sia nuovi fattori di scaling, come ad esempio il nuovo “AI Super-Resolution 9X” che rende accessibili per la prima volta risoluzioni elevatissime come l’8K con frame rate di 60 FPS in titoli Ray-Tracing (precisiamo che questa modalità è esclusiva della soluzione di punta della gamma Ampere, vale a dire la GeForce RTX 3090).
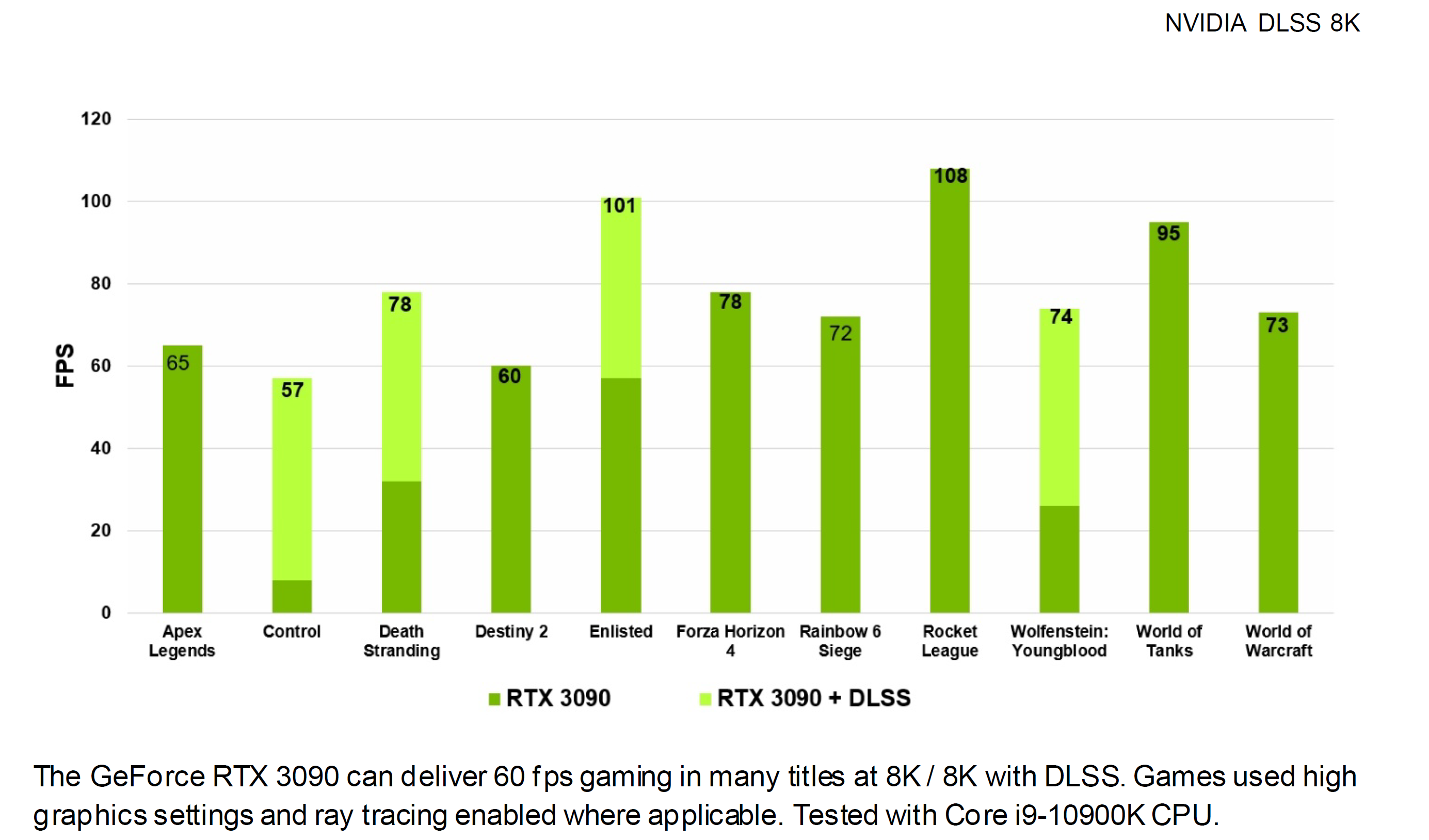
Inutile dire come sia intenzione dell’azienda quella di spingere il più possibile gli sviluppatori ad implementare tale feature in un numero sempre maggiore di titoli. Con l’imminente revisione 3.0 questo sarà ancora più semplice e praticamente immediato, dal momento che l’unico requisito richiesto sarà il supporto, da parte del titolo stesso, del TAA.
[nextpage title=”NVIDIA Ampere: Processore Grafico GA104″]
Con il nuovissimo processore grafico GA104 l’azienda americana porta una ventata d’aria fresca nella fascia medio alta del mercato, con soluzioni certamente più al passo coi tempi e soprattutto capaci di assicurare performance velocistiche complessive sensibilmente superiori alle proposte di pari segmento della passata generazione già in commercio ad un costo competitivo.

In un primo momento vide la luce una prima soluzione consumer basata su una declinazione leggermente depotenziata di questo processore grafico, denominata GA104-300 ed implementata sulle proposte GeForce RTX 3070. Lo scorso mese di giugno, in concomitanza con il lancio della nuova scheda grafica di fascia alta GeForce RTX 3080 Ti, l’azienda californiana, anche grazie a migliori rese produttive migliori, presentò anche la nuovissima GeForce RTX 3070 Ti, basata come prevedibile sulla versione completa del chip GA104 (GA-104-400), nella quale troviamo attive tutte le 48 unità SM, per un totale complessivo di 6.144 CUDA Cores, 192 Texture Mapping Unit (TMU), 192 Tensor Cores e 48 RT Cores. Osserviamo quindi, nel dettaglio, la struttura interna del nuovo processore grafico di fascia medio-alta GA104-400, utilizzato da NVIDIA sulle soluzioni GeForce RTX 3070 Ti:
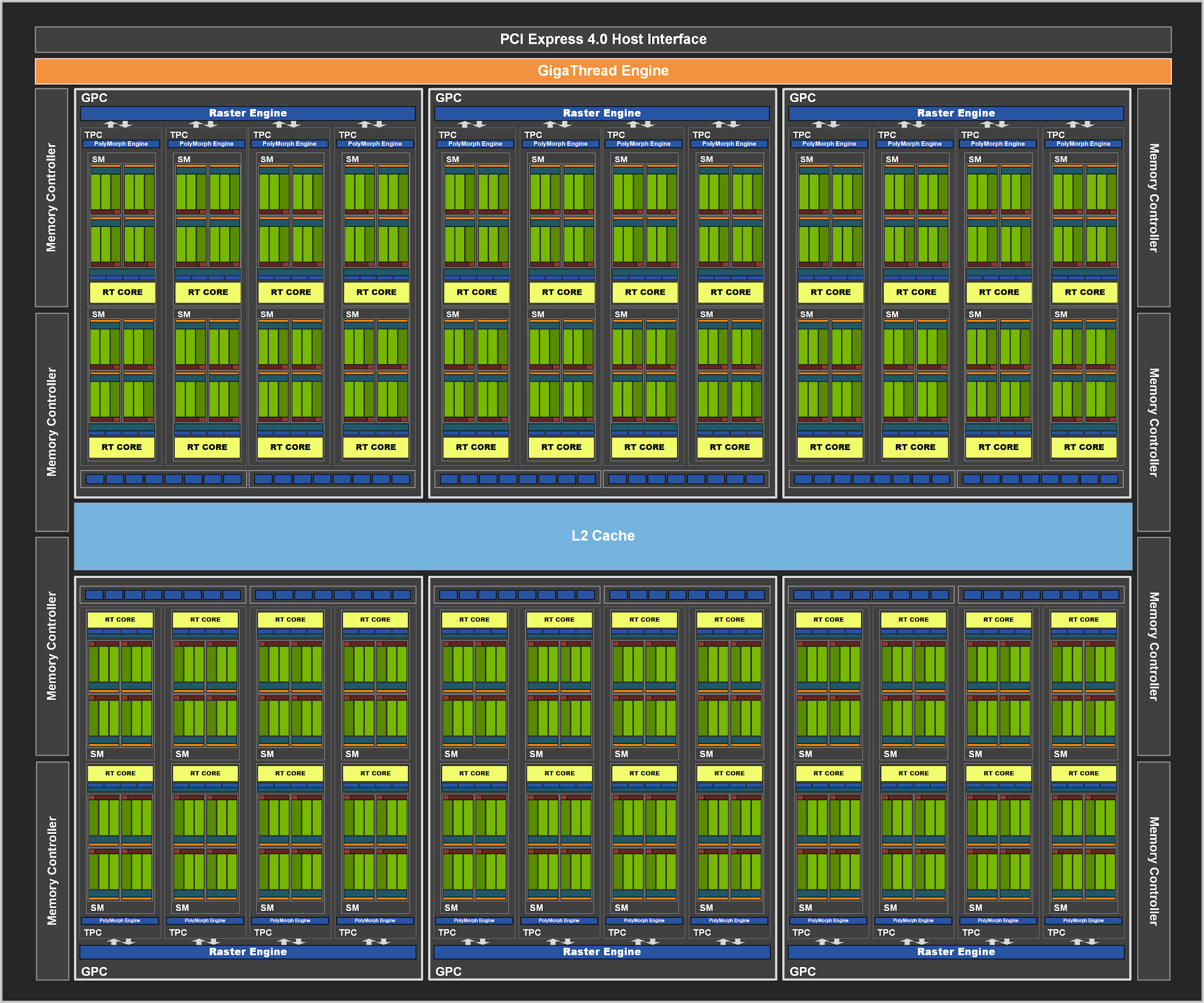
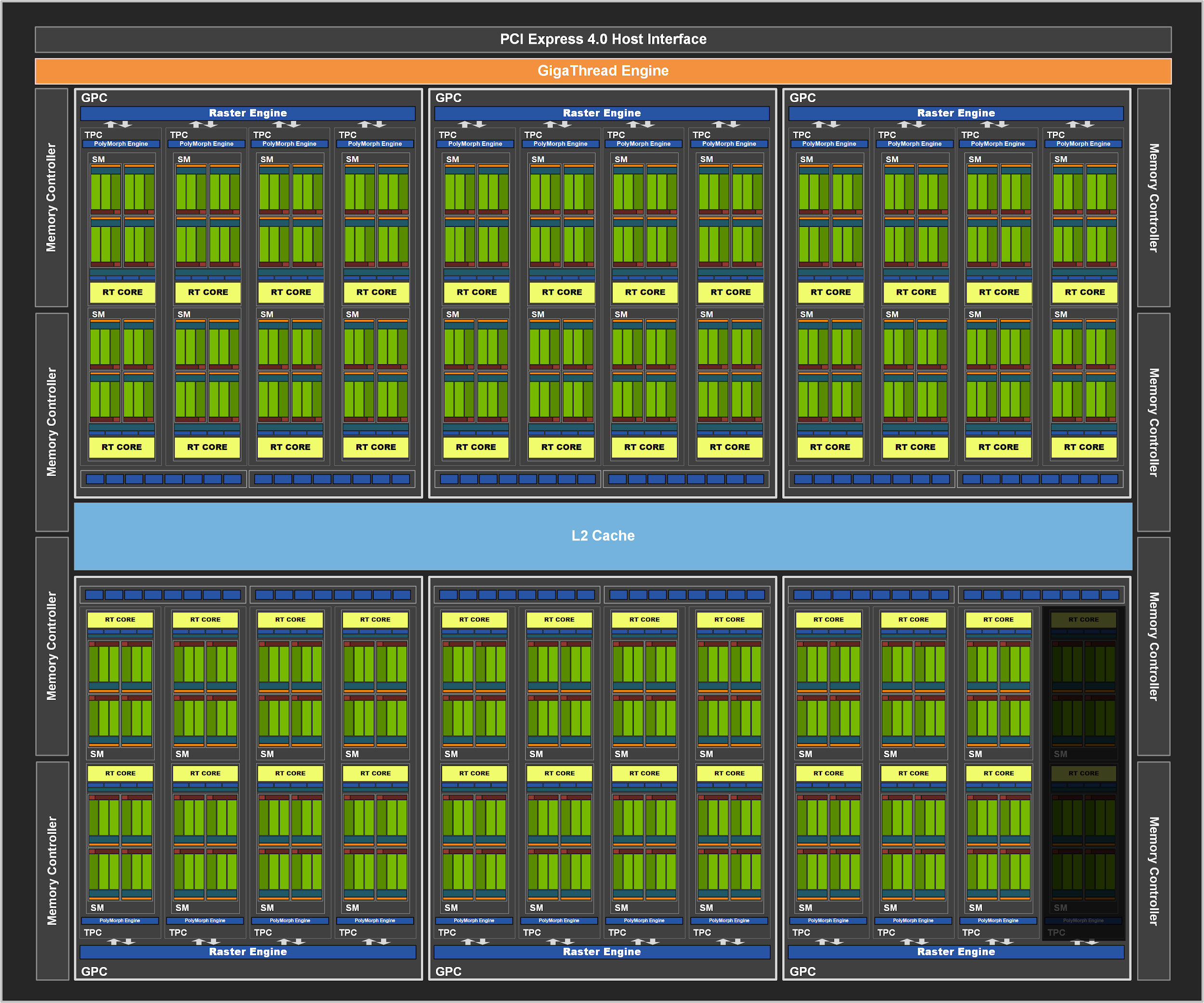
Come vediamo dal diagramma, il blocco principale è ancora una volta denominato GPC (Graphics Processing Cluster) ed include un Raster Engine (per la rimozione di tutti i triangoli non visibili dalla scena, al fine di ridurre la banda necessaria) e quattro blocchi TPC (Thread/Texture Processing Clusters), ognuno formato da un PolyMorph Engine e da una coppia di unità Streaming Multiprocessor, comprendenti, come abbiamo osservato, la maggior parte delle unità fondamentali per l’esecuzione dei calcoli grafici.

Esternamente al blocco Graphics Processing Cluster (GPC), troviamo le unità ROPs (Raster Operator), suddivise in blocchi separati da 8 unità ciascuno, connessi a dei Memory Controller con interfaccia a 32 bit, ed in grado di accedere ad una porzione dei 4.096KB di memoria Cache L2 presenti, nello specifico a 512KB. Ne consegue un bus di memoria aggregato pari a 256-bit ed un totale di 96 unità ROPs completamente sfruttabili.
Non manca, inoltre, un potente Giga Thread Engine, responsabile della suddivisione intelligente del carico di lavoro complessivo tra i tre blocchi GPC che compongono il processore grafico.
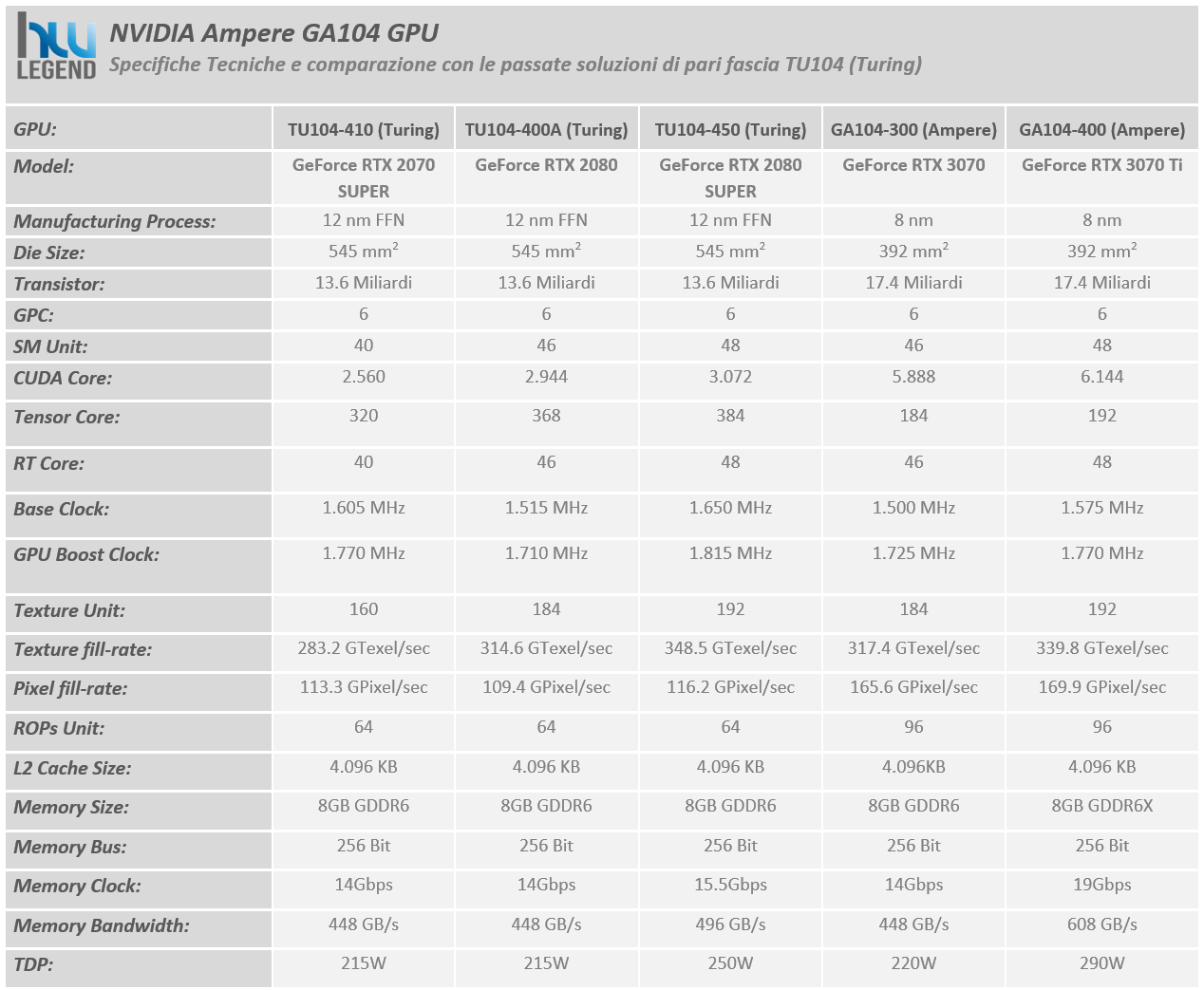
Nella tabella postata appena sopra, abbiamo riassunto le caratteristiche tecniche del nuovo processore grafico GA104 proposto da NVIDIA, posto a diretto confronto con le soluzioni GeForce RTX 2070 SUPER, GeForce RTX 2080 e GeForce RTX 2080 SUPER della passata generazione, basate su architettura Turing e GPU TU104 nelle varie declinazioni previste.
[nextpage title=”NVIDIA Ampere: Display e Gestione dei Flussi Video”]
Con il passare degli anni la richiesta, da parte dei consumatori, di schermi a risoluzione sempre maggiore continua ad aumentare. I giocatori e gli appassionati desiderano pannelli con risoluzioni e frequenze di aggiornamento sempre più elevate, in modo da beneficiare di un maggior livello di definizione dell’immagine associato alla migliore fluidità possibile.
Per questo motivo NVIDIA, in fase di sviluppo dell’architettura Ampere, ha messo a punto un nuovo Display Engine, espressamente pensato per soddisfare le nuove richieste e gestire nel migliore dei modi gli schermi di prossima generazione, contraddistinti da risoluzioni più elevate, frequenze di aggiornamento più veloci e supporto High Dynamic Range (HDR) avanzato.
Le nuove soluzioni grafiche Ampere implementano uscite video Display Port con certificazione 1.4a e pieno supporto VESA Display Stream Compression (DSC) 1.2a per la gestione di schermi a risoluzione 8K (7680 x 4320) con refresh di 60Hz e High Dynamic Range (HDR) oppure 4K (3840 x 2160) con refresh fino a ben 240Hz, sempre con HDR.
Presente anche una connessione HDMI conforme al nuovo standard 2.1, capace di assicurare una bandwidth massima pari a ben 48Gbps, così da poter gestire senza alcun impedimento schermi con risoluzione 8K (7680 x 4320), refresh 60Hz e HDR con un singolo cavo. Anche in questo caso viene implementato il supporto High-bandwidth Digital Content Protection (HDCP) 2.3, oltre al VESA DSC 1.2a.

HDR e Gestione dei Flussi Video
Il nuovo Display Engine di Ampere riconferma il pieno supporto per l’elaborazione di contenuti High Dynamic Range (HDR) in modo nativo all’interno della pipeline, prevedendo, rispetto alla precedente generazione, anche un supporto hardware alla mappatura dei toni. Questa tecnica, utilizzata per approssimare l’aspetto di immagini HDR su schermi al contrario di tipo Standard Dynamic Range (SDR), richiedeva, nell’implementazione prevista nelle vecchie soluzioni Pascal, una mole di calcoli non indifferente, che inevitabilmente aggiungevano latenza. Supportata, inoltre, la formula di Tone Mapping definita dallo standard ITU-R Recommendation BT.2100, al fine di evitare il fenomeno del “color shift” su diversi display HDR.
Oltre a questo, numerose migliorie coinvolgono la componente hardware dedicata alla codifica e decodifica dei contenuti video. Le nuove GPU Ampere, infatti, vantano un’unità encoder NVENC potenziata di settima generazione che fornisce codifica video basata su hardware completamente accelerata ed è indipendente dalle prestazioni grafiche. La codifica video può essere un’attività complessa dal punto di vista computazionale e con la codifica dislocata su NVENC, il processore grafico e la CPU sono liberi per gestire altre operazioni.
Con le impostazioni di streaming comuni di Twitch e YouTube, la codifica hardware basata su NVENC nelle GPU Ampere supera la qualità di codifica X264 basati su software utilizzando il preset Fast ed è alla pari con X264 Medium, un preset che in genere richiede una configurazione a doppio PC. La codifica 4K è un carico di lavoro troppo pesante per una tipica configurazione della CPU, ma l’encoder NVENC di Ampere assicura la codifica ad alta risoluzione senza problemi fino a 4K su H.264 e persino 8K su HEVC.
Sono stati inoltre previsti interventi anche sul decoder NVDEC, giunto alla sua quinta generazione, allo scopo di implementare il supporto alla decodifica di numerosi codec video in ambiente Windows e Linux fino alla risoluzione 8K. Nello specifico viene assicurata l’accelerazione in hardware di MPEG-2, VC-1, H.264 (AVCHD), H.265 (HEVC), VP8, VP9 ed AV-1 ad 8/10 o 12-bit.
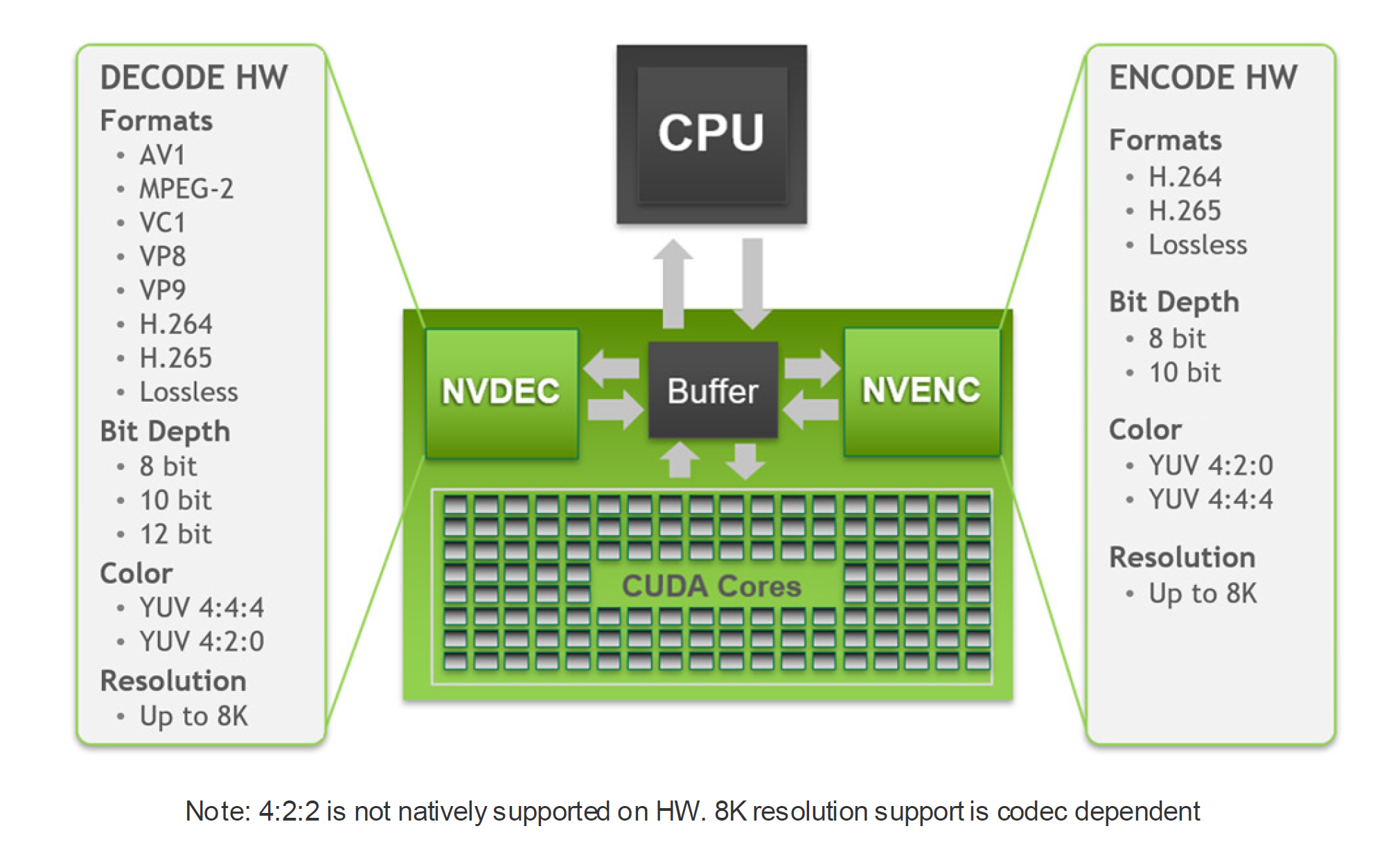
Quest’ultimo rappresenta la più grande novità introdotta da Ampere rispetto alla precedente generazione. AV-1, anche noto come AOMedia Video 1, è un formato di codifica video aperto e privo di royalty sviluppato da AOM (Alliance for Open Media), progettato principalmente per trasmissioni video su Internet.
Le GPU Ampere GA10x sono le prime sul mercato a fornire il supporto per la sua decodifica hardware. AV1 fornisce una compressione e una qualità migliore rispetto ai codec esistenti come H.264, HEVC e VP9, e viene adottato da molte delle principali piattaforme video e browser. AV1 assicura generalmente un risparmio di velocità in bit del 50-55% rispetto ad H.264 ma, sebbene sia molto efficiente nel comprimere video, la decodifica è molto impegnativa dal punto di vista computazionale. Gli attuali decoder software causano un elevato utilizzo della CPU e faticano a riprodurre risoluzioni elevate.

Test interni condotti da NVIDIA facendo uso di una CPU Intel Core i9 9900K hanno registrato una riproduzione media di 28 FPS con un video HDR 8K 60Hz su YouTube e l’utilizzo della CPU è stato superiore all’85%. Le GPU Ampere GA10x possono riprodurre AV1 scaricando la decodifica su NVDEC, che è in grado di riprodurre contenuti HDR fino a 8K 60Hz con un utilizzo della CPU molto basso (~4% sulla stessa CPU del test precedente).
[nextpage title=”INNO3D GeForce RTX 3070 Ti X3 OC: Confezione e Bundle”]
La nuovissima INNO3D GeForce RTX 3070 Ti X3 OC è giunta nella nostra redazione all’interno della confezione originale prevista dal produttore asiatico. La scatola, contraddistinta da dimensioni abbastanza generose, è realizzata con un cartoncino resistente e capace di assicurare l’integrità della scheda grafica, nonché della dotazione accessoria, anche nell’eventualità di un trasporto movimentato. La finitura superficiale è semi-lucida e vengono riportate numerose informazioni circa le principali caratteristiche del prodotto.
Sulla parte frontale domina una generosa immagine di un demone pronto a sferrare il colpo mortale, aspetto che ci permette di intuire fin da subito l’obiettivo da parte dell’azienda di enfatizzare le potenzialità del prodotto. In basso a sinistra possiamo notare la dicitura “Dual Slot”, che ci permette di intuire fin da subito che la scheda grafica adotta un sistema di dissipazione del calore del tutto compatto di tipo proprietario e, in questo specifico modello, contraddistinto dalla presenza di tre ventole di raffreddamento efficienti e silenziose (X3 Edition).
Spostandoci sulla parte destra troviamo l’indicazione circa il quantitativo e la tipologia di memoria grafica prevista, pari a 8GB di tipo GDDR6X, e l’ampiezza del bus di memoria, pari a 256-bit. Nella parte bassa, invece, è riportata la nomenclatura della scheda grafica, il tipo di GPU installata, basata sulla nuovissima architettura Ampere, e le principali caratteristiche di rilievo implementate, tra le quali citiamo la compatibilità con il software di gestione proprietario TuneIT (che osserveremo nel dettaglio in seguito) ed il pieno supporto alla tecnologia DLSS e al Ray-Tracing in tempo reale, aspetto di spicco in ambito consumer.

Nella parte posteriore viene nuovamente riportata la nomenclatura del prodotto ed il marchio aziendale, nonché una panoramica di quelli che sono i punti di forza più significativi del nuovo processore grafico NVIDIA Ampere, tradotti nelle lingue dei vari paesi in cui il prodotto viene commercializzato, italiano compreso.

Nelle fasce laterali ritroviamo l’immancabile logo aziendale, la nomenclatura della scheda grafica e la tipologia di GPU installata. Sulla fascia sinistra trova posto una piccola etichetta adesiva riportante tutti i vari codici identificativi e seriali della scheda grafica.


Aprendo la confezione troviamo un’ulteriore scatola in cartone rigido di colore nero, davvero molto resistente e curata. Al suo interno trova posto la scheda grafica, adeguatamente protetta all’interno di un tradizionale sacchetto anti-statico e da una coppia di spallette realizzate in schiuma poliuretanica compatta, nonché tutto il materiale fornito in dotazione.




Il bundle fornito in dotazione è abbastanza minimale, ma comprende ugualmente tutto il necessario per sfruttare fin da subito la nuova scheda grafica. Troviamo, infatti:
- 1x Guida alla scelta dell’alimentatore più idoneo;
- 1x Manuale rapido di installazione.

Passiamo ora ad analizzare la scheda e le sue caratteristiche tecniche.
[nextpage title=”INNO3D GeForce RTX 3070 Ti X3 OC: Caratteristiche Tecniche”]

La scheda video INNO3D GeForce RTX 3070 Ti X3 OC è costruita attorno al nuovissimo processore grafico di fascia alta GA104-400 di NVIDIA, basato su architettura Ampere, e differisce dalla soluzione di riferimento sia in termini di PCB, in questo caso di tipo custom, e sia per quanto riguarda il particolare sistema di dissipazione del calore impiegato, di tipo proprietario a tripla ventola e doppio slot, contraddistinto da un aspetto estetico del tutto accattivante e, come vedremo in seguito, da ottime performance.

La soluzione in esame viene commercializzata con frequenze operative fedeli alle specifiche sancite da NVIDIA sia per quanto riguarda il base clock, fissato a 1.575MHz e sia per quanto concerne i nuovissimi moduli di memoria GDDR6X (ovviamente prodotti da Micron), fissati a ben 1.188MHz (19Gbps effettivi).

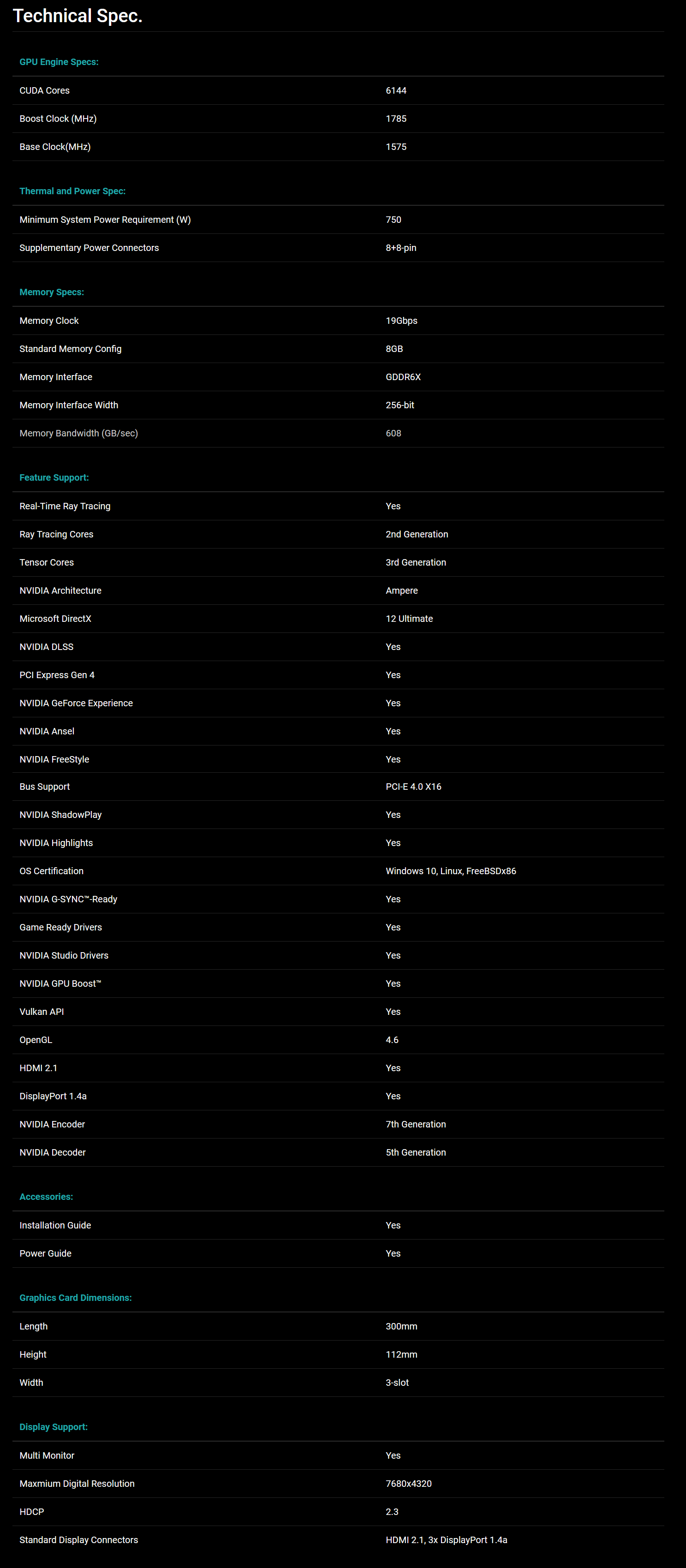
L’unica, seppur lieve, differenza è rappresentata dalla frequenza di boost clock, per la quale è stato previsto un aumento di 15MHz rispetto alle specifiche di riferimento, raggiungendo così quota 1.785MHz (anziché 1.770MHz), intervento che si ripercuoterà in maniera certamente positiva e del tutto proporzionale sulle pure prestazioni velocistiche della scheda. Riportiamo di seguito un riassunto delle principali caratteristiche tecniche e funzionalità esclusive così come dichiarate dal produttore:

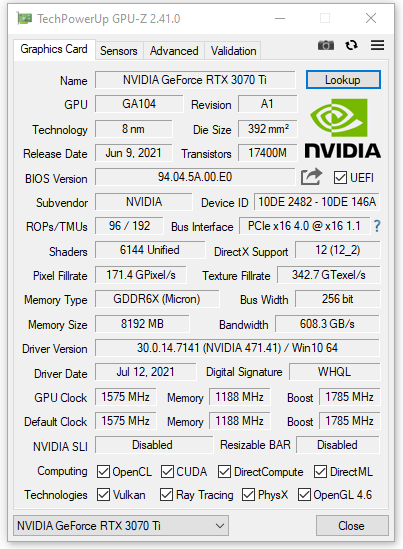
Il software GPU-Z, aggiornato all’ultima versione al momento disponibile (2.40.0), rileva correttamente le caratteristiche fisiche e le frequenze operative della scheda grafica e ne riportiamo uno screen.
Per ulteriori informazioni è possibile consultare la pagina web dedicata al prodotto sul sito INNO3D.
[nextpage title=”INNO3D GeForce RTX 3070 Ti X3 OC: Software in dotazione”]

Il produttore ha previsto, anche per la sua nuovissima soluzione grafica GeForce RTX 3070 Ti X3 OC, un interessante software proprietario che ci permetterà di gestire e configurare al meglio numerosi parametri avanzati. Stiamo parlando dell’ottimo TuneIT OC Utility.
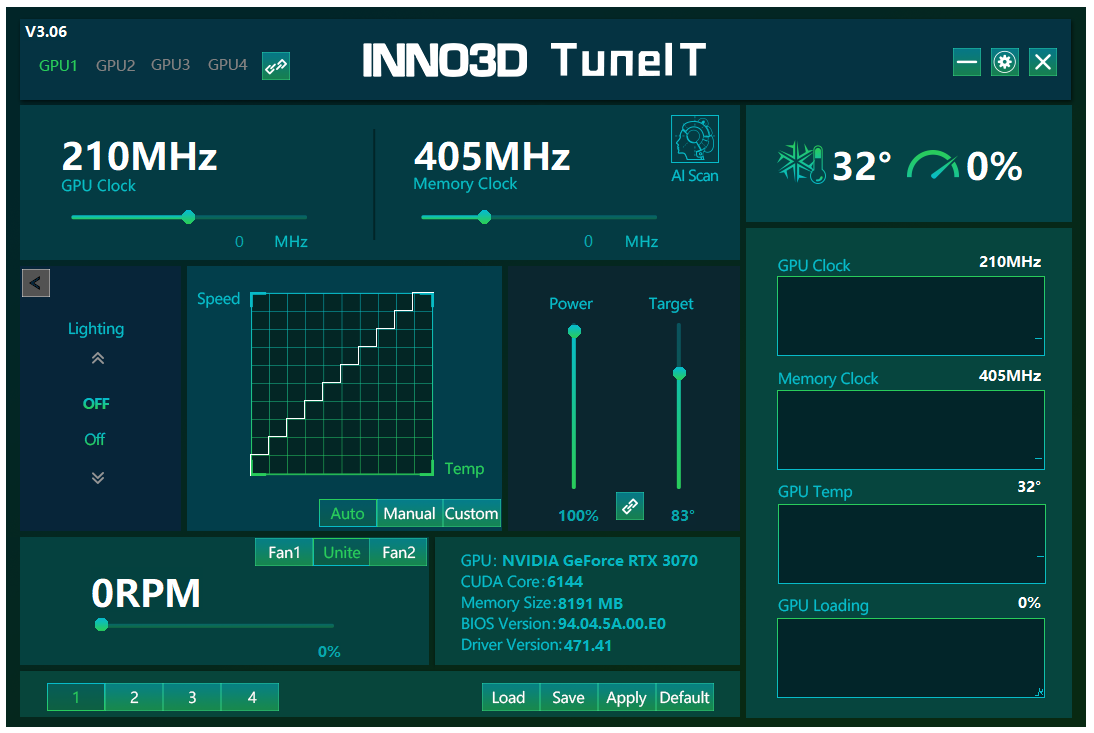
Una volta installato ed eseguito notiamo fin da subito un’interfaccia senza dubbio molto intrigante, ma per la gioia degli utenti meno smaliziati, anche decisamente ordinata ed intuibile. Ai lati sono presenti una serie di grafici che mostrano la frequenza e la percentuale di utilizzo del processore grafico e dei moduli di memoria in tempo reale.
Poco più in alto, invece, la temperatura d’esercizio della GPU e la relativa percentuale utilizzo. La parte centrale della schermata del programma è dedicata al rilevamento e all’eventuale impostazione delle frequenze operative e di alcuni parametri avanzati utili in fase di overclocking, tra cui il Power Limit, il regime di rotazione delle ventole e la soglia critica di temperatura della GPU.
Non manca, infine, la possibilità di salvare i parametri immessi sotto forma di comodi profili (fino a massimo di quattro), in maniera da poterli velocemente ricaricare con un semplice click del mouse.
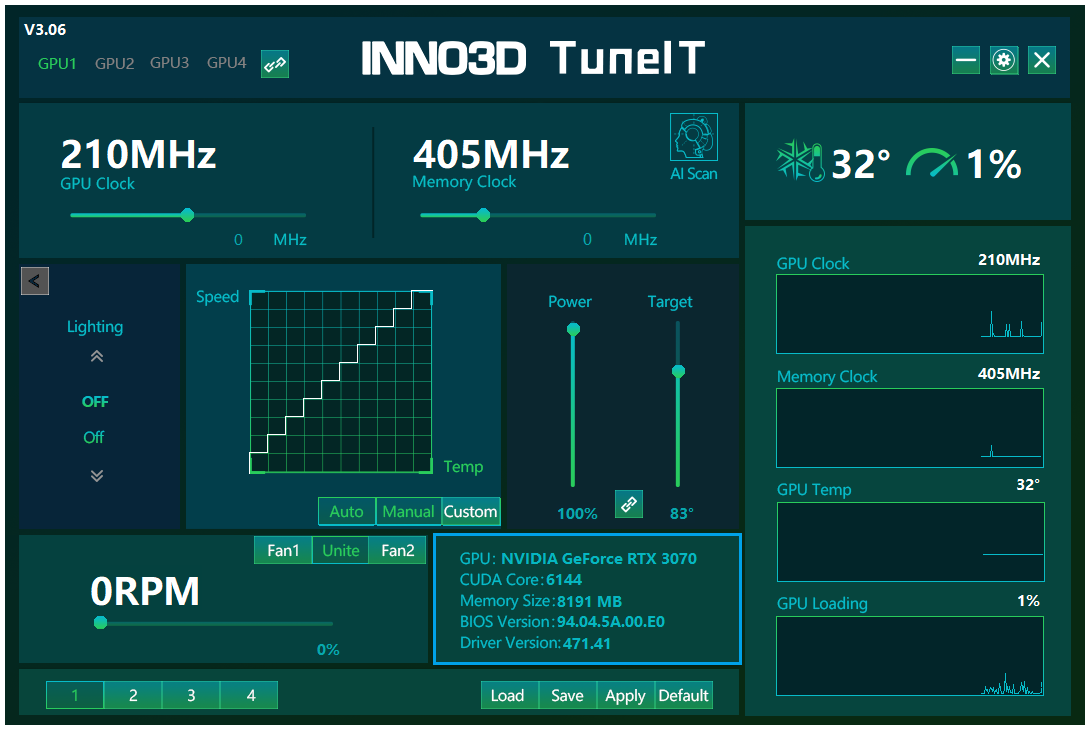
Poco più in basso è prevista una sorta di sezione “Information”, che ci permetterà di conoscere le principali specifiche tecniche della nostra scheda grafica, quali ad esempio il tipo di GPU ed il quantitativo di memoria di cui è dotata, la versione del BIOS presente) ed infine la versione dei driver grafici installati.
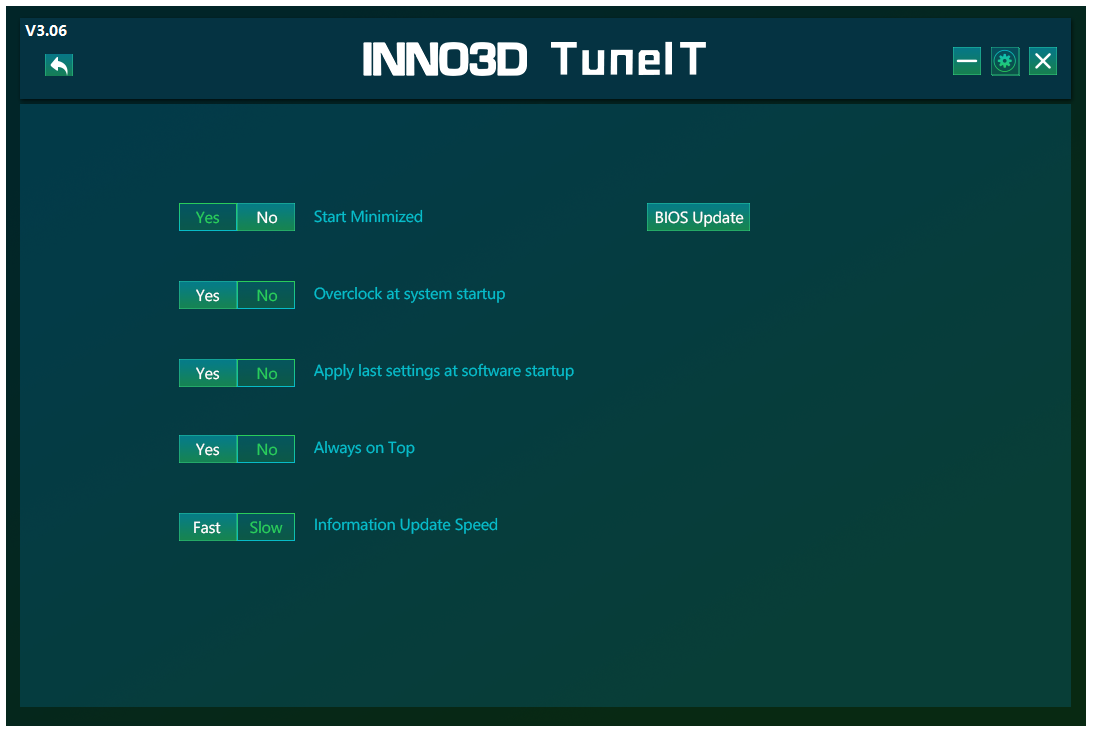
Premendo, invece, il pulsante “Setting” verrà mostrato un piccolo pannello in cui sarà possibile impostare alcune funzionalità avanzate del programma, tra cui l’avvio automatico all’accesso nel sistema operativo e la possibilità di applicare il profilo di overclock in automatico.
Il dissipatore di calore messo a punto da INNO3D per questo specifico modello non implementa un sistema di illuminazione a LED di tipo RGB. Di conseguenza, la sezione del software dedicata per l’appunto alla personalizzazione del colore e dell’effetto dell’illuminazione non è attiva.
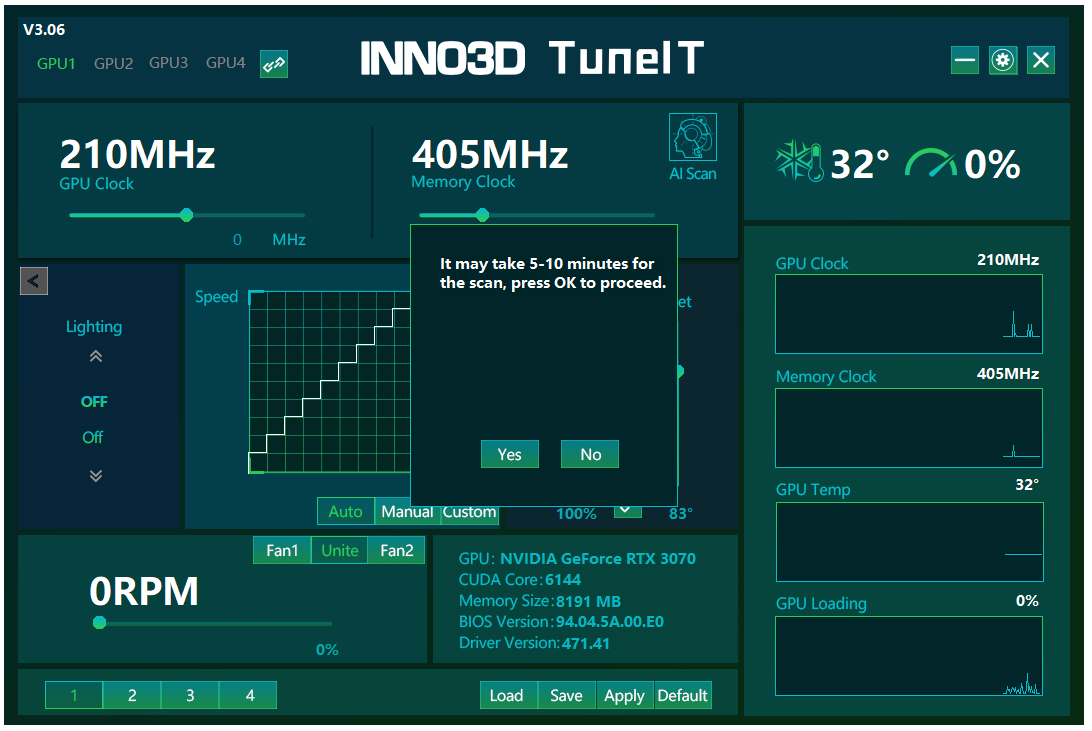
Concludiamo con la funzionalità di overclocking automatico AI Scanner prevista dal programma. Sarà sufficiente premere il tasto dedicato, collocato nella parte alta della schermata principale, per avviare la procedura di ricerca della frequenza stabile ottimale del proprio processore grafico, procedura che, come indicato dal programma stesso, richiederà dai cinque ai dieci minuti per essere portata a termine.
[nextpage title=”INNO3D GeForce RTX 3070 Ti X3 OC: La scheda”]
La nuova INNO3D GeForce RTX 3070 Ti X3 OC si presenta con un aspetto certamente molto particolare, dettato dal dissipatore proprietario che gli conferisce un tono aggressivo e accattivante che lascia subito presagire l’intento del produttore di creare un oggetto dedicato ad una platea di giocatori che amano unire l’estetica a prestazioni velocistiche di assoluto livello.


La prima cosa che colpisce nel toccare con mano questo prodotto è certamente la notevole robustezza e la grande cura nei particolari. Le dimensioni sono indubbiamente generose, pari a 30cm di lunghezza, con un ingombro che però si mantiene entro i 2 slot in altezza.


Posteriormente troviamo un appariscente backplate in alluminio di colore nero, pensato non soltanto per fini puramente estetici, ma anche e soprattutto per assicurare una maggiore protezione dei componenti, conferire maggiore rigidità alla scheda e dissipare, seppur passivamente, parte del calore generato dal processore grafico e dalla circuiteria di alimentazione.



Non manca una connessione PCIe compatibile con il recente standard 4.0 che si attiverà installando la scheda su sistemi in grado di fornire tale supporto. Ne consegue che, almeno per il momento, tale supporto sia garantito esclusivamente dalle più recenti piattaforme Intel di classe mainstream (PCH Serie 400 e 500 in abbinamento a microprocessori di undicesima generazione “Rocket Lake”) ed AMD di classe mainstream ed High-End Desktop (HEDT), in abbinamento ai relativi microprocessori Ryzen e Ryzen Threadripper.

Grazie alla nuovissima architettura “Ampere”, sviluppata utilizzando l’avanzato processo produttivo a 8 nanometri custom NVIDIA (8N) della coreana Samsung, sono stati definiti nuovi valori di riferimento per quanto riguarda l’efficienza energetica, consentendo TDP particolarmente contenuti in relazione alle performance velocistiche espresse.
La soluzione messa a punto da INNO3D si mantiene fedele a quelle che sono le specifiche di riferimento di NVIDIA per le nuovissime proposte GeForce RTX 3070 Ti (non Founders Edition), prevedendo una coppia di connettori supplementari di tipo PCI-Express ad 8-Pin, più che sufficienti a soddisfare le richieste energetiche della scheda grafica e consentire anche un ulteriore e discreto margine di manovra in overclocking.

Le nuove soluzioni grafiche Ampere implementano uscite video Display Port con certificazione 1.4a e pieno supporto VESA Display Stream Compression (DSC) 1.2a per la gestione di schermi a risoluzione 8K (7680 x 4320) con refresh di 60Hz e High Dynamic Range (HDR) oppure 4K (3840 x 2160) con refresh fino a ben 240Hz, sempre con HDR.
Presente anche una connessione HDMI conforme al nuovo standard 2.1, capace di assicurare una bandwidth massima pari a ben 48Gbps, così da poter gestire senza alcun impedimento schermi con risoluzione 8K (7680 x 4320), refresh 60Hz e HDR con un singolo cavo. Anche in questo caso viene implementato il supporto High-bandwidth Digital Content Protection (HDCP) 2.3, oltre al VESA DSC 1.2a.

Come da nostra abitudine, ormai consolidata, non abbiamo resistito alla curiosità di smontare la scheda video per meglio osservare l’interno della GeForce RTX 3070 Ti X3 OC.

La rimozione del sistema di dissipazione del calore proprietario utilizzato, seppur non risulti particolarmente complicata, necessita sicuramente di un po’ più di tempo rispetto alle soluzioni più tradizionali.

È opportuno avvisare, inoltre, che tale operazione comporta la perdita della garanzia del prodotto, anche se non si evidenzia la presenza di particolari sigilli adesivi su alcuna vite di fissaggio.

Per prima cosa è necessario rimuovere il generoso blocco principale, dedicato allo smaltimento del calore generato dal complesso processore grafico di fascia alta GA104. Per farlo è sufficiente svitare alcune viti di fissaggio poste nel retro e nella fascia anteriore e posteriore della scheda grafica.

Successivamente, per riuscire a separare completamente il blocco dissipante dalla scheda grafica, è necessario scollegare i cavi di alimentazione delle ventole presenti.

A questo punto il grosso del “lavoro” è praticamente fatto e possiamo cominciare ad intravvedere cosa si cela al di sotto del compatto dissipatore “Dual-Slot X3 Edition”.
[nextpage title=”INNO3D GeForce RTX 3070 Ti X3 OC: La scheda – Parte Prima”]
Il blocco dissipante principale appare certamente generoso nelle dimensioni, oltre che indubbiamente molto curato e prevede una serie di heatpipes in rame nichelato dal buon diametro, in grado di trasportare efficientemente e uniformemente il calore generato dal processore grafico e dai moduli di memoria sull’ampia superficie a disposizione.

Lo smaltimento del calore è, infine, assicurato dall’impiego di ben tre ventole da 92 mm di diametro e undici pale, capaci di ottime prestazioni e buona silenziosità, grazie al supporto verso la tecnologia Intelligent FAN Stop 0dB, che provvederà ad interromperne completamente la rotazione nel momento in cui la GPU non viene sfruttata (Idle Mode) e la sua temperatura di esercizio non raggiunge la soglia prefissata (<35°C).

Appare innegabile come il produttore asiatico abbia curato fin nei minimi particolari la dissipazione del calore della propria soluzione grafica, prevedendo una generosa piastra metallica, provvista di PAD termo-conduttivi di buona qualità, posta a diretto contatto sia con i moduli di memoria che con le componenti “calde” della circuiteria di alimentazione.


La rimozione dell’intero sistema di dissipazione ci offre l’opportunità di poter osservare con più attenzione il PCB della scheda grafica che, come anticipato, è di tipo custom proprietario, con design sensibilmente diverso da quello previsto da NVIDIA per le soluzioni di riferimento basate su GPU GeForce RTX 3070 Ti.


Il primo particolare che cattura la nostra attenzione è la pulizia del circuito stampato, che risulta davvero ben organizzato, anche grazie alle maggiori dimensioni in lunghezza. Un altro aspetto che colpisce immediatamente lo sguardo è il particolare design adottato, con parte finale a V che ricorda la forma delle soluzioni Founders Edition di NVIDIA, è che consente una migliore dissipazione del calore generato dal processore grafico, con minore rischio di surriscaldamento anomalo della scheda.
È innegabile che INNO3D, sotto questo punto di vista, ha svolto un lavoro veramente impeccabile. In posizione pressappoco centrale trova posto il nuovo processore grafico di fascia media GA104-400-A1, sviluppato con tecnologia produttiva ad 8 nanometri custom NVIDIA (8N) dalla coreana Samsung e contraddistinto da ben 17.4 Miliardi di Transistor integrati in una superficie del Die di 392 mm2. Ne consegue una densità estremamente elevata, pari a ben 44 Milioni di Transistor per mm2.

Tutti attorno sono collocati gli otto moduli di memoria GDDR6X a disposizione, da 1.024MB ciascuno, per un totale complessivo di 8.192MB di memoria grafica dedicata. I moduli utilizzati, nello specifico dei MT61K256M32JE-19G:T, sono come intuibile prodotti da Micron, riportano la serigrafia “IBT77 D8BWW” e sono accreditati per una frequenza operativa pari a ben 1.188MHz (19Gbps effettivi), ovvero la medesima prevista da NVIDIA per le soluzioni GeForce RTX 3070 Ti di riferimento dedicate al mercato consumer. Tale frequenza, in abbinamento al bus da 256-bit, assicura una banda passante a completa disposizione del processore grafico veramente elevatissima, pari a ben 608.3 GB/s.

Il produttore asiatico ha previsto per questa sua nuova soluzione grafica una circuiteria di alimentazione del tutto robusta e di qualità. Nello specifico notiamo un design da 9+2 fasi di alimentazione complessive, le prime dedicate al prestante processore grafico, mentre le restanti al comparto di memoria.

Questo garantirà una maggiore efficienza e stabilità in considerazione della richiesta energetica necessaria alla corretta alimentazione del complesso processore grafico GA104. La qualità delle componenti discrete è più che buona e perfettamente in grado non soltanto di soddisfare le richieste energetiche previste ai valori di targa, ma anche di garantire un buon margine in overclock.

Ogni singola fase, infatti, prevede induttori ben dimensionati, precisamente sono stati scelti degli R22 da 220mH sia per il circuito dedicato al processore grafico e sia per il comparto di memoria. A questi sono affiancati ottimi moduli AOZ5332QI, in grado di supportare sino a 50A, prodotti da Alpha & Omega Semiconductor e provvisti di MOSFET Low-Side & High-Side e driver IC integrati in un singolo package e capaci di assicurare un più elevato livello affidabilità, precisione ed efficienza rispetto alle precedenti implementazioni Dr.MOS. Per il comparto di memoria, invece, sono stati scelti degli altrettanto validi QM3816N prodotti da UBIQ Semiconductor.

La gestione del circuito GPU è affidata ad un rodato controller prodotto dalla uPI Semiconductor, capace di offrire supporto alla regolazione della tensione tramite software. Nello specifico è stato scelto il modello configurabile ad 8 canali di ultima generazione uP9512R, specificatamente progettato per fornire una tensione in uscita ad alta precisione ed in grado di supportare la tecnologia Open Voltage Regulator Type 4i+ PWMVID di NVIDIA.

Per quanto riguarda la gestione del circuito dedicato al comparto di memoria GDDR6X è previsto il modello uP1666Q, collocato nel lato posteriore del PCB, in posizione pressappoco corrispondente alle fasi a lui affidate. A questo punto è giunto il momento di testare le potenzialità offerte dalla nuova INNO3D GeForce RTX 3070 Ti X3 OC.
[nextpage title=”Sistema di Prova e Metodologia di Test”]
Per il sistema di prova ci siamo avvalsi di una scheda madre dotata di PCH Intel Z390 Express, prodotta da ASRock. In particolare è stato scelto il modello Z390 Taichi Ultimate, opportunamente aggiornato con l’ultimo BIOS ufficiale rilasciato (4.20).
Come processore è stato scelto un modello Intel appartenente alla famiglia Coffee-Lake Refresh, precisamente il Core i9 9900K 8C/16T. La frequenza di funzionamento è stata fissata a 5.000MHz, semplicemente impostando il moltiplicatore a 50x senza mettere mano alla frequenza del BCLK (100MHz).
Per il comparto memorie la scelta è ricaduta su un kit DDR4 prodotto da G.Skill da 16GB di capacità assoluta e pieno supporto Dual-Channel, nello specifico il modello Trident-Z F4-3200C15D-16GTZSW. Sia la frequenza e sia le latenze sono state manualmente ottimizzate in modo da raggiungere valori sensibilmente superiori e più efficienti rispetto a quelli di targa, vale a dire 3.600MHz 14-14-14-34-1T.
Nella tabella che segue vi mostriamo il sistema di prova utilizzato per i test di questa nuova unità disco esterna:

Il sistema operativo, Microsoft Windows 10 Pro May 2021 Update X64, è da intendersi privo di qualsiasi ottimizzazione particolare, ma comprensivo di tutti gli aggiornamenti rilasciati fino al giorno della stesura di questo articolo (Versione 21H1 – build 19043.1151).
Le nostre prove sono state condotte con l’intento di verificare il livello prestazionale della INNO3D GeForce RTX 3070 Ti X3 OC, ponendola non soltanto a diretto confronto con diverse soluzioni grafiche precedentemente testate in condizioni operative similari.
Per meglio osservare le potenzialità offerte dalla nuova scheda grafica di INNO3D abbiamo condotto le nostre prove basandoci su due differenti livelli d’impostazione, preventivamente testati al fine di non incorrere in problemi causati dall’instabilità:
- Default: INNO3D GeForce RTX 3070 Ti X3 OC / Frequenze GPU/Boost/Memorie pari a 1.575MHz/1.785MHz/1.188MHz (19Gbps effettivi) / Power Limit 100% (290W) / Gestione Ventole Automatica;
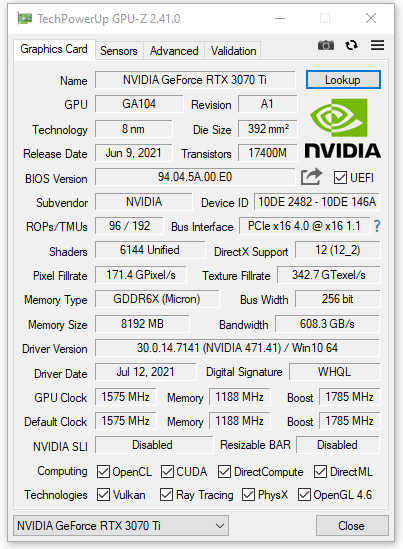
- OC-Daily: INNO3D GeForce RTX 3070 Ti X3 OC / Frequenze GPU/Boost/Memorie pari a 1.675MHz/1.885MHz/1.313MHz (21Gbps effettivi) / Power Limit 100% (290W) / Gestione Ventole Automatica;
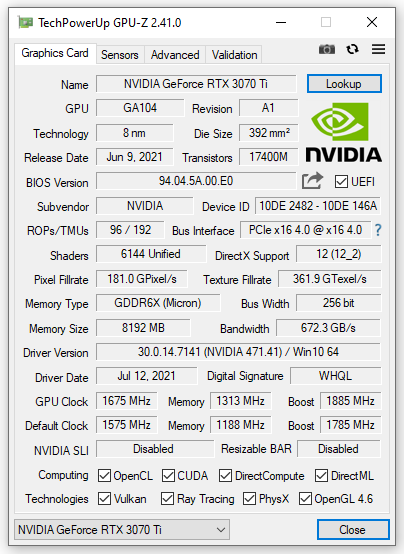
Tutti i settaggi sono stati effettuati con l’ultima versione disponibile del software proprietario TuneIT di INNO3D. I driver utilizzati, come possiamo osservare dagli screen sopra riportati, sono gli ultimi NVIDIA Game Ready 471.41, provvisti di certificazione WHQL. Queste le applicazioni interessate, suddivise in due tipologie differenti:
Benchmark Sintetici
- DX11: 3DMark 11 Advanced Edition v1.0.179;
- DX11-DX12-DXR: 3DMark Advanced Edition v2.19.7225;
- DX11: Unigine Heaven Benchmark v4.0;
- DX11: Unigine2 Superposition Benchmark v1.1;
- VR: VRMark Advanced Edition v1.3.2020;
- GPGPU: V-Ray Benchmark 1.0.8 64bit;
- GPGPU: V-Ray Benchmark 5.0.20 64bit;
- GPGPU: Indigo Benchmark 4.0.64 64bit.
Giochi
- DX12: Assassin’s Creed Valhalla;
- DX12: Battlefield V;
- DX12: Metro Exodus;
- DX12: Shadow of the Tomb Raider;
- DX12: Deus Ex Mankind Divided;
- DX12: Forza Horizon 4;
- DX12: Hitman 3;
- DX12: Horizon Zero Dawn;
- DX12: Gears 5;
- Vulkan: Red Dead Redemption 2;
- Vulkan: Strange Brigade;
- Vulkan: Wolfenstein Youngblood;
- DX11: FarCry New Dawn;
- DX11: Immortals Fenyx Rising;
- DX11: Middle-Earth Shadow of War;
- DX11: The Witcher 3 Wild Hunt.
Andiamo ad osservare i risultati ottenuti.
[nextpage title=”DX11: 3DMark 11 Advanced Edition”]
La penultima versione del famoso software richiederà obbligatoriamente la presenza nel sistema sia di una scheda video con supporto alle API DirectX 11.
Secondo Futuremark, i test sulla tessellation, l’illuminazione volumetrica e altri effetti usati nei giochi moderni rendono il benchmark moderno e indicativo sulle prestazioni “reali” delle schede video.

La versione Basic Edition (gratuita) permette di fare tutti i test con l’impostazione “Performance Preset”. La versione Basic consente di pubblicare online un solo risultato. Non è possibile modificare la risoluzione e altri parametri del benchmark. 3DMark 11 Advanced Edition non ha invece alcun tipo di limitazione.
Il benchmark si compone di sei test, i primi quattro con il compito di analizzare le performance del comparto grafico, con vari livelli di tessellazione e illuminazione. Il quinto test non sfrutta la tecnologia NVIDIA PhysX, bensì la potenza di elaborazione del processore centrale. Il sesto e ultimo test consiste, invece, in una scena precalcolata in cui viene sfruttata sia la CPU, per i calcoli fisici, e sia il processore grafico.
I test sono stati eseguiti in DirectX 11 sfruttando i preset Entry, Performance ed Extreme. Nei grafici il punteggio complessivo ottenuto.
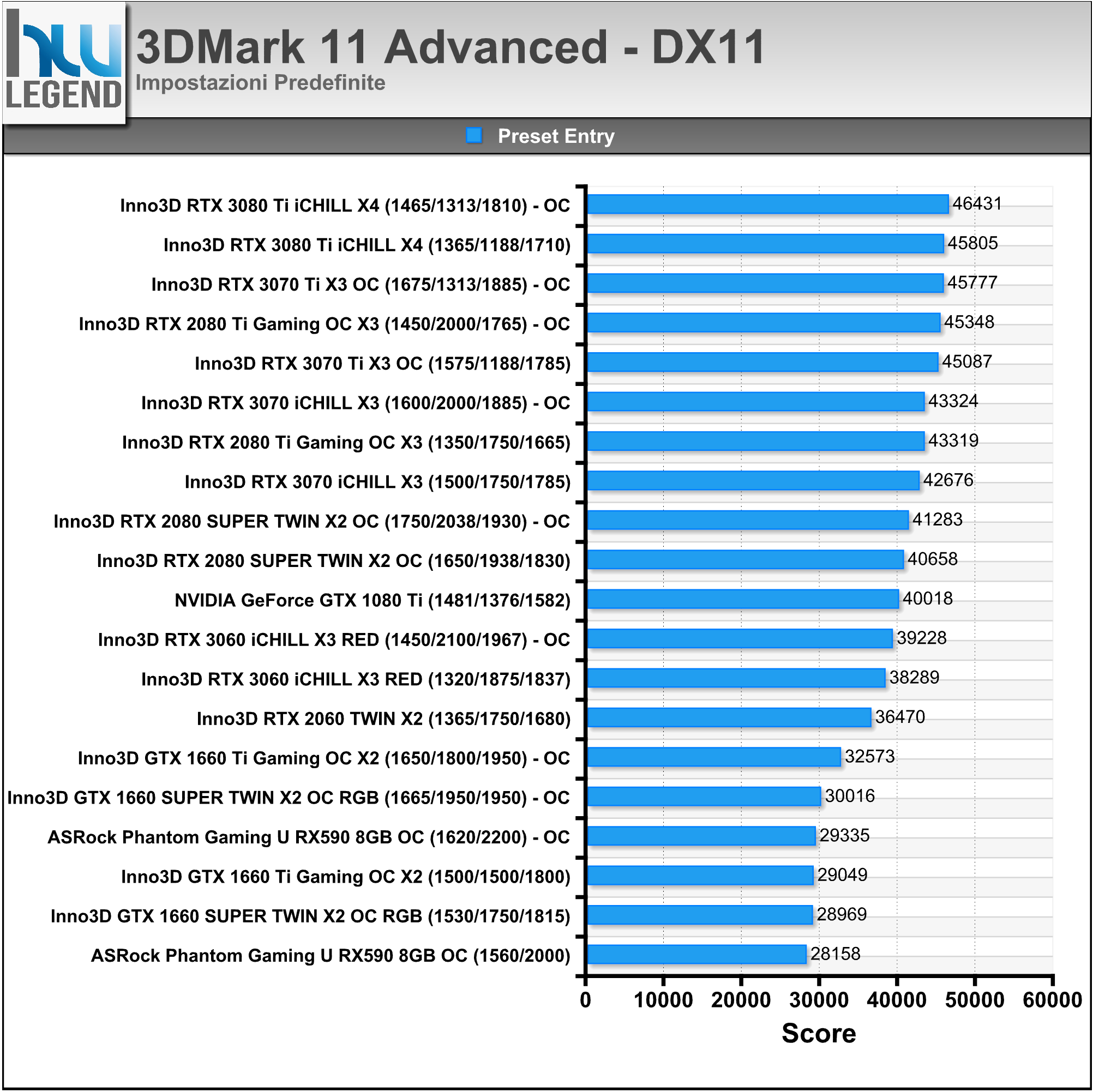
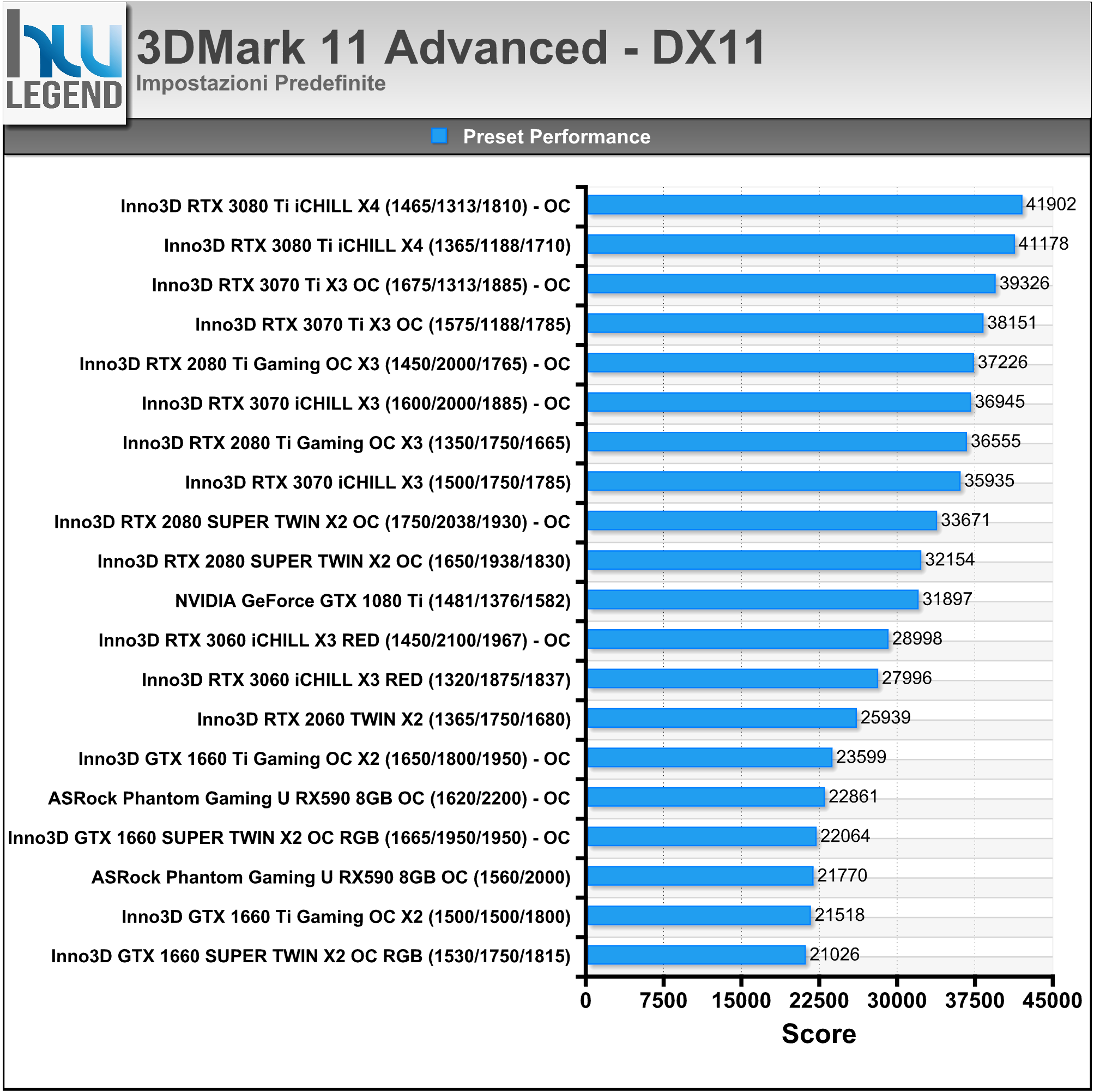
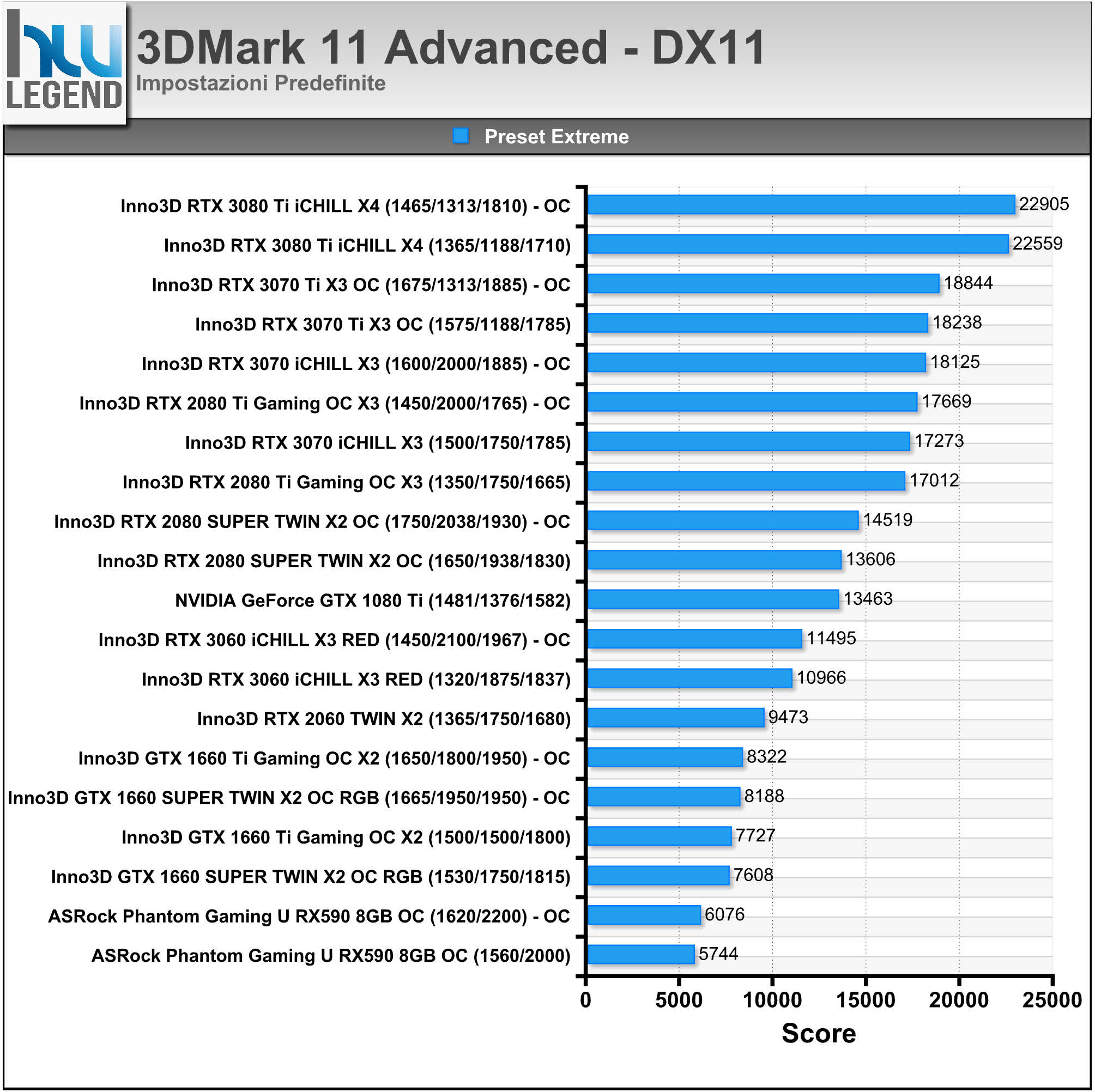
[nextpage title=”DX11-DX12-DXR: 3DMark Advanced Edition”]
La nuova versione del famoso software è senza dubbio la più potente e flessibile mai sviluppata da Futuremark (attualmente UL Benchmarks). Per la prima volta viene proposto un programma multipiattaforma, capace di eseguire analisi comparative su sistemi operativi Windows, Windows RT, Android e iOS.
Le prestazioni velocistiche del proprio sistema possono essere osservate sfruttando nuovi ed inediti Preset, trai cui Ice Storm, Cloud Gate, Sky Diver, Fire Strike, Time Spy ed il nuovissimo Port Royal.

Il primo, Ice Storm, sfrutta le funzionalità delle librerie DirectX 9.0 ed è sviluppato appositamente per dispositivi mobile, quali Tablet e Smartphone senza comunque trascurare i computer di fascia bassa. Il secondo, Cloud Gate è pensato per l’utilizzo con sistemi più prestanti, come ad esempio notebook e computer di fascia media, grazie al supporto DirectX 10. Il terzo, Sky Diver, fa da complemento offrendo un punto di riferimento ideale per laptop da gioco e PC di fascia medio-alta con supporto DirectX 11.
Infine gli ultimi preset, denominati Fire Strike, Time Spy e Port Royal, sono pensati per l’analisi dei moderni sistemi di fascia alta, contraddistinti da processori di ultima generazione e comparti grafici di assoluto livello con pieno supporto DirectX 11 (Fire Strike) e DirectX 12 (Time Spy) e DirectX Raytracing (Port Royal).
I nostri test sono stati eseguiti sfruttando i preset Fire Strike (Normal, Extreme ed Ultra), Time Spy (Normal ed Extreme) ed ovviamente il nuovissimo Port Royal, con pieno supporto DX12 e DXR. Nei grafici il punteggio complessivo ottenuto.
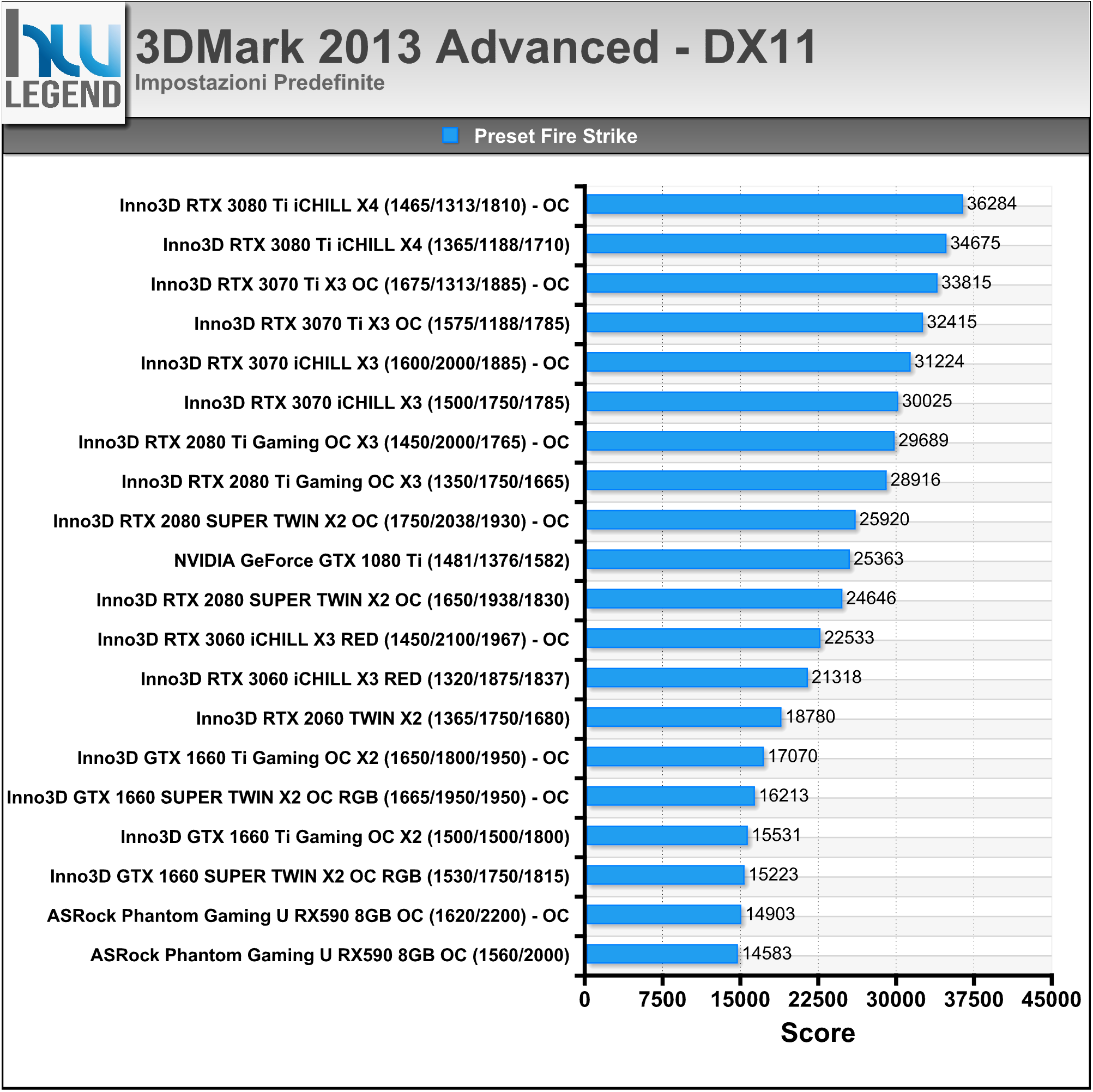
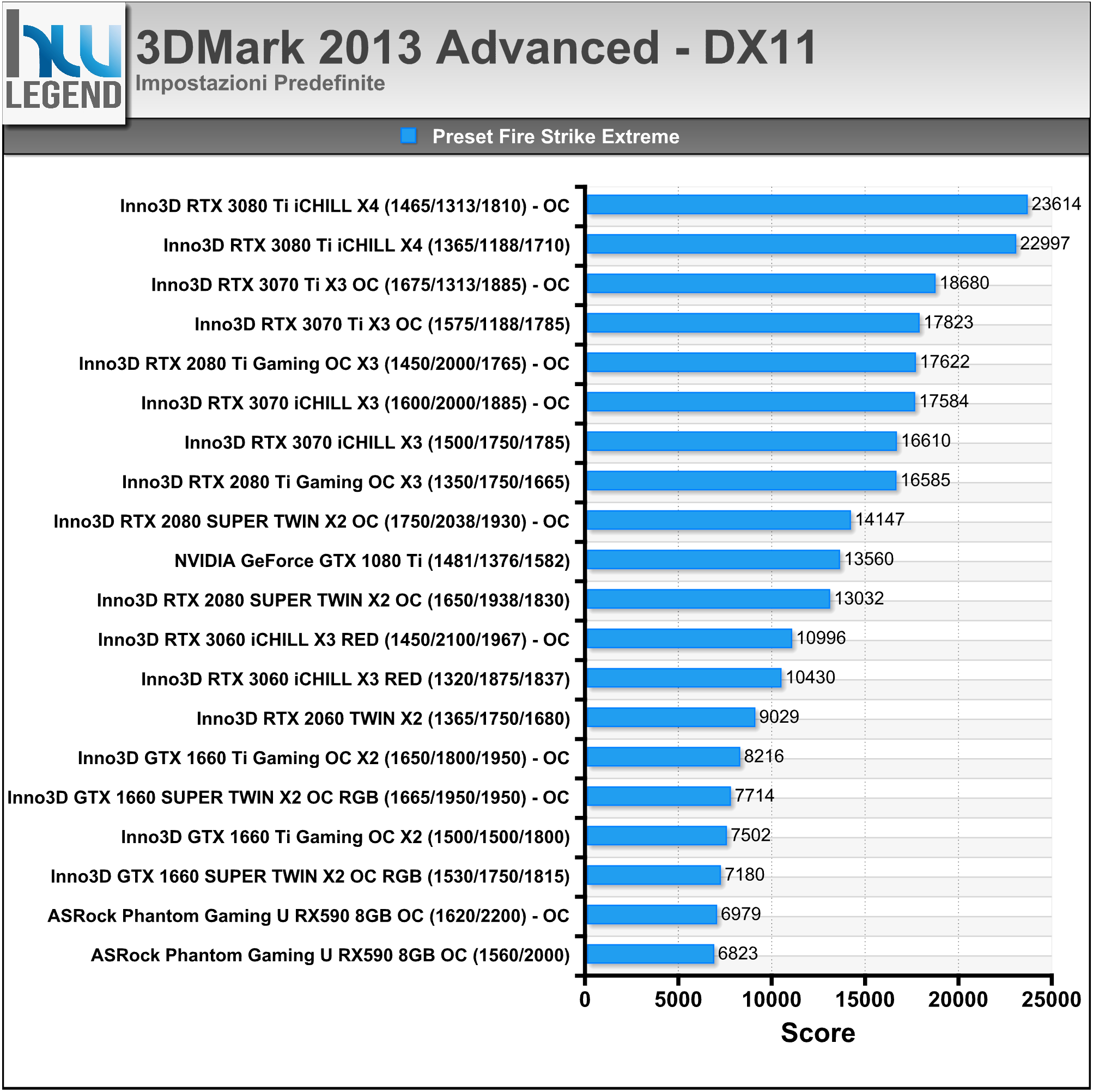
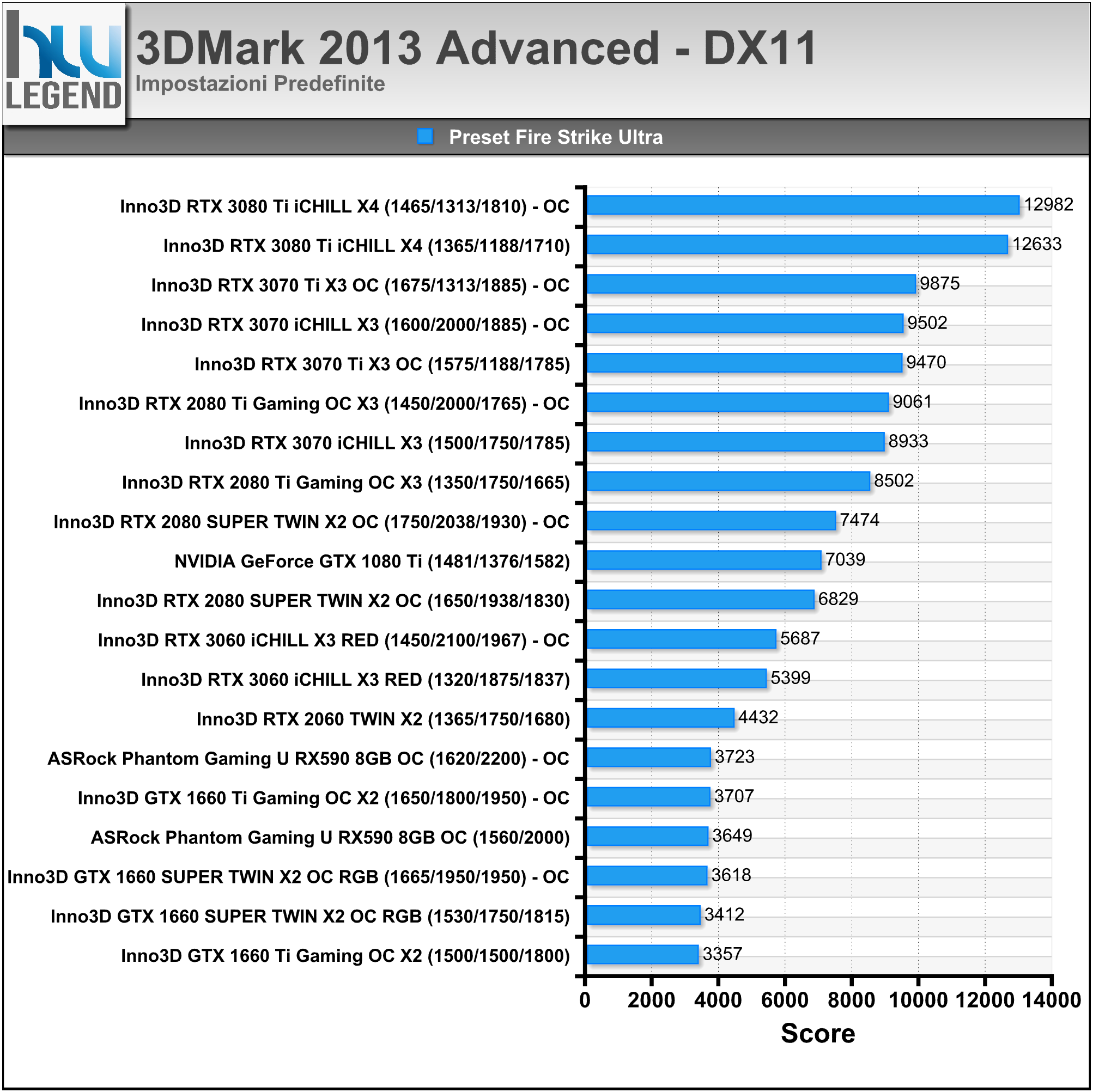
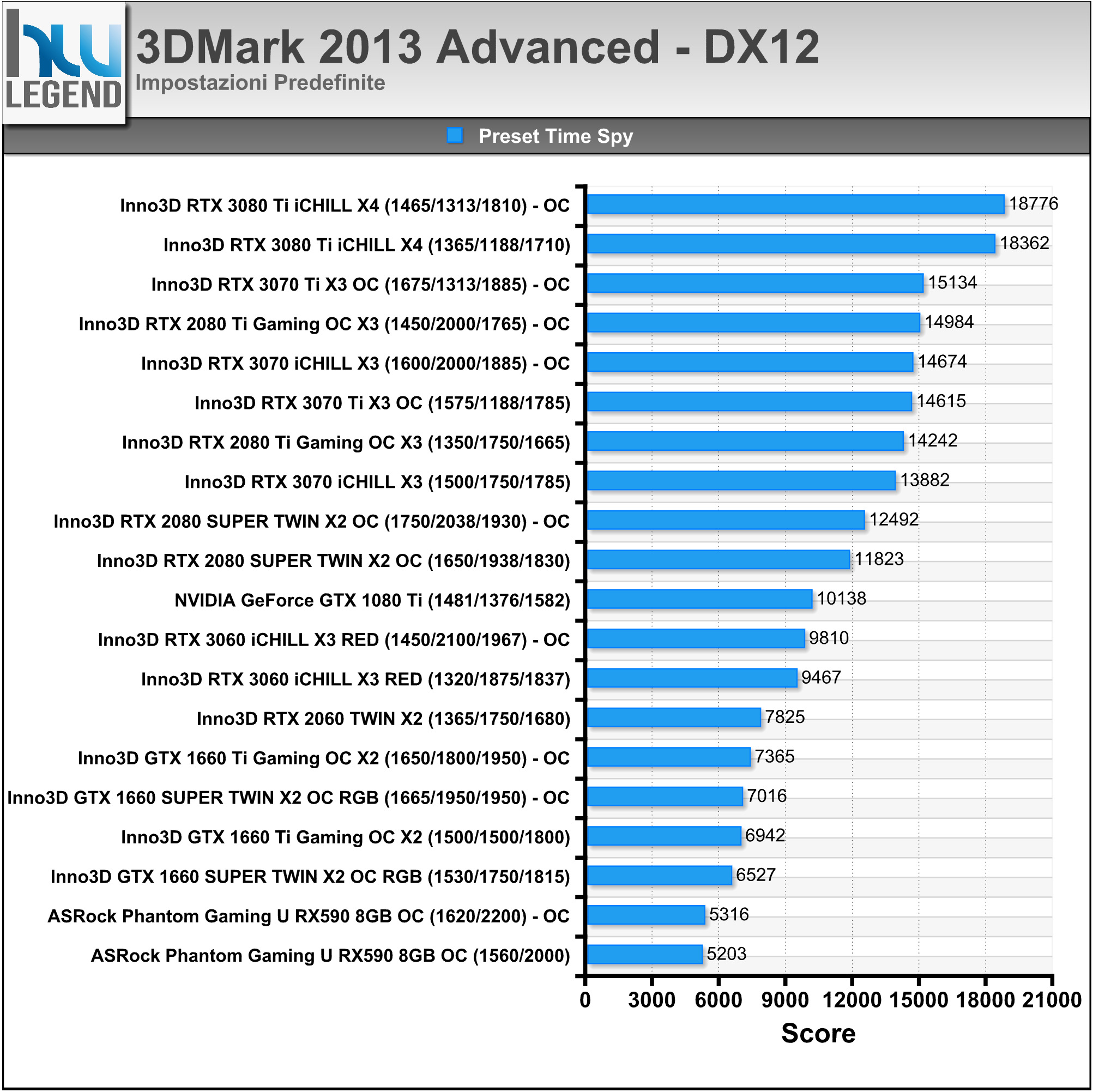
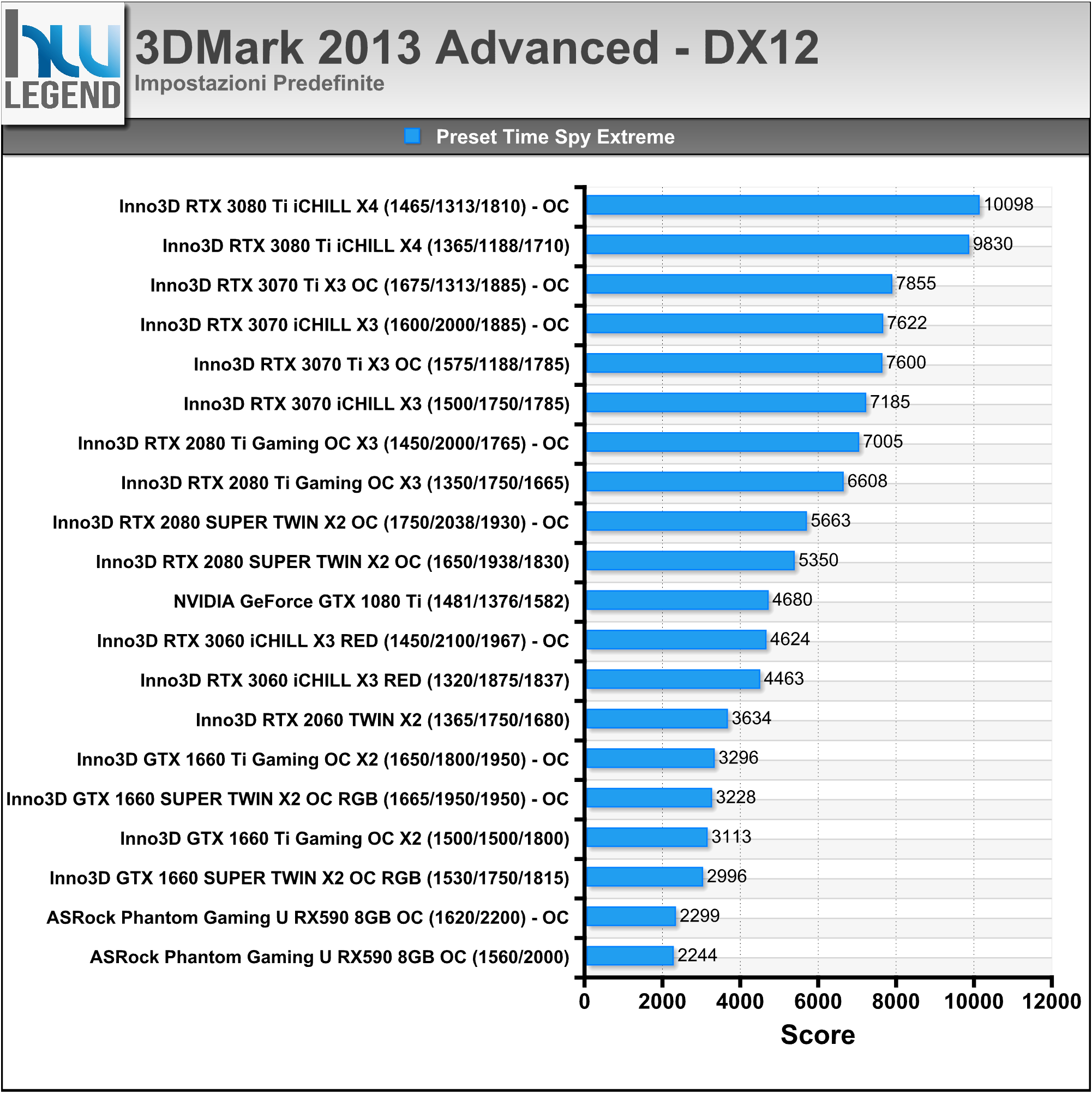
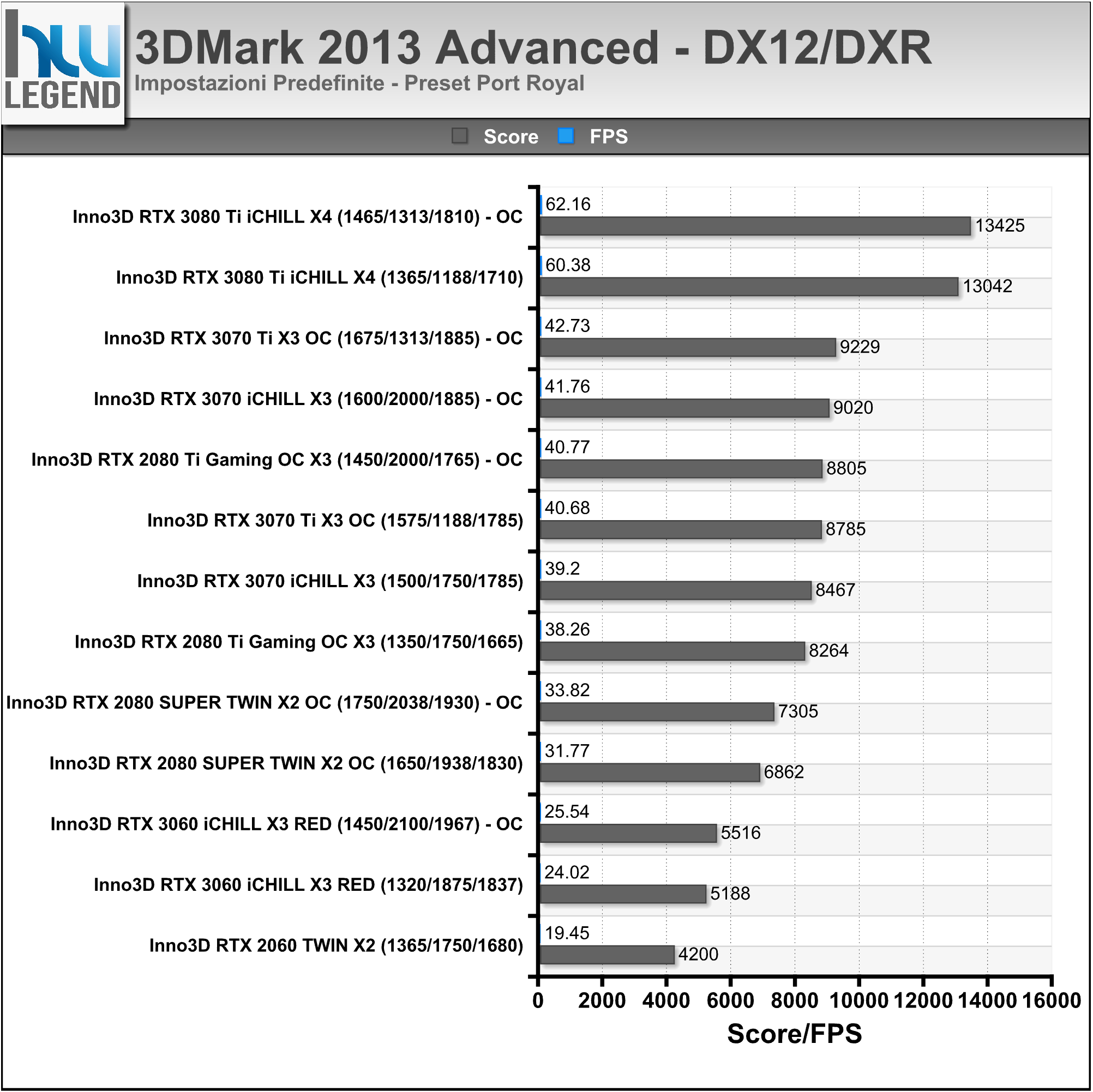
Grazie ai recenti aggiornamenti del programma è stato finalmente reso possibile verificare le potenzialità offerte dalle recenti soluzioni grafiche GeForce RTX di NVIDIA. Il nuovissimo preset Port Royal, infatti, ha portato sui nostri schermi non soltanto il ray-tracing in tempo reale, sfruttando le API DirectX Raytracing (DXR), ma anche l’interessante Deep Learning Super-Sampling (DLSS), una tecnica di miglioramento della qualità dell’immagine basata sull’intelligenza artificiale, capace di sfruttare le nuove unità Tensor Cores al fine di competere a livello qualitativo con tecniche anti-aliasing tradizionali quali il TAA pur senza impattare eccessivamente a livello prestazionale.
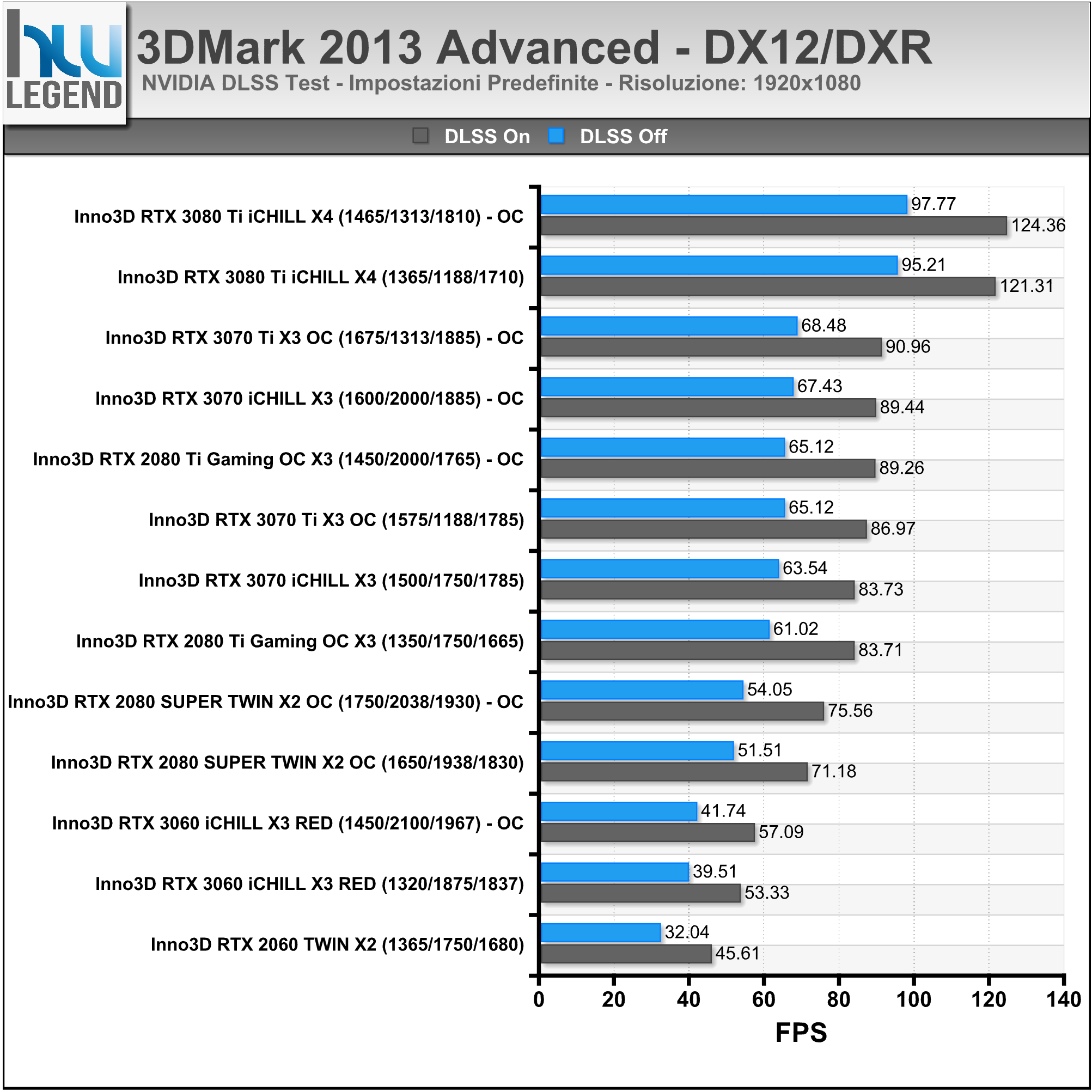
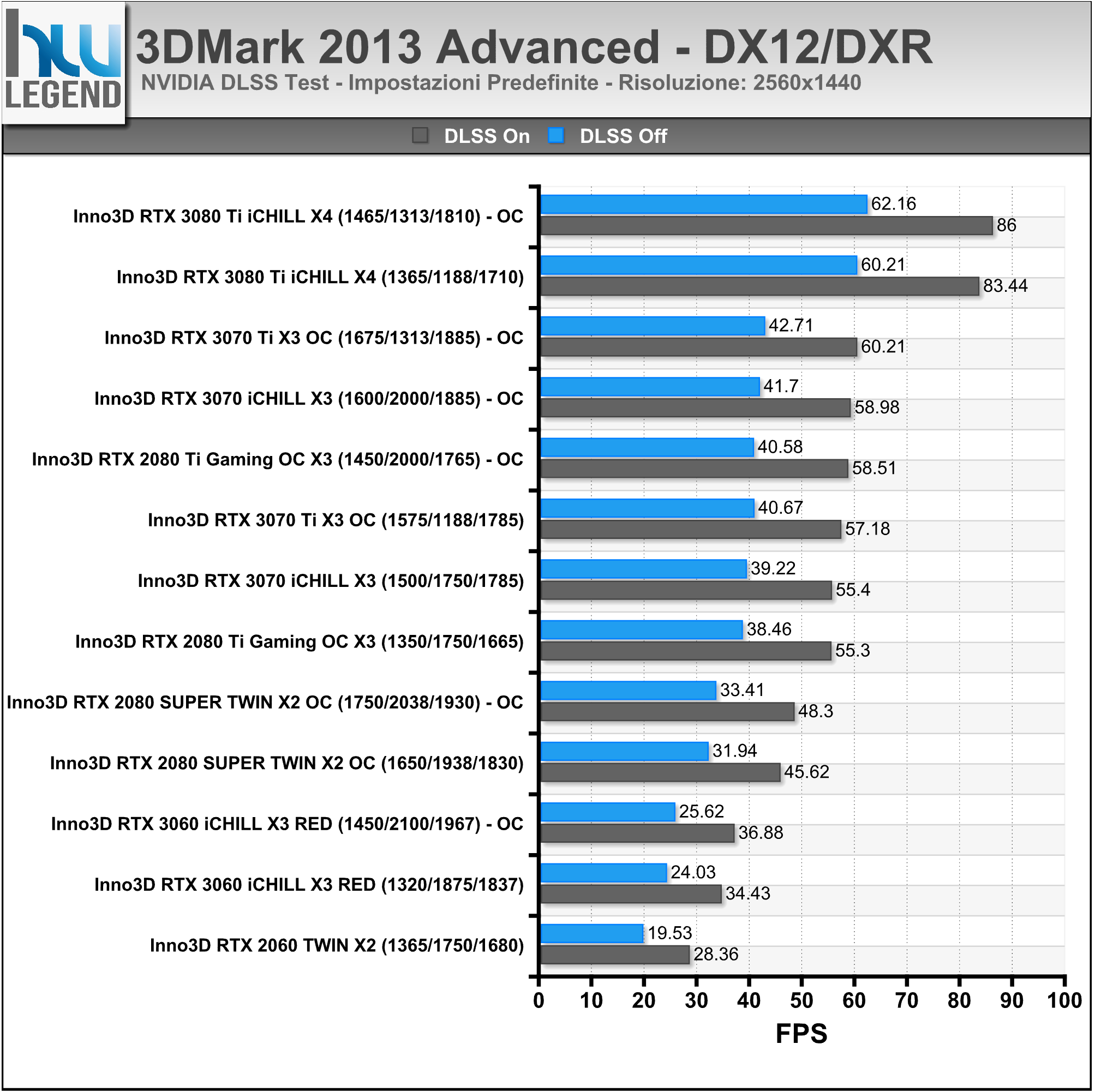
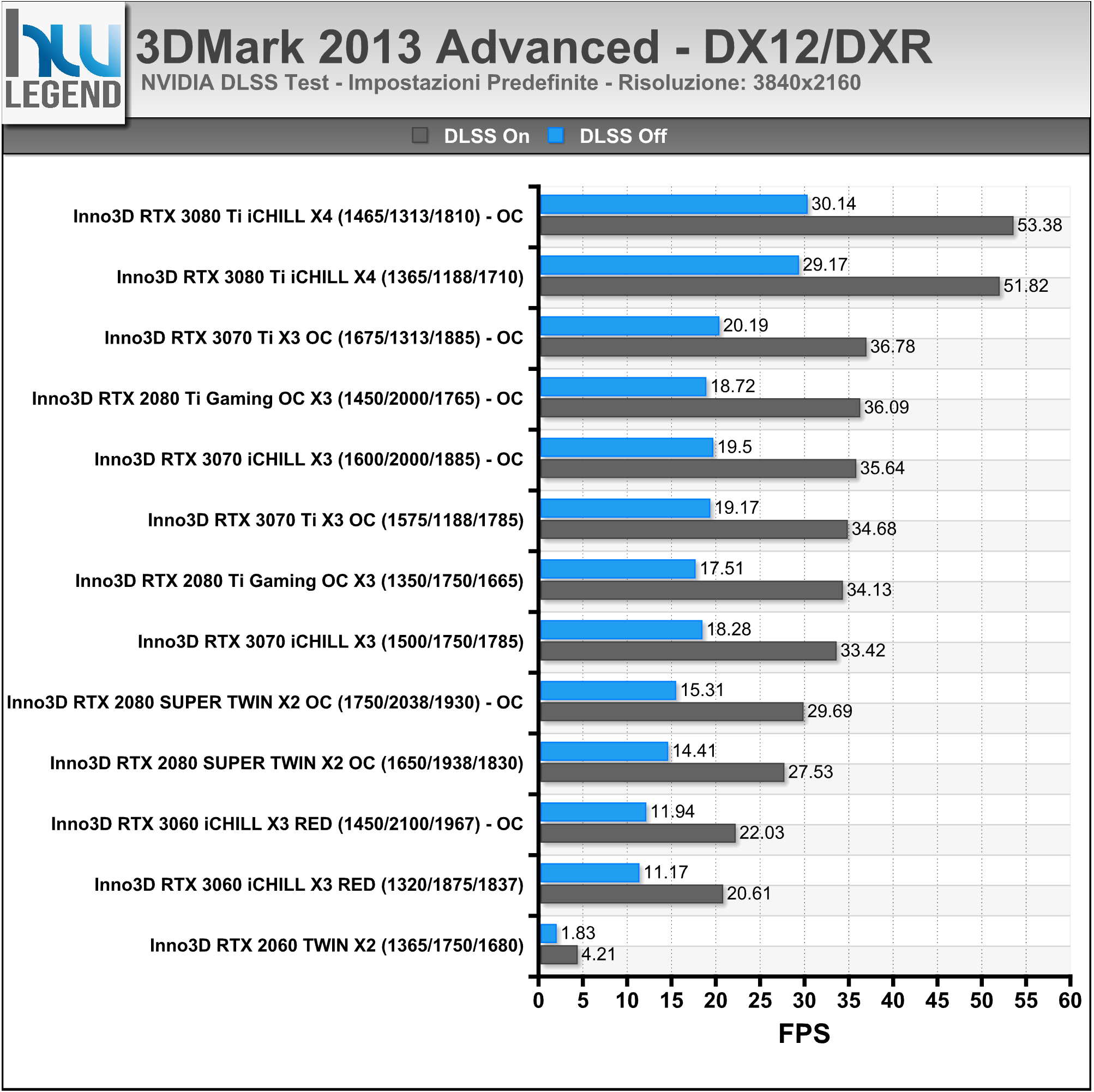
Nell’ultima versione del programma troviamo anche un nuovo ed interessante feature test, capace di mostrare i benefici del Variable-Rate Shading (VRS) integrato nelle librerie DirectX 12.
Questa particolare tecnica è espressamente pensata per incrementare le prestazioni velocistiche andando a ridurre il livello di dettaglio dell’ombreggiatura in modo selettivo o più precisamente in quelle parti della scena che impattano in maniera minima e marginale sulla qualità complessiva dell’immagine.
Il VRS è pienamente supportato dai processori grafici NVIDIA basati sia su architettura Turing che Ampere e per questo motivo ne abbiamo verificato il corretto funzionamento e ne riportiamo i risultati ottenuti:
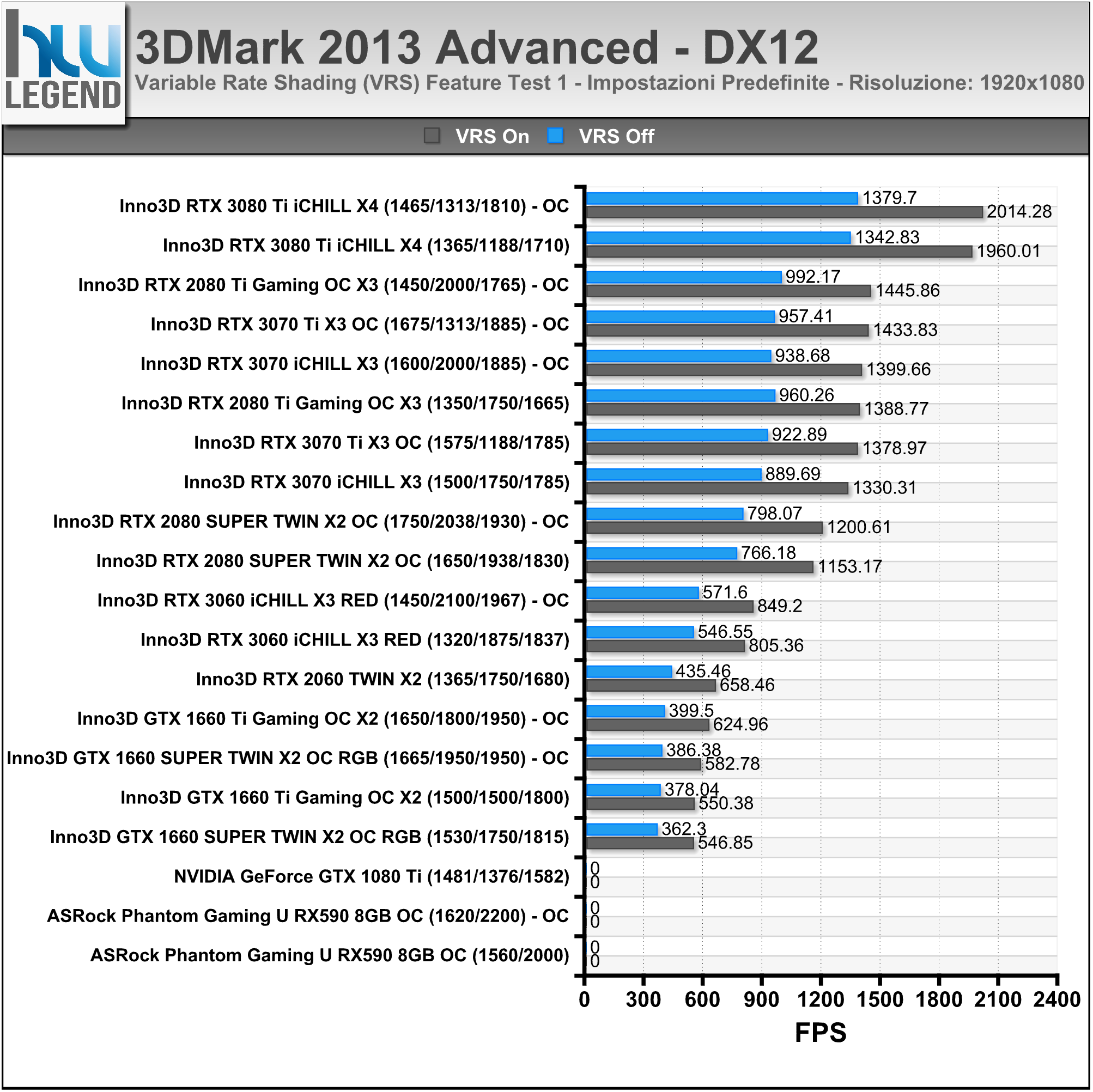
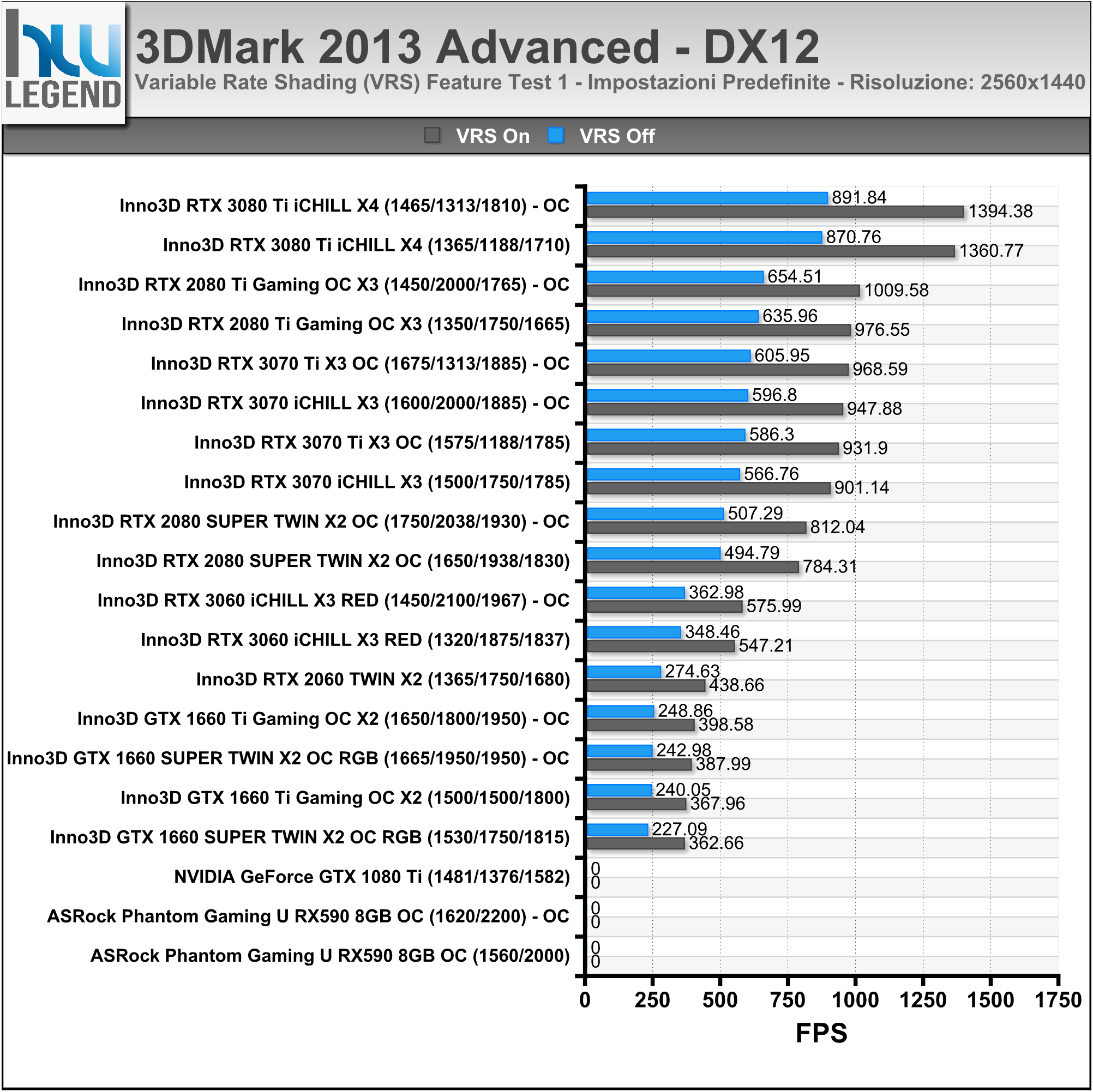
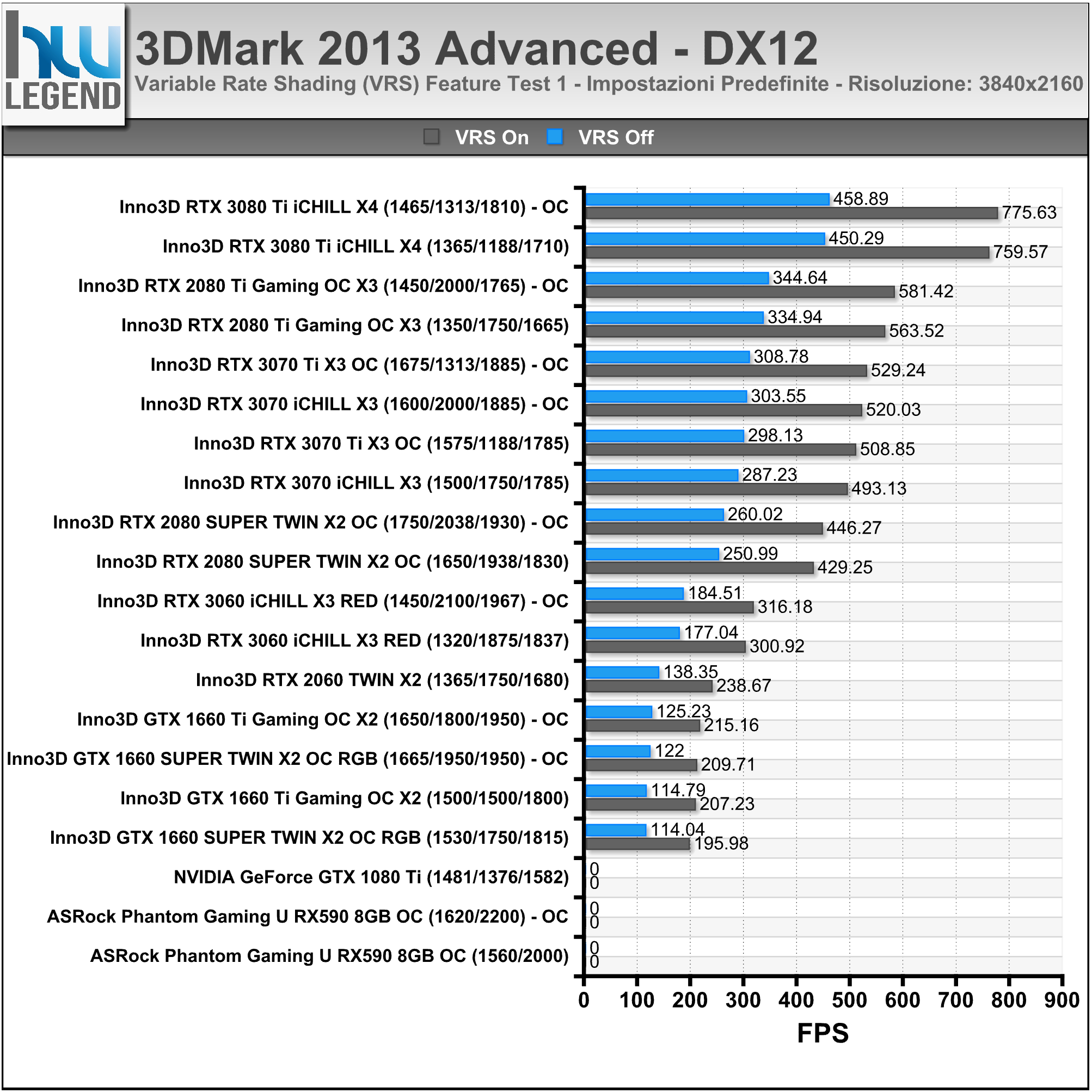
Sempre tra i vari feature test inclusi nel programma troviamo il recente DirectX Raytracing, un preset espressamente progettato per rendere le prestazioni del ray-tracing il fattore limitante. Invece di fare affidamento sul rendering tradizionale, l’intera scena viene renderizzata con ray-tracing e finalizzata in un unico passaggio. Il risultato del test, di conseguenza, consente di misurare e confrontare le prestazioni dell’hardware dedicato al ray-tracing nelle schede grafiche più recenti sul mercato.

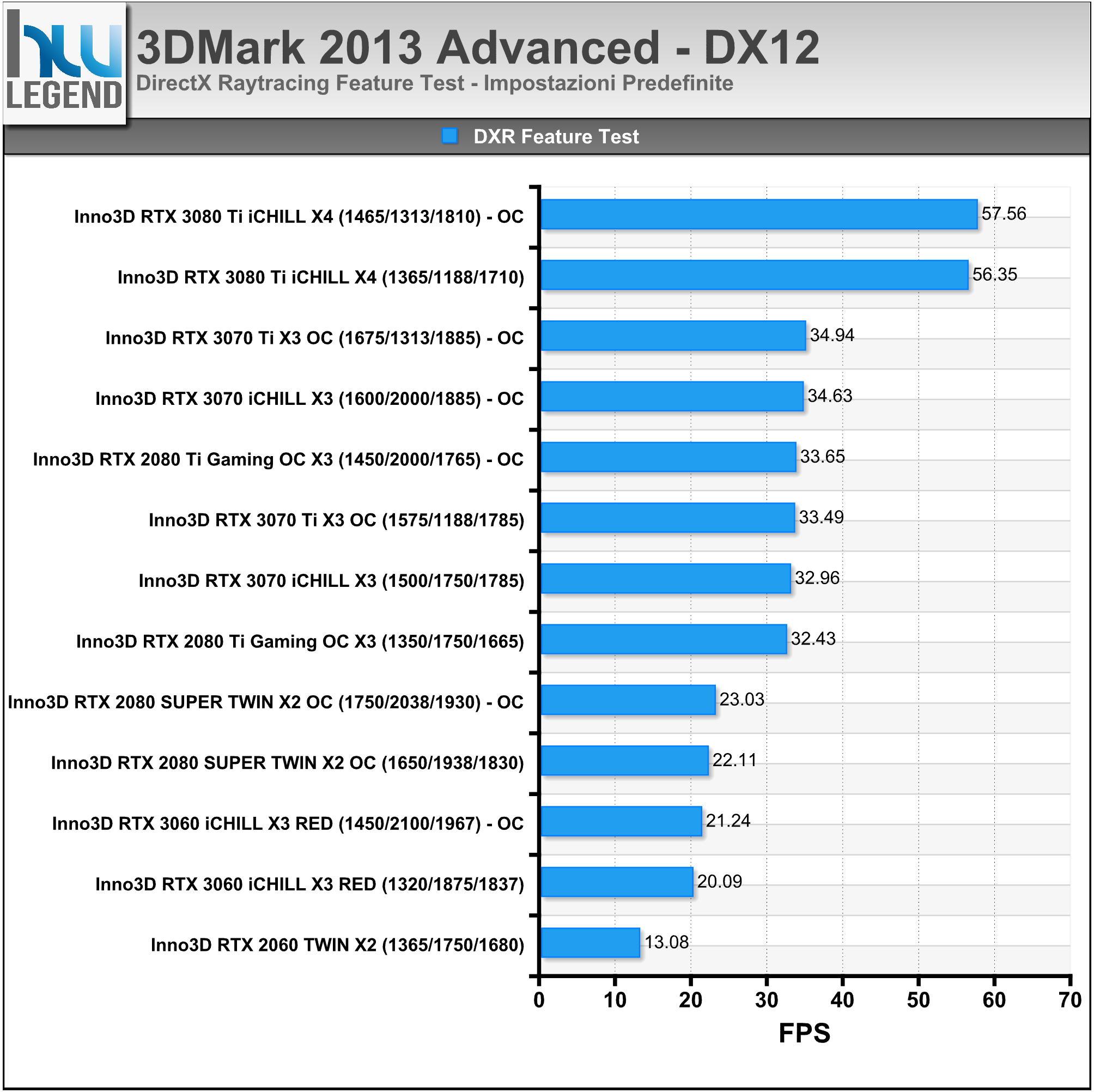
[nextpage title=”DX11: Unigine Heaven Benchmark v4.0″]
Unigine ha aggiornato il suo benchmark DirectX 11, che permette agli utenti di provare la propria scheda video con le nuove librerie grafiche.
Basato su motore Unigine, il benchmark Heaven v4.0 supporta schede video DirectX 11, 10, 9, OpenGL e il 3D Vision Surround di Nvidia. Tra le novità la possibilità di avere a disposizione dei preset per avere delle performance paragonabili immediatamente tra gli utenti.

I test sono stati condotti utilizzando il preset Extreme alle seguenti risoluzioni: 1920×1080, 2560×1440 e 3840×2160. Nel grafico i risultati ottenuti, espressi sotto forma di Score finale e di FPS medi.
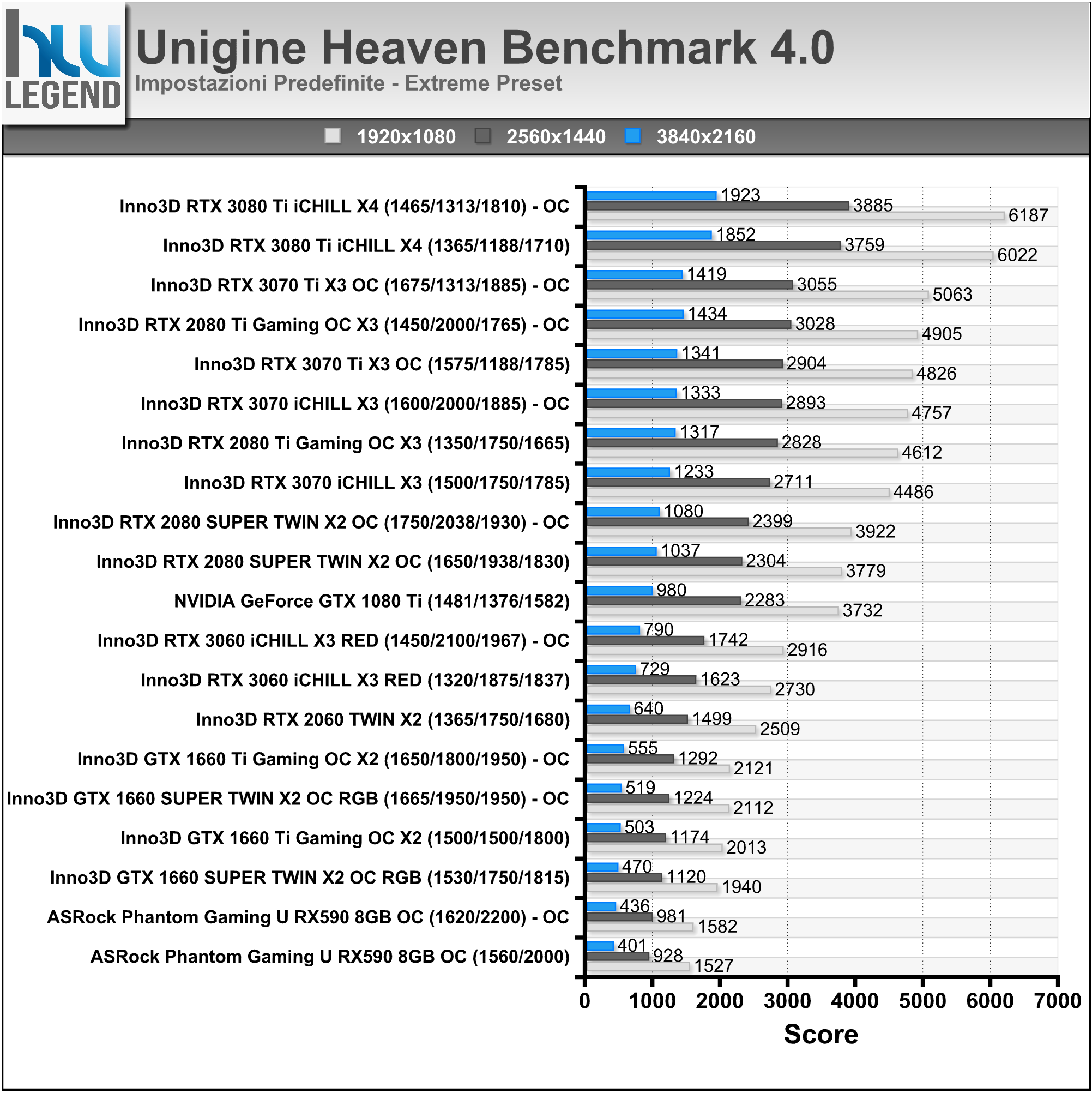
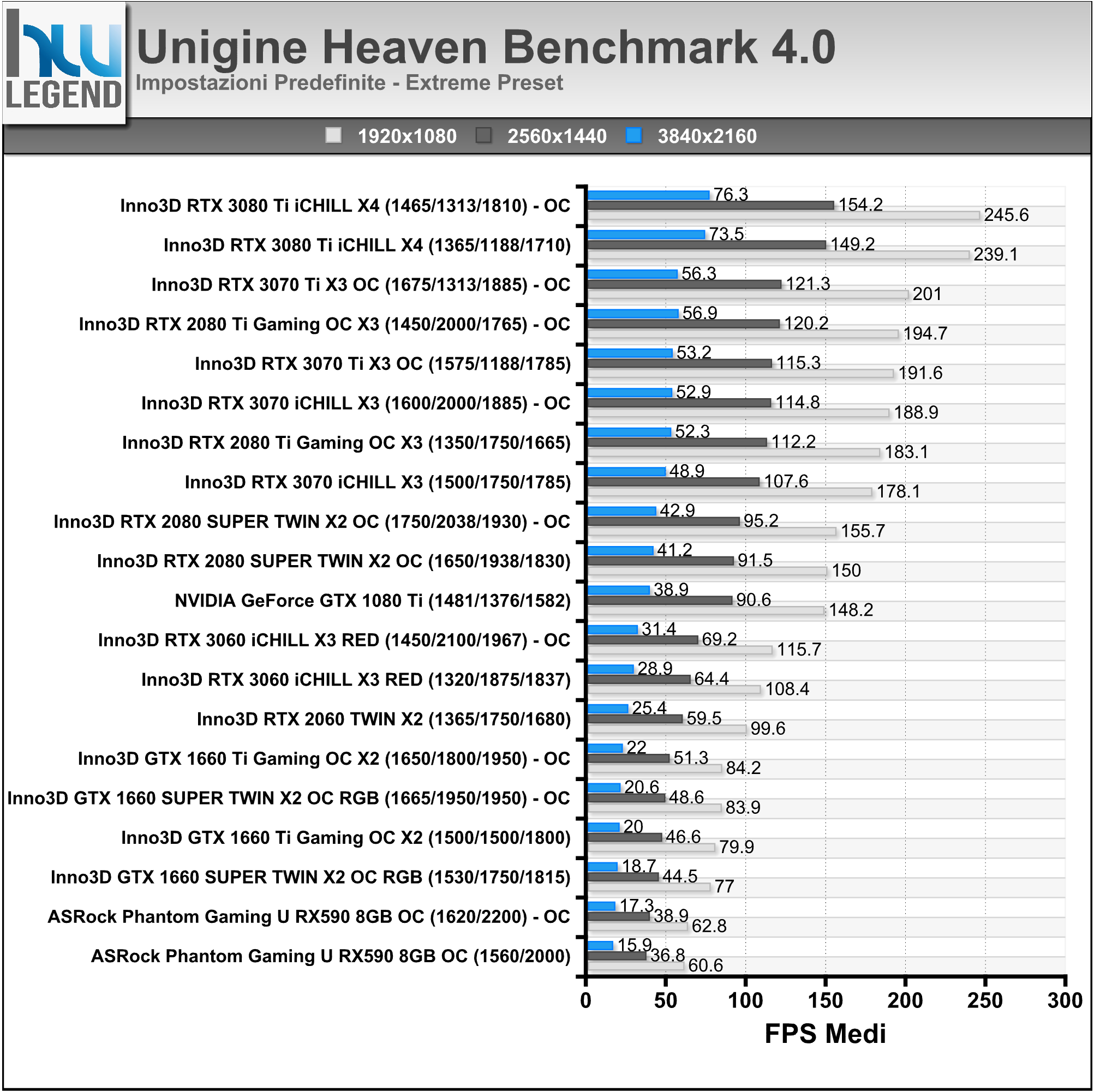
[nextpage title=”DX11: Unigine2 Superposition Benchmark v1.0″]
Direttamente dagli sviluppatori degli apprezzati Heaven e Valley, e seppur con un leggero ritardo sulla tabella di marcia, ecco che finalmente vede la luce il nuovo software di benchmark Superposition, basato sul potente motore grafico di nuova generazione Unigine 2, capace di spremere all’inverosimile anche le più prestanti soluzioni grafiche sul mercato.
Come di consueto sono previsti vari profili predefiniti, che consentiranno di ottenere risultati, in termini prettamente prestazionali, facilmente confrontabili. Rispetto al passato è stato implementato un database online, nel quale verranno raccolti i risultati ottenuti dagli utenti e poter quindi fare confronti su ben più larga scala.

Oltre a questo sono state introdotte nuove modalità, a cominciare da una simulazione interattiva dell’ambiente, denominata “Game”, alla possibilità di sfruttare i più moderni visori per realtà virtuale, come Oculus Rift e HTC Vive. Viene inoltre offerta la possibilità di verificare la piena stabilità del proprio comparto grafico, grazie allo “Stress Test” integrato (esclusiva della versione Advanced del programma).
I test sono stati condotti utilizzando i preset 1080p Extreme, 4K Optimized e 8K Optimized. Nel grafico i risultati ottenuti, espressi sotto forma di Score finale e di FPS medi.



[nextpage title=”VR: VRMark Advanced Edition”]
La suite VRMark, sviluppata da Futuremark (attualmente UL Benchmarks) consente di verificare se il nostro sistema è in grado di garantire una buona esperienza con le applicazioni di alla realtà virtuale, così da valutare eventualmente l’acquisto di uno dei moderni visori dedicati.
Per ovvi motivi, quindi, non sarà necessario disporre di un visore fisicamente collegato al computer per eseguire i vari preset previsti dal programma, ma al contrario ci si potrà semplicemente affidare al proprio monitor.

Nei grafici la sintesi dei risultati ottenuti eseguendo tutti e tre i preset previsti (Orange Room, Cyan Room e Blue Room), espressi sotto forma di Score Finale e di Frames Medi Elaborati.

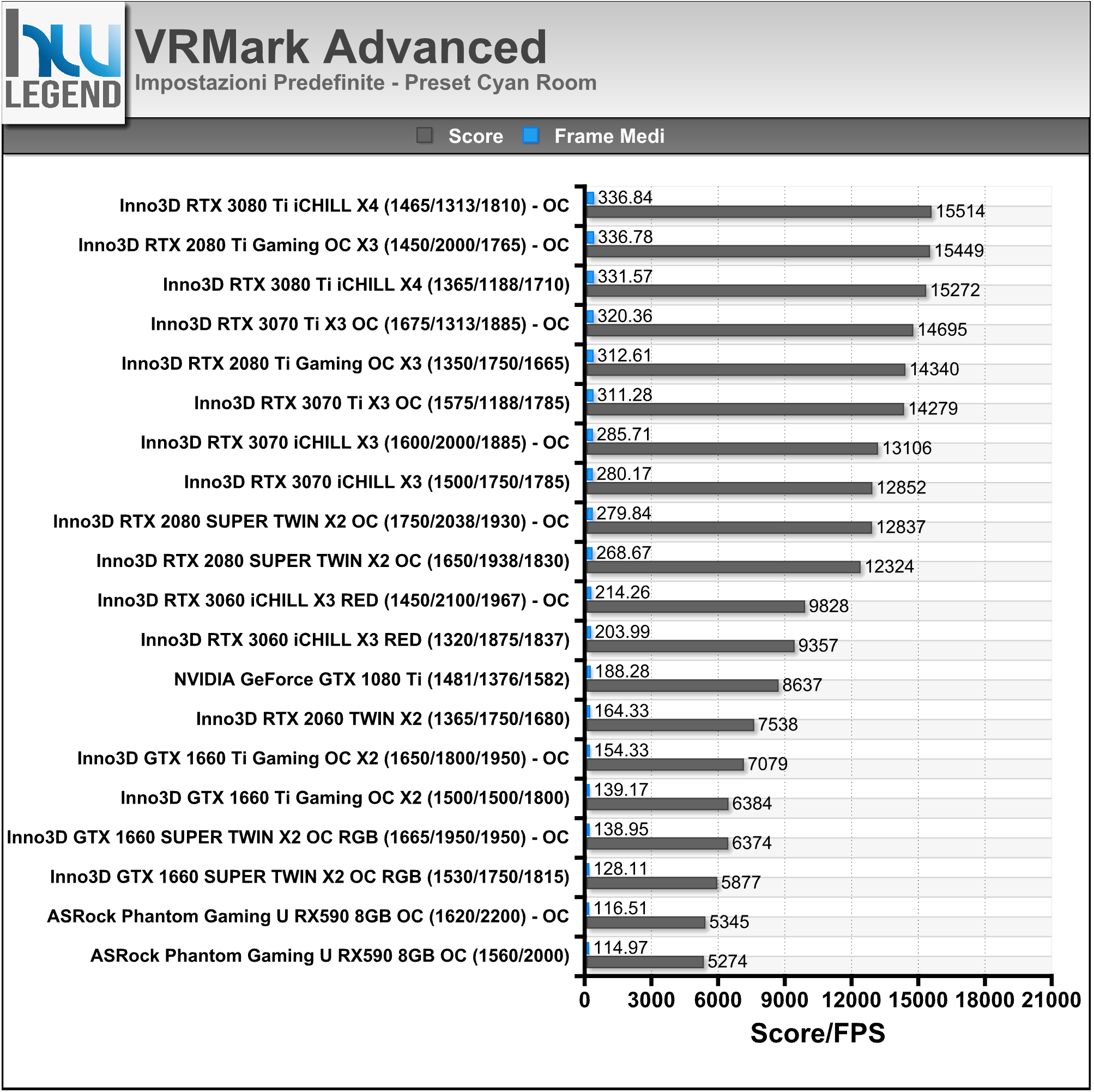
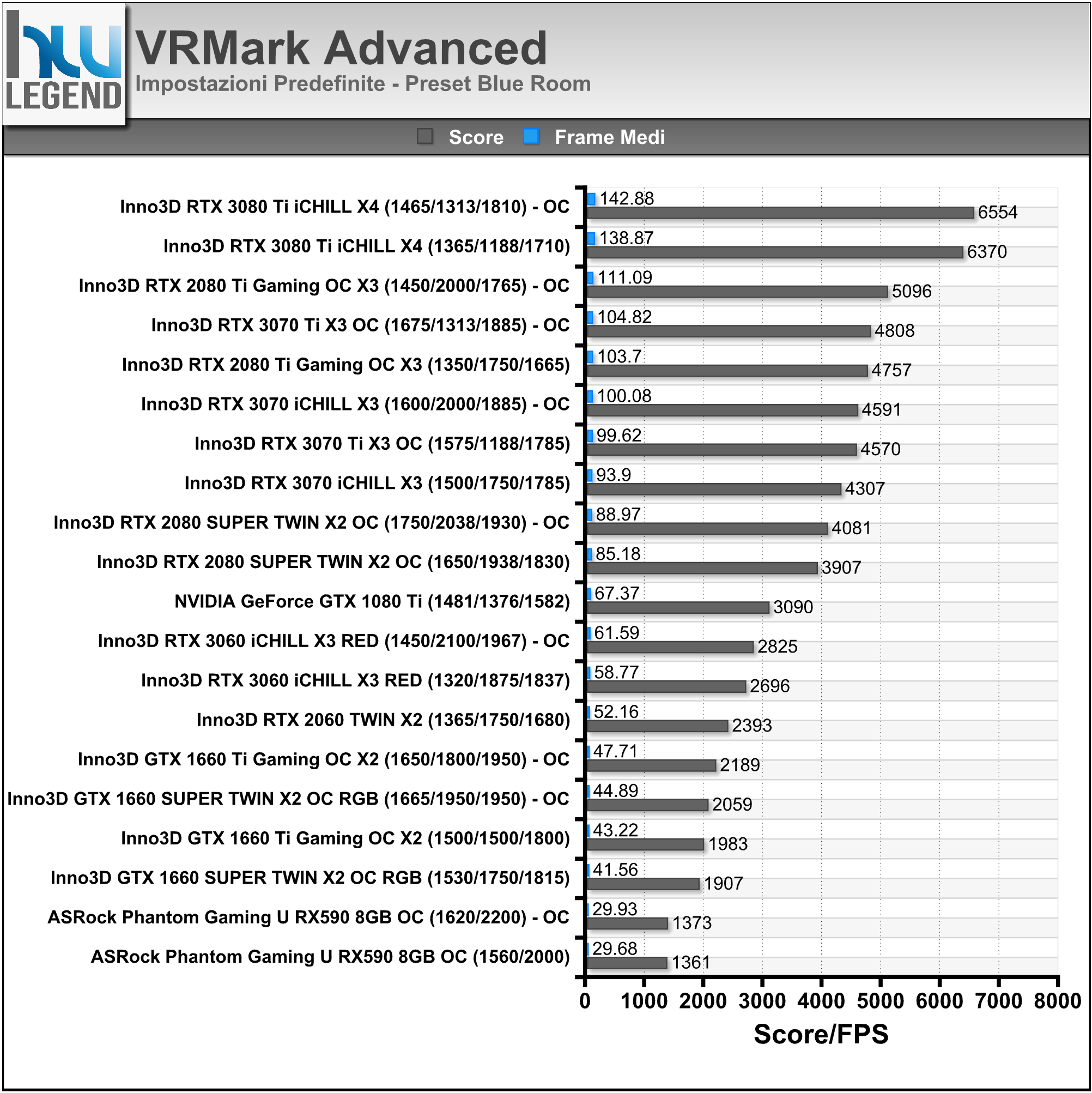
[nextpage title=”GPGPU: V-Ray Benchmark”]
V-Ray Benchmark è un tool completamente gratuito per la misura delle performance velocistiche del proprio hardware nel rendering con V-Ray. È disponibile gratuitamente, previa registrazione su chaosgroup.com e verrà eseguito senza requisiti di licenza come applicazione autonoma.
Il programma prevede la possibilità di eseguire rendering di raytrace sfruttando la CPU oppure la/e schede grafiche presenti. V-Ray è uno dei principali raytracers al mondo e viene utilizzato in molte industrie in fase di architettura e progettazione automobilistica.

È stato utilizzato anche in oltre 150 immagini cinematografiche e numerose serie televisive episodiche. Ha inoltre vinto un premio Oscar per il conseguimento scientifico e tecnico nel 2017.
Nel grafico il tempo (in Secondi) necessario al rendering della scena di riferimento, eseguita con impostazioni predefinite, sfruttando il solo processore grafico.
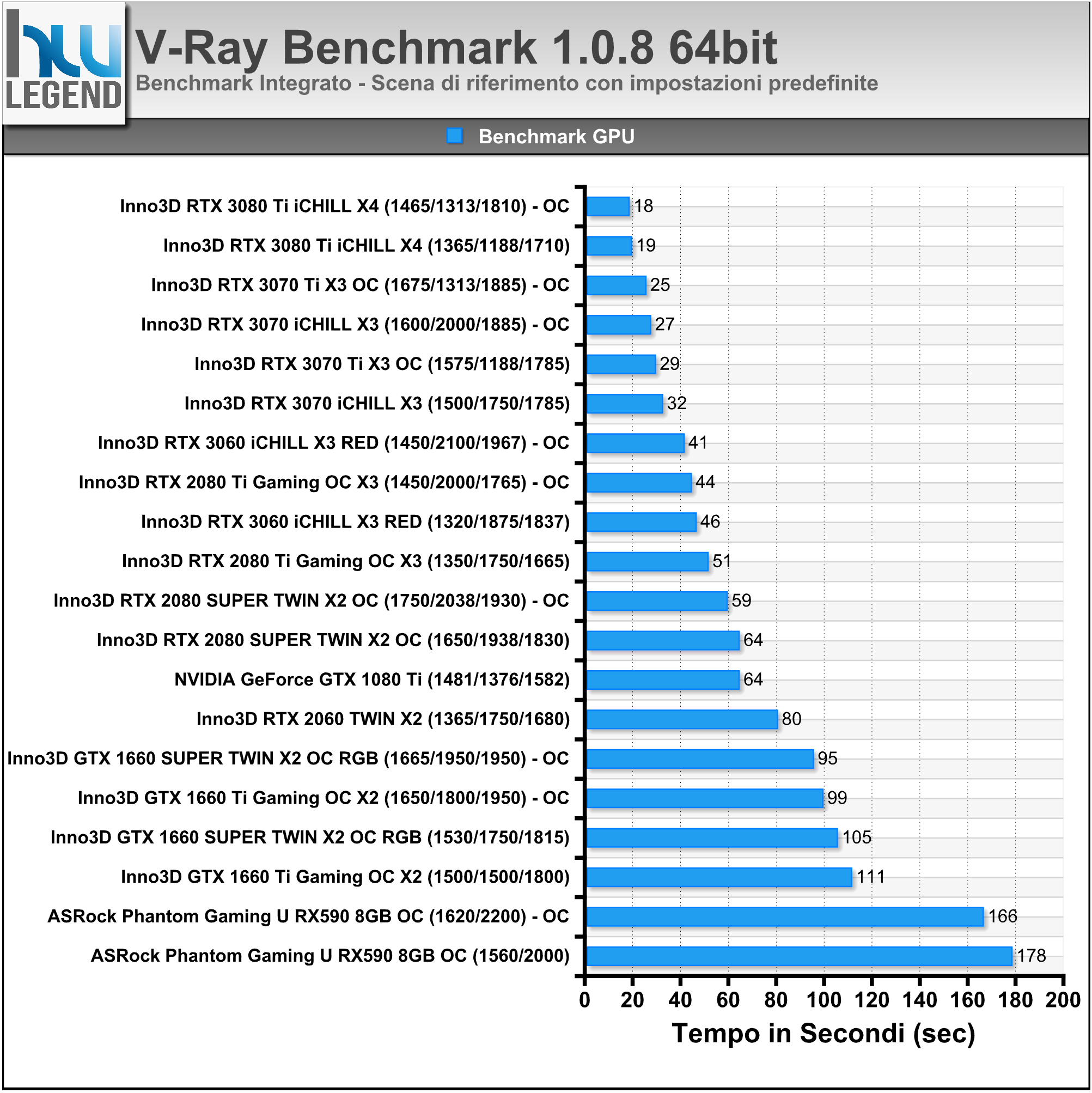
Chaosgroup ha recentemente rilasciato una nuova versione del programma, arricchita con un’inedita modalità di testing espressamente pensata per sfruttare appieno le tecnologie implementate nelle soluzioni grafiche NVIDIA GeForce RTX. Nel grafico che segue riportiamo lo score finale ottenuto (espresso in Vrays) eseguendo il nuovo test con impostazioni predefinite:
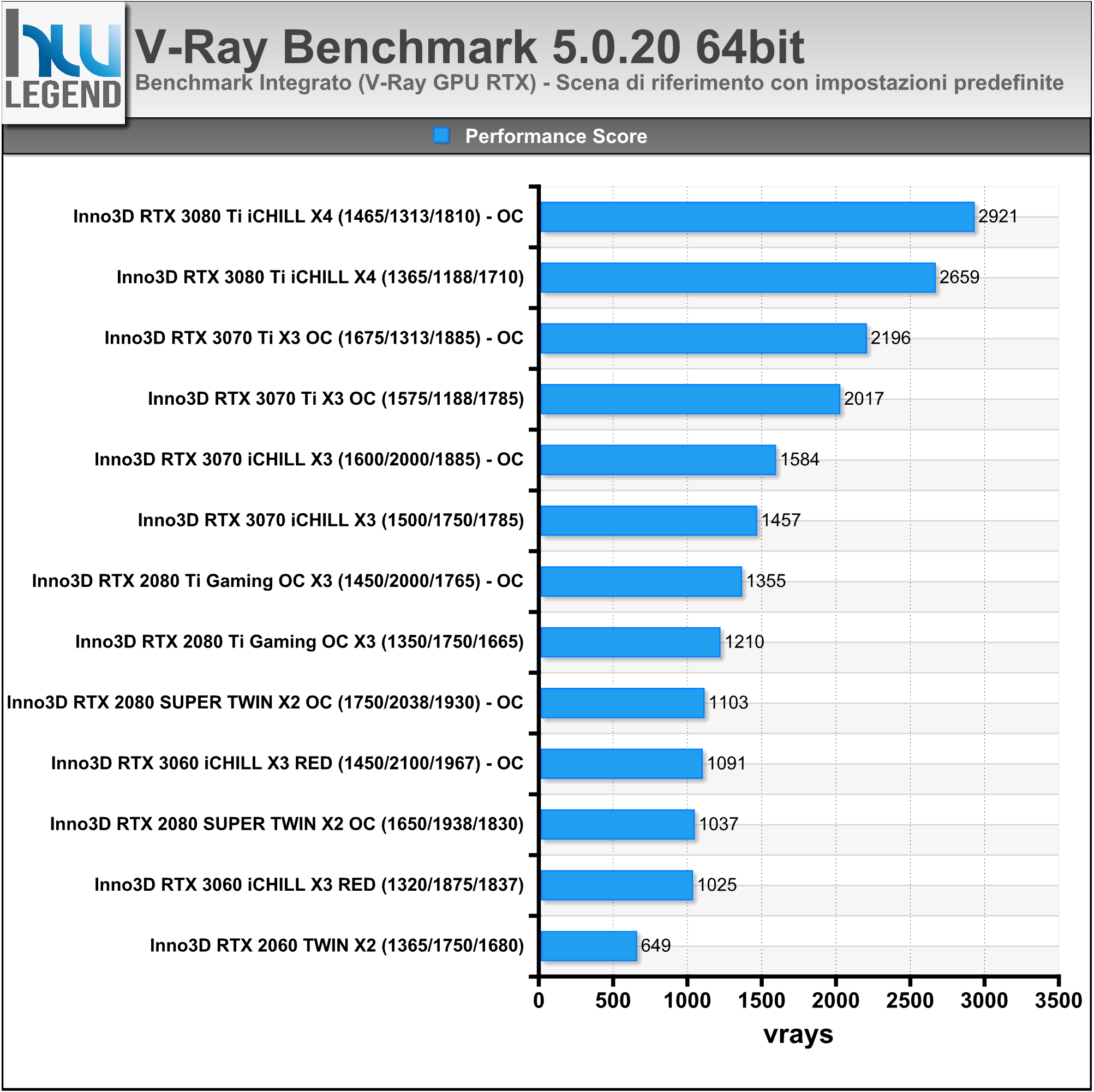
[nextpage title=”GPGPU: Indigo Benchmark”]
Indigo Bench è un’applicazione di benchmark standalone basata sul motore di rendering avanzato di Indigo 4, utile per misurare le prestazioni delle moderne CPU e GPU.
Grazie all’utilizzo di OpenCL standard del settore, è supportata un’ampia varietà di GPU di NVIDIA, AMD e Intel. Il programma è completamente gratuito e può essere utilizzato senza una licenza Indigo su Windows, Mac e Linux.
Nel grafico lo score ottenuto in seguito al completamento del rendering di entrambe le scene di riferimento previste, eseguito con impostazioni predefinite.
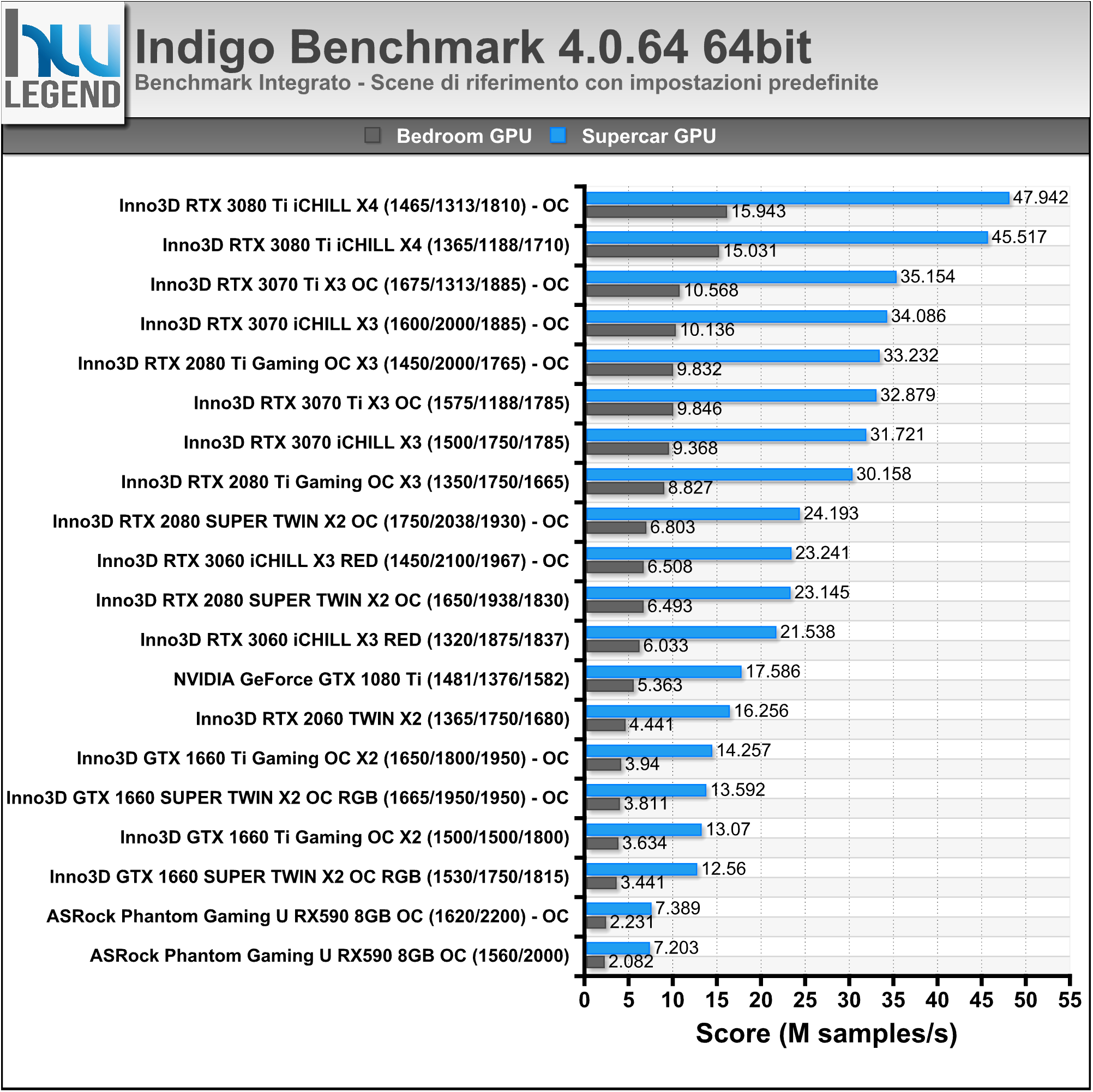
[nextpage title=”DX12: Assassin’s Creed Valhalla “]
Assassin’s Creed: Valhalla è un videogioco sviluppato da Ubisoft Montreal e pubblicato da Ubisoft. È il dodicesimo capitolo della saga principale di Assassin’s Creed, sequel di Assassin’s Creed: Odyssey, pubblicato nel 2018.
Un anno dopo aver rivissuto le memorie della Misthios, Layla Hassan si trova nel New England per indagare su due eventi apparentemente non correlati: il progressivo rinforzo del campo geomagnetico (fenomeno che causa un’eterna aurora boreale) e il ritrovamento del corpo di un guerriero vichingo del IX secolo, risalente a ben due secoli prima della presenza norrena in America.

Nonostante sia ancora turbata dalla morte di Victoria Bibeau, e sebbene senta un forte influsso proveniente dal Bastone di Hermes, Layla decide di rivivere attraverso l’Animus le memorie del guerriero vichingo, coadiuvata dai due Assassini Shaun Hastings e Rebecca Crane….
Il gioco, presentato lo scorso mese di novembre su PC, è in grado di sfruttare le API DirectX 12. I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:
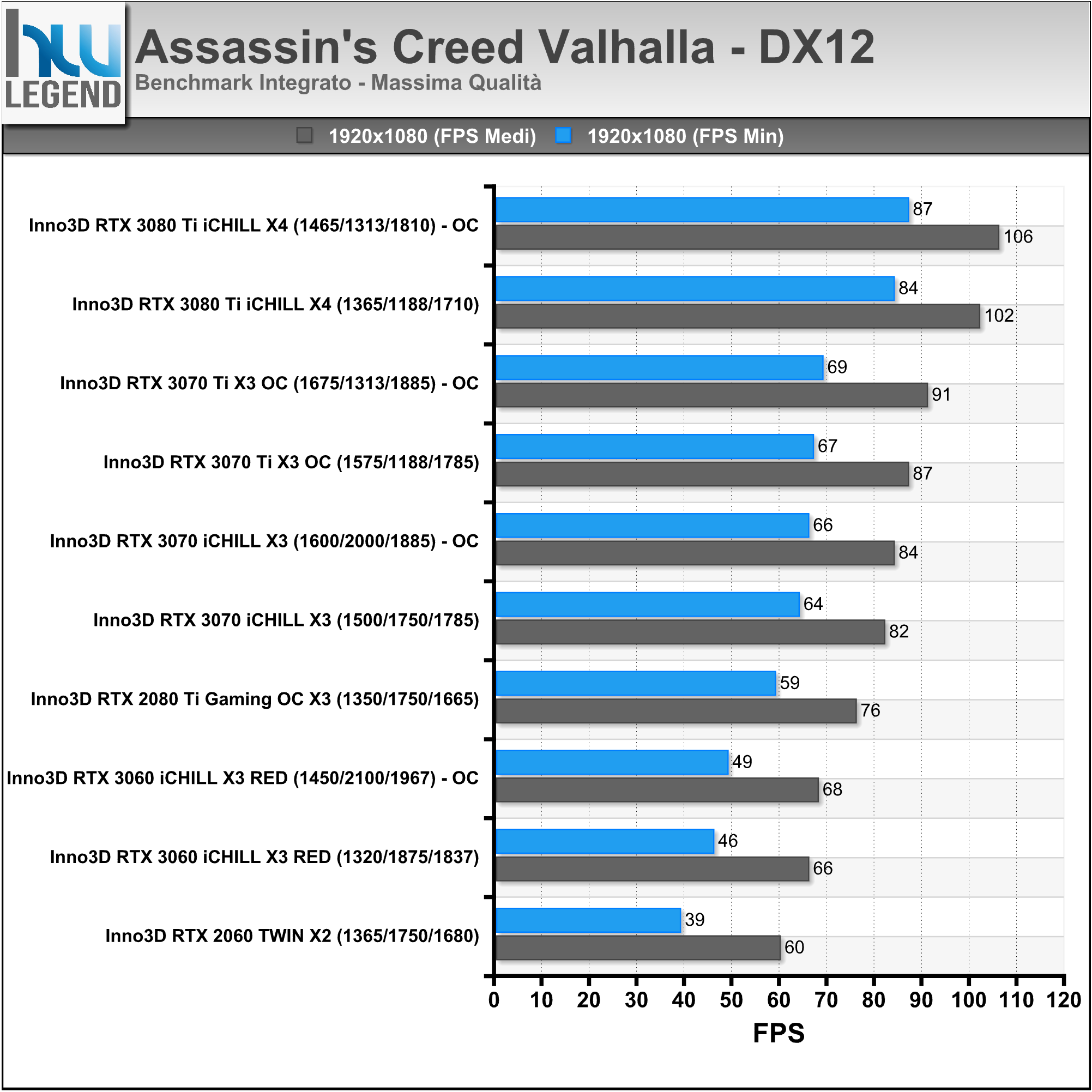
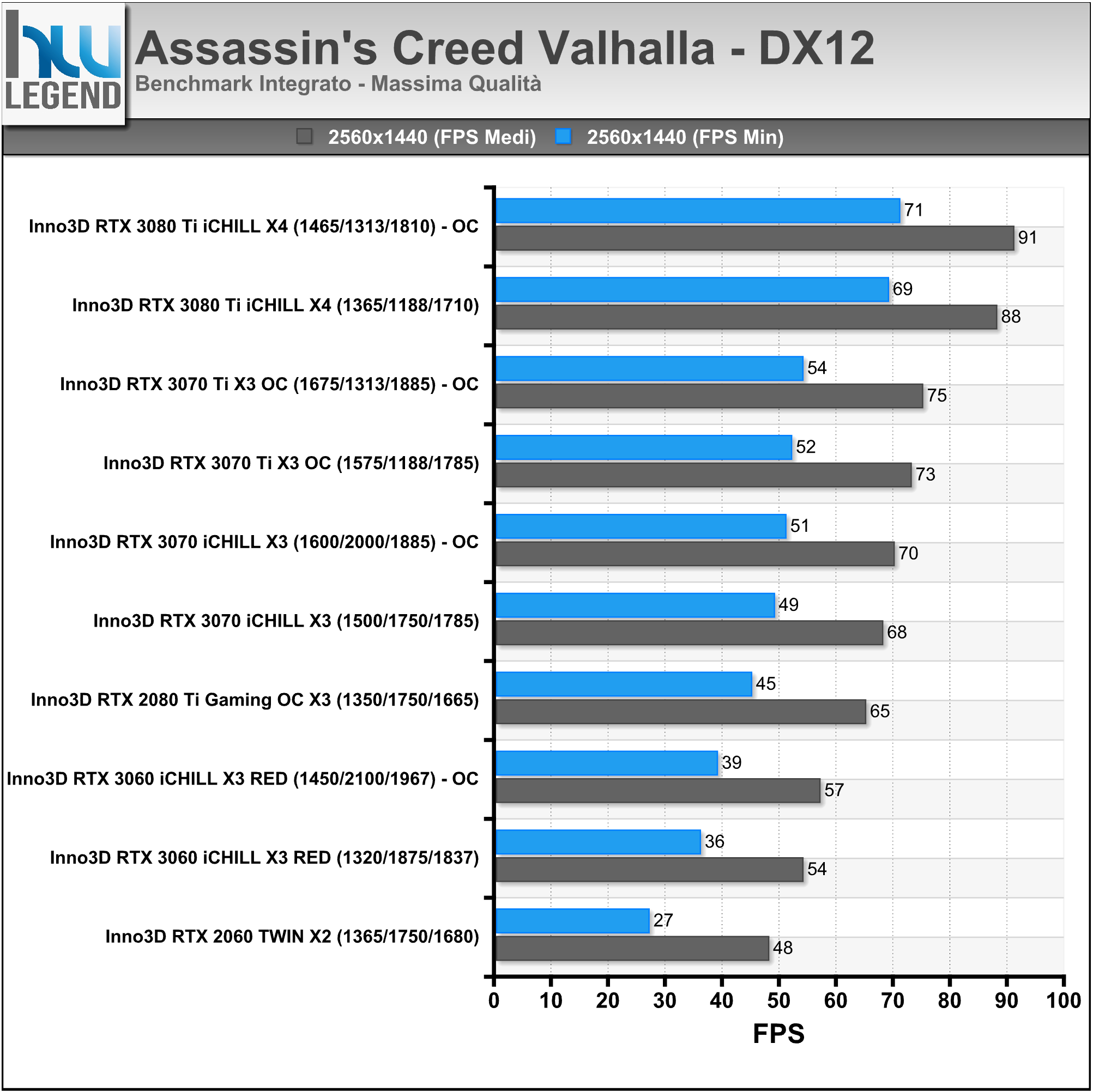
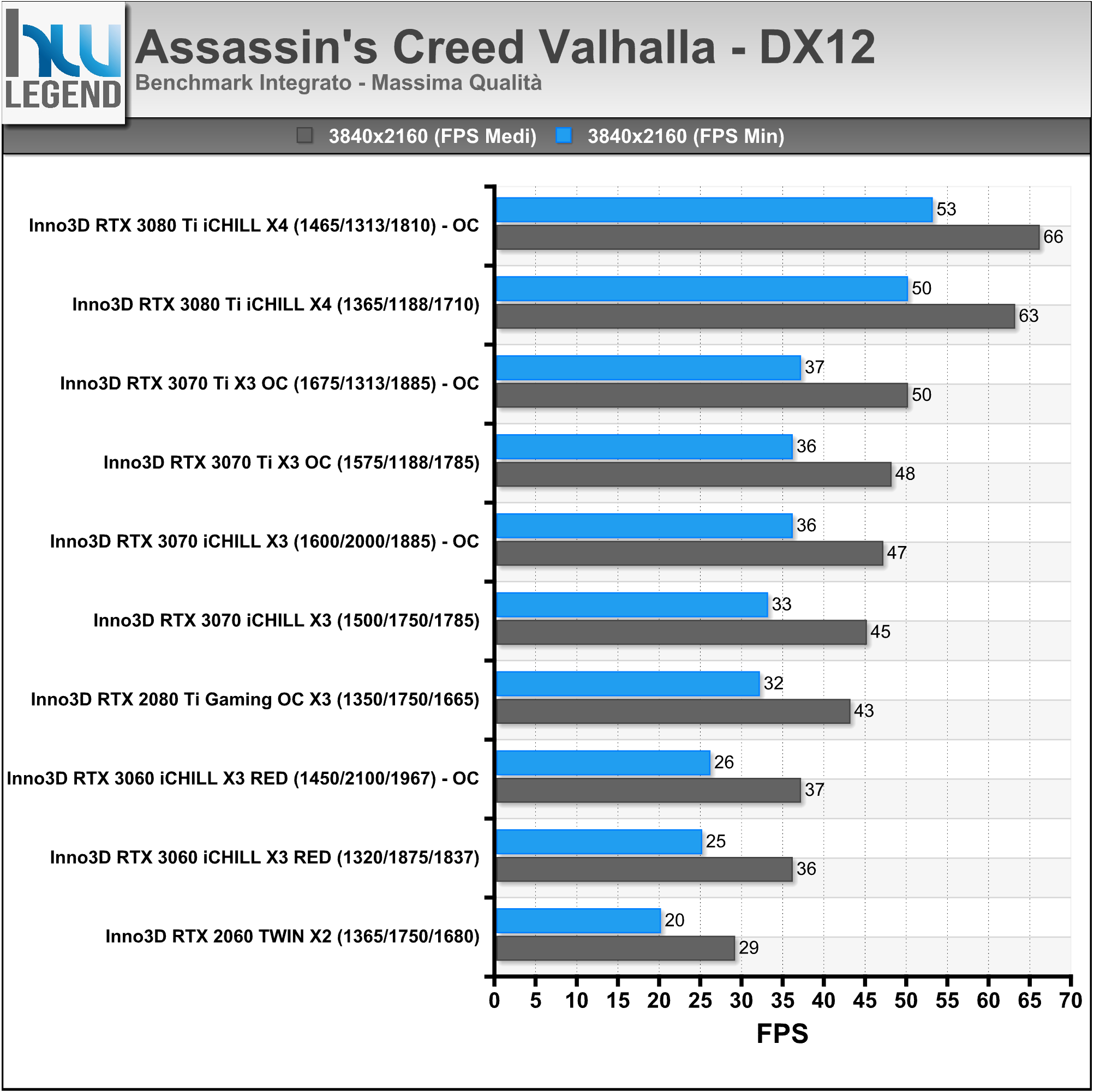
[nextpage title=”DX12: Battlefield V “]
Battlefield V è uno sparatutto in prima persona, sviluppato da Digital Illusions Creative Entertainment (DICE) e pubblicato da Electronic Arts. È il sedicesimo capitolo della serie Battlefield.
Il gioco è stato ufficialmente rilasciato per PC, PlayStation 4 e Xbox One il 20 novembre 2018, allo scopo di continuare il filone storico intrapreso dal suo precursore Battlefield 1, concentrandosi e basandosi sulle ambientazioni e vicende della seconda guerra mondiale.

L’ultimo capitolo del gioco non soltanto supporta le librerie DirectX 12, ma è stato il primo titolo ad implementare il pieno supporto al ray-tracing tramite API DirectX Raytracing (DXR) e alla tecnologia Deep Learning Super-Sampling (DLSS) di NVIDIA. I test sono stati condotti usando i seguenti settaggi:
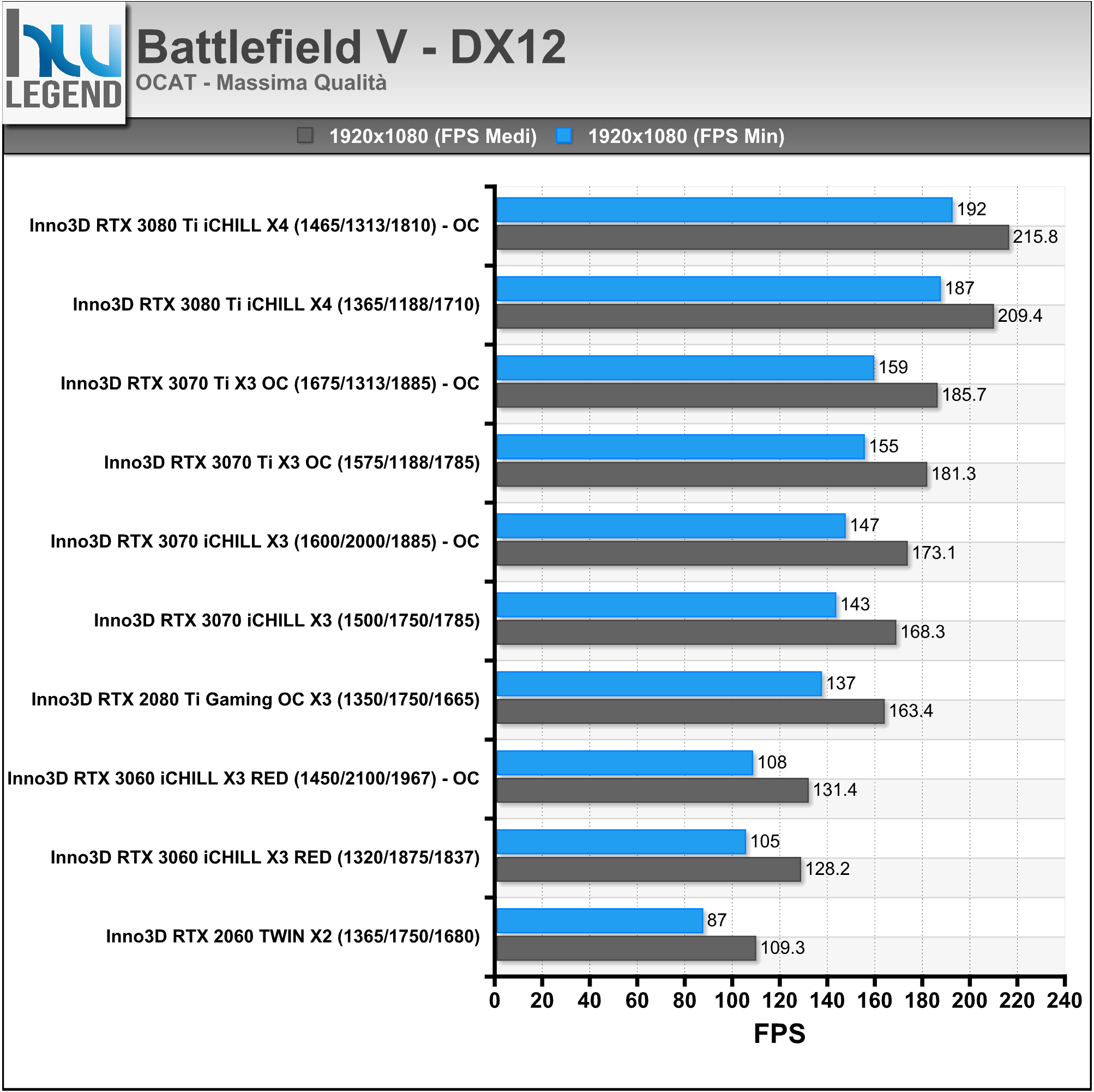
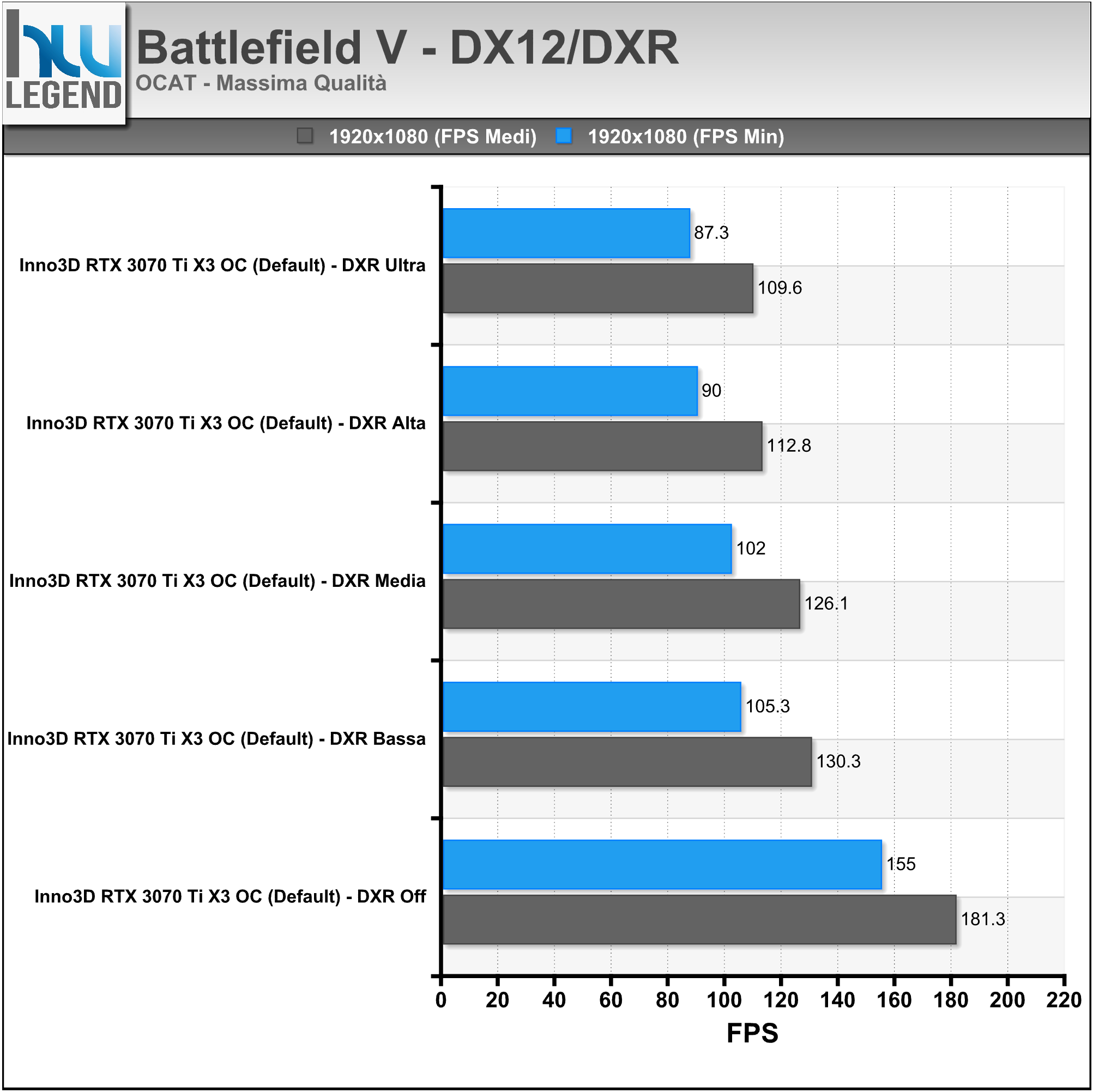
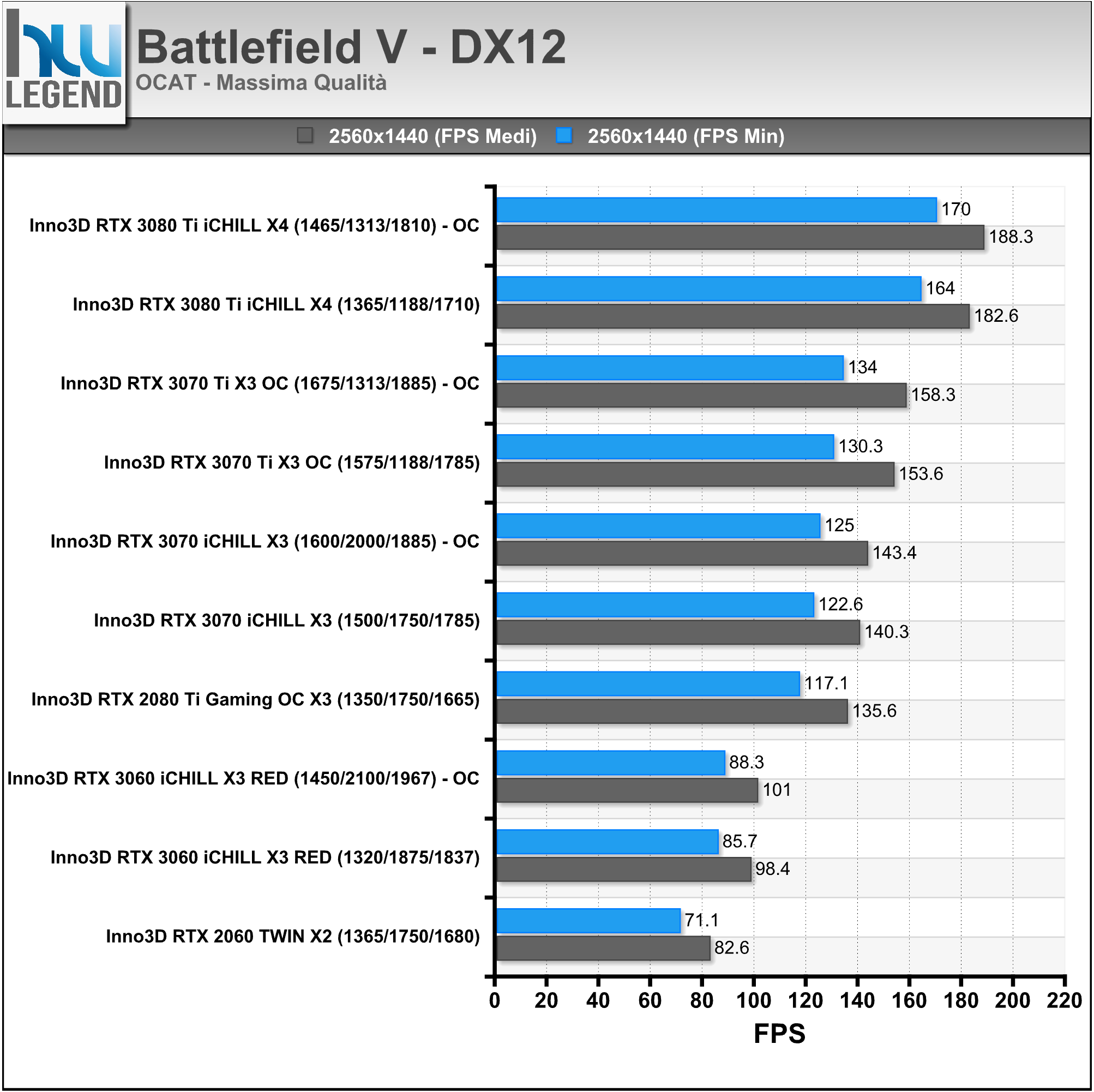
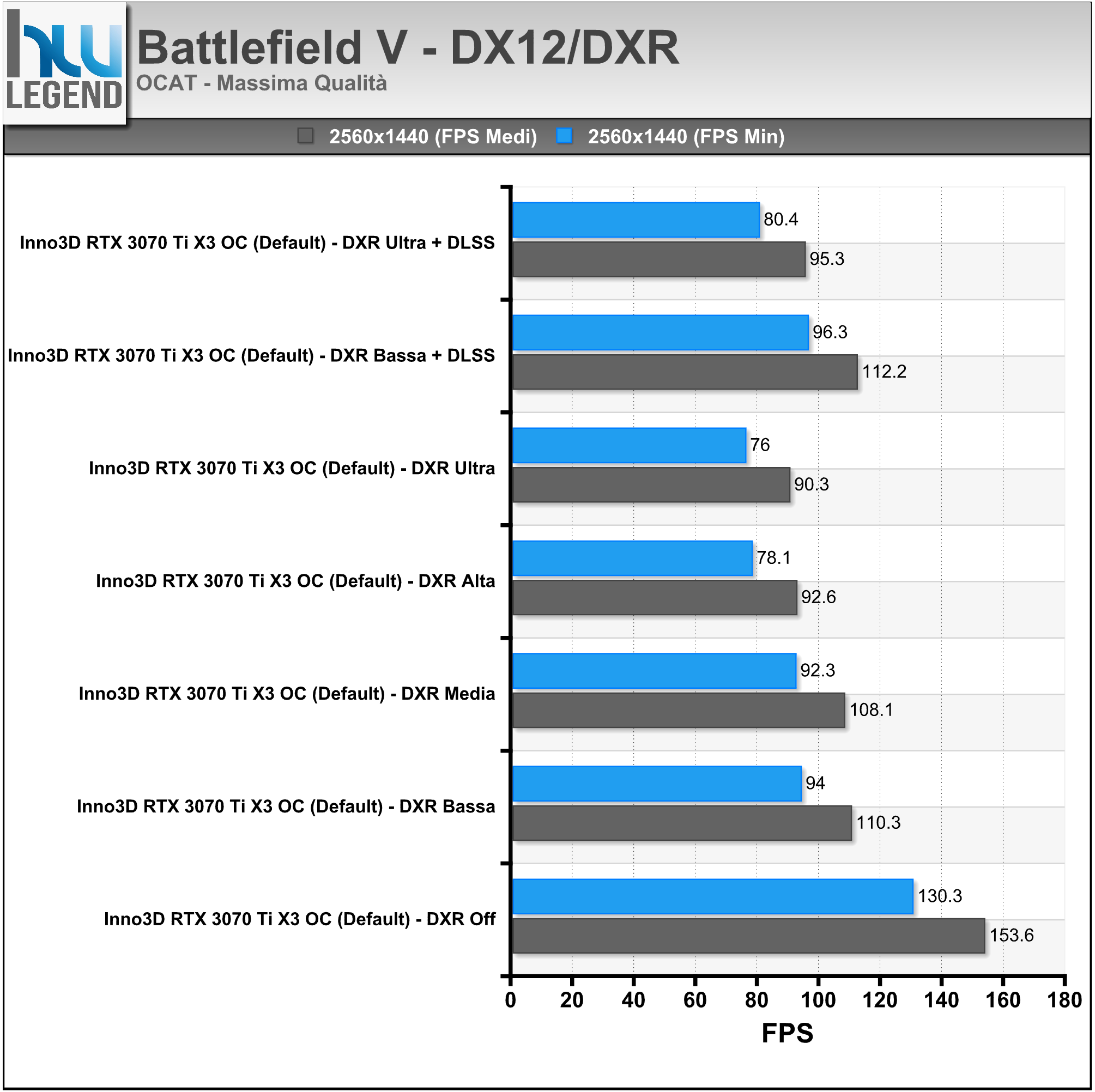
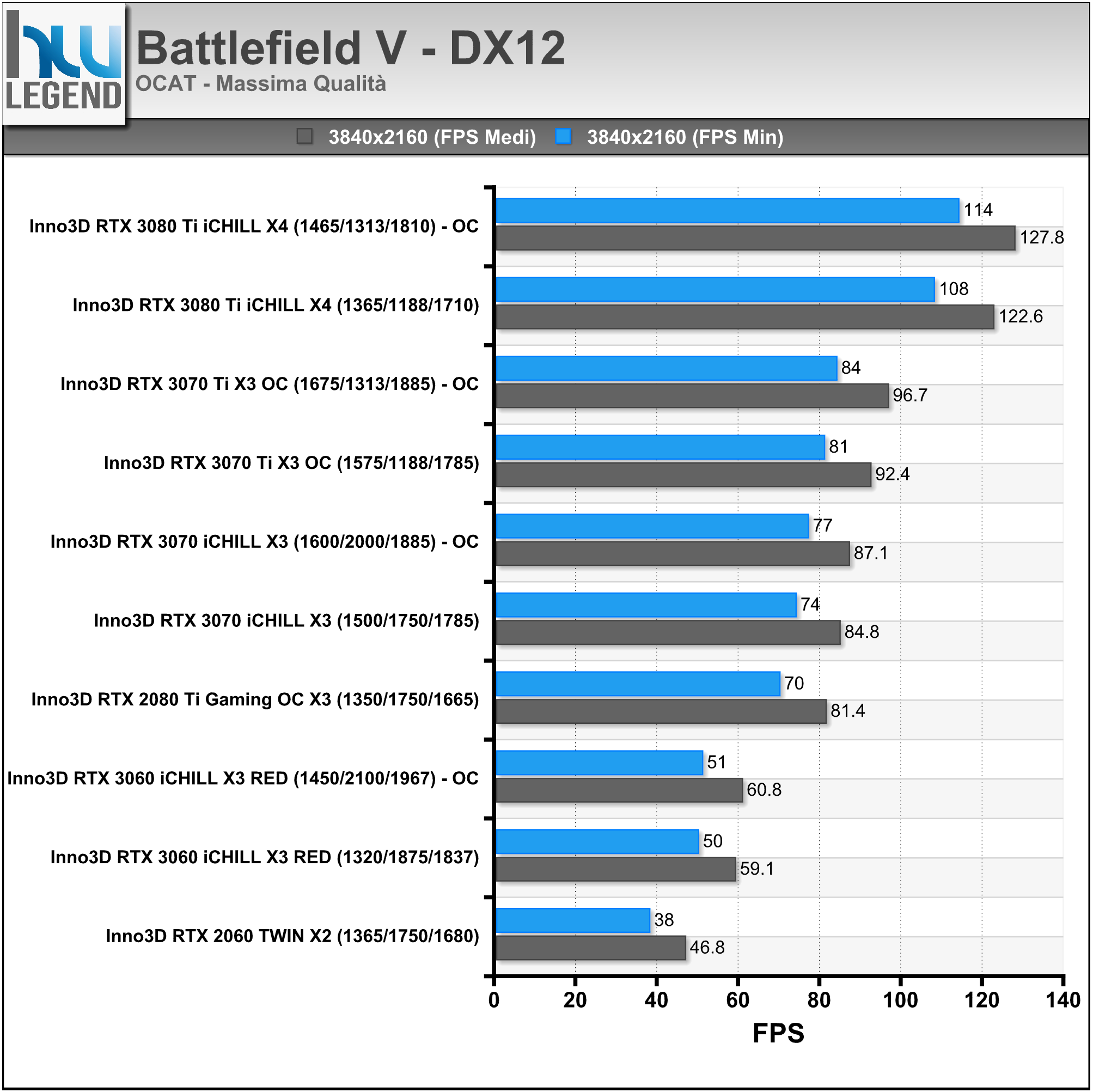
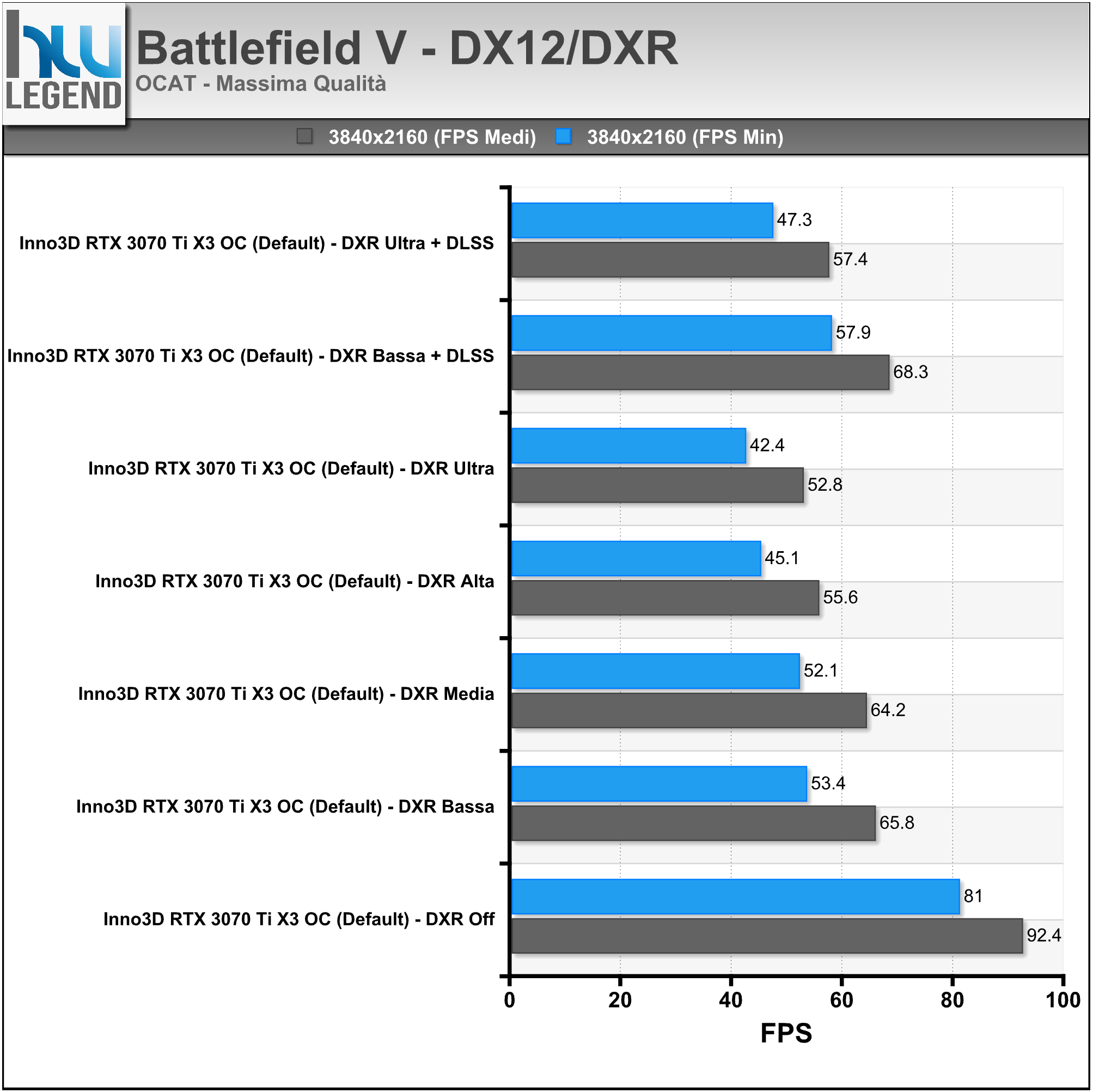
NOTA: Per la misurazione degli FPS abbiamo utilizzato l’ultima versione disponibile del software OCAT, liberamente scaricabile a questo indirizzo e capace di registrare correttamente il framerate indipendentemente dalle API in uso.
[nextpage title=”DX12: Metro Exodus”]
Metro Exodus è un videogioco action-adventure FPS del 2019, sviluppato da 4A Games e pubblicato da Deep Silver per PlayStation 4, Xbox One e PC. Si tratta del terzo capitolo della serie di videogiochi Metro, basata sui romanzi di Dmitrij Gluchovskij.
Ambientato nel 2036, due anni dopo gli eventi di Metro: Last Light, su una Terra post-apocalittica che è stata devastata 23 anni fa da una guerra nucleare.

Il gioco continua la storia di “Redenzione”, Metro: Last Light. Il giocatore assume il ruolo di Artyom, 27 anni, che fugge dalla metropolitana di Mosca e parte per un viaggio, attraverso i continenti, con Spartan Rangers fino all’Estremo Oriente. Artyom viaggia per la prima volta lungo il fiume Volga, non lontano dagli Urali, per raggiungere una locomotiva conosciuta come “Aurora” che viaggia verso est. La storia si svolge nel corso di un anno, a partire dal duro inverno nucleare nella metropolitana.
Quest’ultimo capitolo, oltre a sfruttare le ultime librerie DirectX 12, è tra i primi titoli ad implementare il pieno supporto al ray-tracing tramite API DirectX Raytracing (DXR) e alla tecnologia Deep Learning Super-Sampling (DLSS) di NVIDIA. I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:
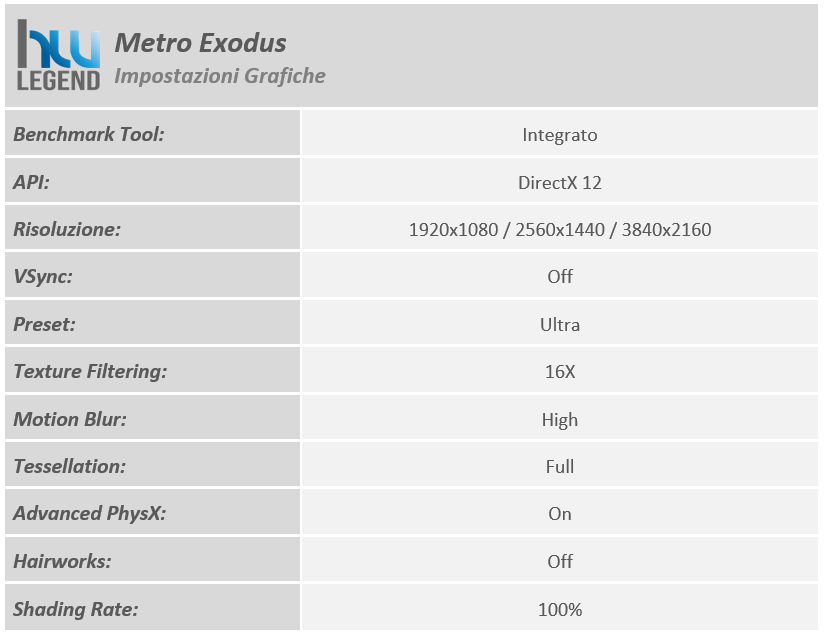
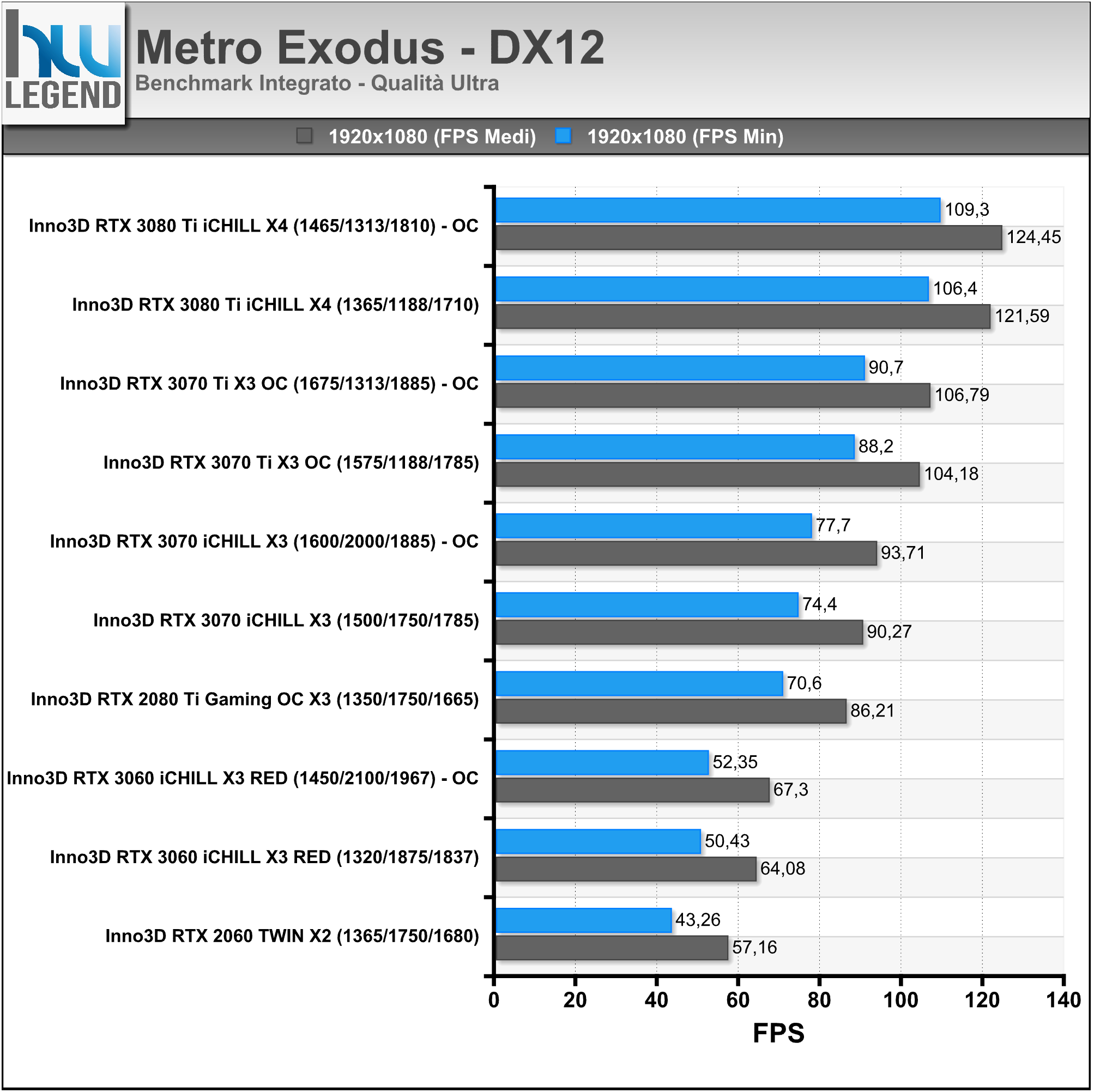
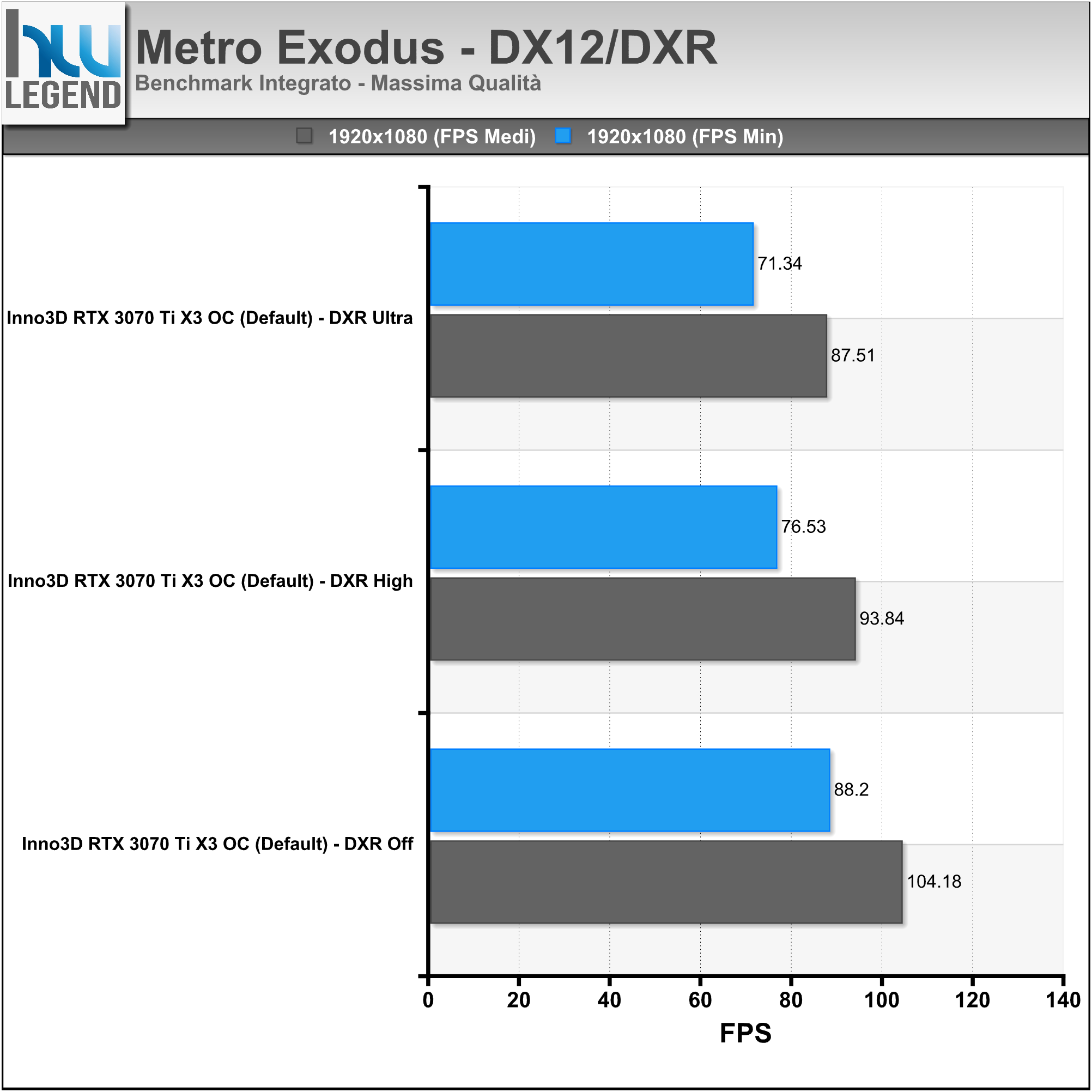
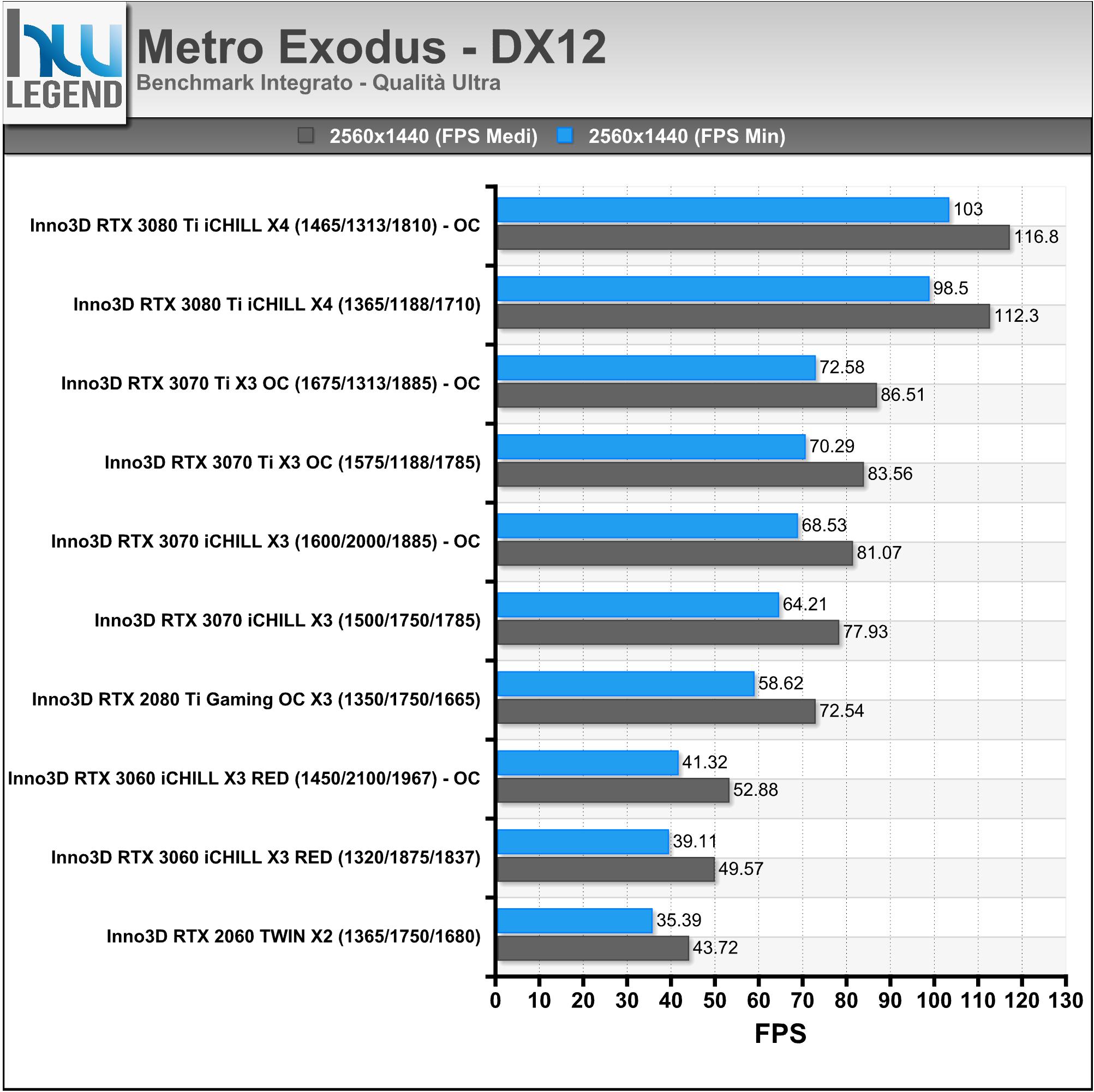
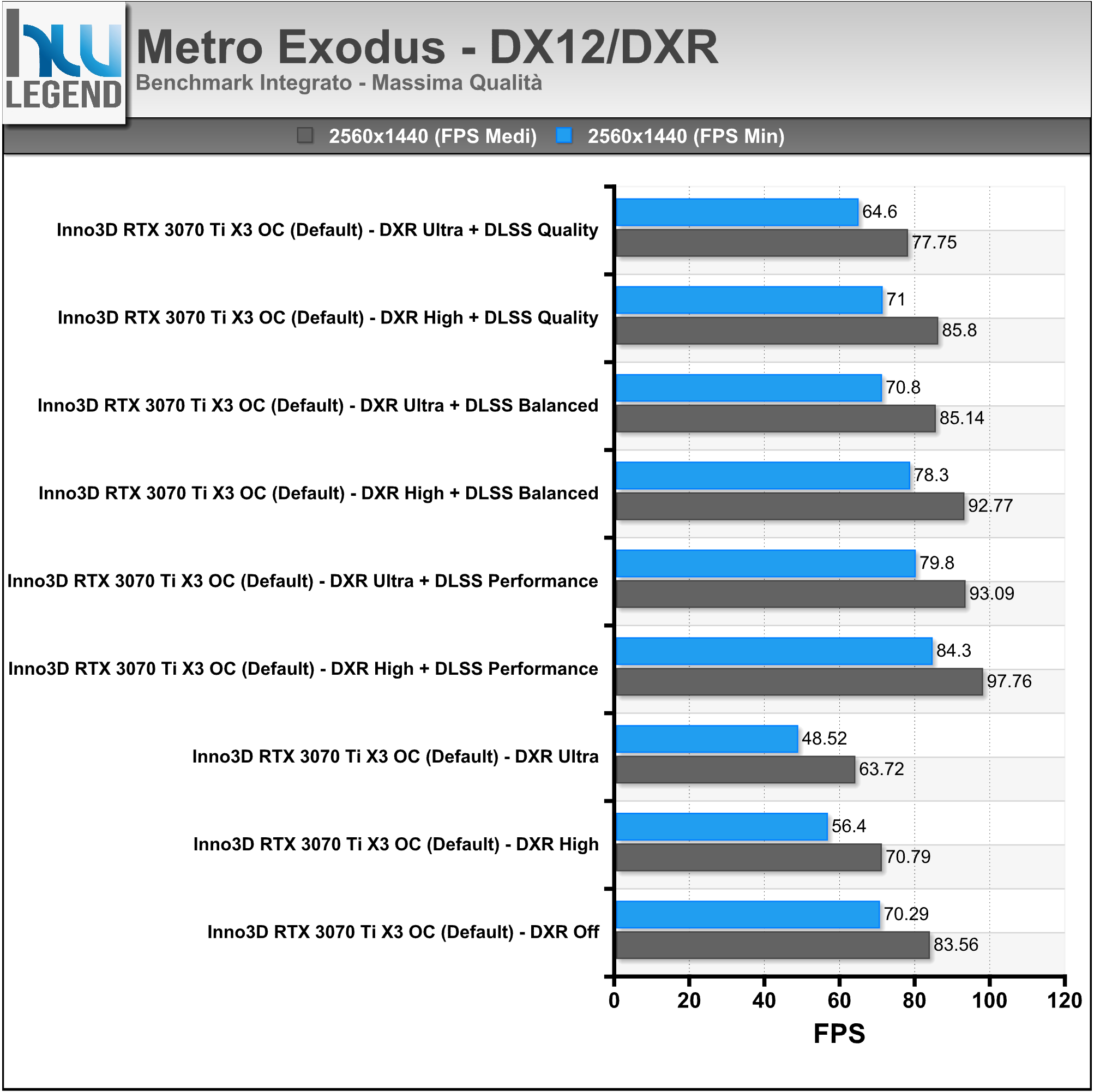
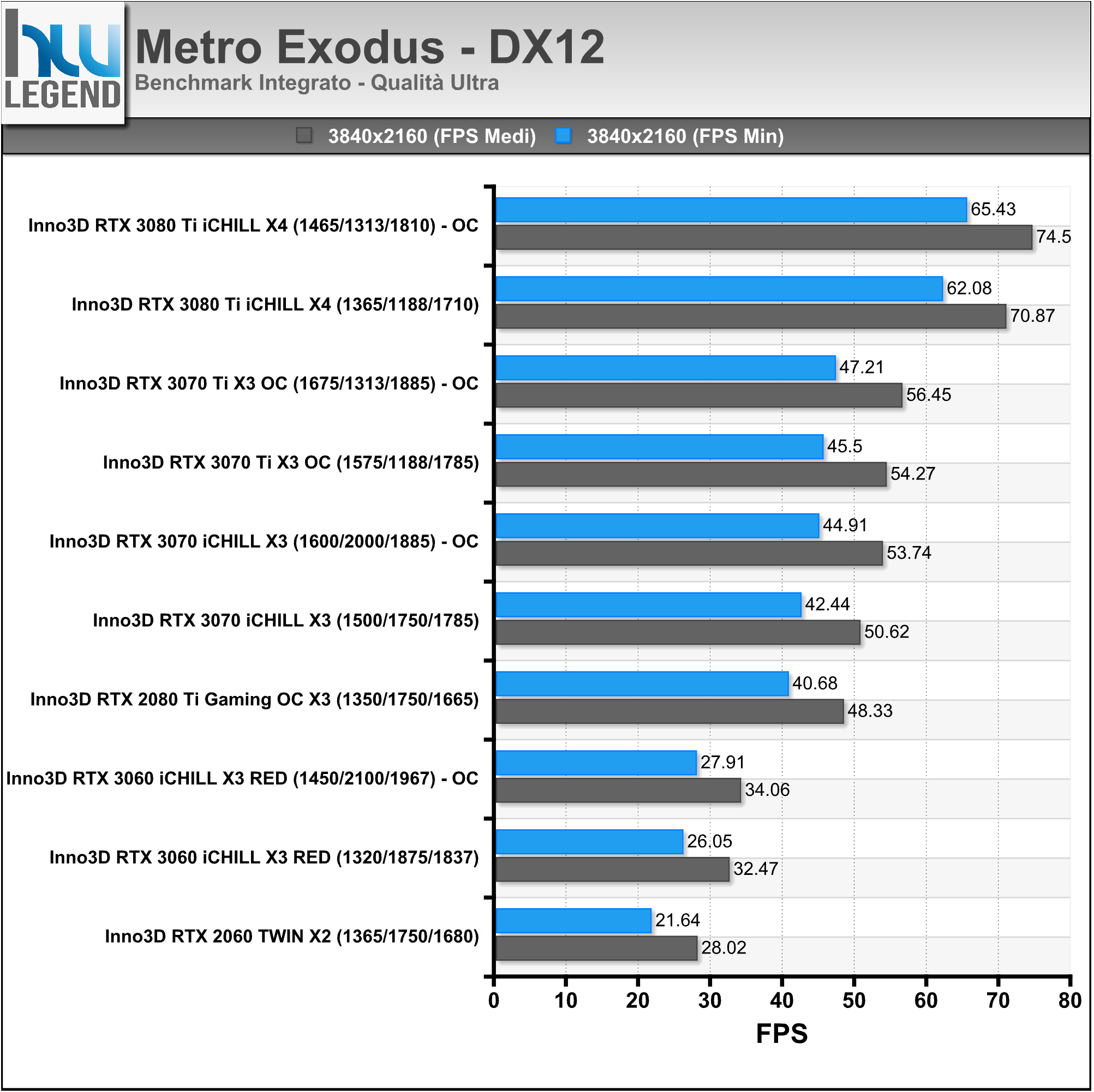
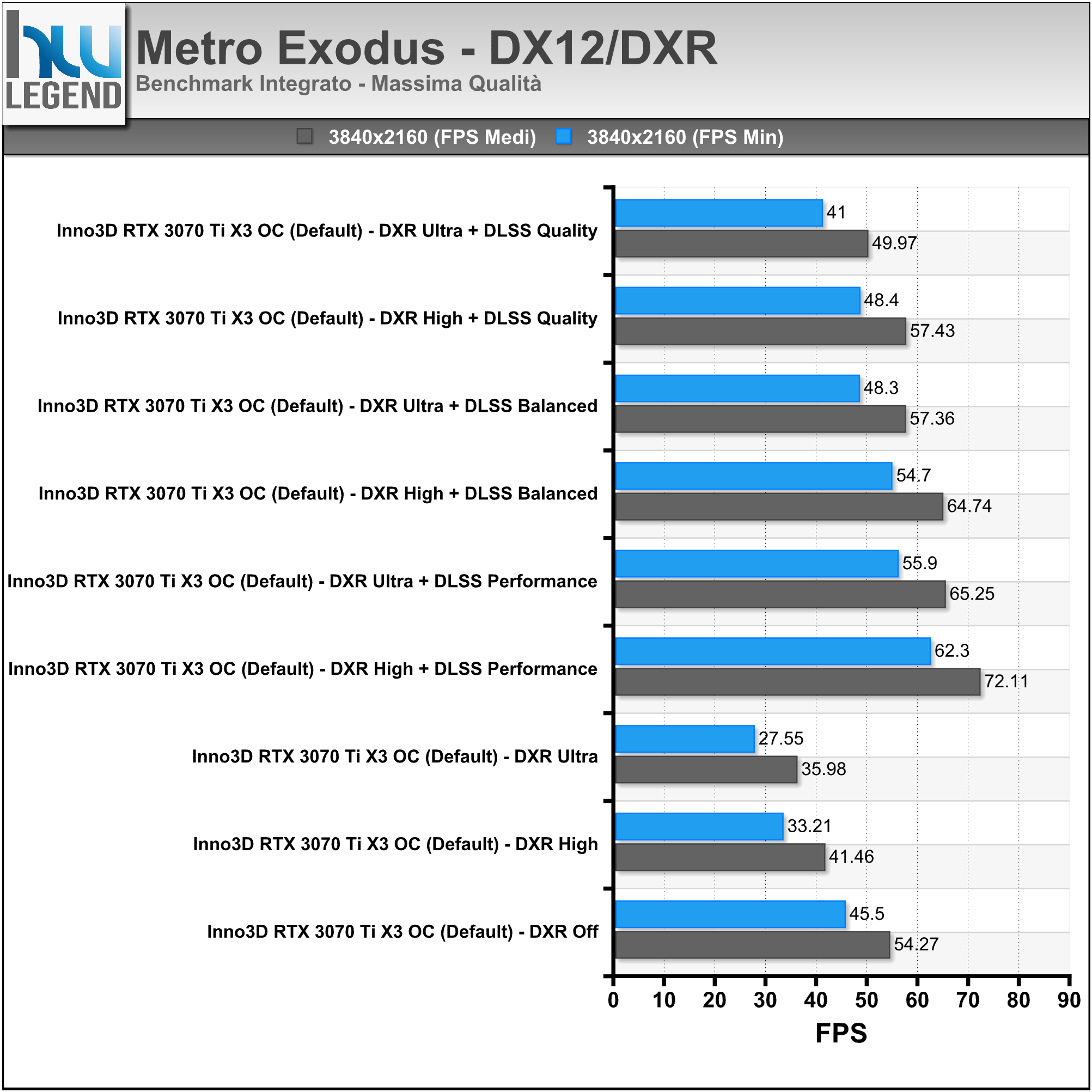
[nextpage title=”DX12: Shadow of the Tomb Raider”]
Circa due mesi dopo la sua precedente avventura, Lara Croft e il suo amico Jonah sono nuovamente sulle tracce della Trinità. Seguendo gli indizi lasciati dal padre di Lara, i due arrivano a Cozumel, in Messico, per spiare il capo della cellula locale, il dottor Pedro Dominguez; durante una spedizione in una tomba già visitata dall’organizzazione, Lara scopre alcune notizie circa una misteriosa città nascosta.
Successivamente, camuffandosi con gli abiti tipici per il dia de los muertos, Lara riesce a seguire gli adepti della Trinità, scoprendo così che Dominguez è addirittura il capo dell’organizzazione e che è sulle tracce di una misteriosa reliquia nascosta in un tempio non ancora localizzato. Vivi momenti di pura azione, conquista nuovi luoghi ostili, combatti usando tattiche di guerriglia ed esplora tombe mortali in questa evoluzione del genere action survival.

L’ultimo capitolo della saga (il settimo in ordine cronologico), presentato lo scorso mese di settembre su PC, è sviluppato dalla Crystal Dynamics e distribuito da Square Enix ed è in grado di sfruttare le ultime DirectX 12, oltre che il ray-tracing delle ombre tramite API DirectX Raytracing (DXR) e la tecnologia Deep Learning Super-Sampling (DLSS) di NVIDIA. I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:
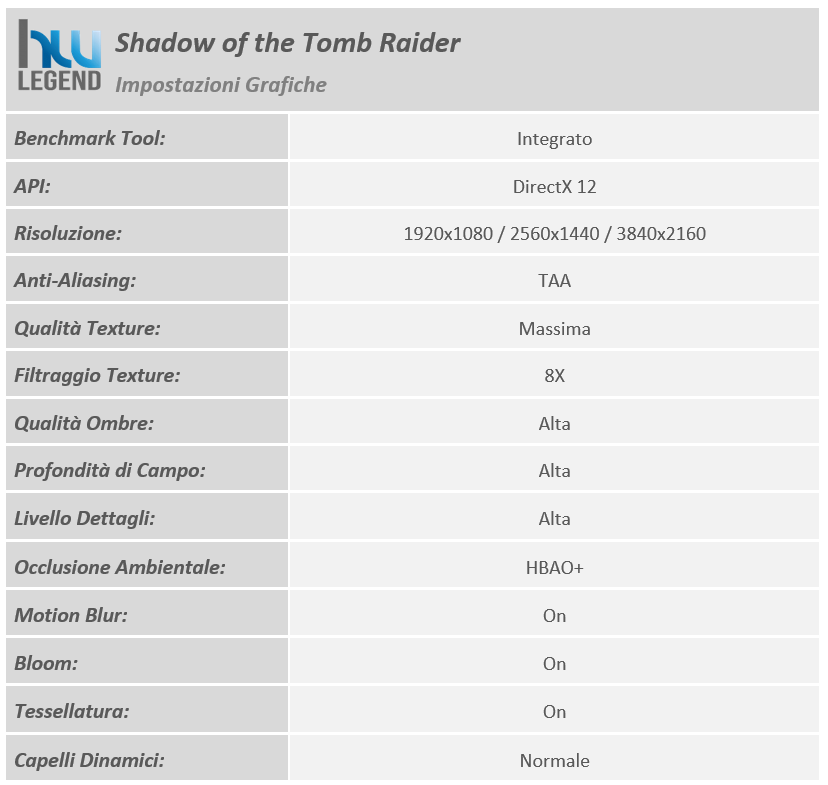
Seppur con considerevole ritardo rispetto alle previsioni anche nell’ultimo capitolo di Tomb Raider è finalmente possibile abilitare il ray-tracing in tempo reale (nello specifico per quanto riguarda le ombre). Anche in quest’occasione viene assicurata un’esperienza di gioco più realistica e coinvolgente, ma ancora una volta le prestazioni subiscono un calo senz’altro significativo. Fortunatamente la resa grafica in presenza della tecnologia DLSS di NVIDIA si dimostra più che soddisfacente, rendendo, di fatto, decisamente più abbordabile l’utilizzo del ray-tracing in tempo reale.
Nei grafici che seguono vi mostriamo l’impatto prestazionale derivato dall’uso dei vari livelli previsti per il DXR (Medio, Alto e Ultra). Per quanto riguarda, invece, la tecnologia NVIDIA DLSS abbiamo inserito i risultati ottenuti in seguito alla sua abilitazione nelle uniche risoluzioni previste in abbinamento alla soluzione grafica in esame (GeForce RTX 3070 Ti), ovvero in 1440p (2560 x 1440) e in 4K (3840 x 2160).
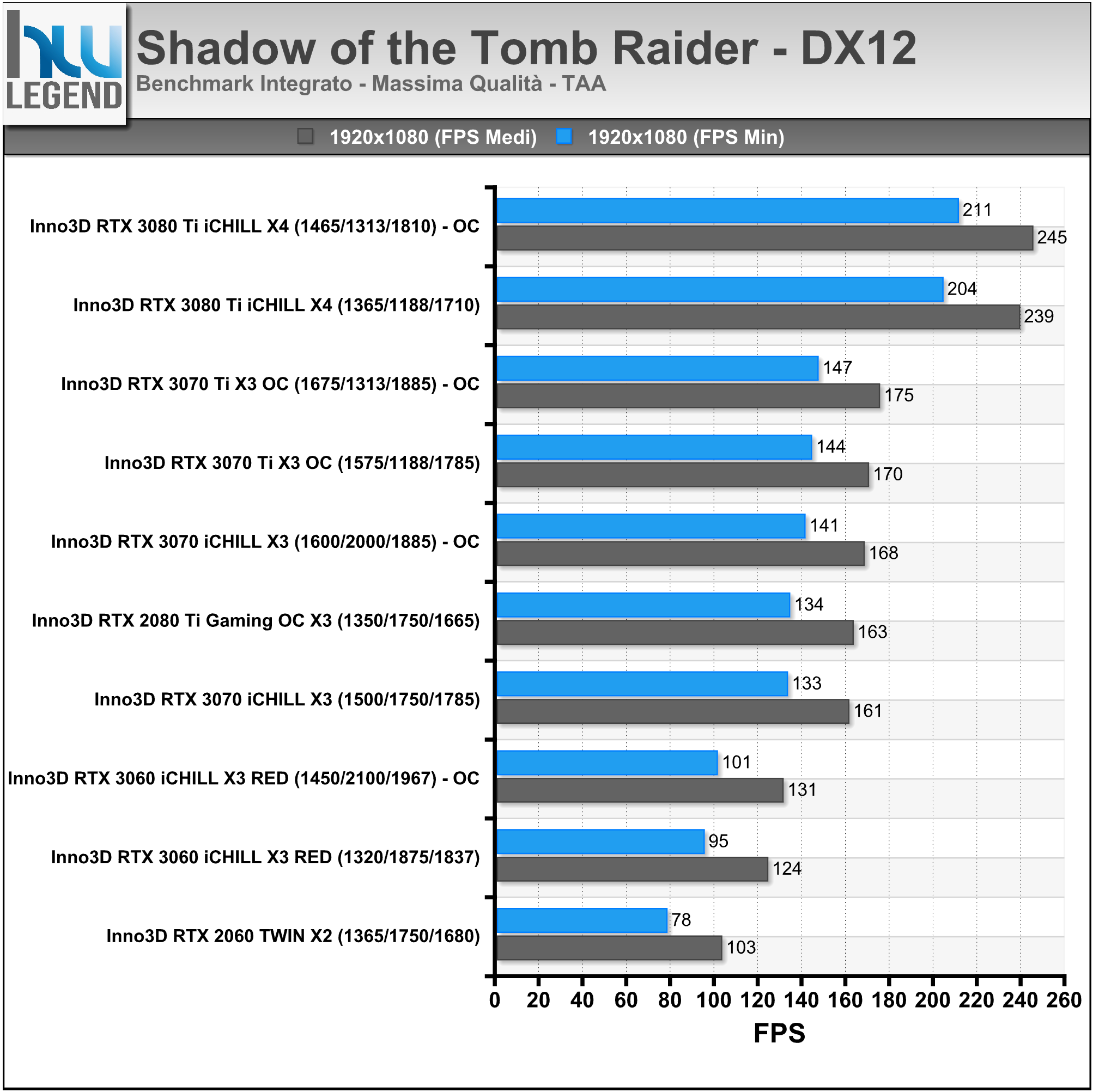
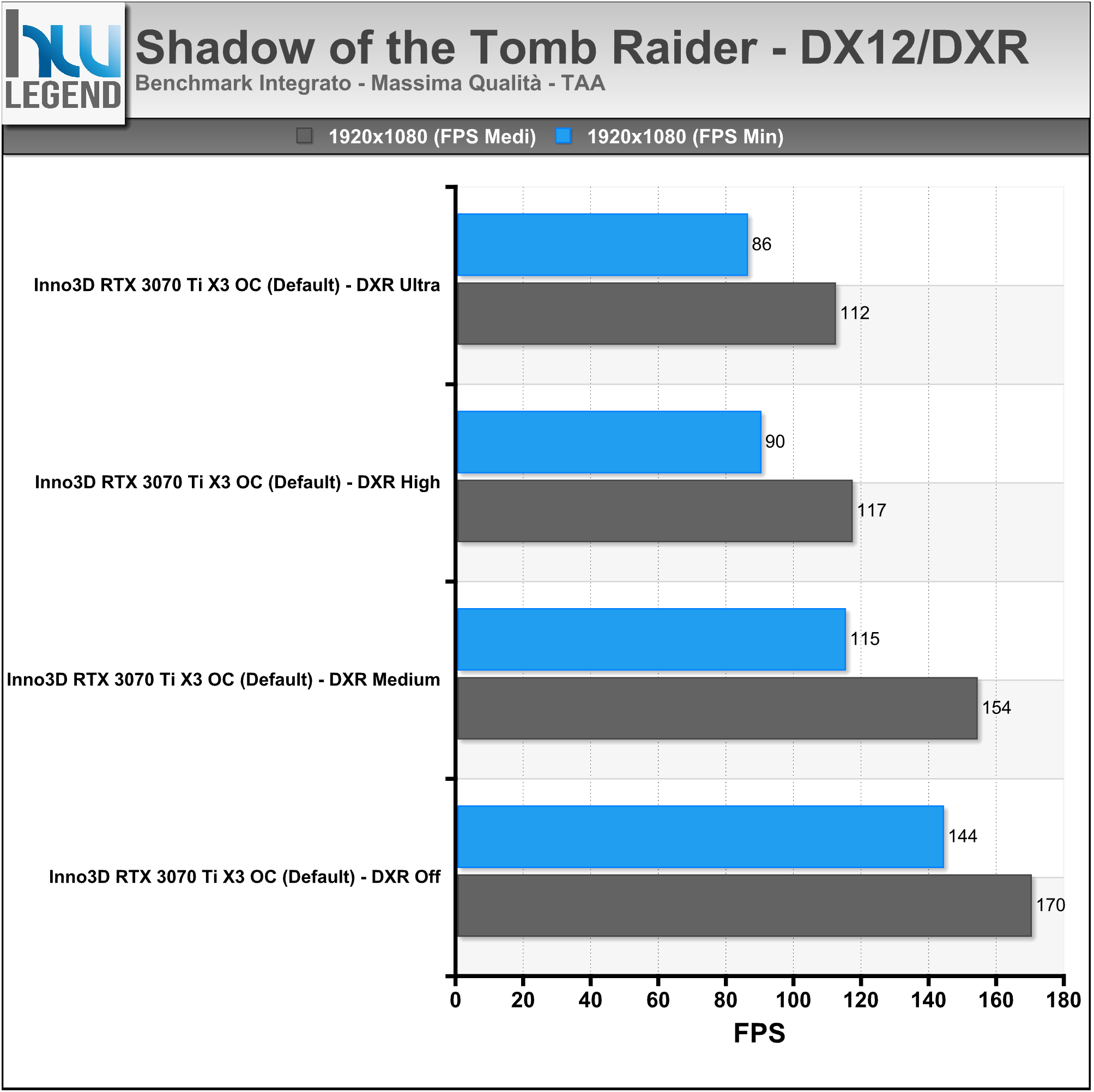
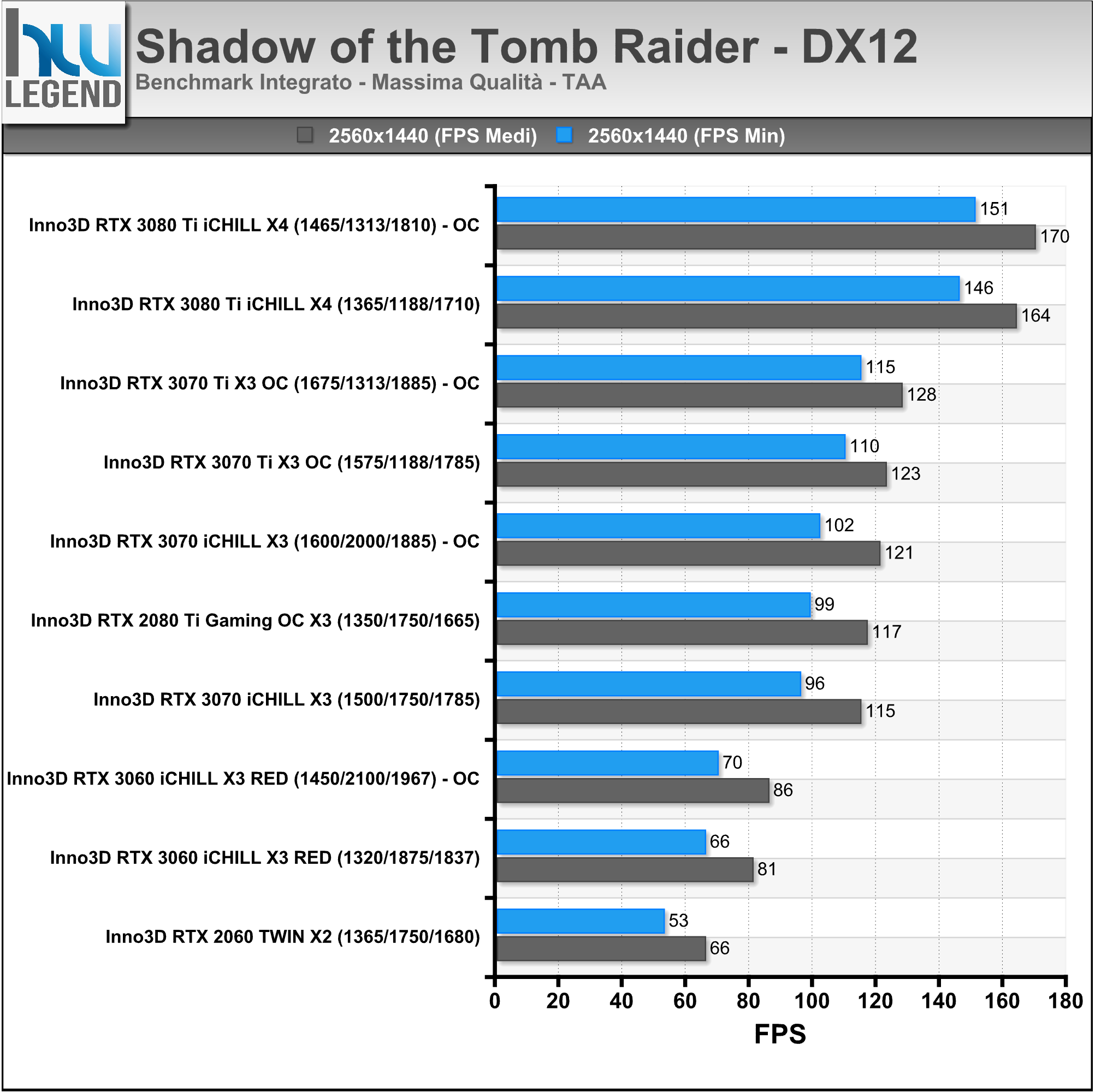
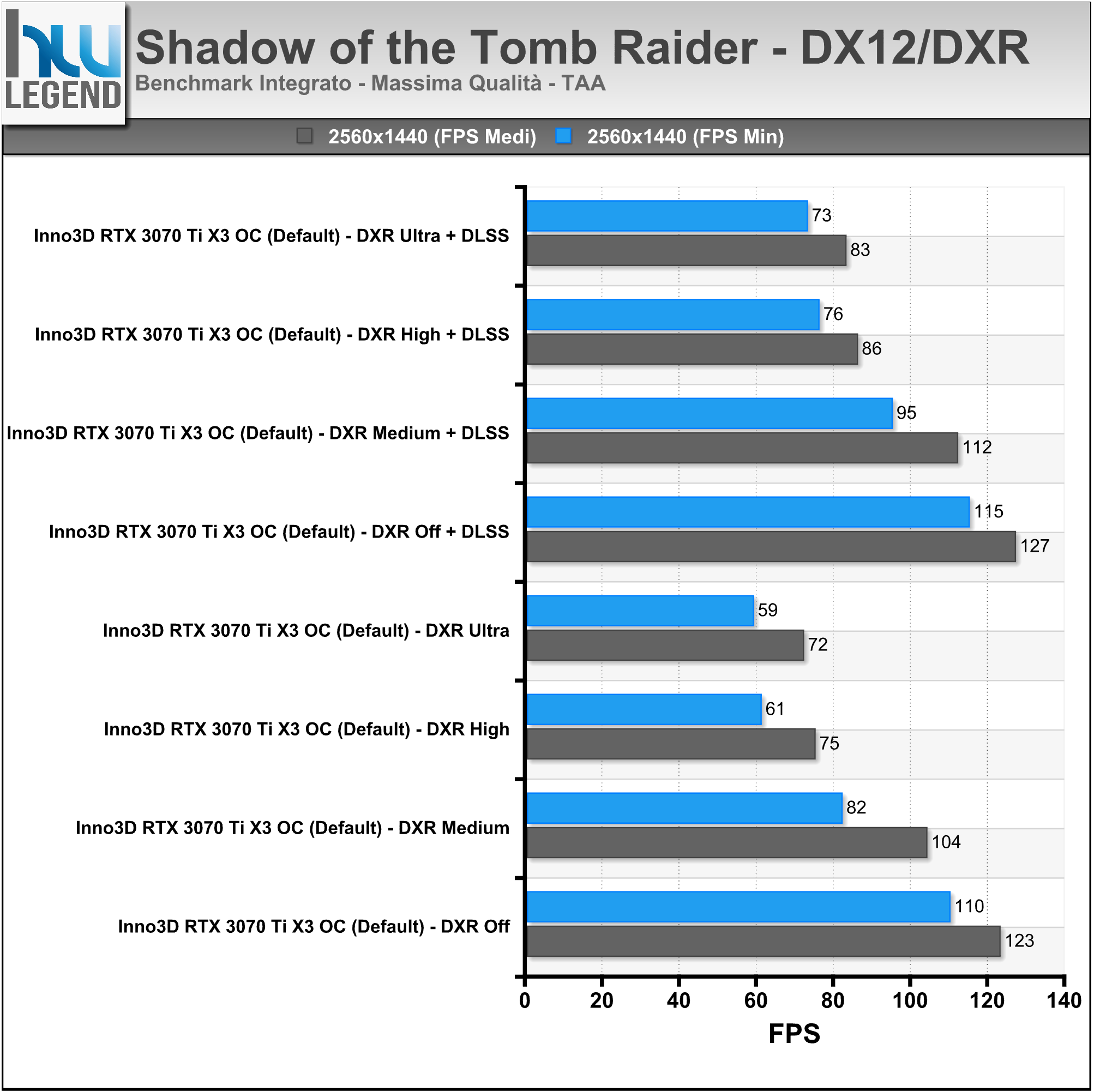
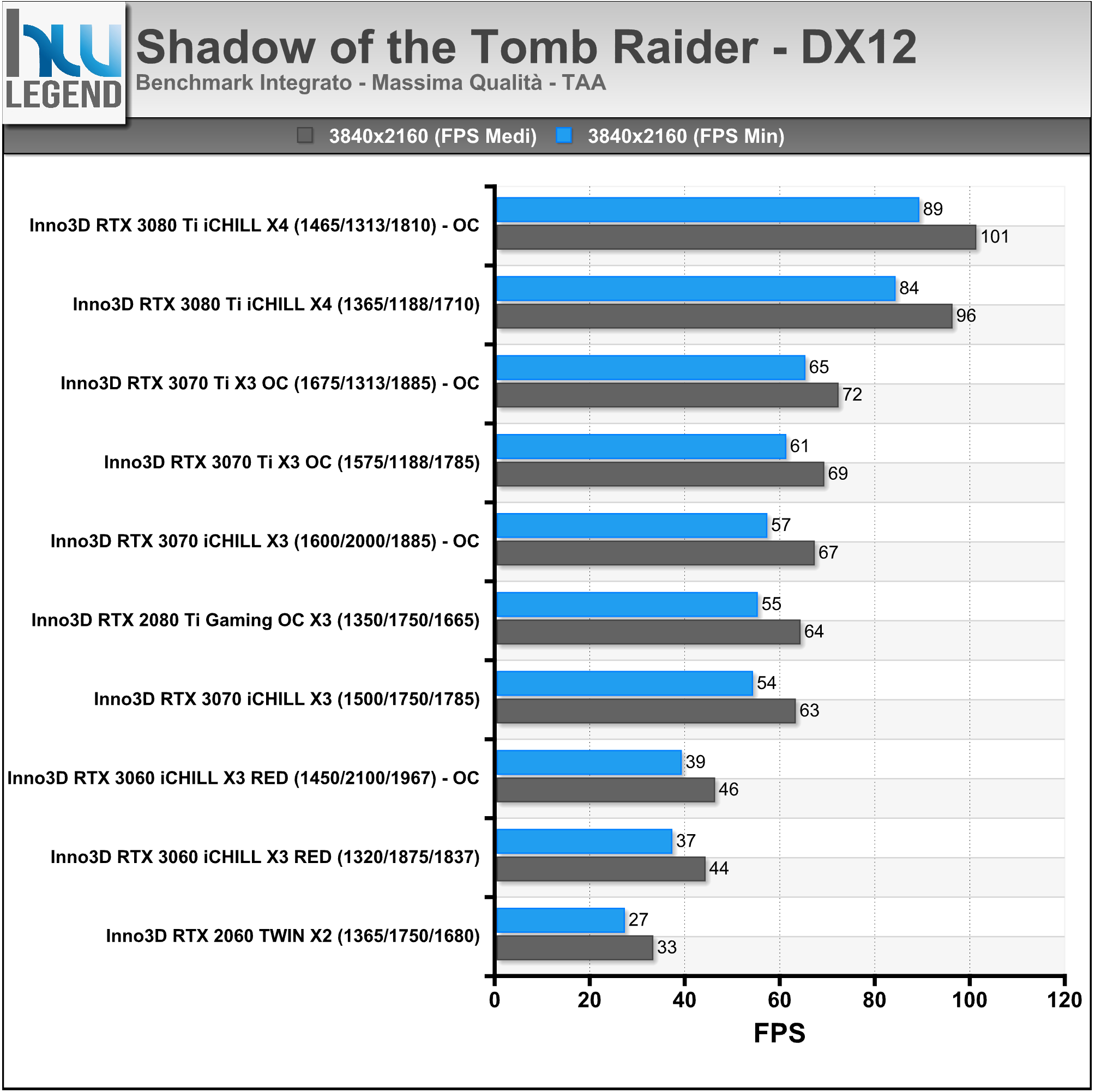
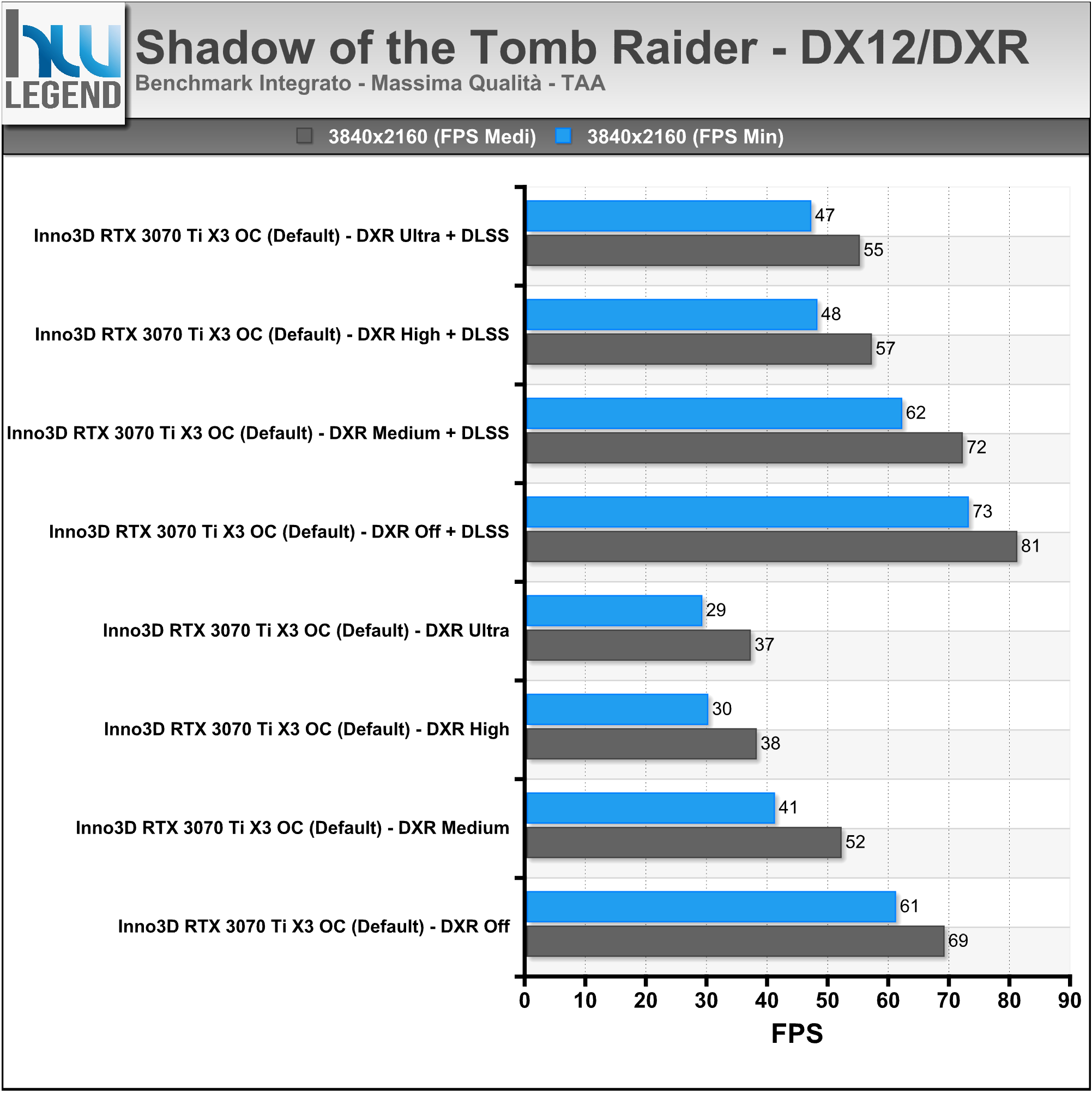
[nextpage title=”DX12: Deus Ex Mankind Divided”]
Deus Ex Mankind Divided riprende le vicende di Adam Jensen da uno dei finali del precedente capitolo. In particolare scopriamo che Adam ha affondato Panchaea e che è rimasto in coma per due anni in una struttura in Alaska.
Avviato il gioco ci ritroveremo su di un elicottero con una truppa armata e ci renderemo conto che Adam fa ora parte di una squadra anti terrorismo dell’Interpol. Questa ha un agente sotto copertura a Dubai, con lo scopo di entrare in contatto con un trafficante di armi e potenziamenti ed organizzare un incontro.

L’ultimo capitolo della saga, presentato lo scorso mese di agosto su PC, è sviluppato dalla Eidos Montreal e distribuito da Square Enix ed è in grado di sfruttare le ultime DirectX 12. I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:
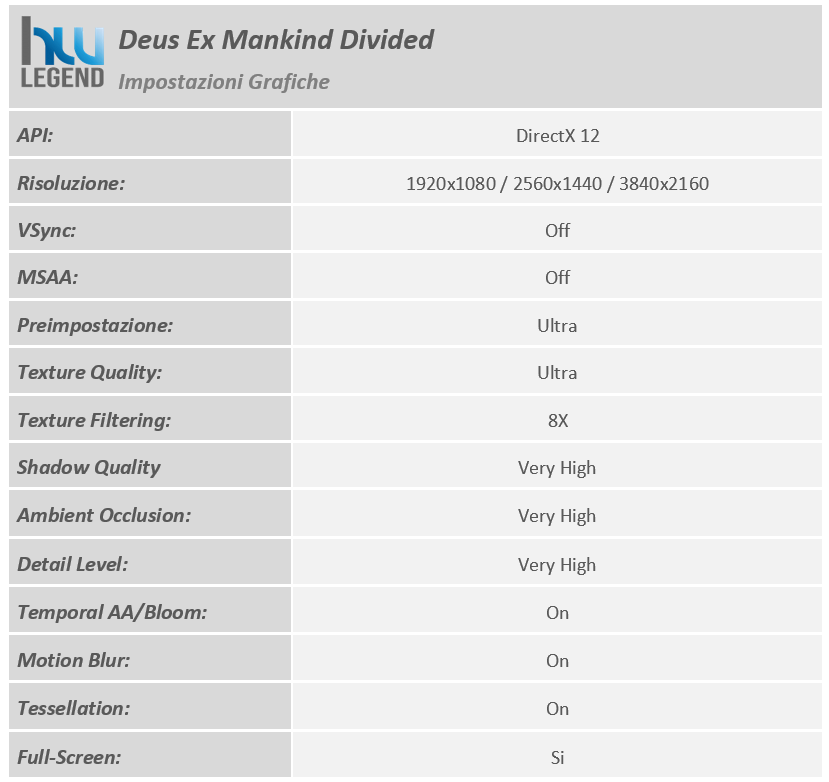
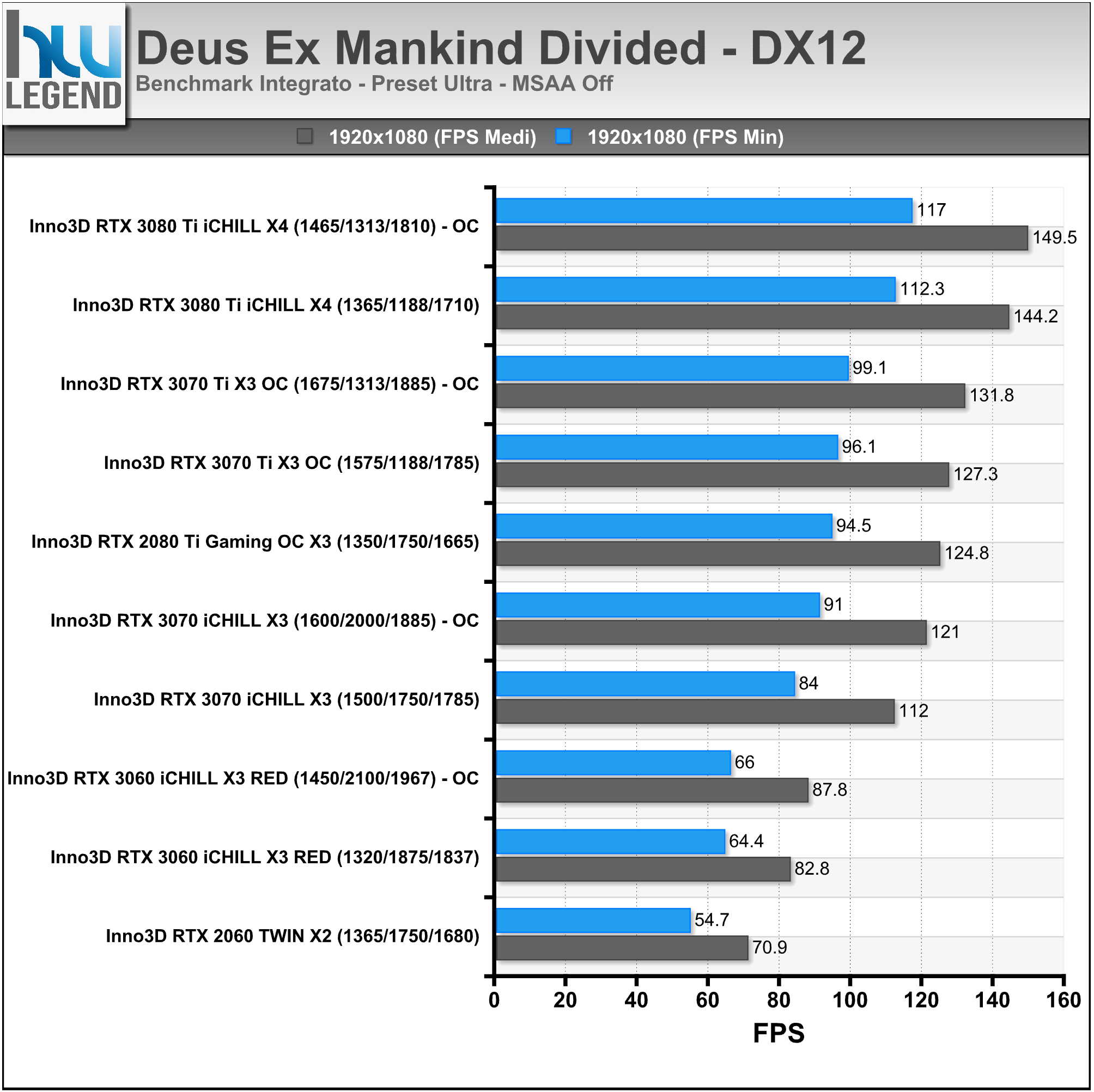
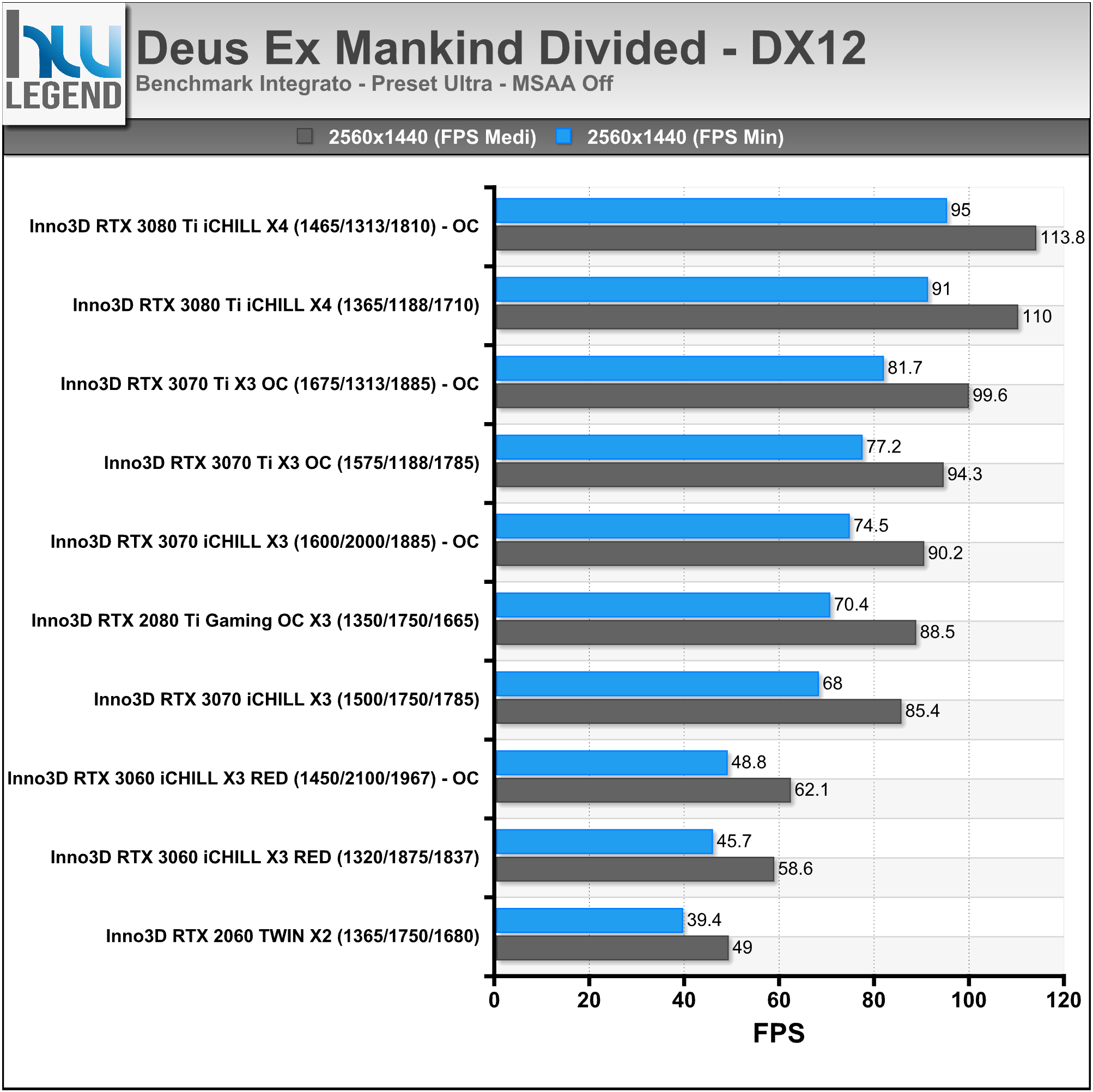
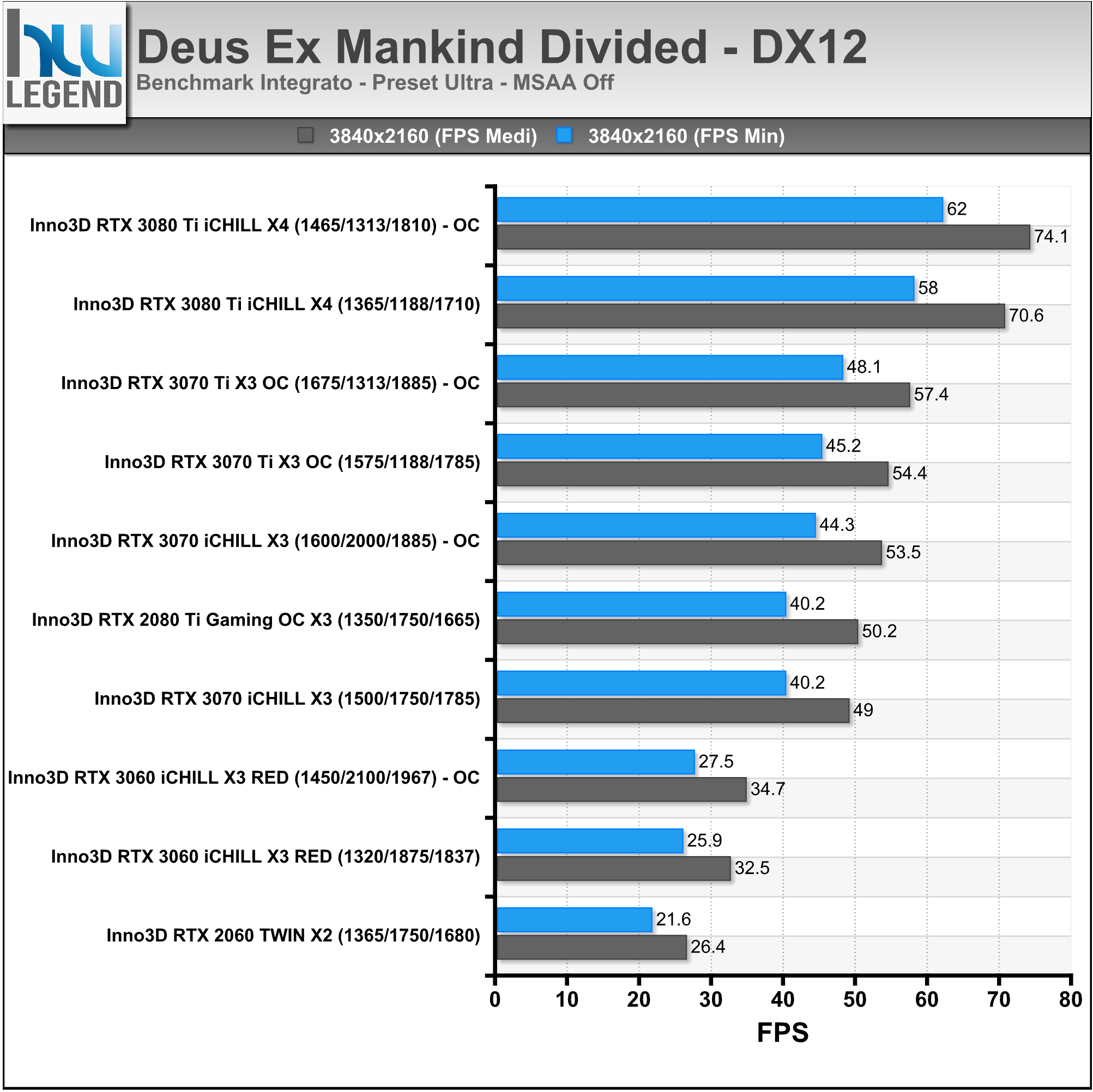
[nextpage title=”DX12: Forza Horizon 4″]
Forza Horizon 4 è un videogioco open world di guida, sviluppato in esclusiva per Xbox One e PC da Playground Games utilizzando il potente motore grafico ForzaTech di Turn 10 Studios, e pubblicato il 2 ottobre 2018.
Il gioco è ambientato in Inghilterra, e comprende varie regioni iconiche come le Costwolds, Edimburgo e la Scozia settentrionale e nord-occidentale. L’open world del gioco, grande quanto quello del suo predecessore Horizon 3, cambia in modo dinamico con il passare delle stagioni.

D’inverno il paesaggio è coperto di neve e ghiaccio e poco illuminato; d’estate, al contrario, l’illuminazione è molto più calda e accesa. In autunno, le foglie ricoprono la strada e il paesaggio si colora di giallo e marrone, mentre in primavera assume un colore verde brillante, con un cielo azzurro. I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:
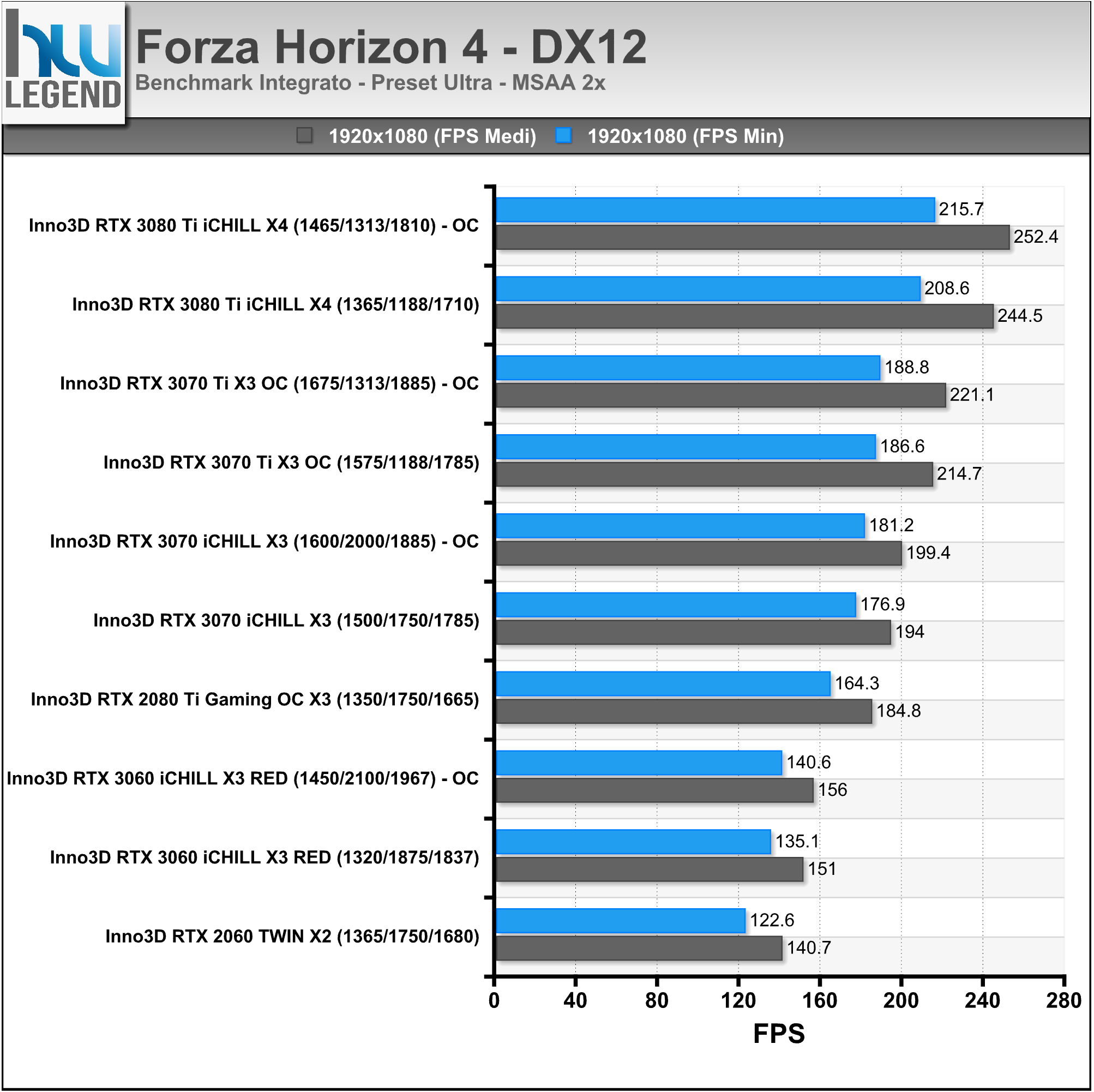
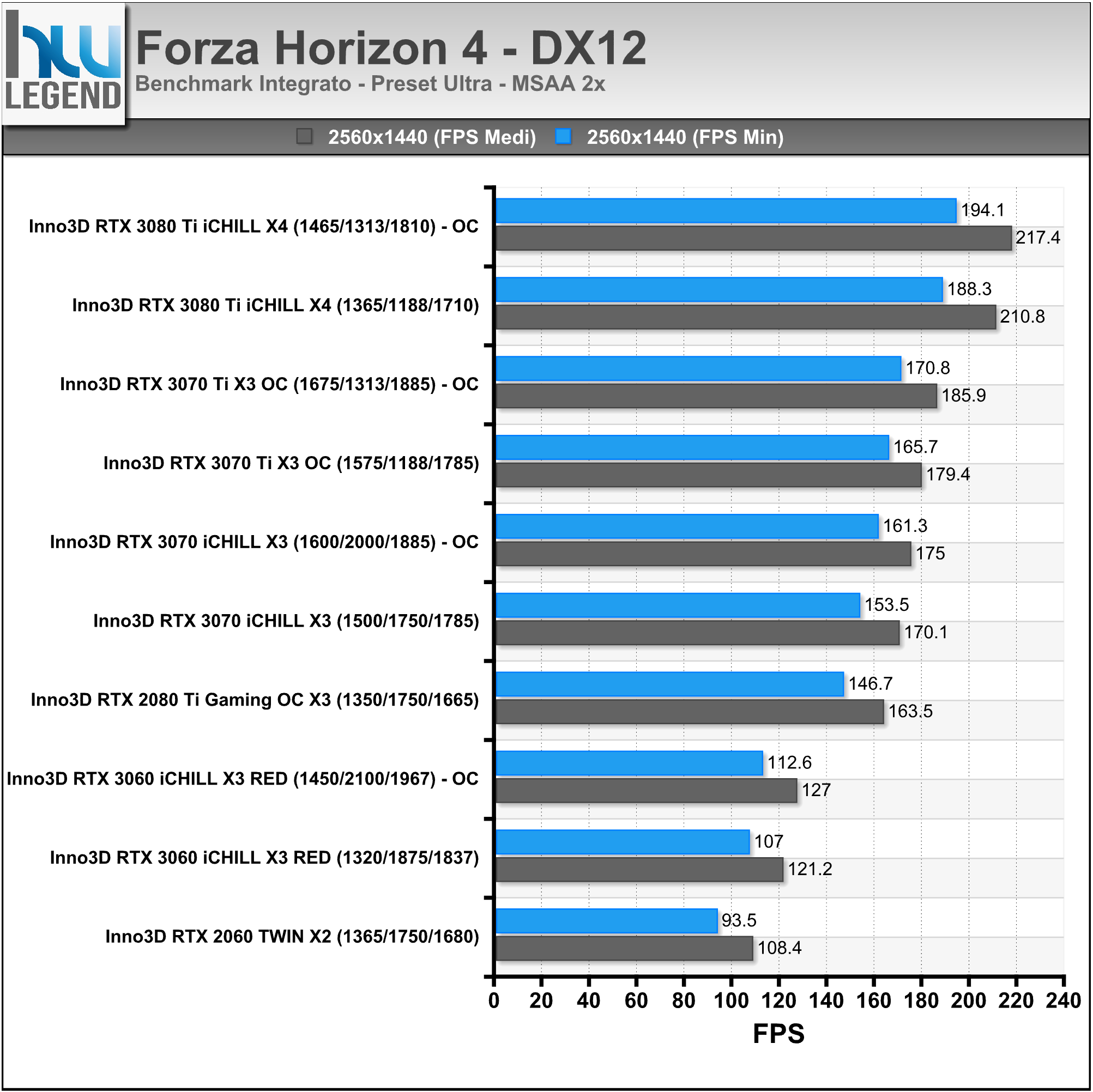
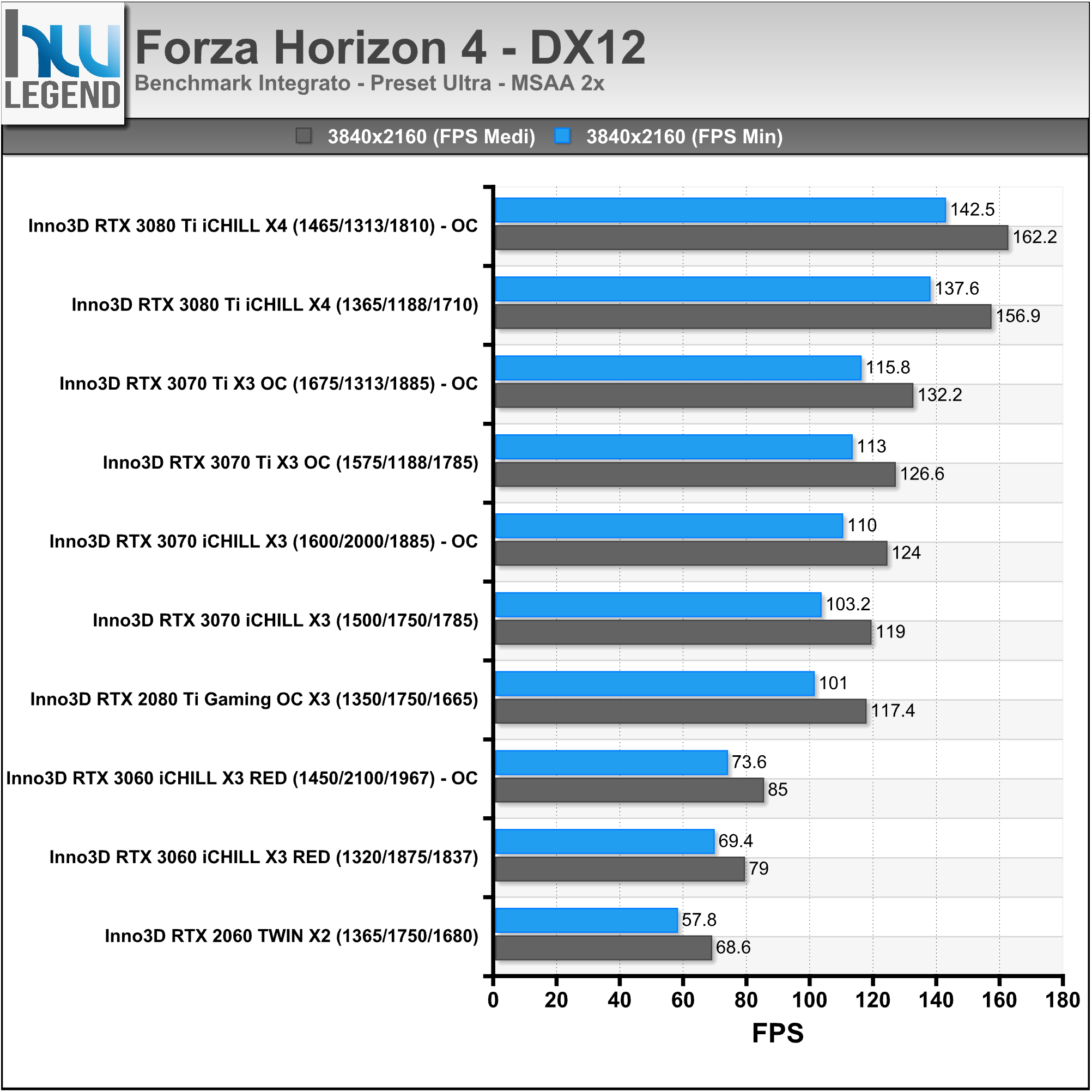
[nextpage title=”DX12: Hitman 3″]
Hitman 3 è un videogioco d’azione stealth, ottavo episodio della serie Hitman e seguito del videogioco omonimo. Il gioco è stato sviluppato da IO Interactive e pubblicato da Warner Bros. Interactive Entertainment per PC, PlayStation 4 e Xbox One nel mese di gennaio 2021.
Il gioco è in terza persona e permette al giocatore di controllare l’Agente 47, un sicario professionista che viaggia in vari luoghi per completare le sue missioni.

I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:
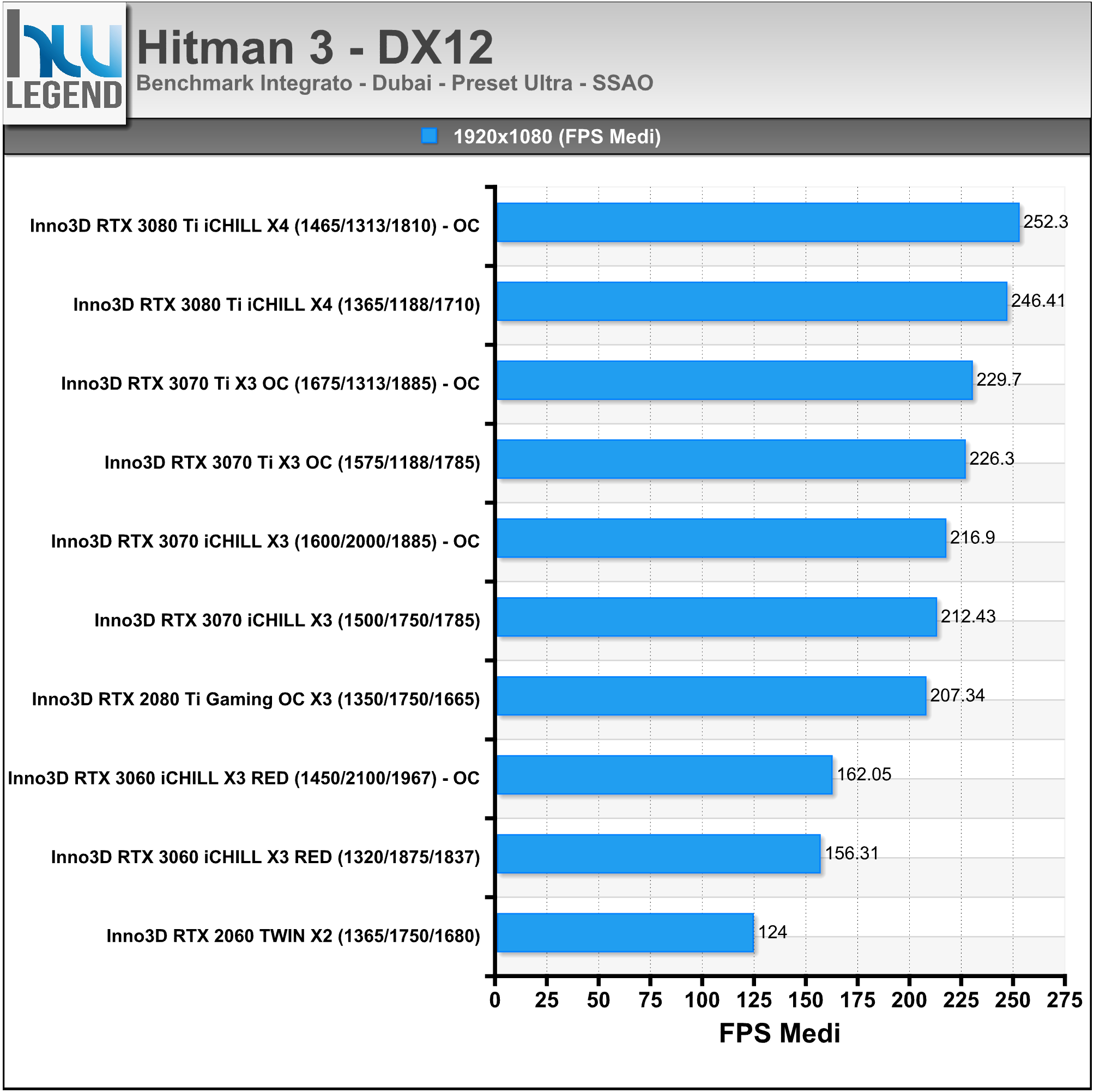
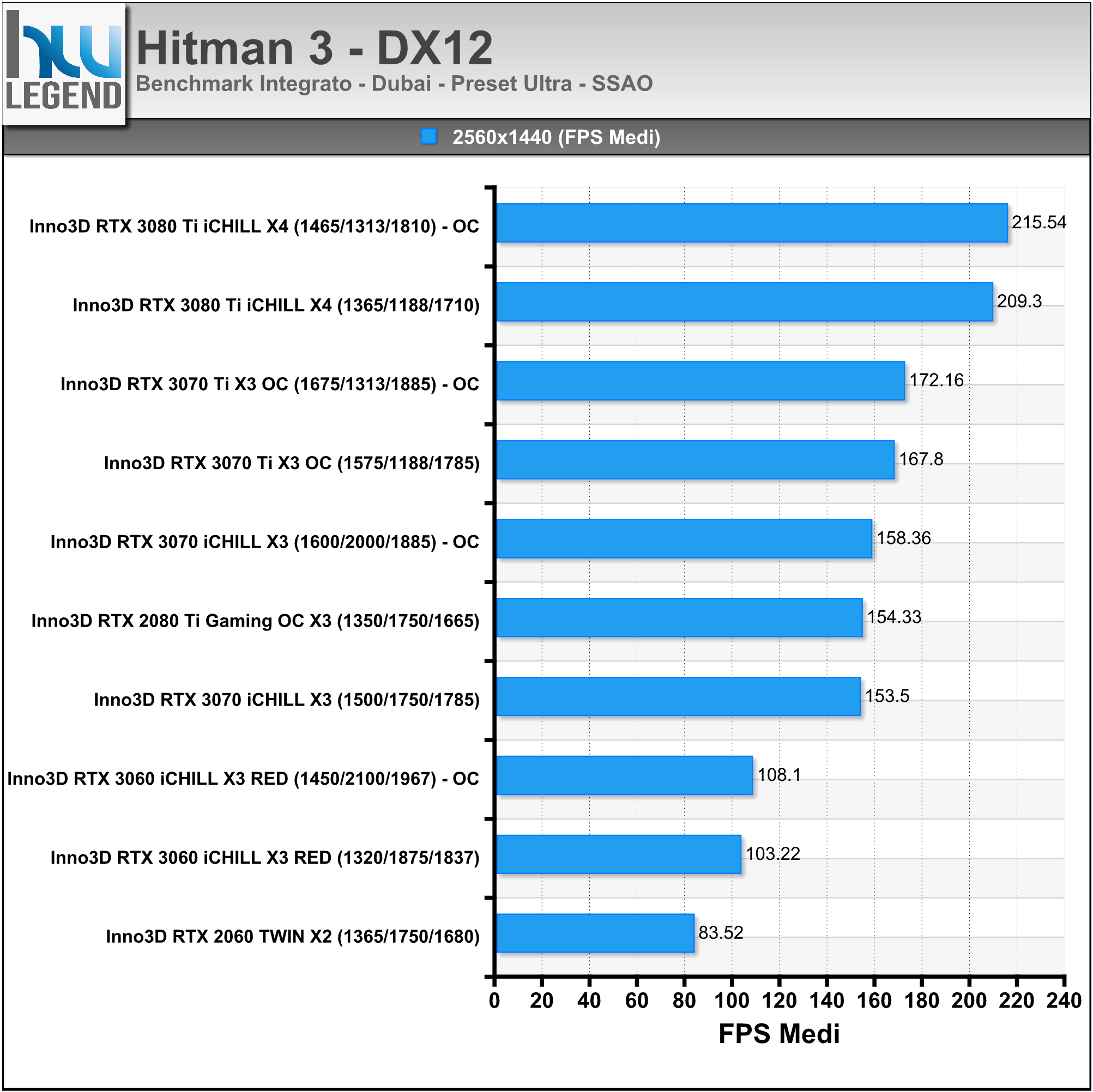
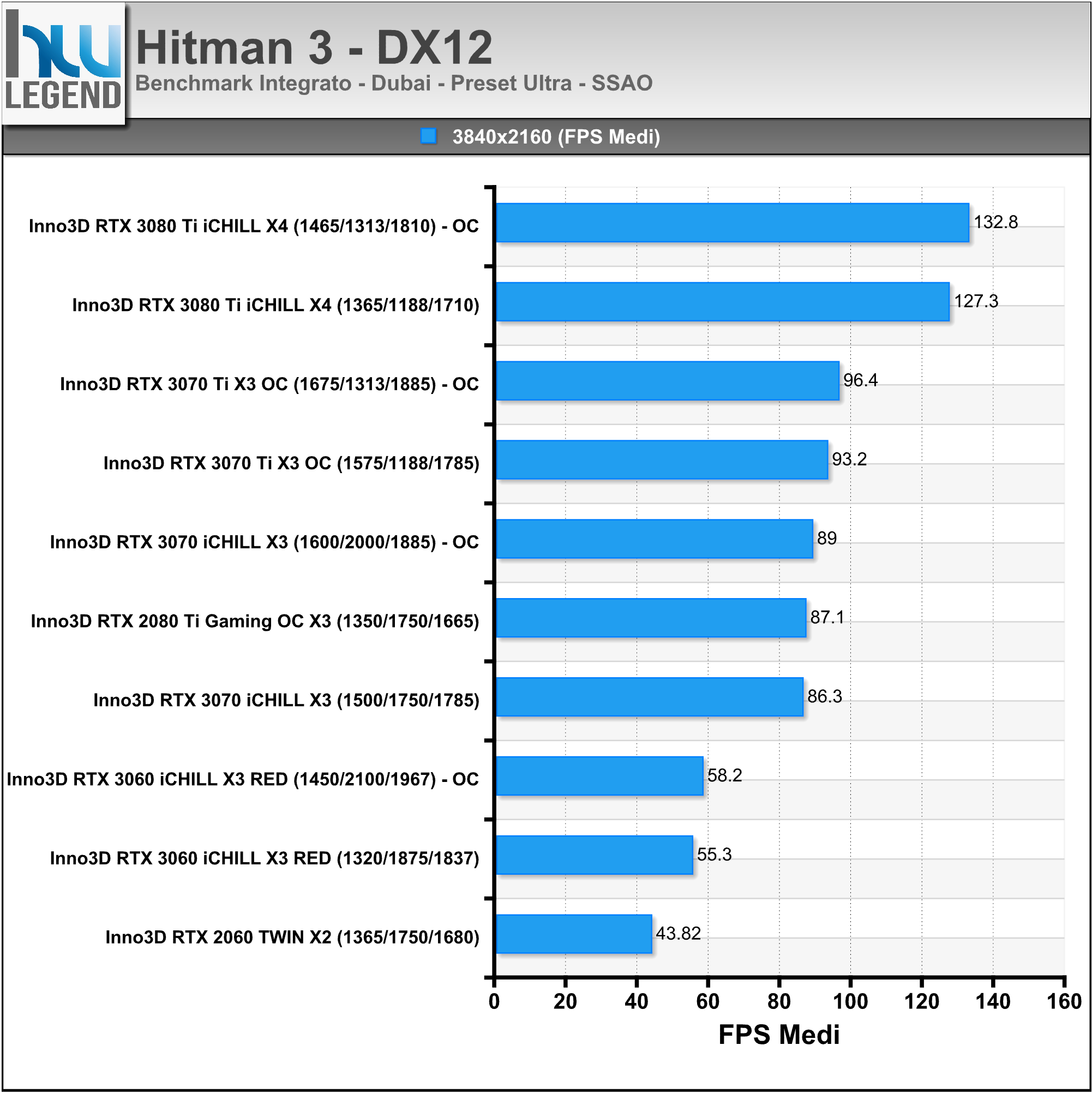
[nextpage title=”DX12: Horizon Zero Dawn”]
Horizon: Zero Dawn è un videogioco action RPG open world, a sfondo post-apocalittico, sviluppato da Guerrilla Games e pubblicato da Sony Interactive Entertainment per PlayStation 4 nel 2017 e successivamente per Microsoft Windows nell’estate 2020.
La storia segue le avventure di Aloy, una cacciatrice che vive all’interno di un mondo post-apocalittico dominato da robot ostili (le “Macchine”), dove gli esseri umani sono riuniti in fazioni tribali. Avendo vissuto fin da bambina emarginata dalla sua stessa tribù, Aloy decide di scoprirne il motivo e di cercare delle risposte sul suo passato e sulla calamità che ha colpito l’umanità.

Il gioco mette a disposizione un open world esplorabile liberamente, con un gran numero di missioni principali e secondarie da completare. Il giocatore può combattere le Macchine con lance, armi da lancio e tattiche stealth, avendo poi la possibilità di saccheggiare i resti dei nemici dopo averli sconfitti per ottenere utili risorse. I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:
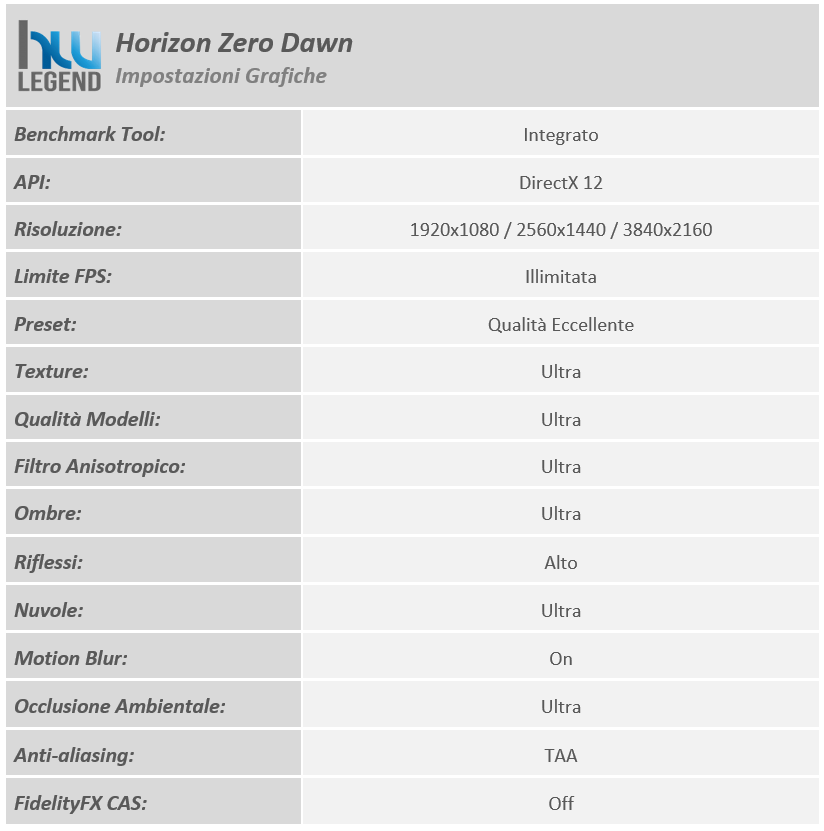
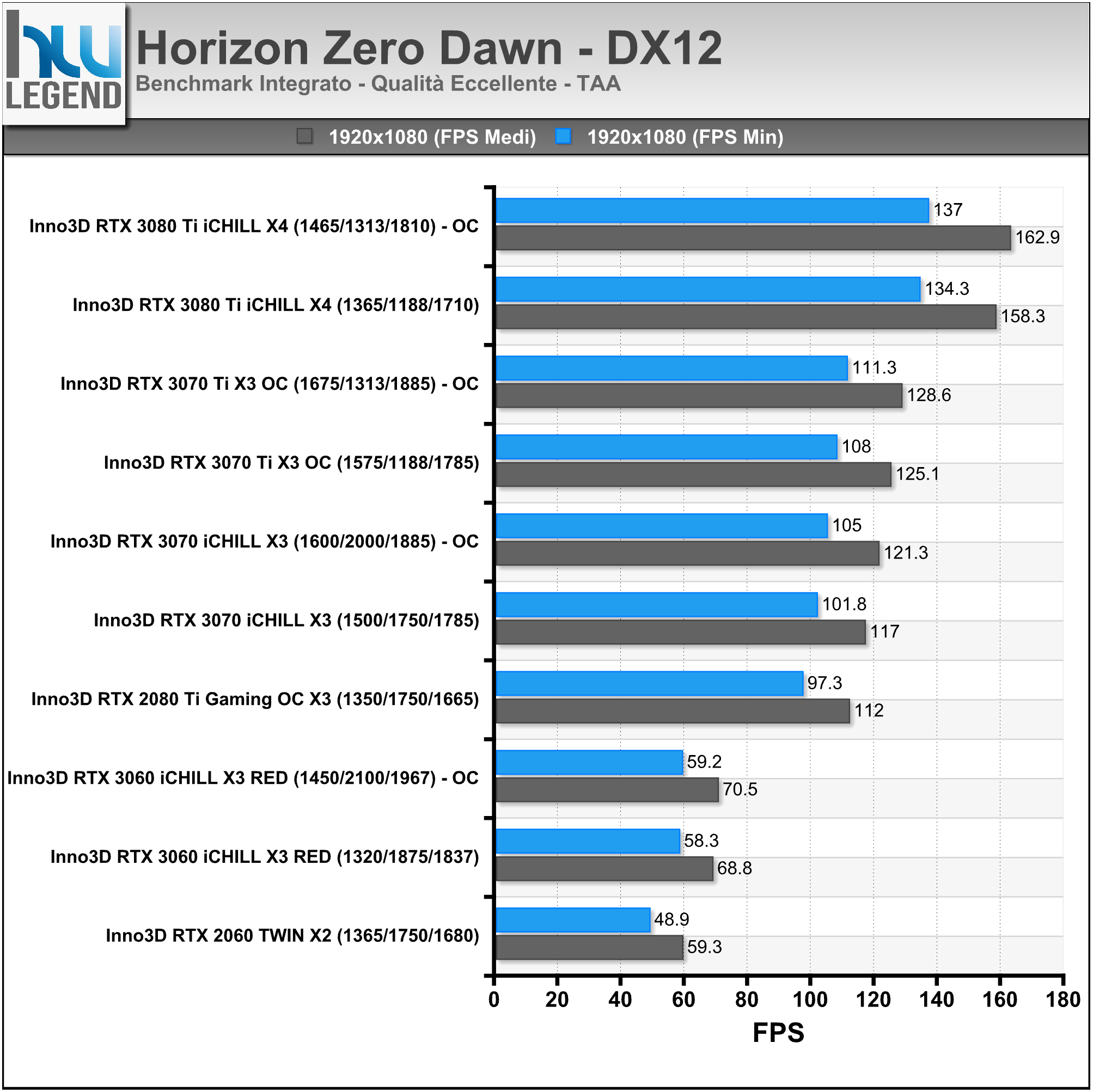
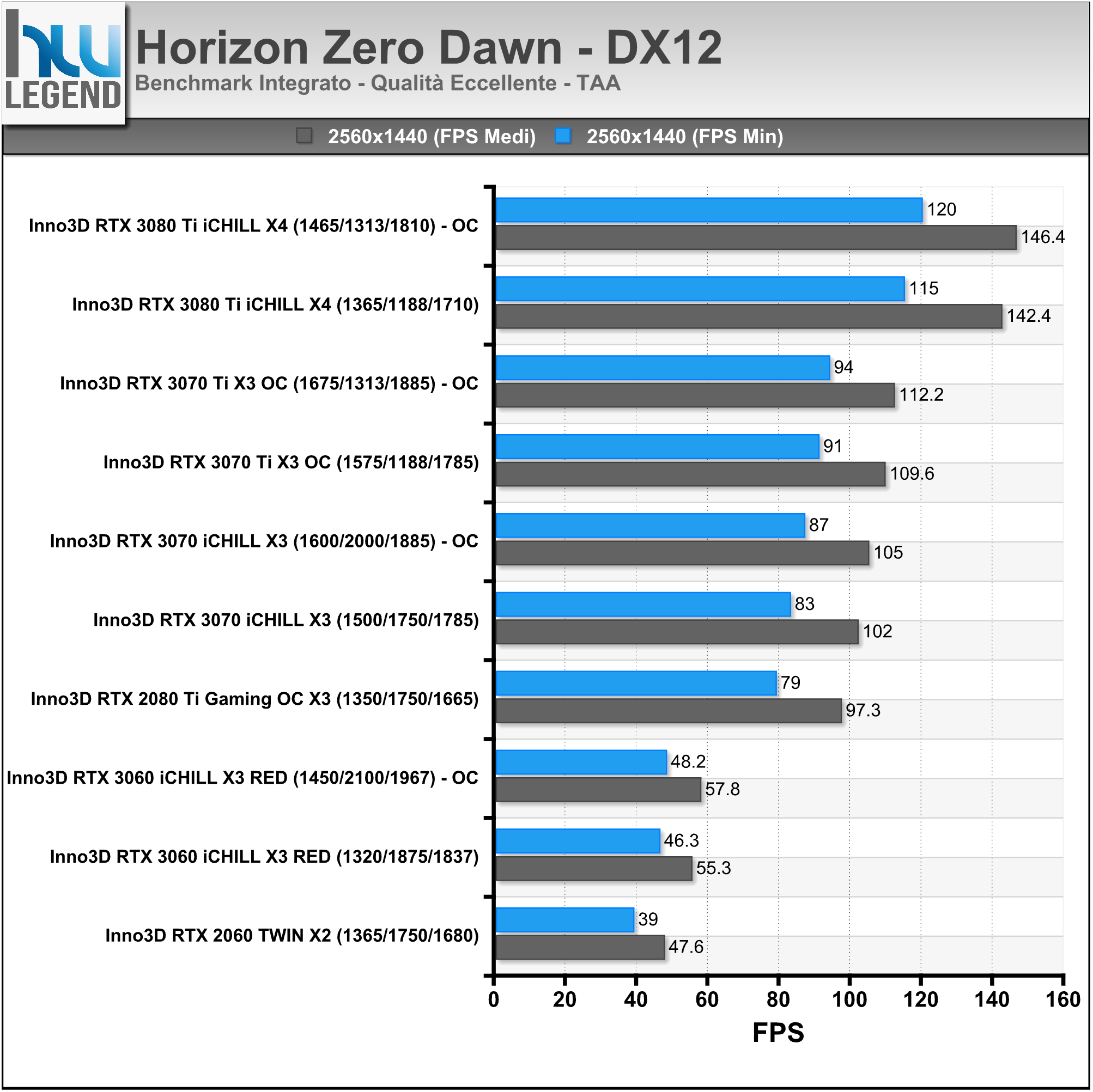
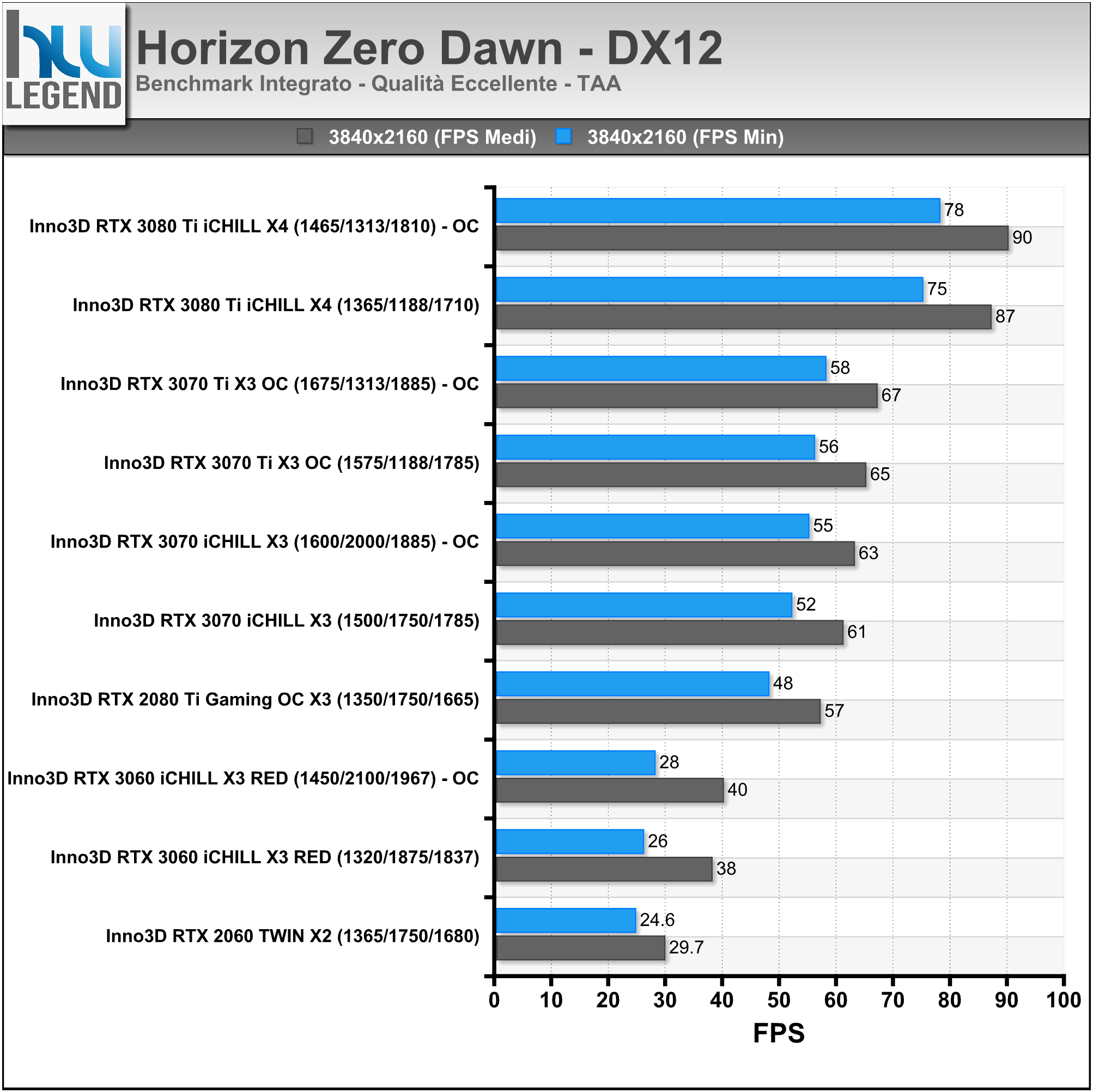
[nextpage title=”DX12: Gears 5″]
Gears 5 è un videogioco sparatutto in terza persona sviluppato da The Coalition e pubblicato da Microsoft Game Studios per Microsoft Windows e Xbox One.
È il secondo capitolo della nuova trilogia di Gears of War annunciato durante l’E3 2018 di Los Angeles previsto provvisoriamente per un generico 2019.

La storia prosegue quella del precedente capitolo e si focalizzerà su Kait Diaz, una COG che si ritrova a dover disubbidire a degli ordini diretti per cercare di bloccare la minaccia e scoprire il mistero che lega i suoi incubi allo Sciame. I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:
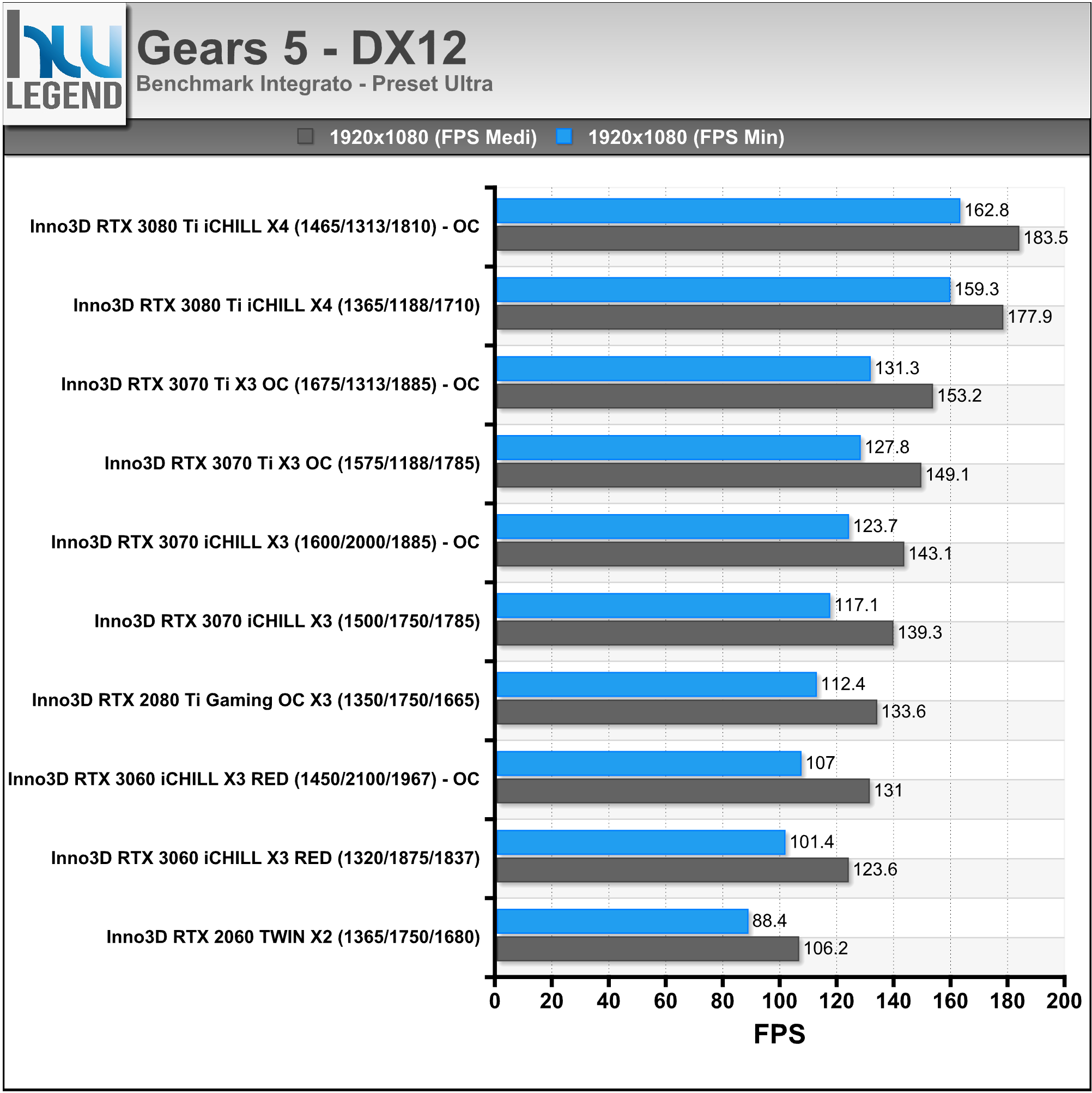
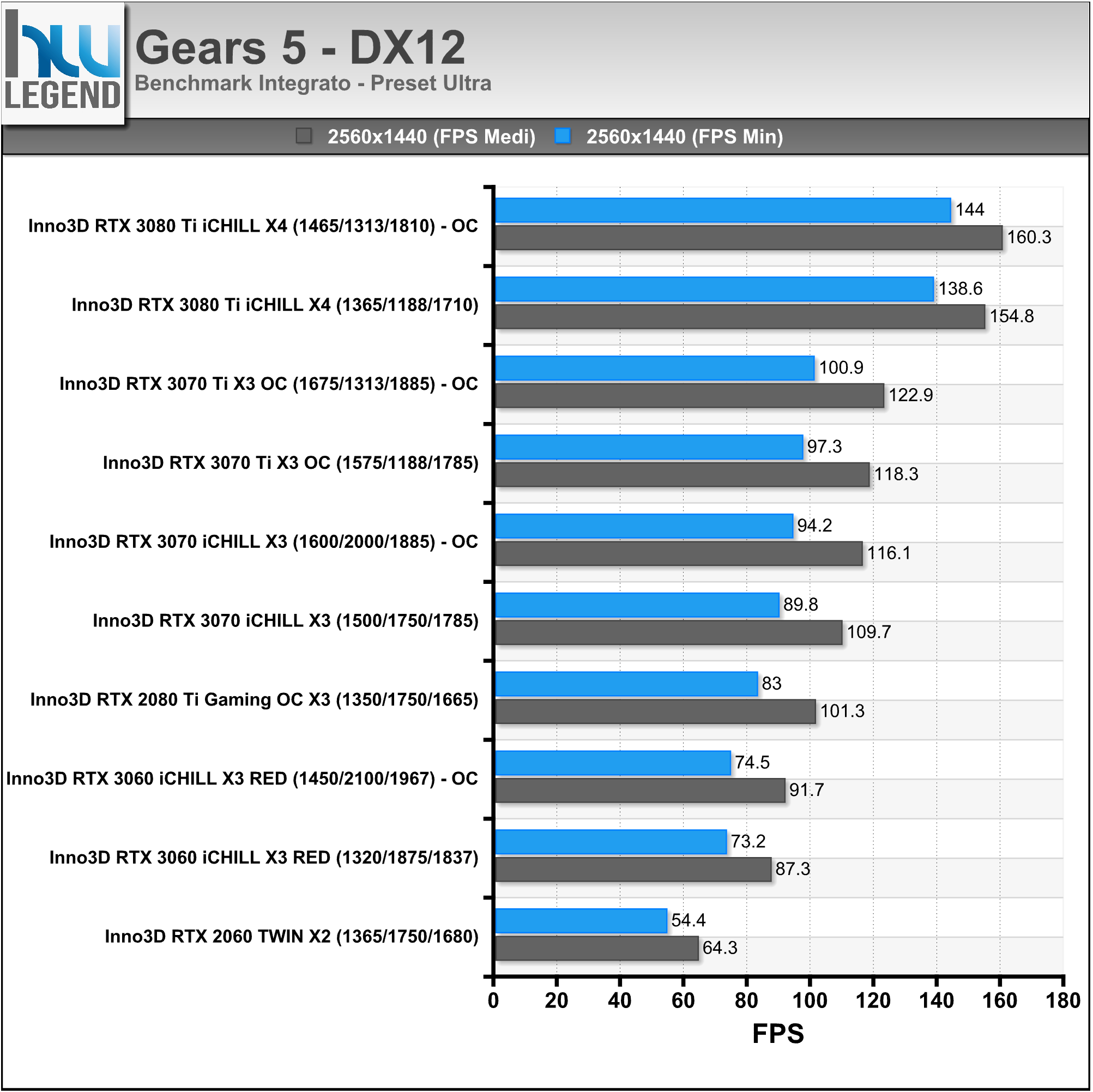
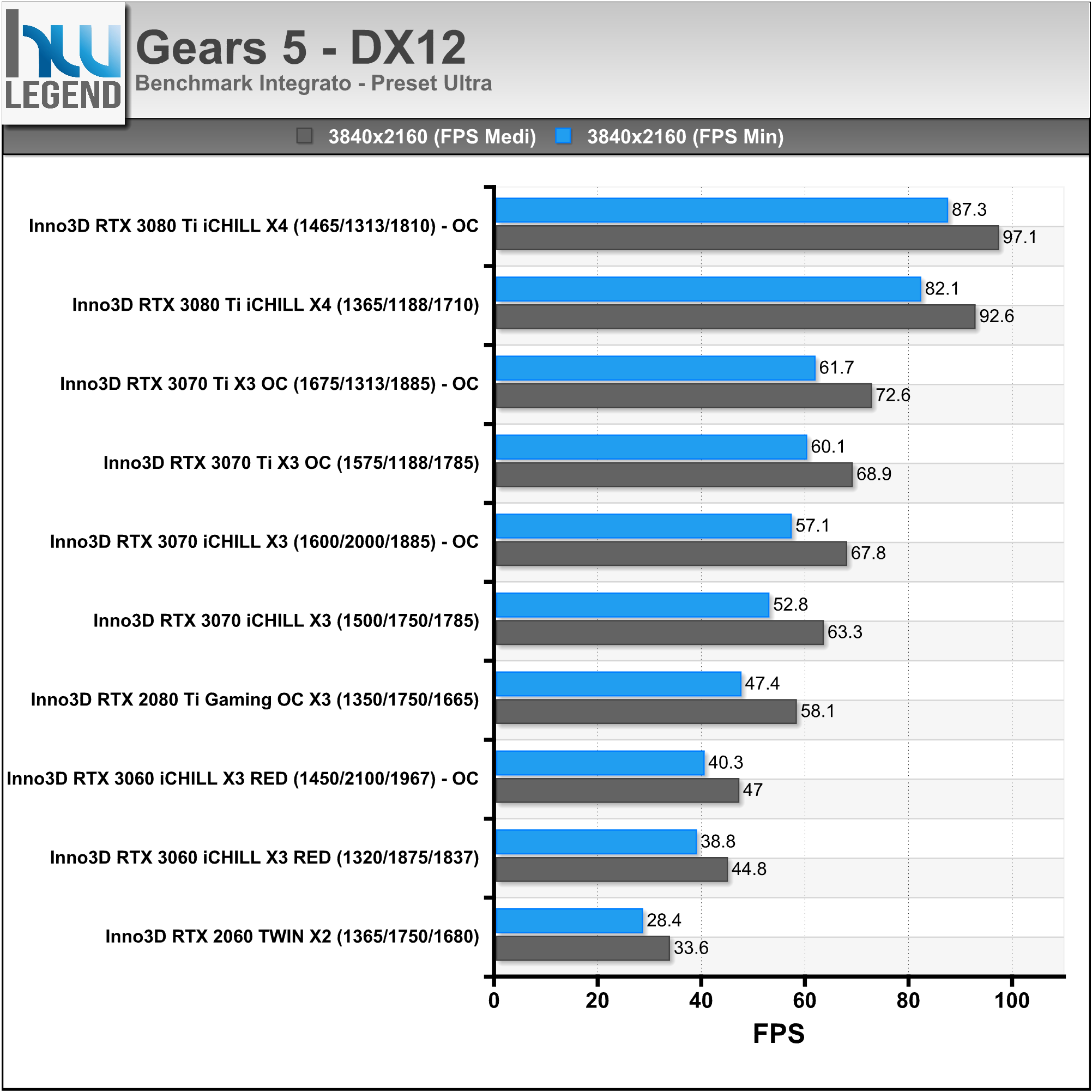
[nextpage title=”Vulkan: Red Dead Redemption 2″]
Red Dead Redemption 2 è un videogioco action-adventure del 2018, sviluppato e pubblicato da Rockstar Games per Xbox One, PlayStation 4, Microsoft Windows e Google Stadia. Si tratta del prequel di Red Dead Redemption (2010) ed è il terzo capitolo della saga di videogiochi Red Dead, cominciata nel 2004 con Red Dead Revolver.
Il titolo è considerato dalla critica e dall’utenza come un capolavoro della storia videoludica. Il gioco ha ricevuto oltre 175 premi nella categoria Game of the Year. È, al 12 aprile 2020, con una votazione di 97 su 100, il videogioco più acclamato per Xbox One e PlayStation 4. Il 5 novembre 2019 è stata pubblicata la versione PC che insieme alla versione per Xbox One X e Google Stadia sono gli unici in grado a poter eseguire il gioco in 4K nativi.

RDR2 è un gioco d’avventura e azione in prima e terza persona ambientato in un open world a tema western. Il giocatore impersona Arthur Morgan, un fuorilegge appartenente alla banda Van der Linde. Come i suoi compagni il protagonista dovrà provvedere al sostentamento del gruppo, contribuendo alle provvigioni dell’accampamento e alle casse della banda. I test sono stati condotti con il benchmark integrato sfruttando le API Vulkan, usando i seguenti settaggi:
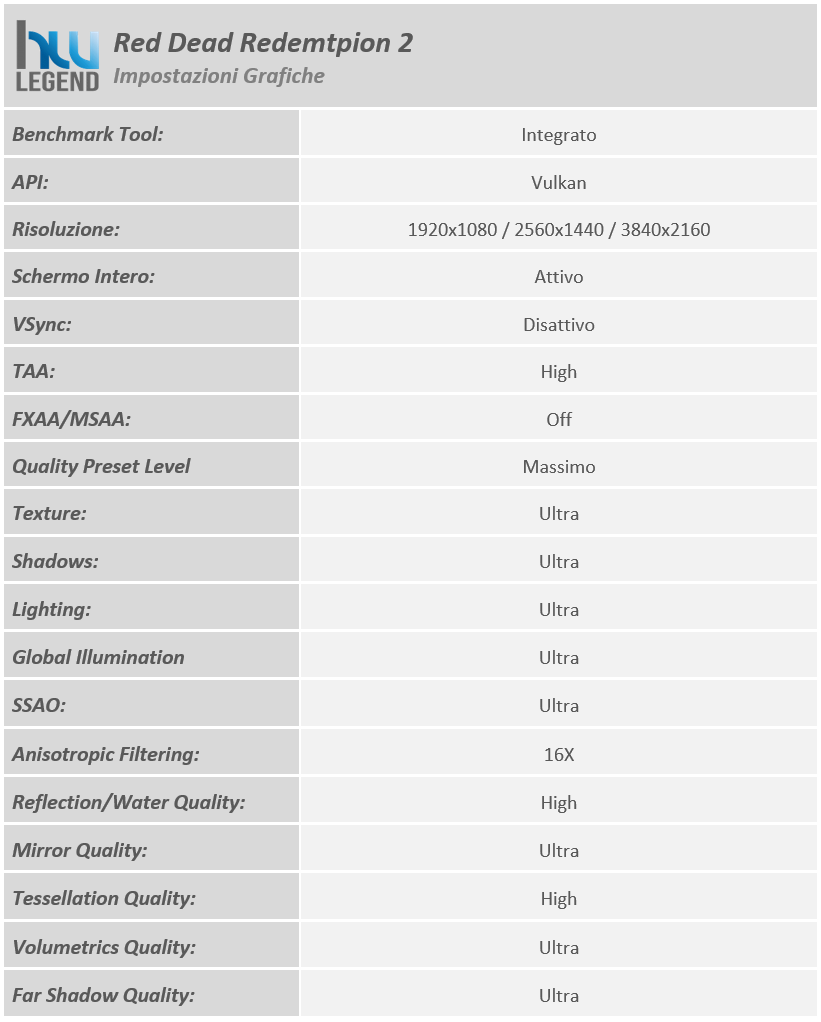
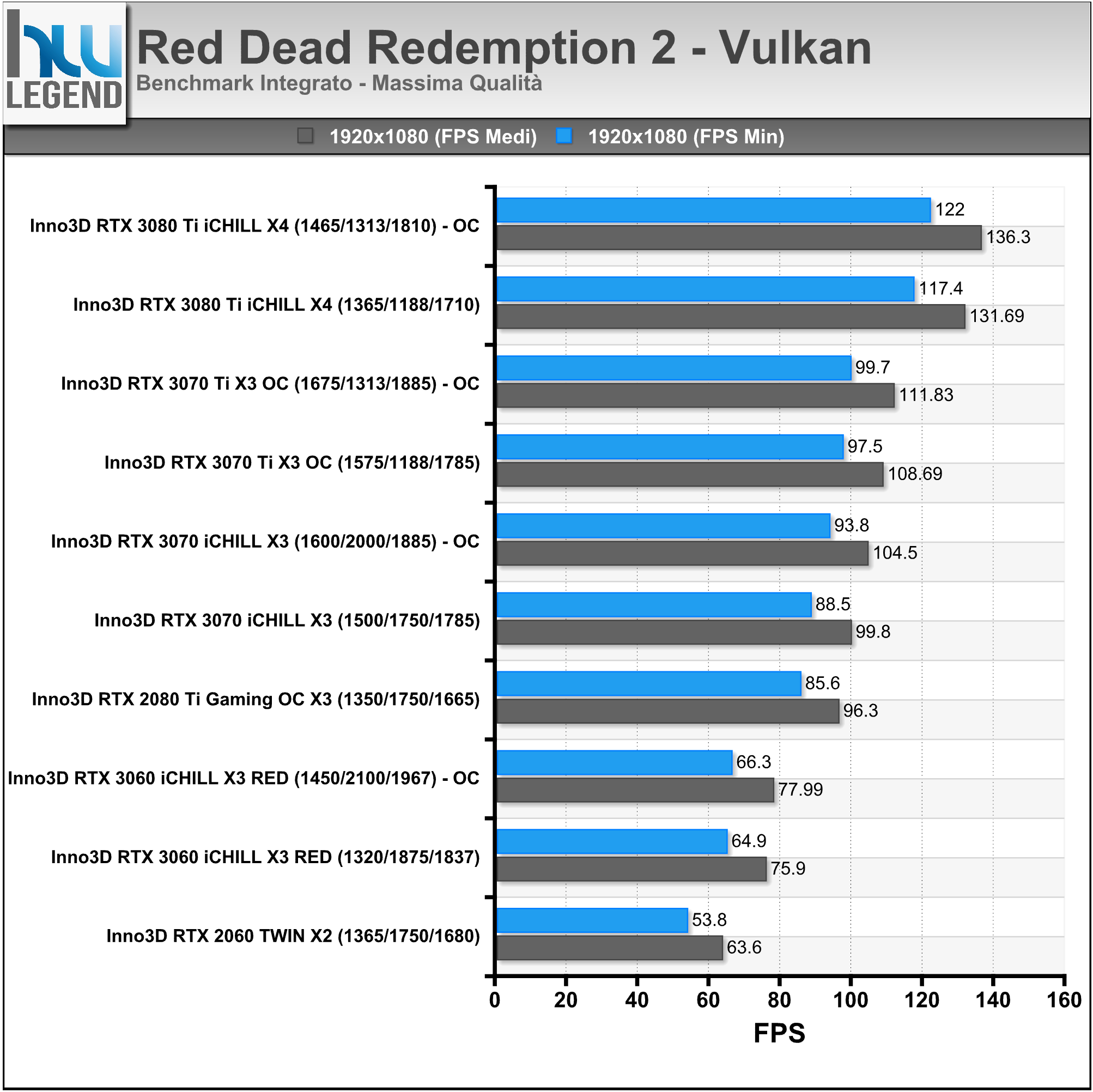
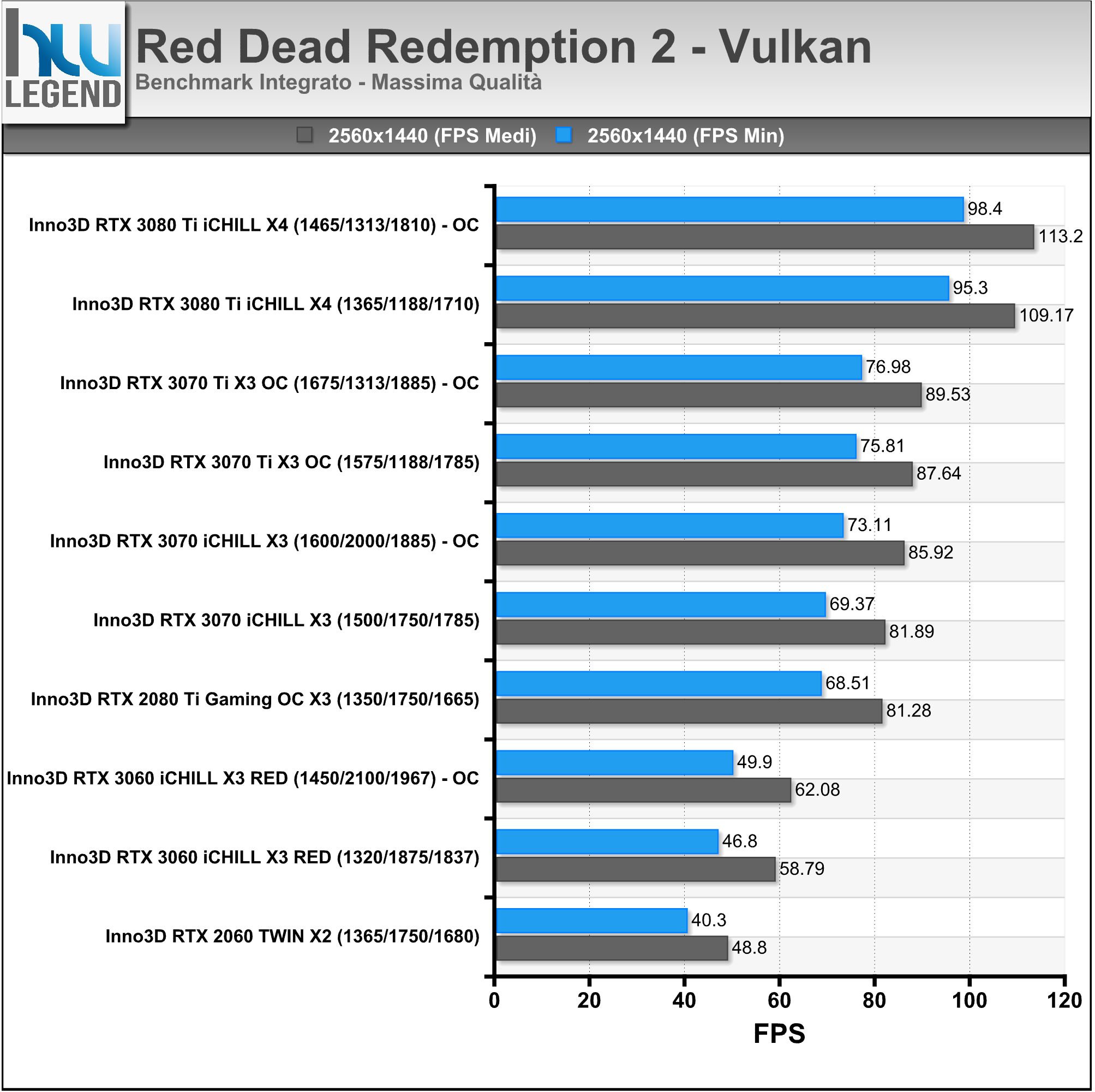
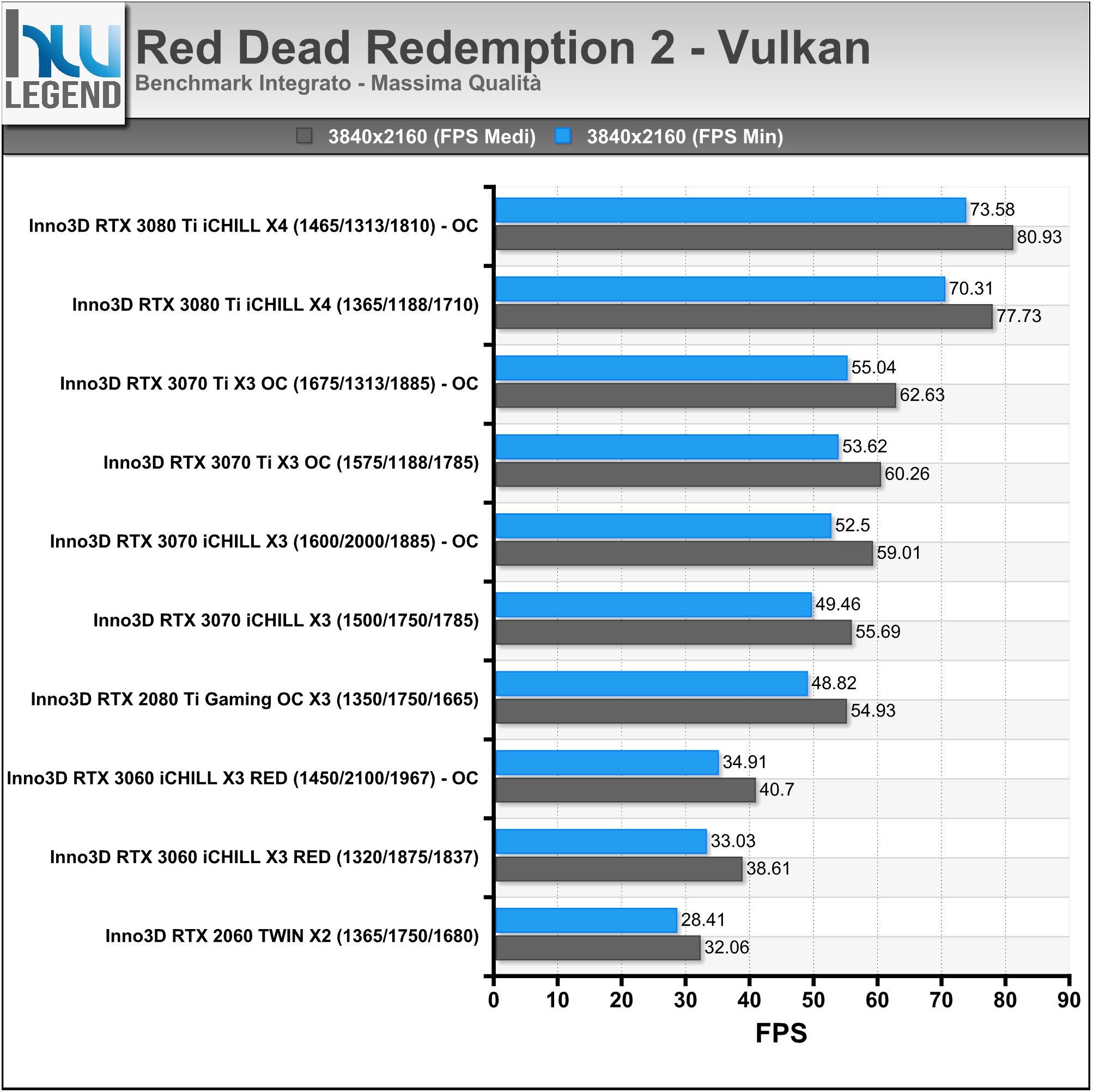
[nextpage title=”Vulkan: Strange Brigade”]
Strange Brigade è uno sparatutto cooperativo in terza persona sviluppato e pubblicato dalla Rebellion Developments nell’agosto 2018 per piattaforma PC, Playstation 4 e Xbox One.
Nel gioco, il giocatore assume il ruolo di un avventuriero negli anni ’30 e può collaborare con altri tre giocatori per combattere contro diversi nemici mitologici come mummie, scorpioni giganti e minotauri.

I quattro personaggi giocabili del gioco, che possono essere personalizzati, hanno diverse armi e abilità. I giocatori hanno a disposizione un grande arsenale di armi, ognuna con diversi slot di aggiornamento, che possono essere utilizzati per migliorarne l’efficienza. Sono previsti diversi livelli complessi e ricchi di puzzle ed enigmi da risolvere al fine di scoprire nuove reliquie e sbloccare numerose tipologie di “poteri”. I test sono stati condotti con il benchmark integrato sfruttando le API Vulkan, usando i seguenti settaggi:
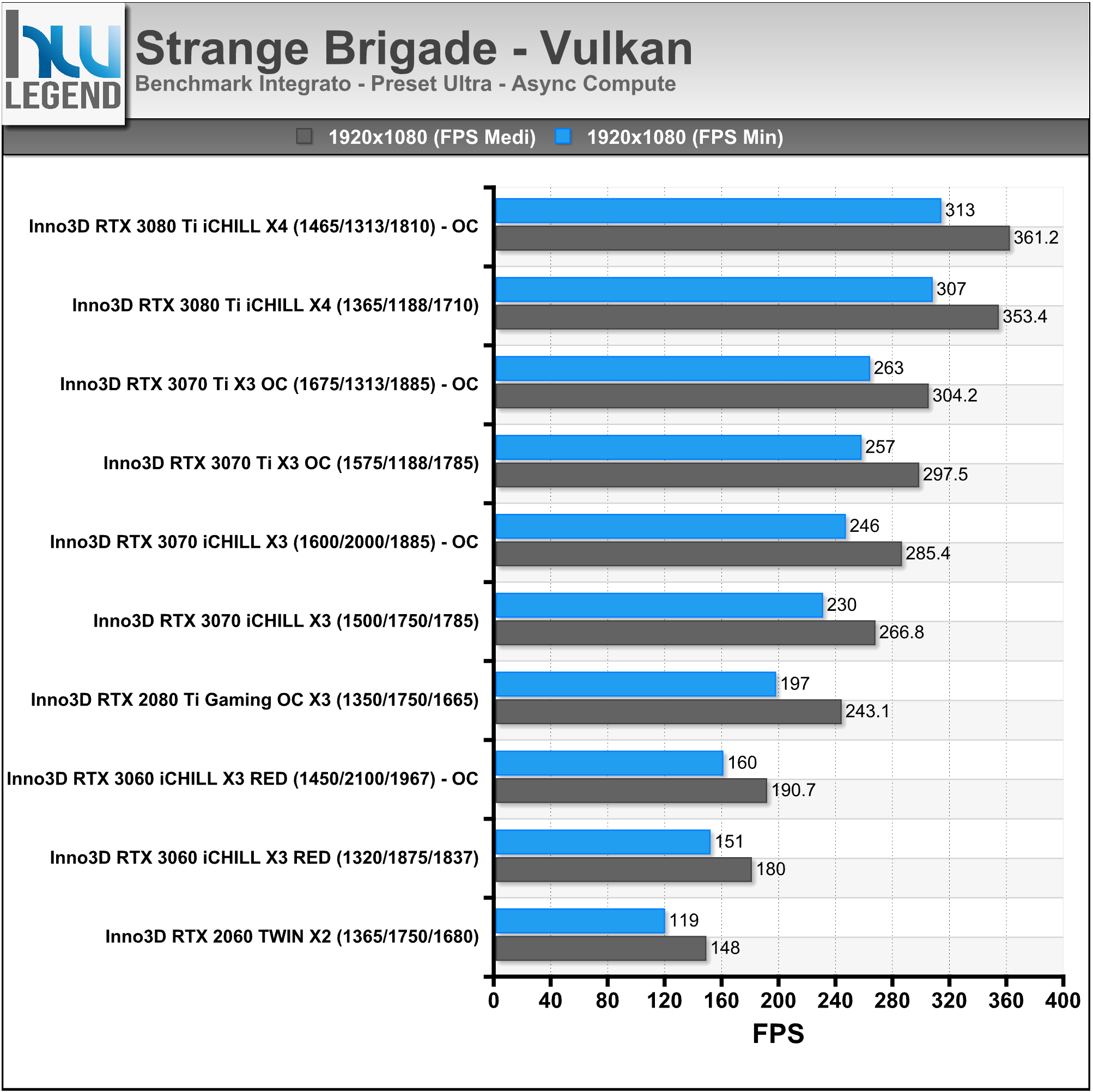
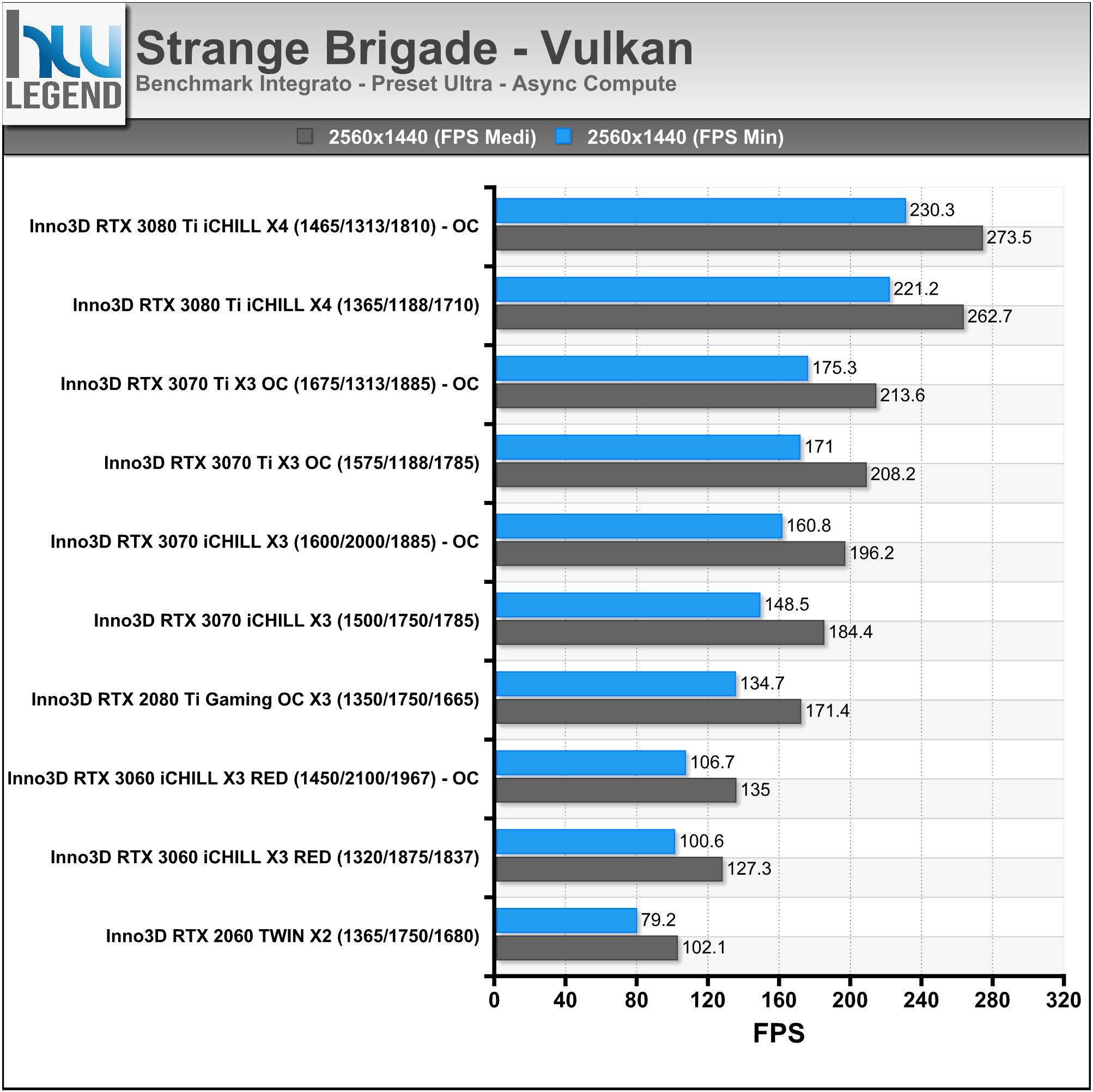
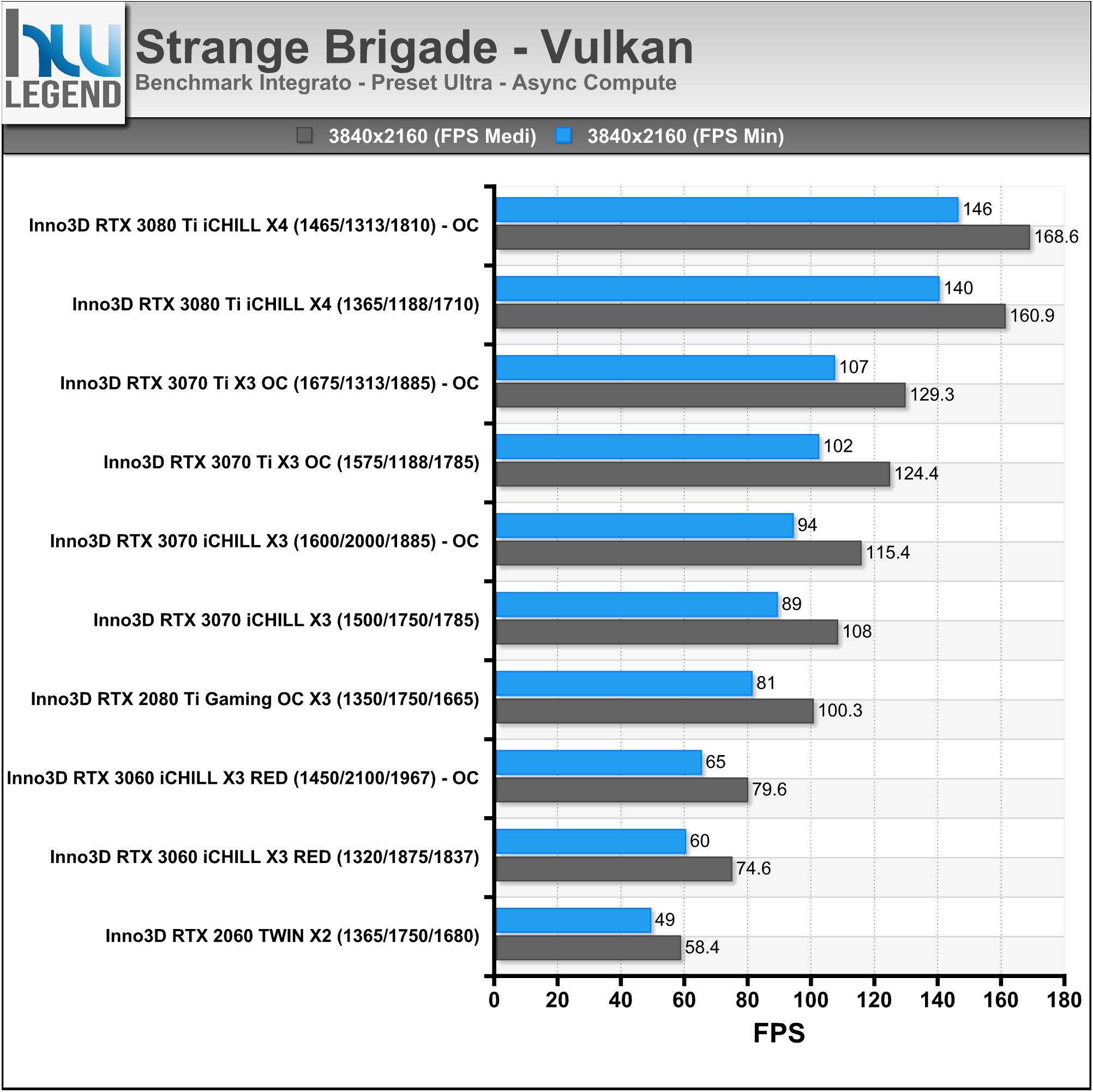
[nextpage title=”Vulkan: Wolfenstein YoungBlood”]
Wolfenstein: Youngblood è uno sparatutto in prima persona di genere fantastorico-horror sviluppato da MachineGames e pubblicato da Bethesda Softworks nel luglio 2019.
Vent’anni dopo Wolfenstein II: The New Colossus, l’America e gran parte del mondo sono liberati dal controllo nazista e William “B.J.” Blazkowicz e sua moglie Anya sono in grado di crescere in tranquillità le loro gemelle, Jessica e Sophia, ed insegnare loro le basi dell’autodifesa.

Ad ogni modo, nel 1980, Blazkowicz misteriosamente scompare senza lasciare alcuna traccia di sé. Jessica, Sophia e la loro amica Abby, figlia di Grace Walker, scoprono una stanza segreta nell’attico con una mappa che indica che Blazkowicz si è portato nel territorio dei nazisti sino a raggiungere Neu-Paris per incontrare i membri della resistenza francese. Credendo che le autorità americane non seguiranno Blazkowicz nella Francia nazista, le ragazze rubano un elicottero dell’FBI e un paio di armature potenziate e si portano in Francia a cercare il padre. I test sono stati condotti usando i seguenti settaggi:
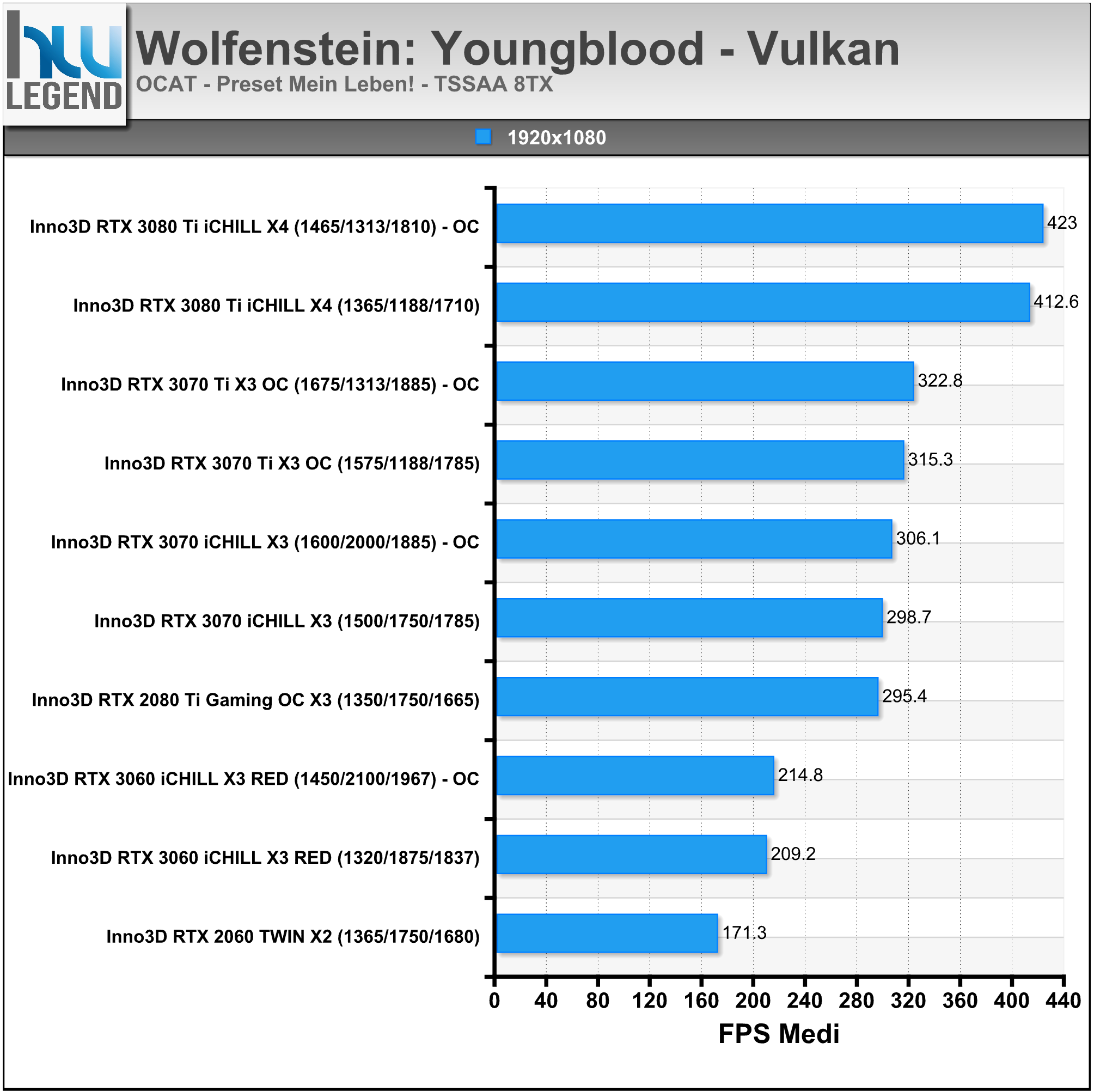
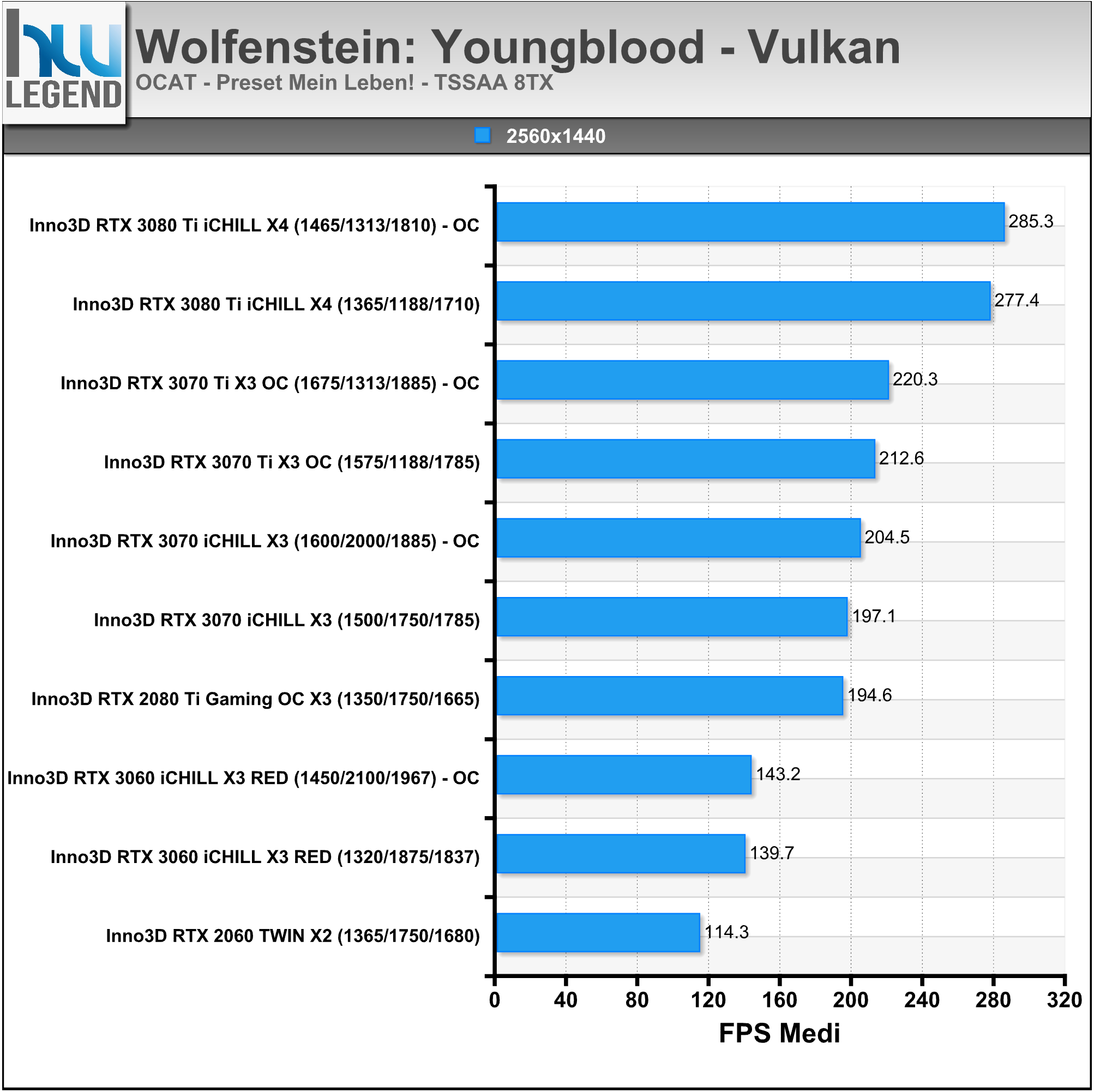
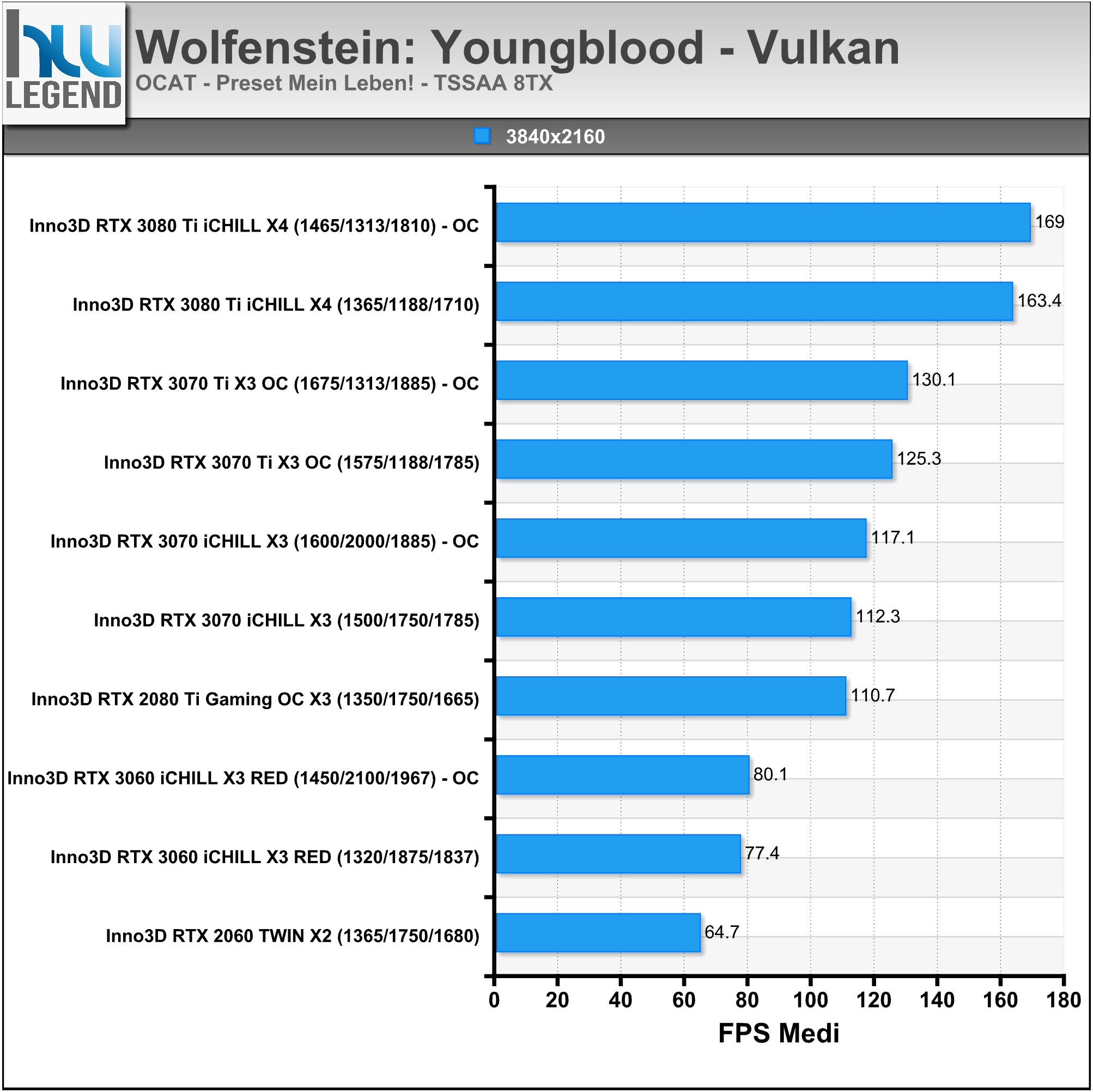
NOTA: Per la misurazione degli FPS abbiamo utilizzato l’ultima versione disponibile del software OCAT, liberamente scaricabile a questo indirizzo e capace di registrare correttamente il framerate indipendentemente dalle API in uso.
[nextpage title=”DX11: Far Cry New Dawn”]
Far Cry New Dawn è uno sparatutto in prima persona sviluppato da Ubisoft Montreal e pubblicato da Ubisoft per PC, PlayStation 4 e Xbox One nel mese di febbraio del 2019.
Il gioco nasce come spin-off del precedente ed apprezzato Far Cry 5, dal quale ne condivide l’ambientazione. Il giocatore si ritroverà infatti nella cittadina immaginaria di Hope County, in Montana, 17 anni dopo una catastrofe nucleare che ha distrutto buona parte della civiltà, a combattere per la sopravvivenza in mezzo a ciò che resta della popolazione, ormai divisa in fazioni rivali.

I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:
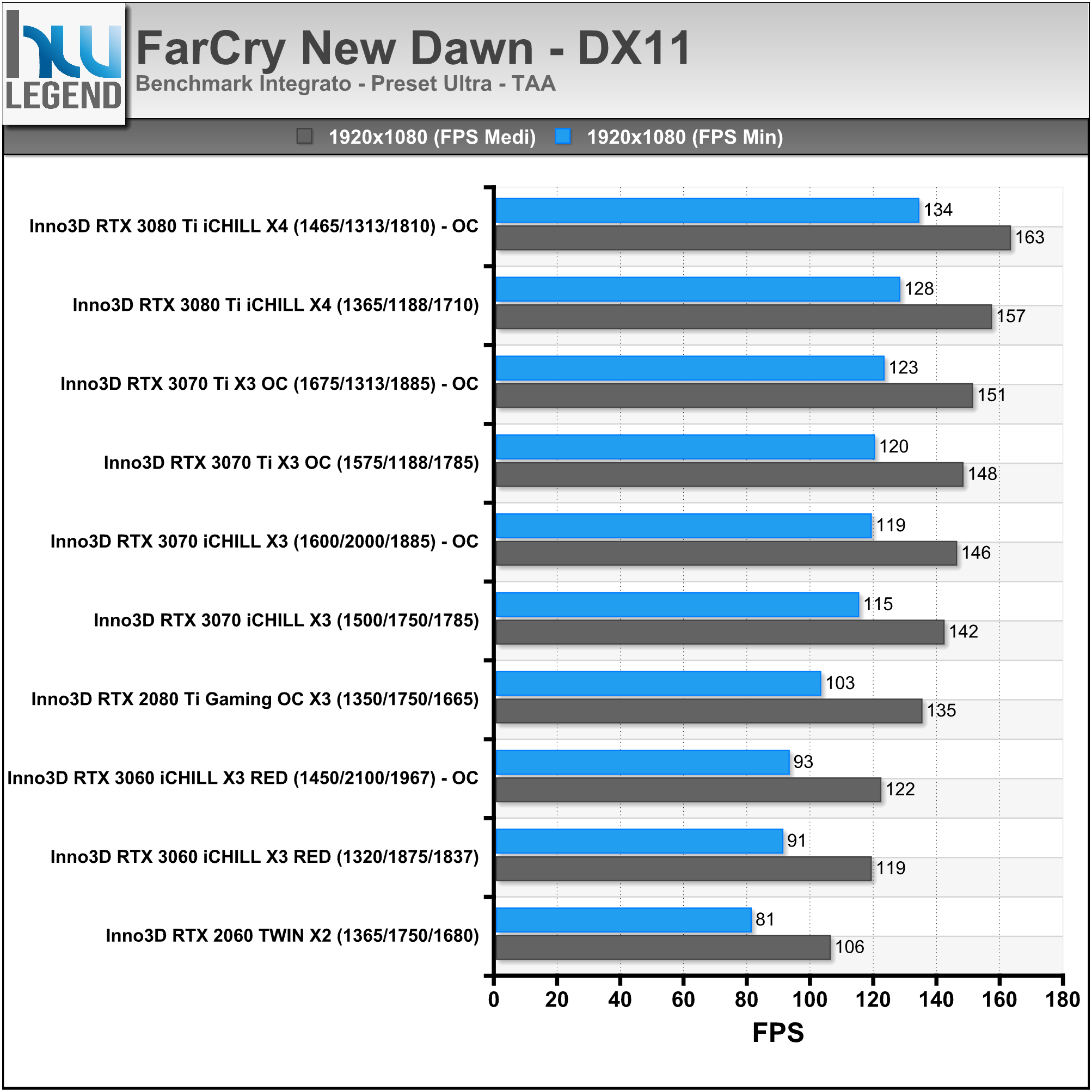
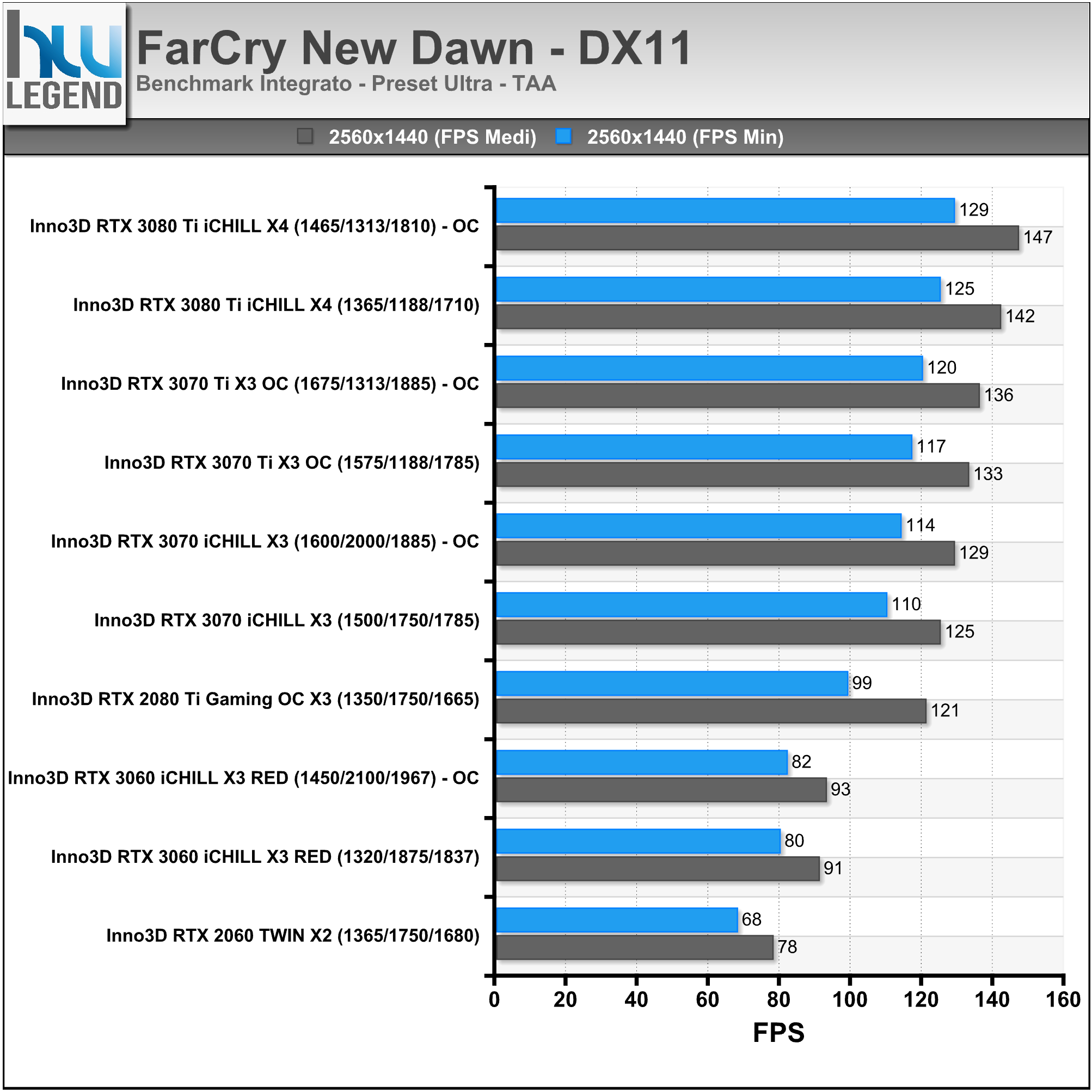
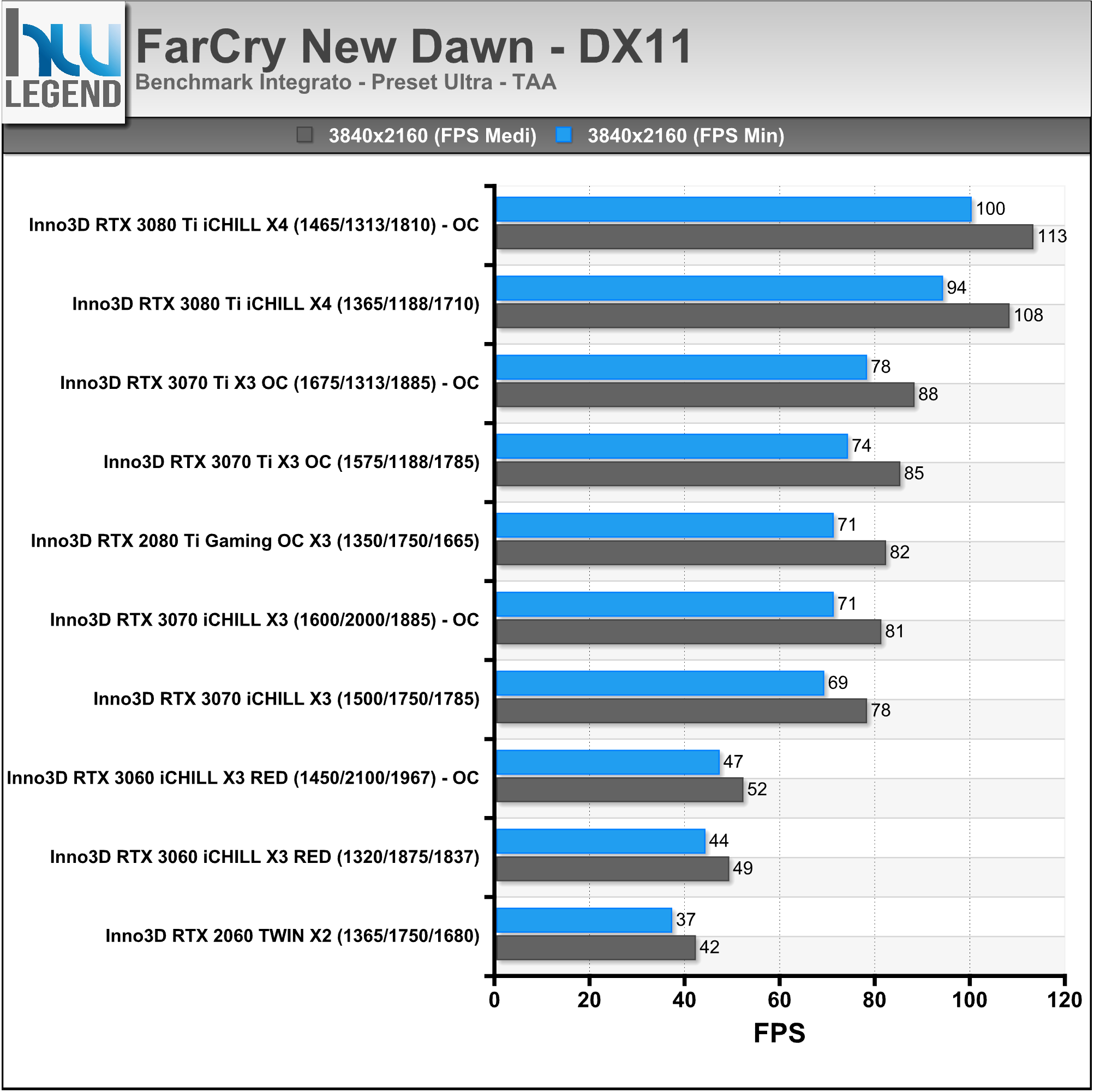
[nextpage title=”DX11: Immortals Fenyx Rising”]
Immortals Fenyx Rising è un videogioco d’azione-avventura del 2020 sviluppato da Ubisoft Quebec e pubblicato da Ubisoft. Il gioco è stato distribuito per Google Stadia, Xbox One, Xbox Series X, PlayStation 4, PlayStation 5, Microsoft Windows e Nintendo Switch a partire dal 3 dicembre 2020.
Il protagonista del gioco è Fenyx, un personaggio giocante completamente personalizzabile nell’aspetto. Il gioco è ambientato in un open world estremamente ampio, costituito da sette regioni ben distinte ispirate dalla mitologia greca.

Fenyx dovrà salvare gli dei greci dal temibile titano Tifone, che cerca vendetta dopo che è stato rinchiuso da Zeus nel Tartaro. Il gioco assume un tono ironico, con Prometeo che diventa il narratore principale del gioco mentre Zeus quello del narratore inaffidabile. I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:
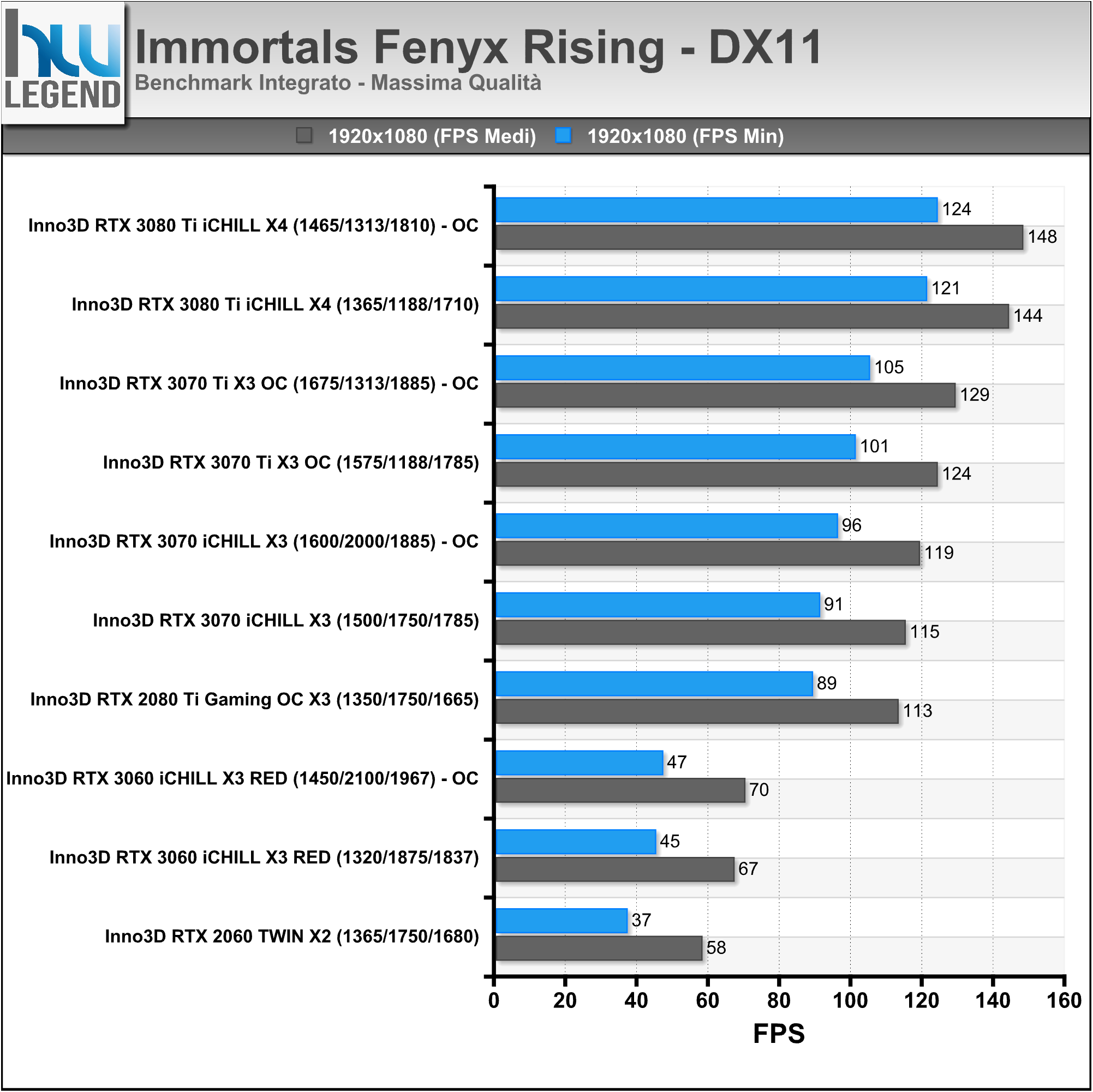
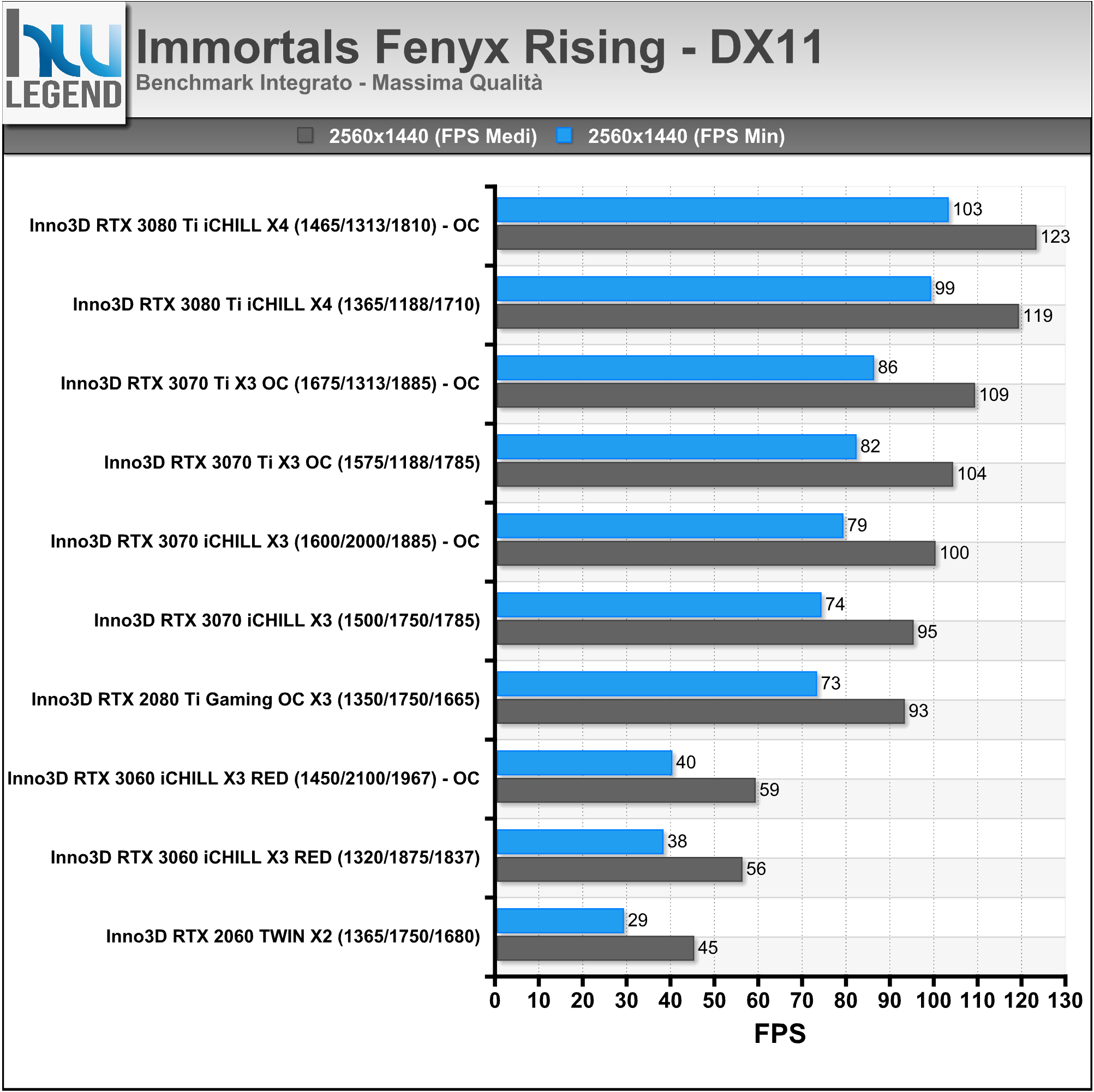
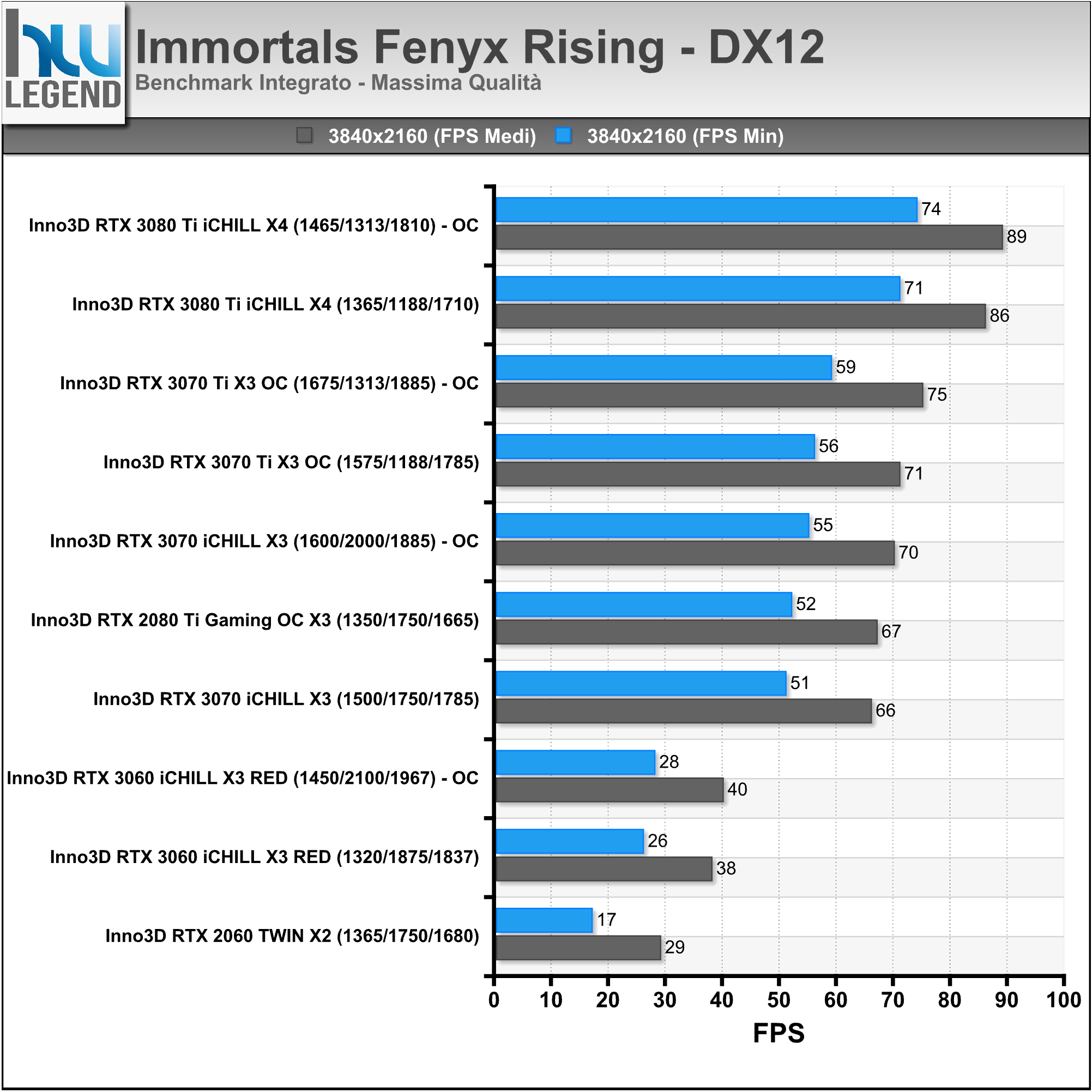
[nextpage title=”DX11: Middle-Earth Shadow of War”]
Middle-Earth: Shadow of War è un’action RPG, sequel di Middle-Earth: Shadow of Mordor, sviluppato da Monolith Productions e pubblicato da Warner Bros. Interactive Entertainment.
Il gioco è stato pubblicato per PC, PlayStation 4 e Xbox One il 10 ottobre 2017 e continua la narrazione del gioco precedente, basata sul legendarium di J. R. R. Tolkien e impostata tra gli eventi de Lo Hobbit e Il Signore degli Anelli.

Come il suo predecessore, il gioco prende anche ispirazione dagli adattamenti cinematografici del regista Peter Jackson Lo Hobbit e Il Signore degli Anelli. Il giocatore prosegue la storia del ramingo Talion e lo spirito del Signore elfico Celebrimbor, che condivide il corpo di Talion, di come essi forgiano un nuovo Anello del Potere per creare un esercito e combattere contro Sauron.
Il gioco si basa sul “sistema Nemesis” introdotto nell’Ombra di Mordor, permettendo a Talion di guadagnare seguaci di diverse razze della Terra di Mezzo, tra cui orchi e troll e pianificare strategie complesse usando questi per completare le missioni. I test sono stati condotti con il benchmark integrato usando i seguenti settaggi:
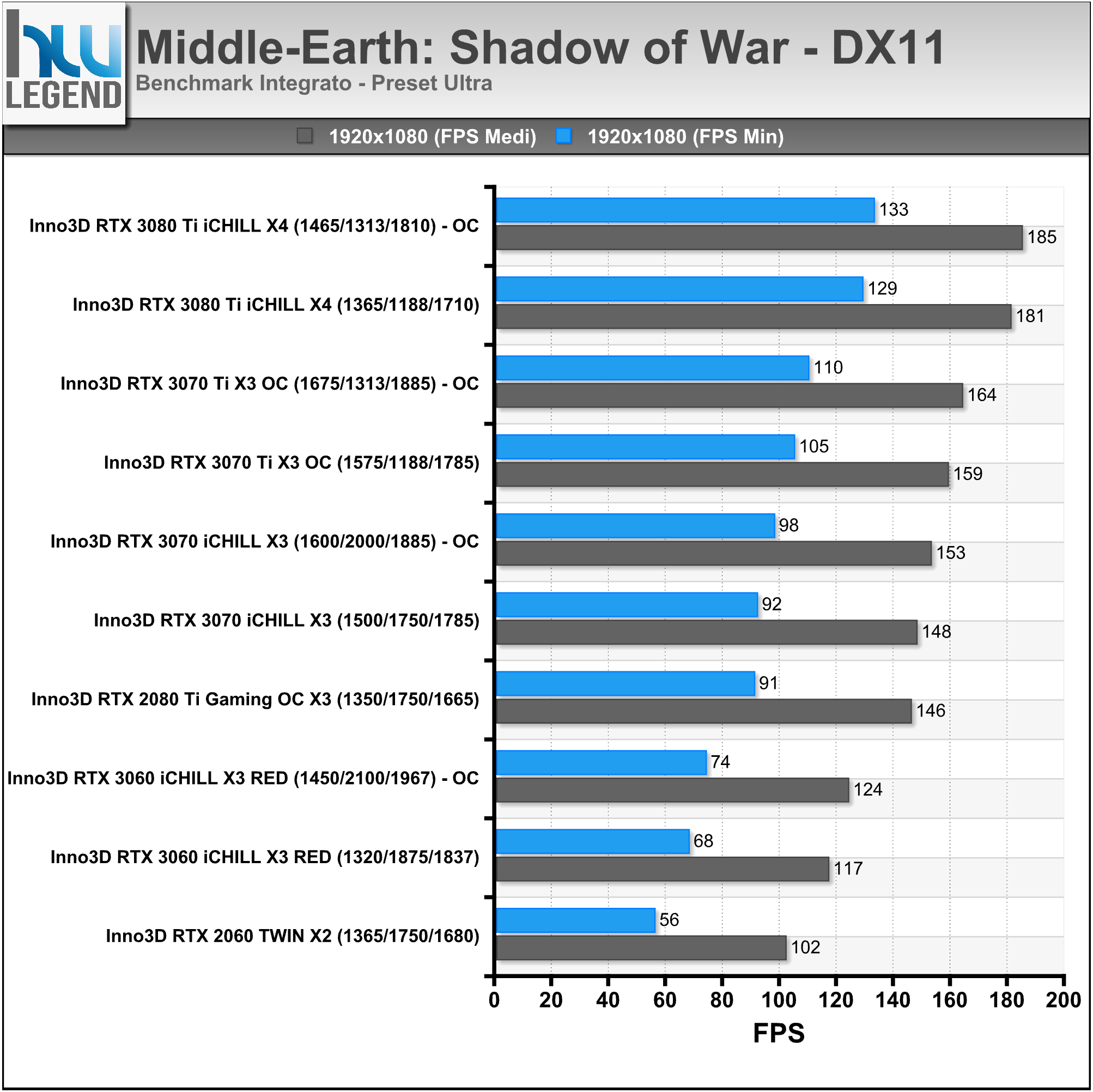
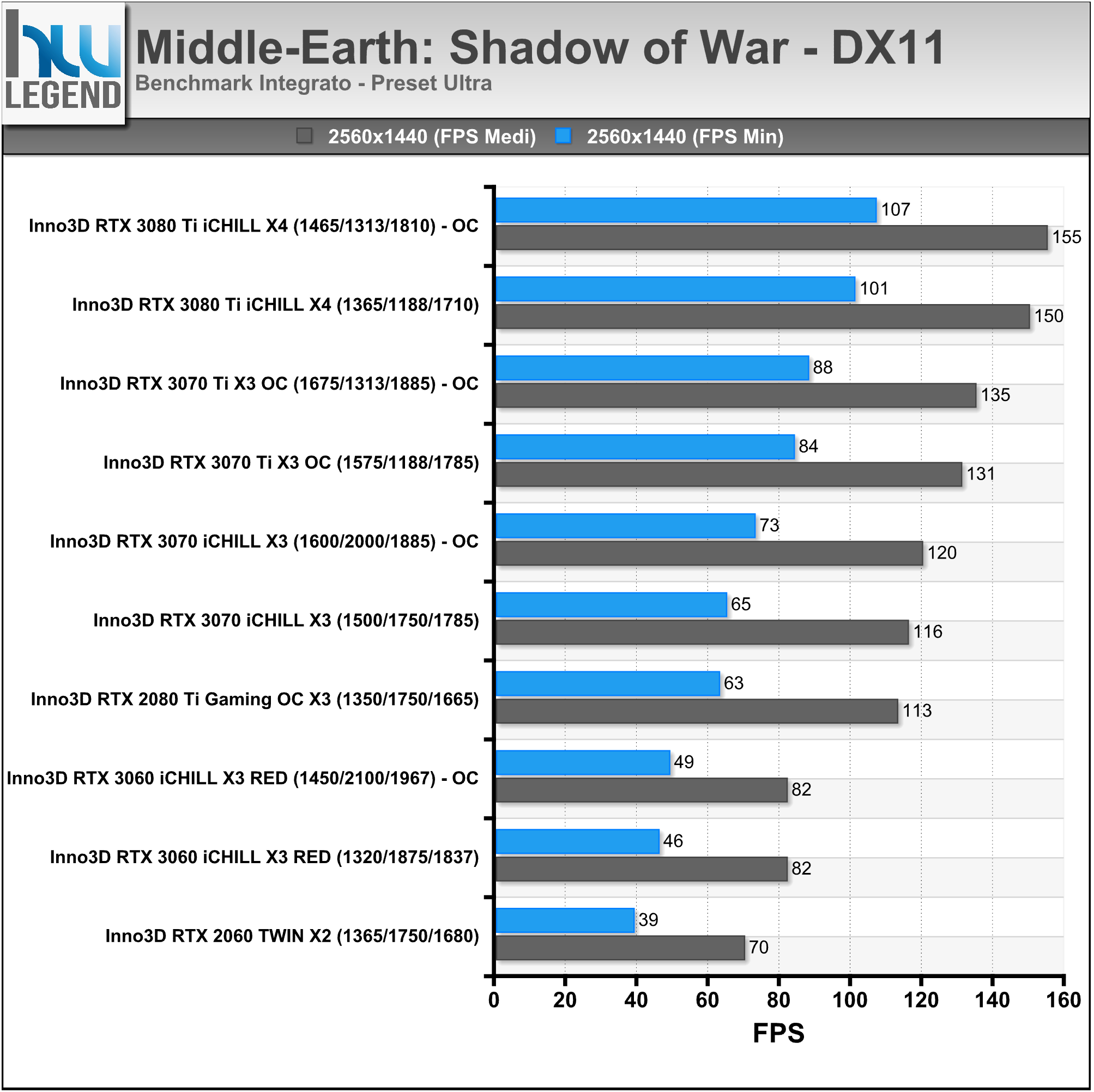
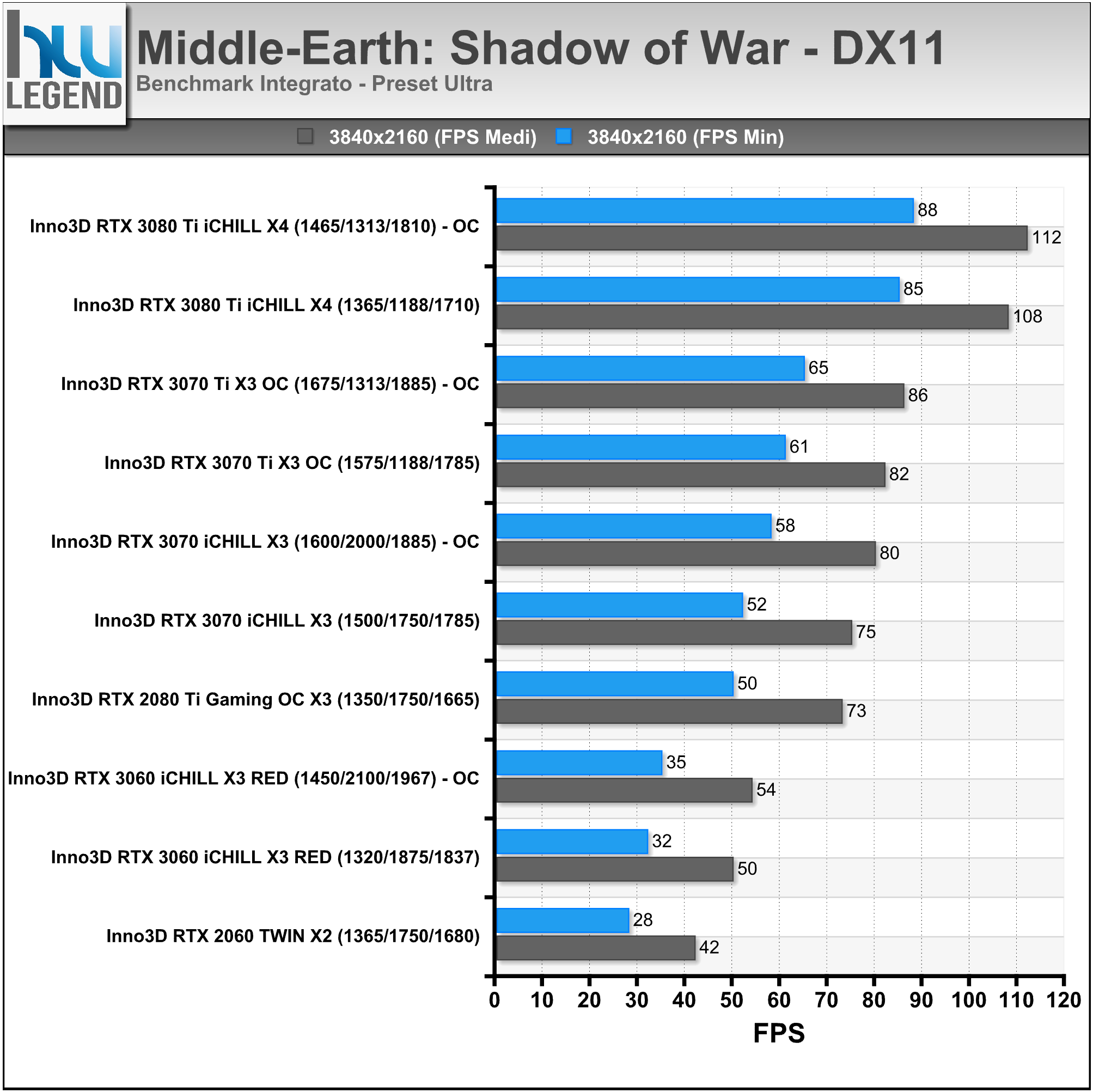
[nextpage title=”DX11: The Witcher 3 Wild Hunt”]
The Witcher 3: Wild Hunt è un gioco di ruolo di nuova generazione, creato dal team polacco CD Projekt RED, incentrato sulla trama e ambientato in un mondo aperto.
L’universo fantasy del gioco ha una resa visiva sbalorditiva e la trama è ricchissima di scelte rilevanti, con vere conseguenze. Il giocatore interpreta Geralt of Rivia, un cacciatore di mostri che ha l’incarico di trovare un bambino il cui destino è al centro di un’antica profezia. Geralt of Rivia è un witcher, un cacciatore di mostri professionista.

I suoi capelli bianchi e gli occhi da felino lo rendono una leggenda vivente. Addestrati sin dalla prima infanzia e mutati geneticamente per dotarli di abilità, forza e riflessi di entità sovrumana, i witcher come Geralt sono una sorta di difesa “naturale” per l’infestazione di mostri che attanaglia il mondo in cui vivono.
Nei panni di Geralt, ti imbarcherai in un viaggio epico all’interno di un mondo sconvolto dalla guerra che ti porterà inevitabilmente a scontrarti con un nemico oscuro, peggiore di qualsiasi altro l’umanità abbia affrontato sinora, la Caccia selvaggia. I test sono stati condotti usando i seguenti settaggi:
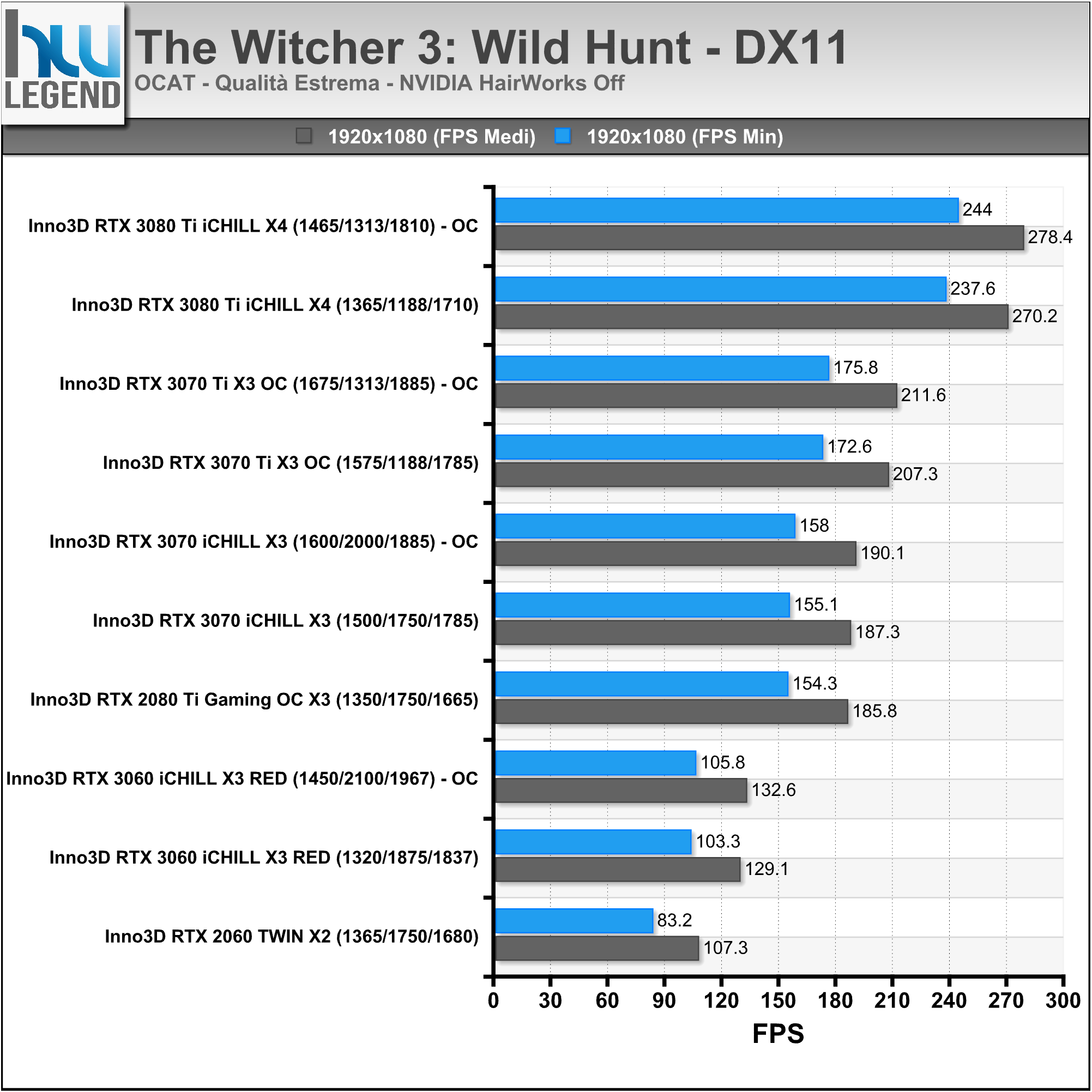
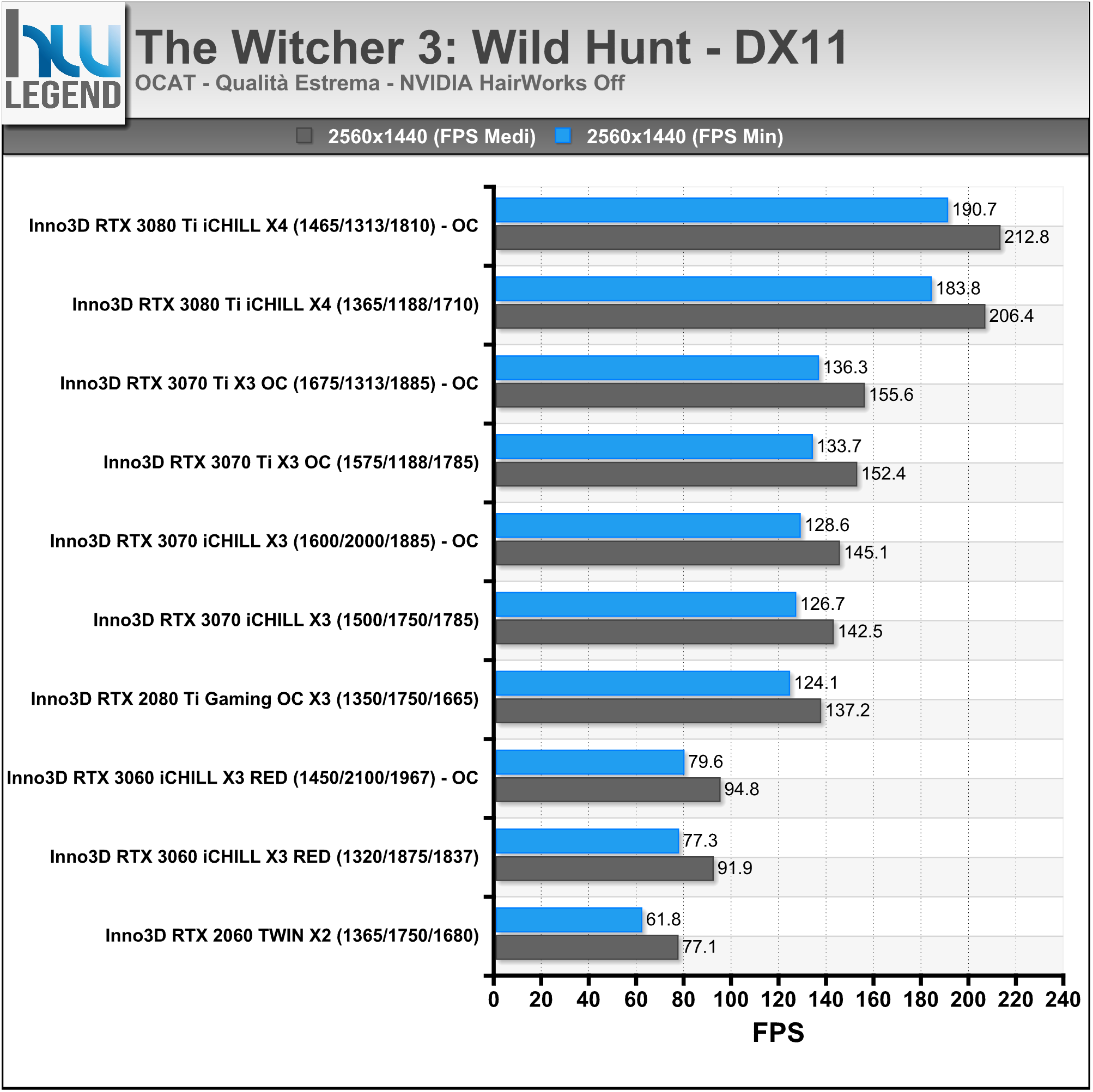
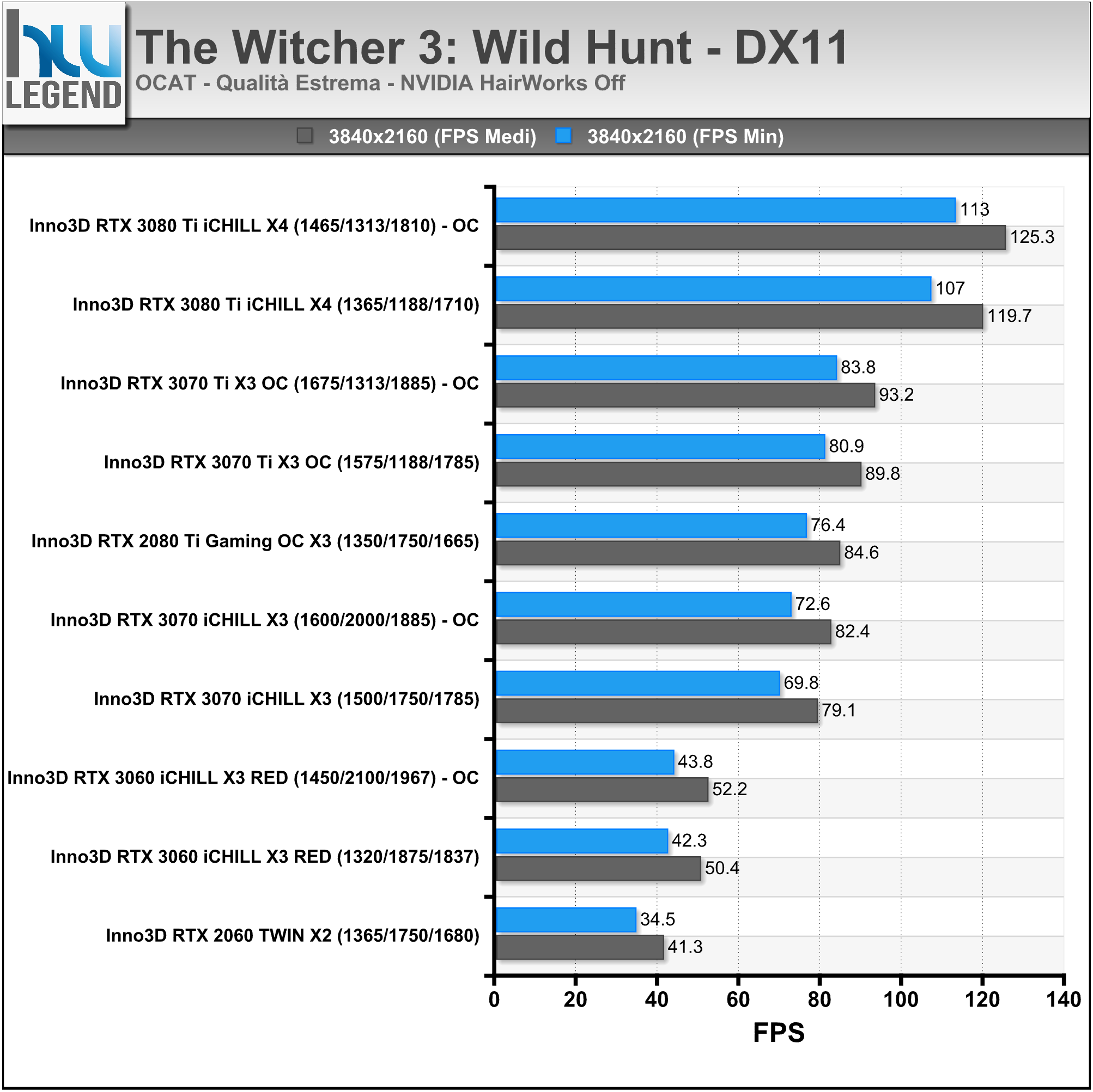
NOTA: Per la misurazione degli FPS abbiamo utilizzato l’ultima versione disponibile del software OCAT, liberamente scaricabile a questo indirizzo e capace di registrare correttamente il framerate indipendentemente dalle API in uso.
[nextpage title=”Considerazioni e Riepilogo Risultati Benchmark Sintetici e Giochi”]
La nuovissima INNO3D GeForce RTX 3070 Ti X3 OC si è dimostrata un prodotto certamente molto valido, capace di ottenere risultati più che soddisfacenti in ogni ambito in cui è stata messa alla prova, che sia il puro gaming oppure uno dei tanti benchmark sintetici. Rispetto alle proposte concorrenti, la soluzione messa a punto dal noto produttore asiatico si differenzia soprattutto per l’esclusivo sistema di dissipazione del calore impiegato di tipo Dual-Slot, espressamente pensato per assicurare una maggiore compatibilità in fase di installazione, oltre che per il mantenimento di buone temperature di esercizio senza rinunciare al confort acustico.
Dopo aver utilizzato la scheda per tutto il tempo necessario all’esecuzione delle nostre prove, infatti, dobbiamo ammettere di non aver mai avvertito una rumorosità che potesse risultare fastidiosa. Inoltre, durante i momenti di scarso utilizzo del processore grafico entra in gioco la tecnologia proprietaria Intelligent Fan Stop 0dB, che provvederà a disattivare completamente tutte le ventole di raffreddamento presenti, ottenendo una silenziosità totale, equivalente a quella di una soluzione passiva.
La nostra suite di prova prevede l’utilizzo dei più noti e diffusi benchmark sintetici e giochi, scelti in maniera da poter offrire un quadro complessivo preciso ed affidabile delle performance velocistiche offerte dalla soluzione grafica in esame. In considerazione della notevole mole di dati rilevati durante l’esecuzione delle nostre prove abbiamo deciso di renderne più semplice l’interpretazione proponendovi un riepilogo delle performance relative registrate nei confronti della precedente soluzione di pari fascia INN03D GeForce RTX 3070 iCHILL X3, basata su una declinazione lievemente decurtata del processore grafico GA104 (GA104-300).
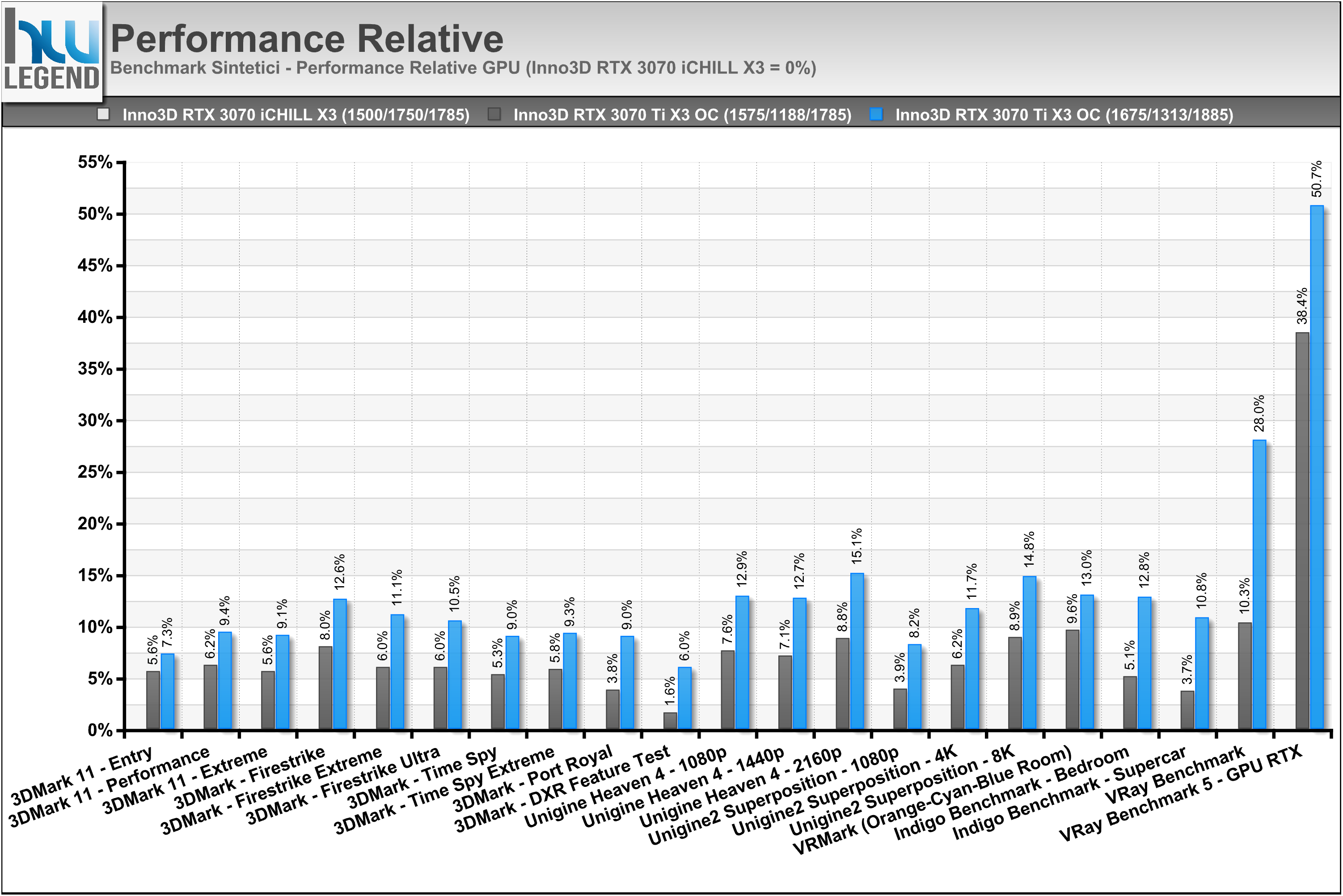
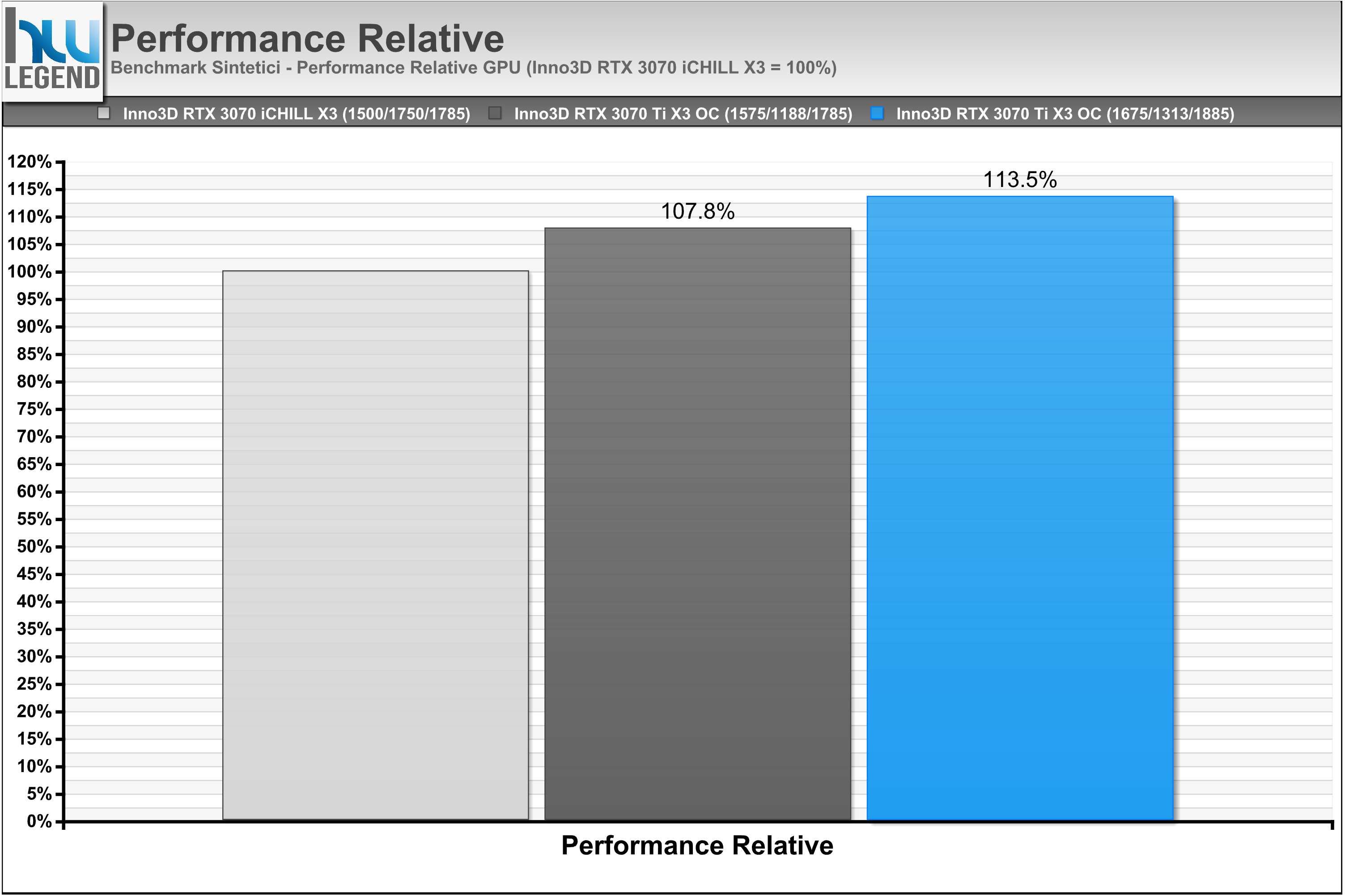
Come vediamo, i risultati ottenuti con i vari benchmark sintetici mostrano un distacco, rispetto alla precedente soluzione GeForce RTX 3070, mediamente pari al +8% ai valori di targa e di poco superiore al +13% applicando il nostro profilo OC-Daily.
I valori di picco vengono registrati in ambito GPGPU, nel quale ritroviamo numerosi applicativi capaci di sfruttare in maniera decisamente più marcata ed efficiente una tra le principali novità introdotte in questa nuova soluzione grafica, ovvero l’impiego di moduli di memoria di tipo GDDR6X, in grado di assicurare una ben più elevata banda passante.
Non è un caso, quindi, che facendo uso del recente software di rendering V-Ray 5 Benchmark, e sfruttando il nuovo preset espressamente dedicato alle soluzioni NVIDIA GeForce RTX, si riesca a raggiungere il +50% di incremento.
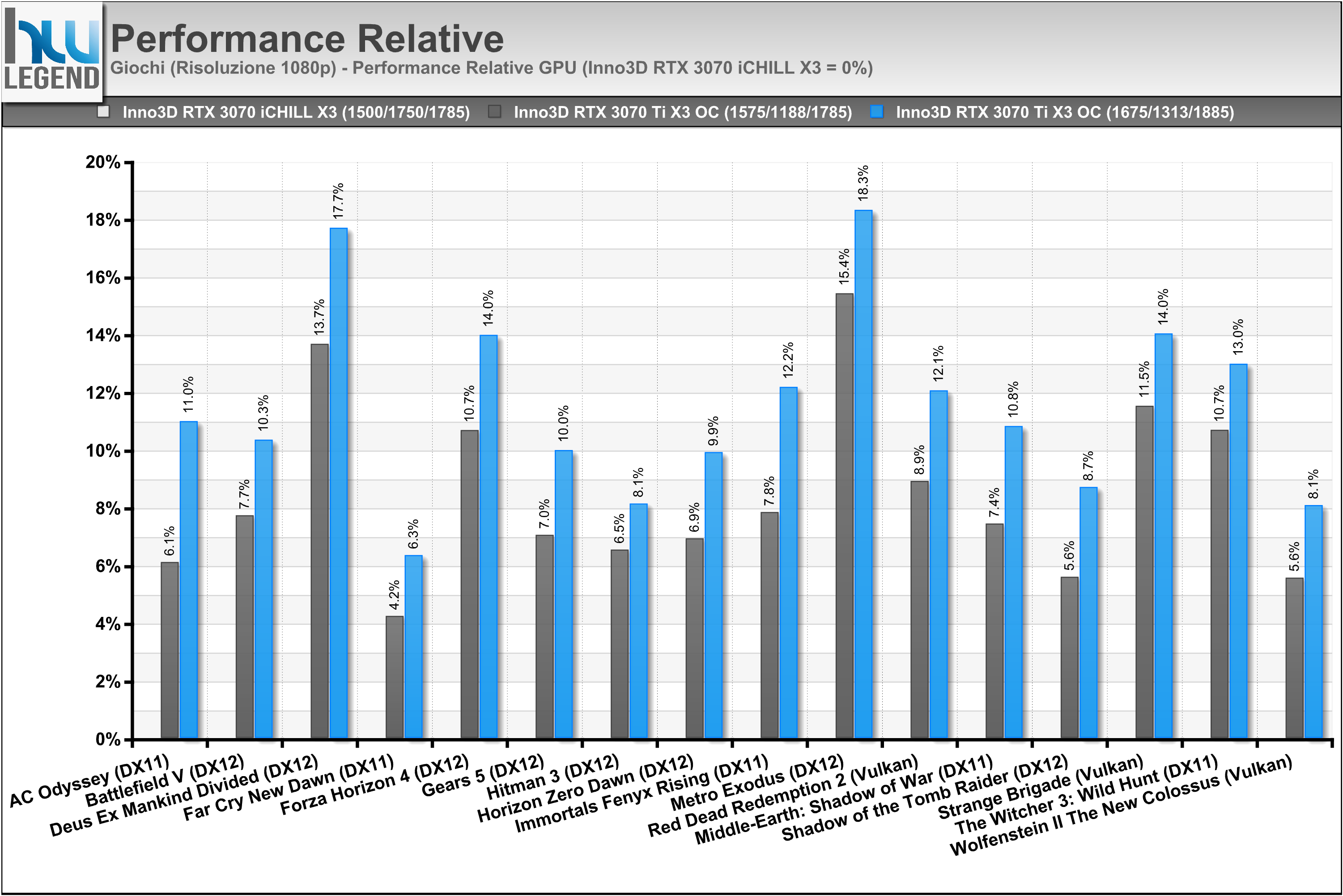
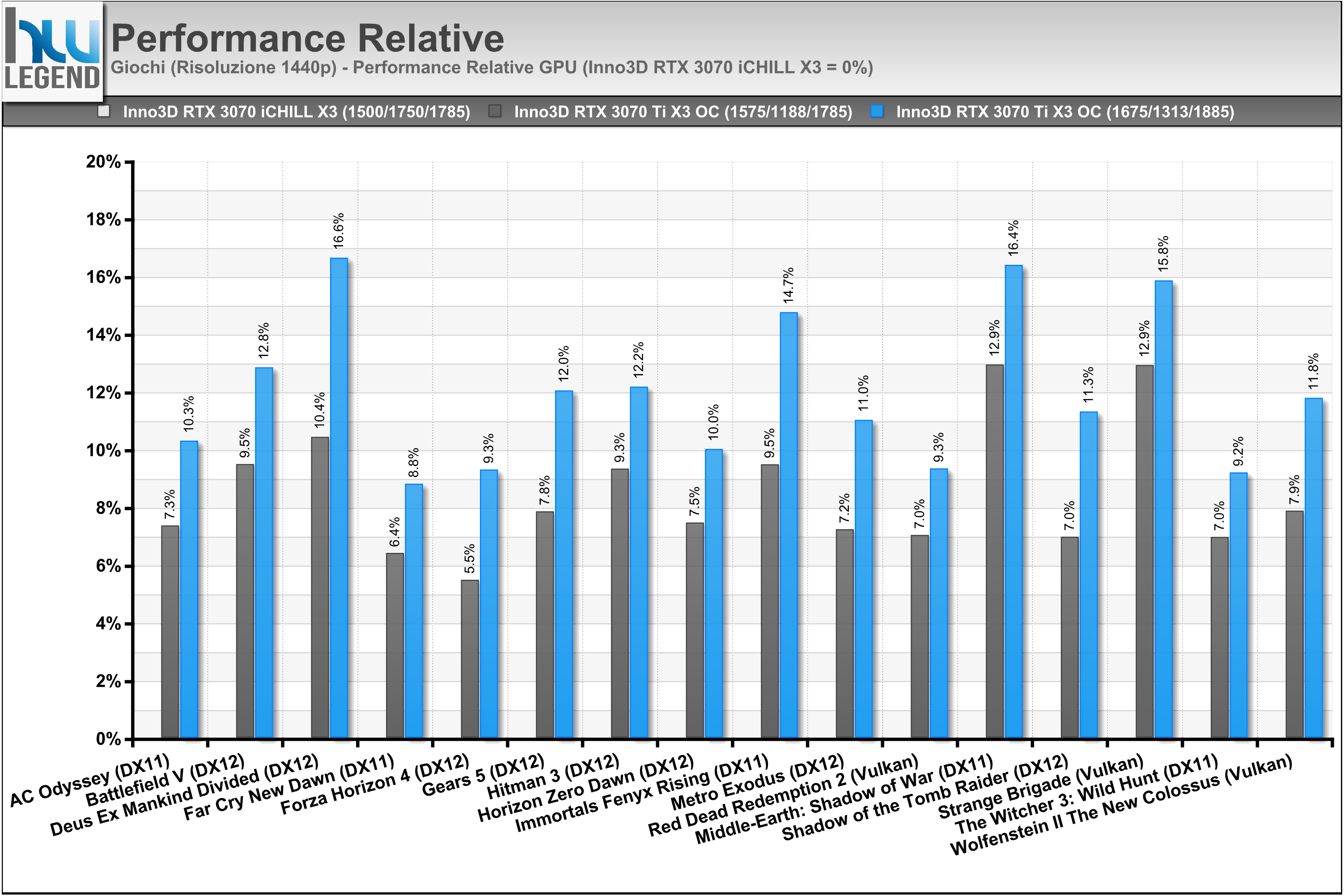
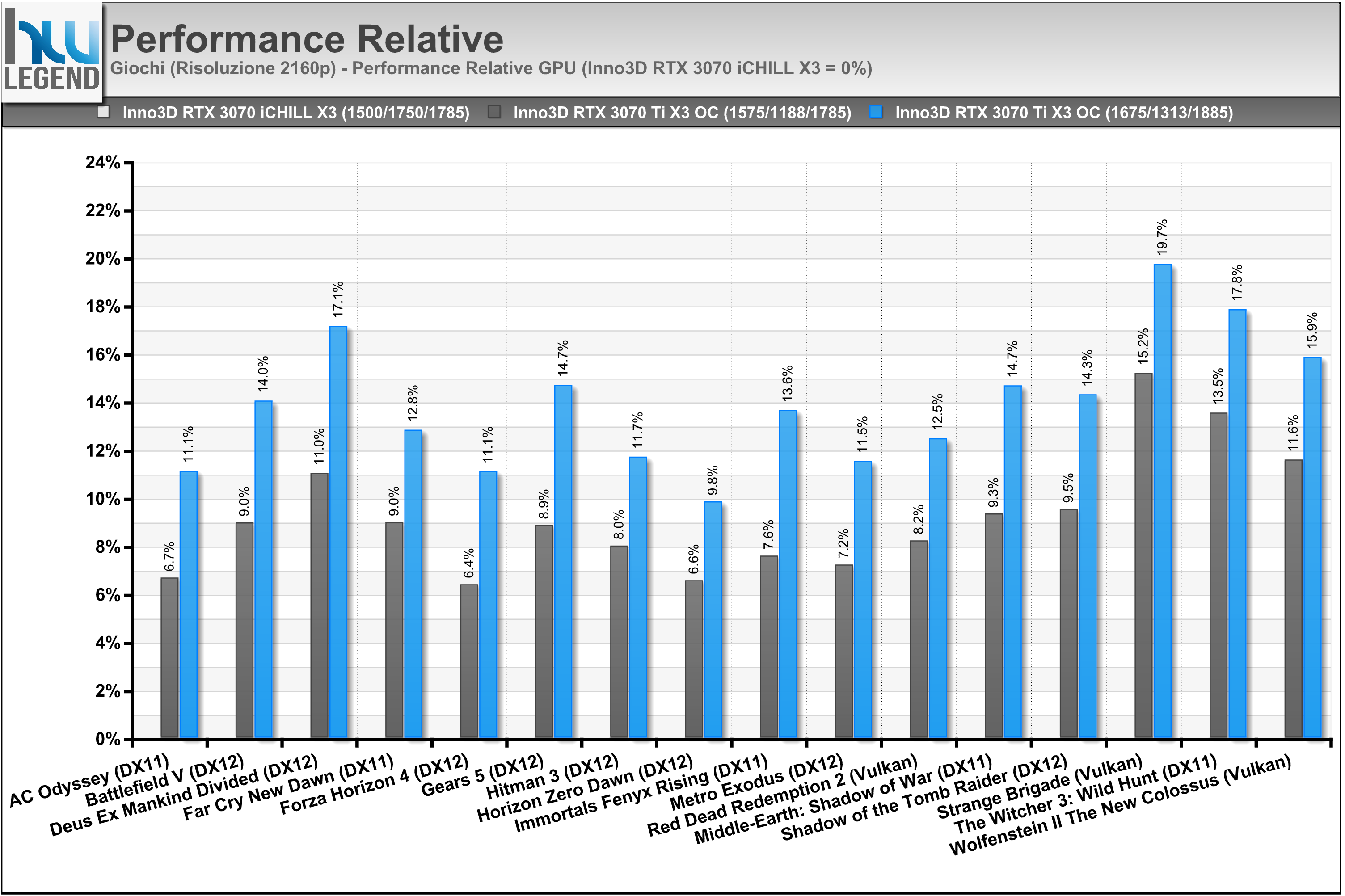
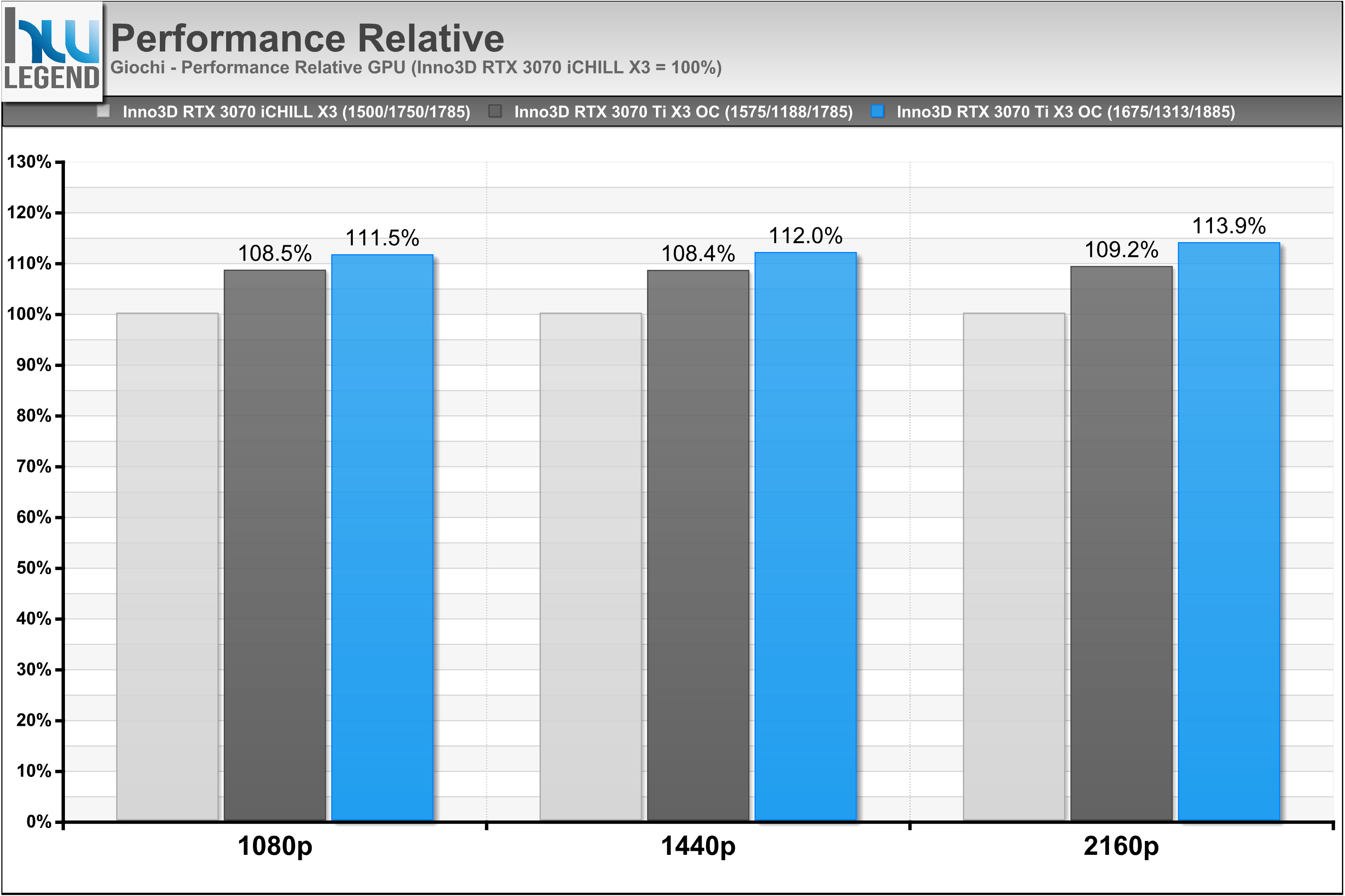
Anche con i giochi testati la situazione è abbastanza similare e vede la nuova soluzione grafica Ampere con GA104 “Full” sensibilmente in vantaggio sulla precedente proposta di pari fascia GeForce RTX 3070. In questo caso abbiamo deciso di proporvi grafici riepilogavi a sé stanti, uno per ogni risoluzione di prova (1080p, 1440p e 2160p).
Alla risoluzione più bassa testata, ovvero a 1920×1080 otteniamo una media del +8% in condizioni di default e poco più del +11% applicando il nostro profilo in overclock, con picco massimo che sfiora il +20% nel recente Metro Exodus. Salendo a risoluzioni ben più consone alle potenzialità delle soluzioni grafiche testate, ovvero a 2560×1440 e 3840×2160, la scheda in esame distanzia ancor più marcatamente la precedente GeForce RTX 3070, nello specifico di un +8% in 1440p a default (che sale a circa +12% in overclock) e poco più del +9% in 2160p a default (circa +14% in overclock).
Alla luce dei risultati ottenuti appare innegabile come questa nuova soluzione grafica di fascia medio alta riesca a garantire un’esperienza di gioco del tutto soddisfacente in ogni scenario. Di conseguenza dobbiamo ammettere che a nostro avviso solamente coloro che intendono giocare al massimo della qualità (anche facendo uso del ray-tracing in tempo reale a livello alto) con tutti gli ultimi titoli disponibili, o che meglio ancora prevedono il futuro acquisto di monitor 4K Ultra-HD ad alto refresh (120/144Hz), sentiranno la necessità di ricorrere a soluzioni di fascia superiore.
Per tutti gli altri, compresi eventualmente quelli disposti a scendere a qualche piccolo compromesso con le opzioni grafiche avanzate, questa interessante proposta custom GeForce RTX 3070 Ti saprà regalare più di una soddisfazione, risultando più che dignitosa fino al 1440p ad alto refresh o 4K, anche con ray-tracing abilitato.
In quest’ultimo scenario abbiamo osservato come il Deep Learning Super-Sampling (DLSS) può fare la differenza, rendendo molto più accessibile l’uso del ray-tracing in tempo reale. Con gli ultimi aggiornamenti dei vari titoli compatibili da parte degli sviluppatori, nonché dei driver grafici NVIDIA, abbiamo finalmente raggiunto un’implementazione più che soddisfacente di questa eccellente tecnologia, capace di assicurare un deciso guadagno prestazionale a fronte di una resa visiva che si mantiene su alti livelli.
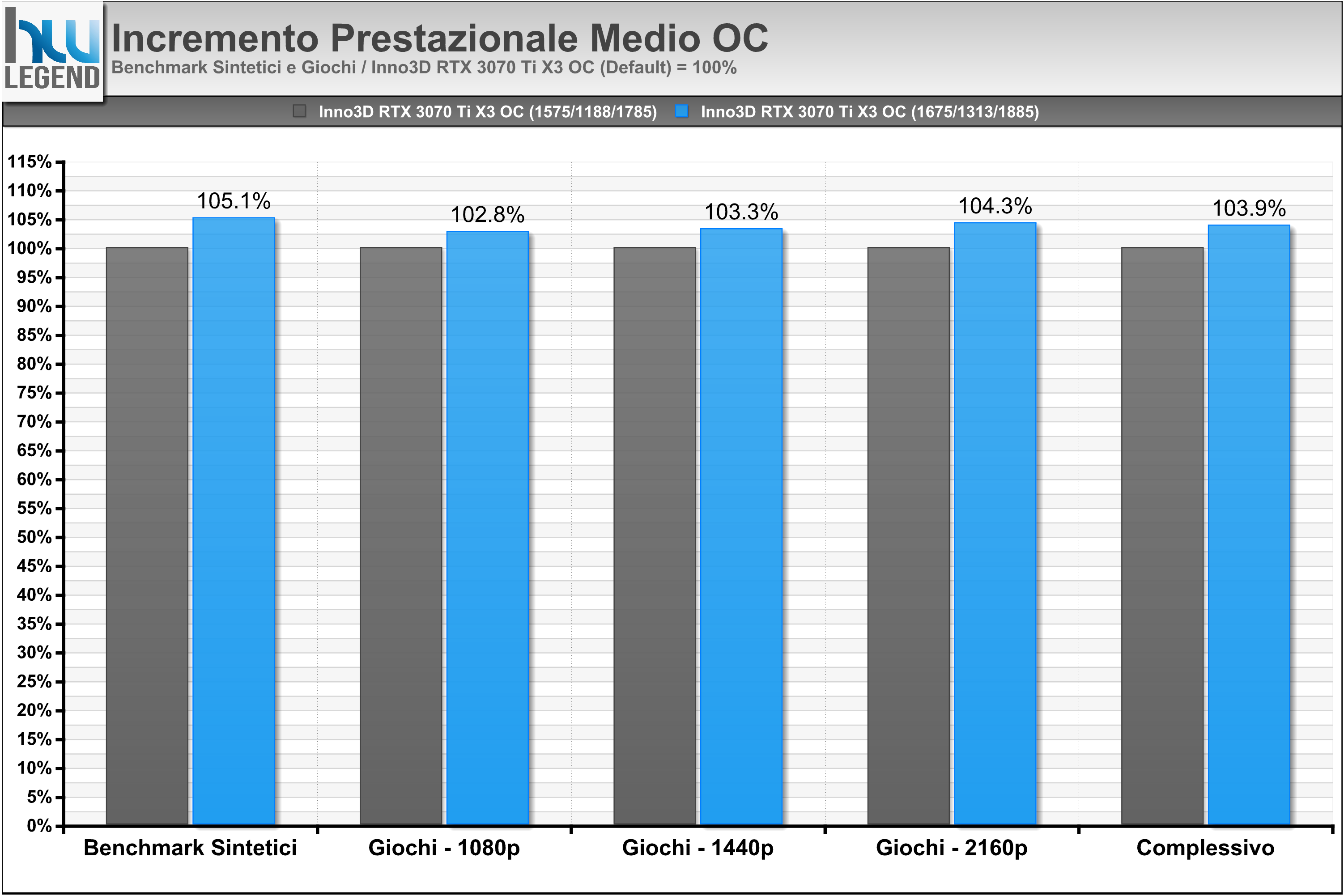
Il nostro profilo in overclock prevede un incremento delle frequenze pari a circa il +7% medio (poco più del +6% sul Base Clock, +5% sul Boost Clock e poco più del +10% per quanto riguarda i nuovi moduli GDDR6X), a fronte del quale otteniamo un impatto sulle prestazioni velocistiche, come possiamo osservare nel seguente grafico riepilogativo, pari all’incirca al +4% medio.
[nextpage title=”Temperature, Rumorosità e Consumi”]
Durante le nostre prove abbiamo potuto constatare che sia le ventole che il gruppo dissipante svolgono egregiamente il loro compito, senza mai eccedere in quanto a rumorosità e garantendo il mantenimento di buone temperature di esercizio, sia a default che con nostro profilo di overclock daily.
Rilevamento delle Temparature
Di seguito l’andamento delle temperature con scheda grafica in condizione Idle e Full-Load (Gaming e Benchmark), registrato utilizzando il software GPU-Z:
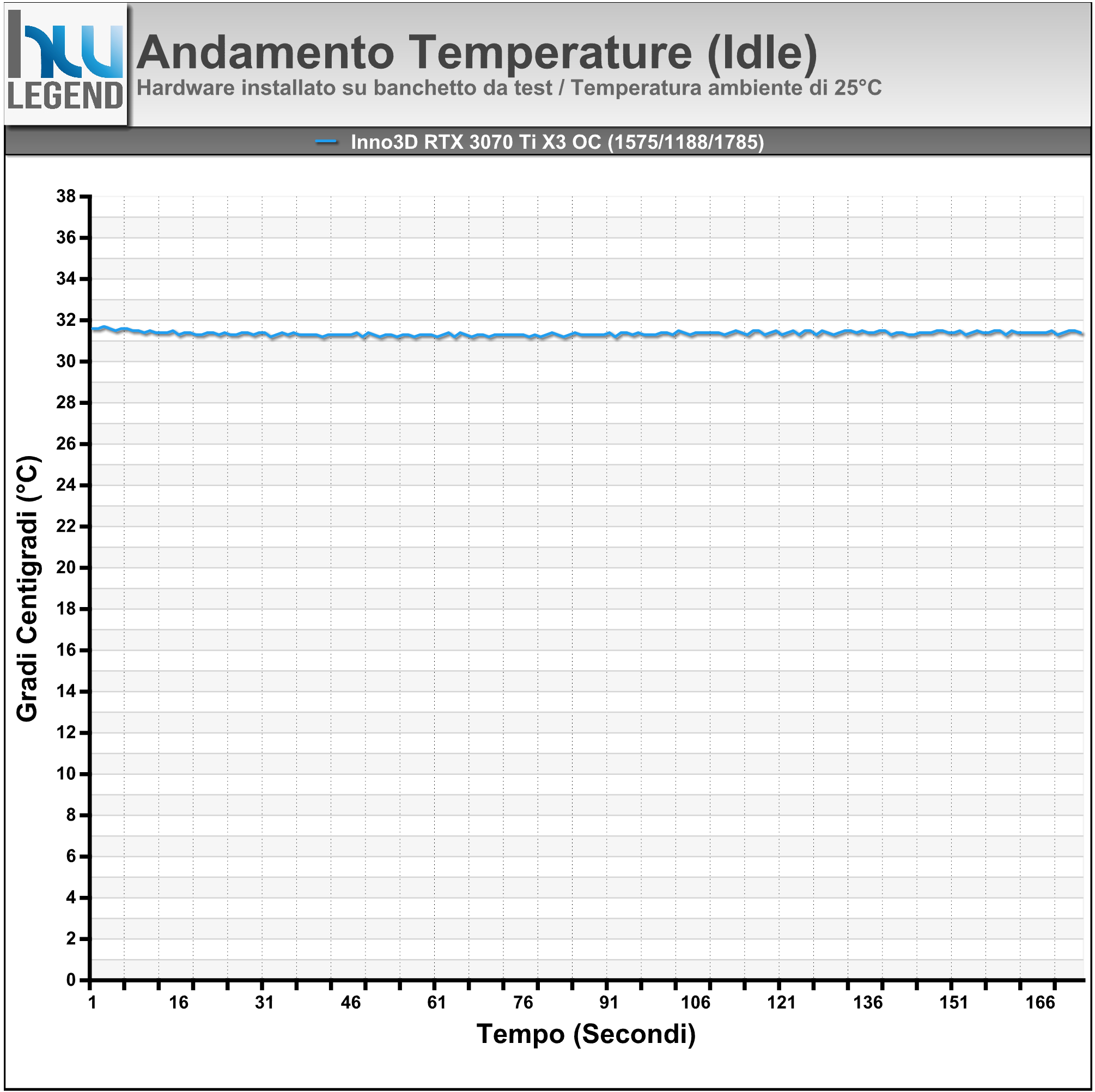
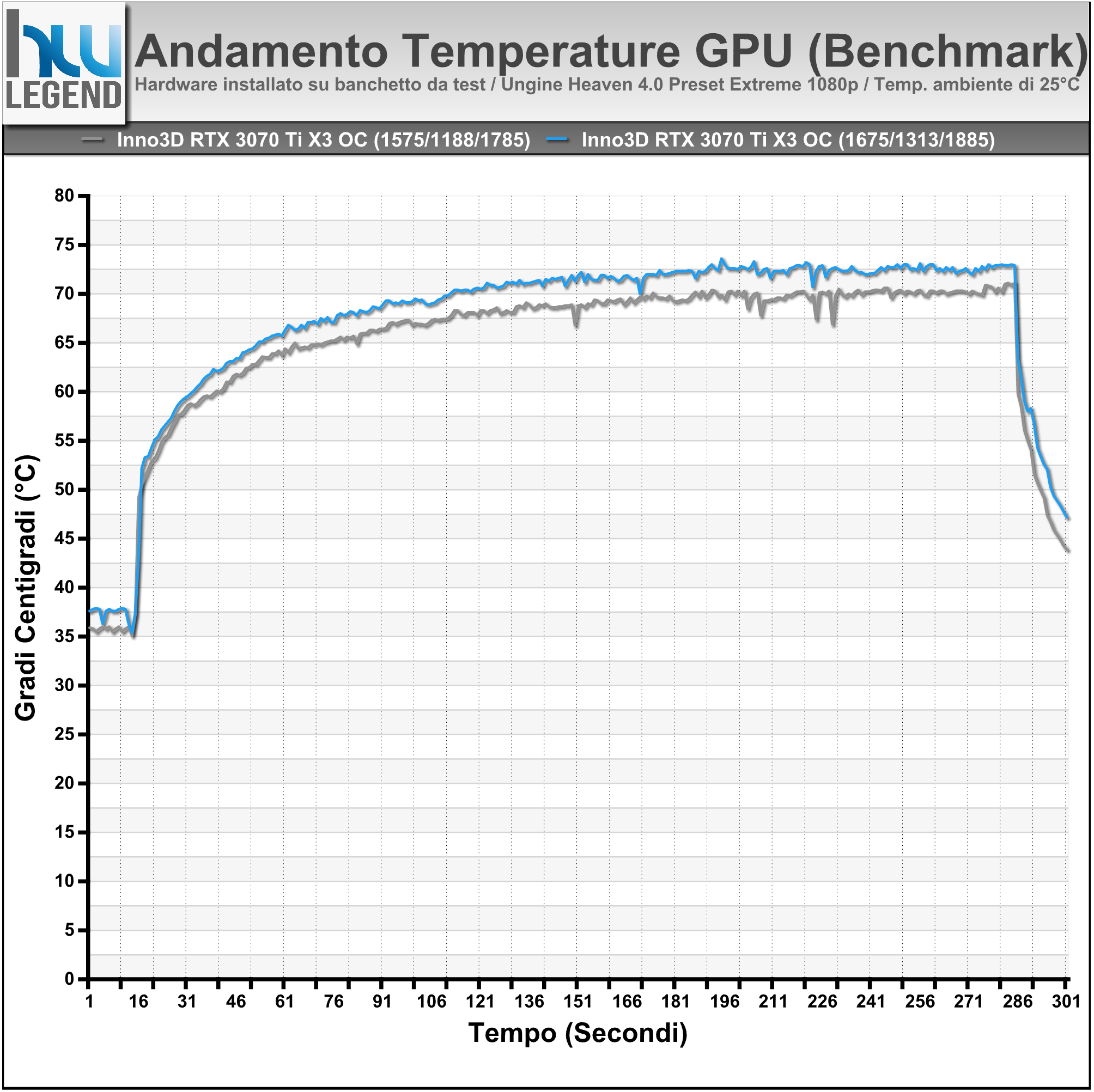
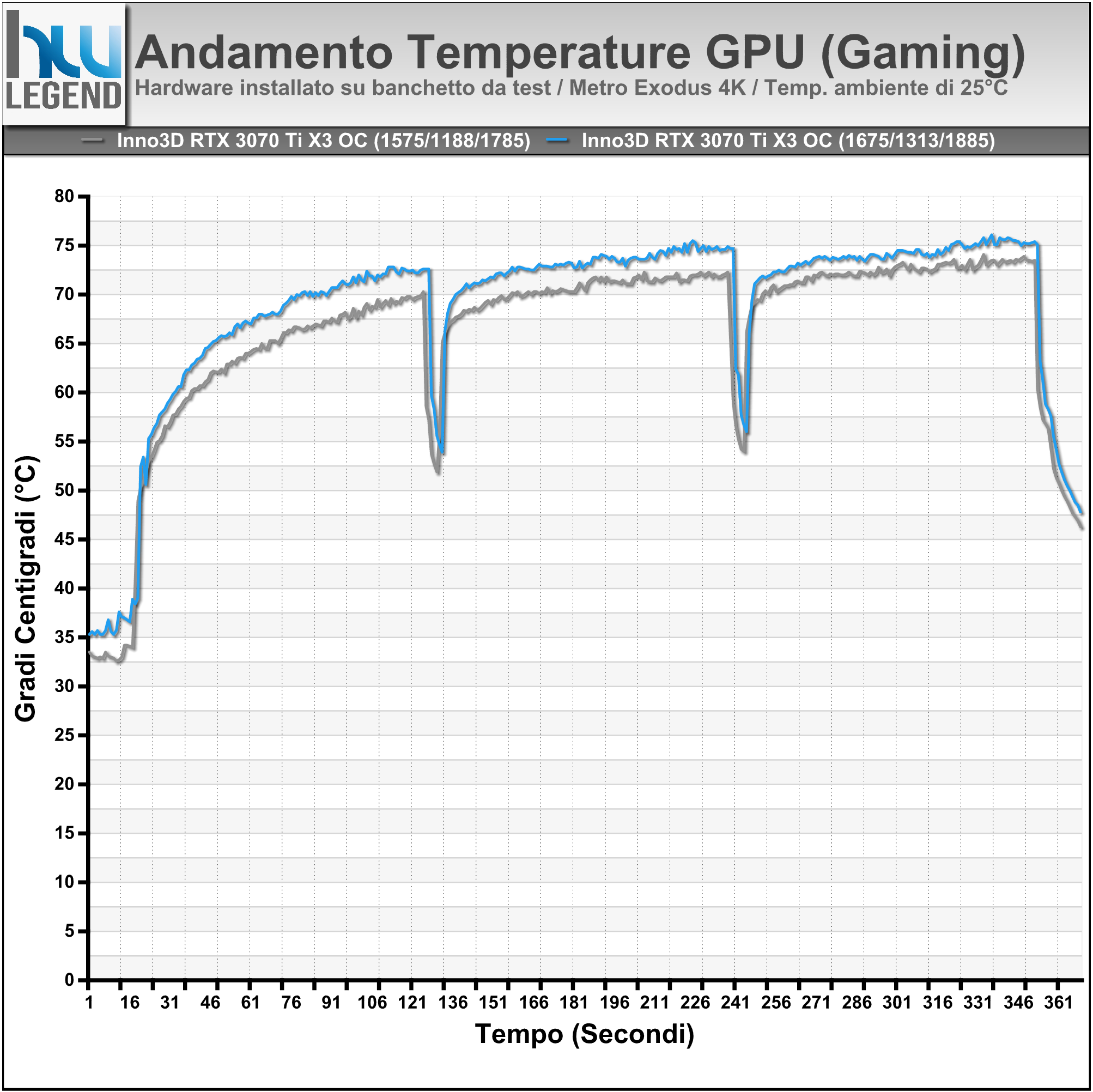
Come possiamo osservare dai grafici riepilogativi le temperature di esercizio medie si mantengono al di sotto della soglia dei 75°C, anche in condizione di overclocking e con carico consistente, come quello rappresentato dal benchmark integrato nel gioco Metro Exodus, eseguito per tre volte consecutive alle massime impostazioni grafiche e ad una risoluzione di 3840×2160 (4K). Leggermente inferiori le temperature massime registrate durante l’esecuzione del benchmark Unigine Heaven 4.0 (Preset Extreme a risoluzione Full-HD), con una media di poco superiore ai 70°C facendo uso del nostro profilo OC-Daily.
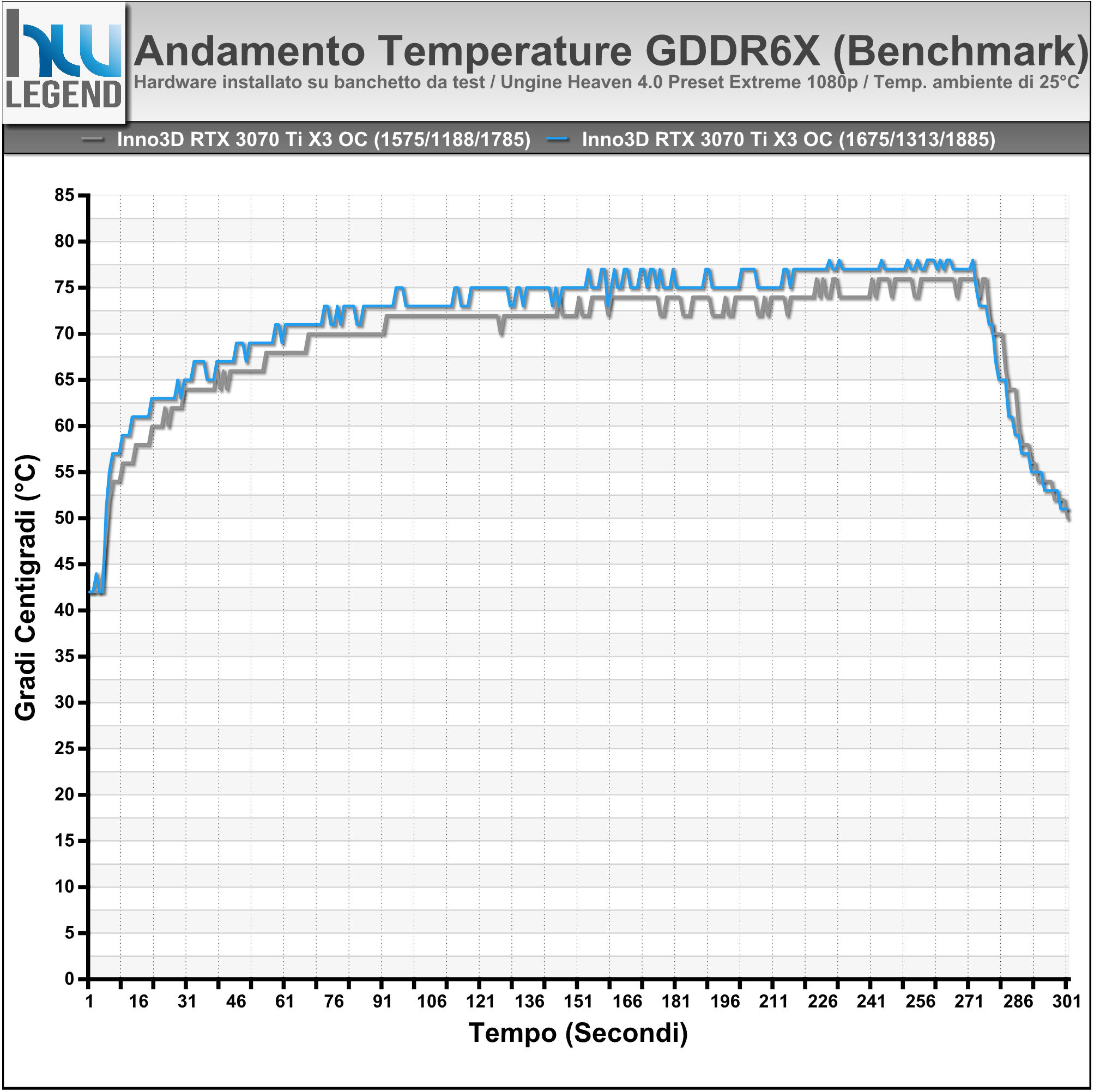
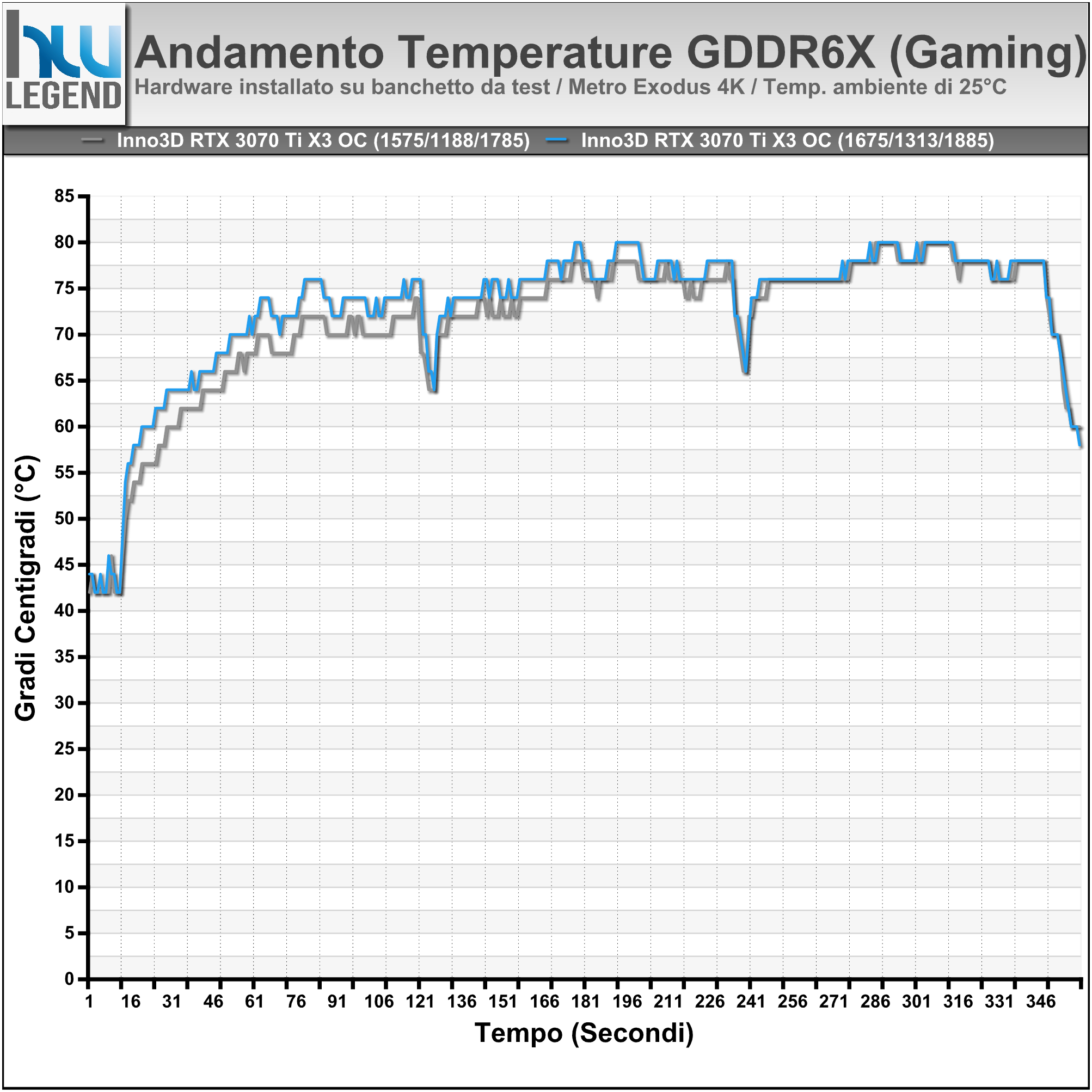
Come osservato nel corso del nostro articolo con la nuova architettura Ampere debuttano ufficialmente, in ambito consumer, anche le nuovissime memorie GDDR6X messe a punto da Micron Technology, capaci di assicurare un raddoppio della bandwidth rispetto alle tradizionali GDDR6. Sulla soluzione in esame sono stati impiegati moduli certificati per una frequenza operativa pari a 1.188MHz (19Gbps).
Nelle nostre prove in overclock siamo riusciti a raggiungere una frequenza operativa di ben 1.313MHz (21Gbps), senza alcun problema di sorta ed in piena stabilità. Anche con queste componenti decisamente “calde”, e per giunta in regime di overclock, il compatto sistema di dissipazione Dual-Slot messo a punto da INN03D si è dimostrato perfettamente in grado di assicurare il mantenimento di temperature di esercizio più che soddisfacenti, e soprattutto abbondantemente entro i livelli di guardia riportati nel datasheet ufficiale.
Ricordiamo che tutto l’hardware è installato su un banchetto da test DimasTech e che la temperatura ambiente, durante le misurazioni, era di circa 25°C.
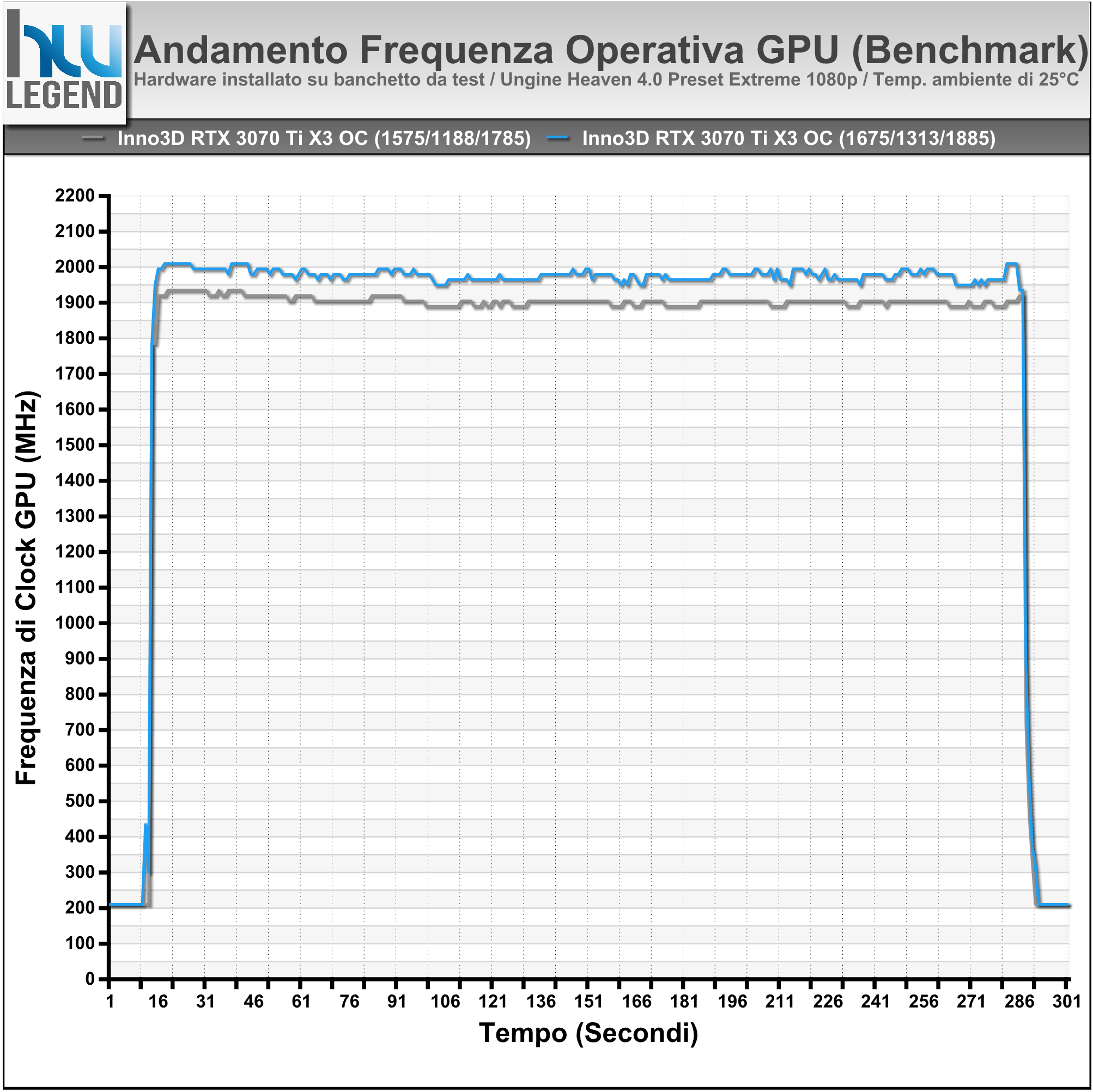
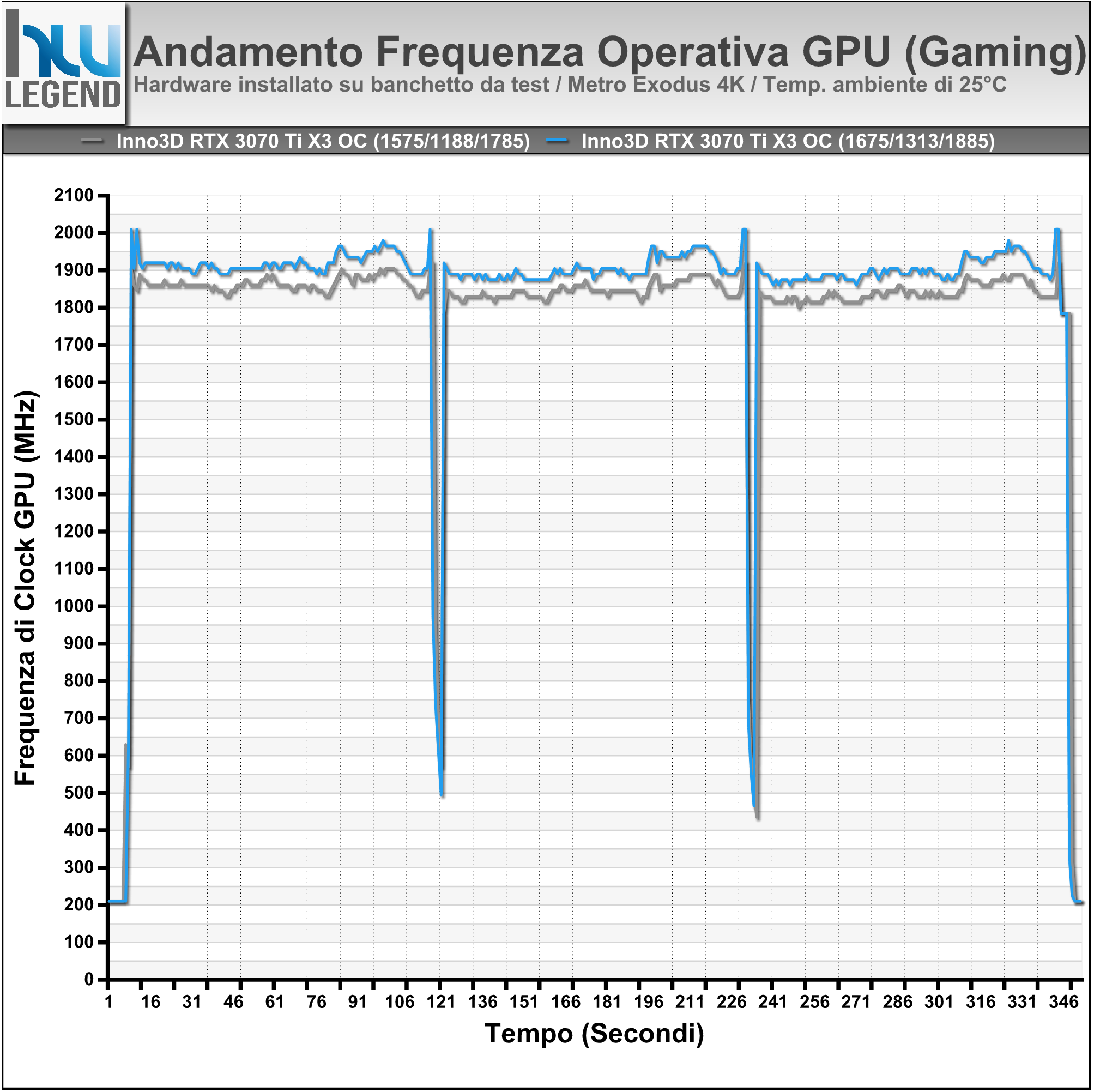
Come ormai sappiamo le ultime soluzioni grafiche di NVIDIA hanno di fatto abbandonato la tradizionale logica di funzionamento a frequenza fissa in favore di un approccio di tipo dinamico, espressamente pensato per consentire una variazione automatica della frequenza di clock del processore grafico in relazione non solamente al carico di lavoro, ma anche a condizioni fisiche come le temperature di esercizio, i consumi energetici e quant’altro, arrivando a raggiungere anche frequenze massime anche sensibilmente superiori a quelle per così dire normali e di base, grazie alla tecnologia GPU Boost, giunta con Ampere alla sua quinta generazione.
Lo scopo è quello di sfruttare sino in fondo la potenza di calcolo della scheda grafica ogni qual volta vi siano le condizioni idonee per poterlo fare, in maniera da garantire un margine di guadagno sulle performance apprezzabile e soprattutto del tutto “gratuito”. La nostra scheda grafica, in condizioni normali previste dal produttore, prevede una frequenza di Boost pari a 1.785MHz (10MHz in più rispetto alle specifiche di riferimento di NVIDIA).
Come possiamo osservare dai grafici riepilogativi, questa frequenza viene abbondantemente superata durante le nostre sessioni di prova, ottenendo una media pari a 1.825MHz con Metro Exodus e ben 1.905MHz con il software di benchmark Unigine Heaven 4.0. Alla stessa maniera in condizione di overclock manuale delle frequenze otteniamo, a fronte di una frequenza di Boost prevista di 1.885MHz, una media reale sensibilmente superiore, pari a circa 1.905MHz con il nostro gioco, e 1.980MHz con il software di benchmark di Unigine.
Rilevamento della Rumorosità

Per il rilevamento della rumorosità durante il funzionamento di ventole e dissipatori abbiamo scelto di usare strumentazione professionale a marca PCE, e nello specifico il fonometro PCE-999.
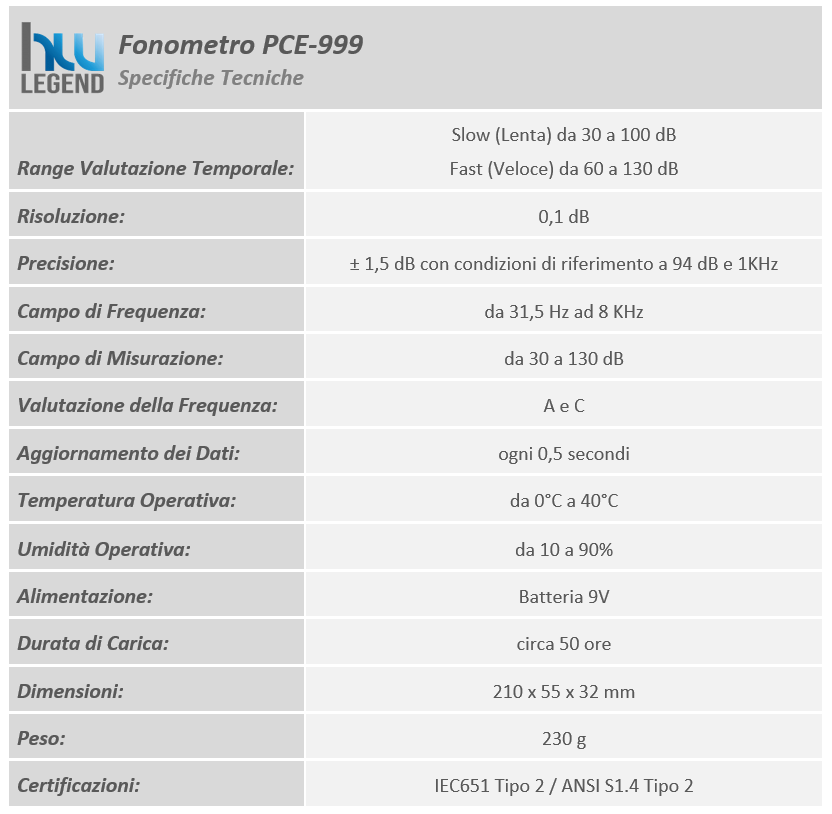
Il test di rumorosità è uno dei più difficili da effettuare, poiché durante la fase di test qualsiasi rumore, anche minimo, può far balzare il grafico verso l’alto, di fatto invalidando il lavoro effettuato e costringendoci a ripetere il test dall’inizio.
Per questo motivo, non disponendo purtroppo di una camera anecoica, ci siamo veduti costretti ad aspettare le tarde ore notturne per poter effettuare i nostri test in tutta tranquillità e con rumore ambientale il più basso e costante possibile. Lo strumento utilizzato, il fonometro PCE-999, è molto sensibile al rumore ambientale. Da questo valore, tipico di qualsiasi ambiente domestico, è necessario partire per poter analizzare la rumorosità del complesso dissipatore/ventola.
Nel grafico che segue vengono riportate le rilevazioni fatte ad una distanza, dalla scheda grafica, prima di 60, poi di 30, ed infine di 15 cm. Il regime di rotazione delle ventole è stato impostato manualmente al 25 (il minimo impostabile), 50, 60, 75, 85 ed infine al 100% (il massimo impostabile), in maniera da fornire un quadro il più possibile preciso della situazione.
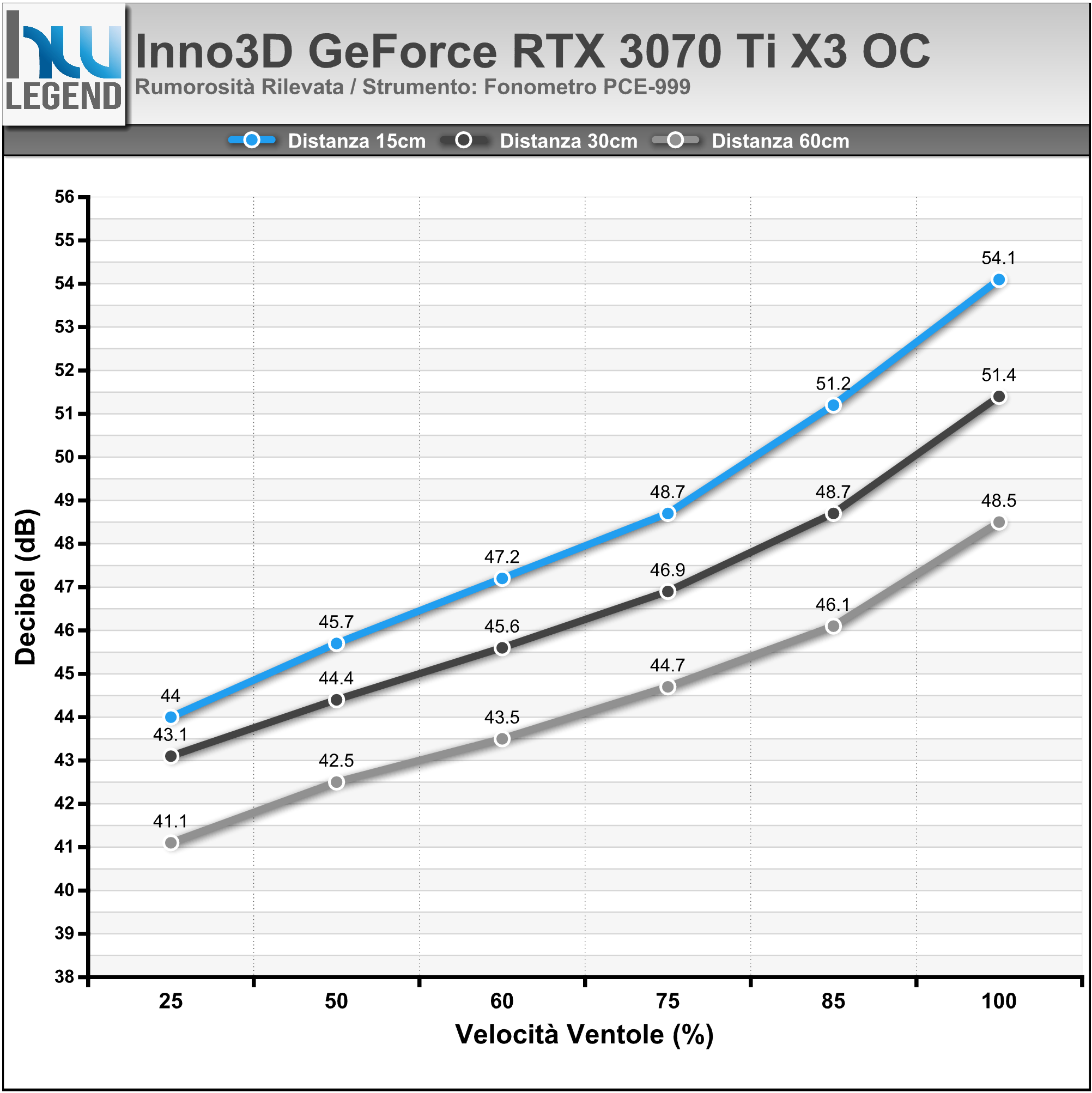
Le nostre misurazioni confermano l’ottima silenziosità del sistema di dissipazione messo a punto da INNO3D, per il quale sono state previste tre ventole da 92 millimetri di diametro, con l’aggiunta del pieno supporto verso la tecnologia proprietaria Intelligent Fan Stop 0dB, che provvederà a sospenderne completamente il funzionamento qualora il processore grafico sia in condizione di riposo (Idle). Questo garantirà una rumorosità praticamente assente durante le fasi di scarso utilizzo della scheda grafica (ed in tutti quei casi nei quali la temperatura della GPU si mantiene al di sotto dei 35°C), del tutto equivalente a quella ottenibile con una soluzione di tipo passivo.
Durante l’utilizzo normale della scheda abbiamo osservato il raggiungimento di un regime di rotazione massimo prossimo al 65-70%, valore che corrisponde ad una rumorosità poco percepibile e non in grado di risultare fastidiosa o compromettere il confort acustico. Procedendo con un’impostazione di tipo manuale, e indicativamente dal 75% a salire, riscontriamo un livello di rumorosità non proprio contenuto e a nostro avviso non indicato ad un utilizzo prolungato.
Quanto scritto non fa che confermare l’ottima efficienza del dissipatore di calore Dual-Slot messo a punto dall’azienda, contraddistinto da una superficie radiante estremamente generosa e coadiuvato da ottime ventole di raffreddamento.
Rilevamento dei Consumi
Tra i principali punti di forza della nuova architettura Ampere di NVIDIA troviamo non soltanto la nuova ed avanzata tecnologia produttiva a 8 nanometri custom NVIDIA (8N) della coreana Samsung, ma soprattutto tutta una serie di miglioramenti e ottimizzazioni mirate al raggiungimento non solo di performance velocistiche sempre più elevate rispetto alle precedenti soluzioni, ma anche ad una maggiore efficienza per Watt. Il nuovo processore grafico di fascia media GA104-400, di cui è dotata la scheda grafica in esame, si è dimostrato, come vedremo, veramente molto interessante.
Di seguito vi mostriamo i consumi del sistema di prova completo, misurati direttamente alla presa di corrente. Le misurazioni sono state ripetute più volte, nel grafico la media delle letture nelle seguenti condizioni:
- Idle con funzionalità di risparmio energetico attivate;
- Full-Load Gaming eseguendo il benchmark integrato nel gioco Metro Exodus a risoluzione 4K;
- Full-Load Stress eseguendo 3DMark Time Spy Extreme Stress Test.
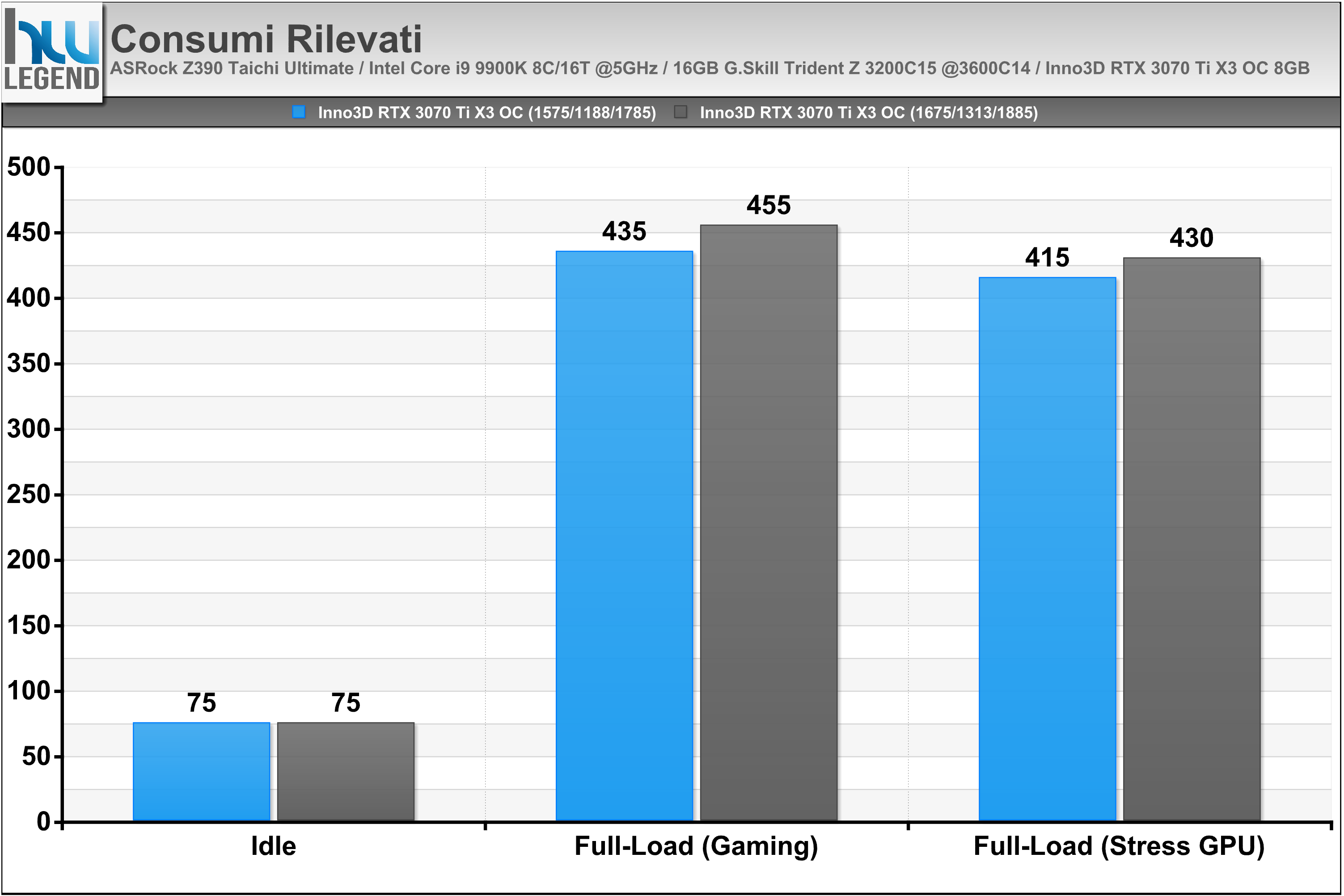
Anche in questo frangente la soluzione INNO3D GeForce RTX 3070 Ti X3 OC è risultata ottima.
[nextpage title=”Conclusioni”]

Per la stesura di questo nostro articolo l’azienda ci ha gentilmente fornito una nuovissima GeForce RTX 3070 Ti X3 OC, soluzione che si colloca nella fascia medio alta del mercato, potendo contare non soltanto sul nuovissimo processore grafico GA104-400 di NVIDIA, basato sull’interessante architettura Ampere, ma anche su un ottimo sistema di dissipazione del calore, di tipo proprietario a doppio slot, contraddistinto non solo da una notevole robustezza e qualità costruttiva, ma soprattutto da ottime performance e notevole silenziosità durante l’uso.
Al pari di altre soluzioni del marchio non manca il pieno supporto verso la tecnologia proprietaria Intelligent FAN Stop 0dB, che provvederà, nel caso in cui la GPU non sia sfruttata in modo intensivo o comunque la sua temperatura non superi la soglia prefissata, a disattivare completamente tutte le ventole di raffreddamento, ottenendo una silenziosità totale, equivalente a quella di una soluzione passiva.
Gli ingegneri INNO3D, come di consueto, oltre alla corretta dissipazione del processore grafico, hanno curato anche quelle delle altre componenti chiave della scheda, spesso trascurate, come i VRM e i moduli di memoria. Il risultato è una scheda grafica che si mantiene abbastanza fresca ed estremamente silenziosa anche dopo ore di utilizzo intensivo. Con gestione automatica del regime di rotazione delle ventole, infatti, non abbiamo quasi mai oltrepassato la soglia dei 75°C, nemmeno applicando il nostro profilo in overclock.
La scheda, come anticipato, si basa sul nuovissimo processore grafico di fascia medio alta GA104-400, capace di beneficiare delle potenzialità e delle novità introdotte da NVIDIA con l’architettura Ampere, oltre che degli indubbi vantaggi derivati dall’utilizzo della nuova ed avanzata tecnologia produttiva ad 8 nanometri custom NVIDIA (8N) dalla coreana Samsung.
Durante le nostre prove, facendo uso dei più noti e diffusi benchmark sintetici e giochi, abbiamo riscontrato un livello prestazionale sensibilmente superiore rispetto alla precedente soluzione di pari fascia GeForce RTX 3070, con medie che raggiungono il +13%. In ambito prettamente gaming l’esperienza è del tutto soddisfacente, con performance interessanti e di alto livello.
Di conseguenza dobbiamo ammettere che a nostro avviso solamente coloro che intendono giocare al massimo della qualità (anche facendo uso del ray-tracing in tempo reale a livello alto) con tutti gli ultimi titoli disponibili, o che meglio ancora prevedono il futuro acquisto di monitor 4K Ultra-HD ad alto refresh (120/144Hz), sentiranno la necessità di ricorrere a soluzioni di fascia superiore.
Per tutti gli altri, compresi eventualmente quelli disposti a scendere a qualche piccolo compromesso con le opzioni grafiche avanzate, questa interessante proposta custom GeForce RTX 3070 Ti saprà regalare più di una soddisfazione, risultando più che dignitosa fino al 1440p ad alto refresh o 4K, anche con ray-tracing abilitato.
In quest’ultimo scenario abbiamo osservato come il Deep Learning Super-Sampling (DLSS) può fare la differenza, rendendo molto più accessibile l’uso del ray-tracing in tempo reale. Con gli ultimi aggiornamenti dei vari titoli compatibili da parte degli sviluppatori, nonché dei driver grafici NVIDIA, abbiamo finalmente raggiunto un’implementazione più che soddisfacente di questa eccellente tecnologia, capace di assicurare un deciso guadagno prestazionale a fronte di una resa visiva che si mantiene su alti livelli.

Smontando la scheda video non abbiamo sorprese particolari, anzi, ci è apparsa evidente l’ottima cura degli assemblaggi di tutti i componenti. Il PCB, come abbiamo visto nel corso del nostro articolo, è estremamente curato e contraddistinto da un layout pulito ed ordinato. Il produttore asiatico ha previsto una circuiteria di alimentazione robusta e di qualità, basata su un design a 9+2 fasi di alimentazione complessive, le prime dedicate al prestante processore grafico, mentre le restanti al comparto di memoria.
Questo garantirà una maggiore efficienza e stabilità in considerazione della richiesta energetica necessaria alla corretta alimentazione del complesso processore grafico GA104 in declinazione “Full”. La qualità delle componenti discrete è più che buona e perfettamente in grado non soltanto di soddisfare le richieste energetiche previste ai valori di targa, ma anche di garantire un buon margine in overclock.
La INNO3D GeForce RTX 3070 Ti X3 OC è ordinabile da Tradeco Modding o AK Informatica. Vista l’attuale difficoltà nel reperire questo genere di prodotti, vi consigliamo di contattare immediatamente il negozio per effettuare eventualmente il pre-ordine. Non perdete tempo!
Pro:
- Processore grafico di fascia alta NVIDIA GA104-400 basato su architettura Ampere e provvisto di 6.144 unità CUDA, 192 unità Tensor Cores e 48 unità RT Cores;
- Frequenze operative fissate a 1.575/1.188/1.785MHz (Core/Memorie/Boost);
- Impiego di nuovissimi moduli di memoria GDDR6X certificati a 19Gbps (prodotti da Micron);
- Buona dotazione di memoria on-board (pari a 8.192MB);
- Layout generale del PCB ordinato e pulito;
- Robusta circuiteria di alimentazione da 9+2 fasi;
- Prestazioni complessive indubbiamente soddisfacenti anche a risoluzione 4K, sensibilmente superiori alla precedente soluzione gaming di pari fascia GeForce RTX 3070 (GPU GA104-300);
- Ottimo sistema di dissipazione compatto di tipo proprietario a doppio slot, silenzioso ed efficiente;
- Elevata stabilità e buone temperature d’esercizio durante le lunghe sessioni di test e gaming;
- Ottime tecnologie supportate;
- Ottima predisposizione all’overclock;
- Software di gestione proprietario (TuneIT) completo ed intuitivo.
Contro:
- Nulla da segnalare.
Si ringrazia ![]()
![]() per il campione fornitoci.
per il campione fornitoci.
Gianluca Cecca – delly – Admin di HW Legend






